17 KiB
Classificatori di cucina 1
In questa lezione, si utilizzerà l'insieme di dati salvati dall'ultima lezione, pieno di dati equilibrati e puliti relativi alle cucine.
Si utilizzerà questo insieme di dati con una varietà di classificatori per prevedere una determinata cucina nazionale in base a un gruppo di ingredienti. Mentre si fa questo, si imparerà di più su alcuni dei modi in cui gli algoritmi possono essere sfruttati per le attività di classificazione.
Quiz pre-lezione
Preparazione
Supponendo che la Lezione 1 sia stata completata, assicurarsi che esista un file clean_cuisines.csv nella cartella in radice /data per queste quattro lezioni.
Esercizio - prevedere una cucina nazionale
-
Lavorando con il notebook.ipynb di questa lezione nella cartella radice, importare quel file insieme alla libreria Pandas:
import pandas as pd cuisines_df = pd.read_csv("../../data/cleaned_cuisine.csv") cuisines_df.head()I dati si presentano così:
| | Unnamed: 0 | cuisine | almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | | --- | ---------- | ------- | ------ | -------- | ----- | ---------- | ----- | ------------ | ------- | -------- | --- | ------- | ----------- | ---------- | ----------------------- | ---- | ---- | --- | ----- | ------ | -------- | | 0 | 0 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 1 | 1 | indian | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 2 | 2 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 3 | 3 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 4 | 4 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | -
Ora importare molte altre librerie:
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve from sklearn.svm import SVC import numpy as np -
Dividere le coordinate X e y in due dataframe per l'addestramento.
cuisinepuò essere il dataframe delle etichette:cuisines_label_df = cuisines_df['cuisine'] cuisines_label_df.head()Apparirà così
0 indian 1 indian 2 indian 3 indian 4 indian Name: cuisine, dtype: object -
Scartare la colonna
Unnamed: 0e la colonnacuisine, chiamandodrop(). Salvare il resto dei dati come caratteristiche addestrabili:cuisines_feature_df = cuisines_df.drop(['Unnamed: 0', 'cuisine'], axis=1) cuisines_feature_df.head()Le caratteristiche sono così:
almond angelica anise anise_seed apple apple_brandy apricot armagnac artemisia artichoke ... whiskey white_bread white_wine whole_grain_wheat_flour wine wood yam yeast yogurt zucchini 0 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 1 0
Ora si è pronti per addestrare il modello!
Scegliere il classificatore
Ora che i dati sono puliti e pronti per l'addestramento, si deve decidere quale algoritmo utilizzare per il lavoro.
Scikit-learn raggruppa la classificazione in Supervised Learning, e in quella categoria si troveranno molti modi per classificare. La varietà è piuttosto sconcertante a prima vista. I seguenti metodi includono tutti tecniche di classificazione:
- Modelli Lineari
- Macchine a Vettori di Supporto
- Discesa stocastica del gradiente
- Nearest Neighbors
- Processi Gaussiani
- Alberi di Decisione
- Apprendimento ensemble (classificatore di voto)
- Algoritmi multiclasse e multioutput (classificazione multiclasse e multietichetta, classificazione multiclasse-multioutput)
Si possono anche usare le reti neurali per classificare i dati, ma questo esula dall'ambito di questa lezione.
Con quale classificatore andare?
Quale classificatore si dovrebbe scegliere? Spesso, scorrerne diversi e cercare un buon risultato è un modo per testare. Scikit-learn offre un confronto fianco a fianco su un insieme di dati creato, confrontando KNeighbors, SVC in due modi, GaussianProcessClassifier, DecisionTreeClassifier, RandomForestClassifier, MLPClassifier, AdaBoostClassifier, GaussianNB e QuadraticDiscrinationAnalysis, mostrando i risultati visualizzati:
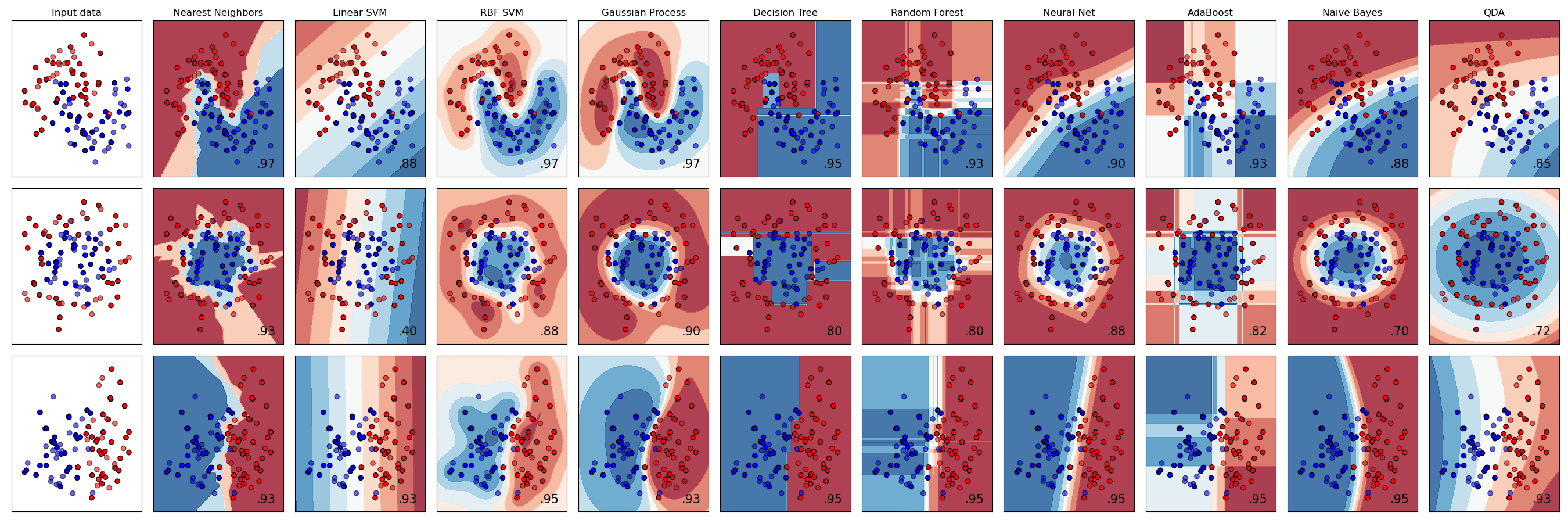
Grafici generati sulla documentazione di Scikit-learn
AutoML risolve questo problema in modo ordinato eseguendo questi confronti nel cloud, consentendo di scegliere l'algoritmo migliore per i propri dati. Si può provare qui
Un approccio migliore
Un modo migliore che indovinare a caso, tuttavia, è seguire le idee su questo ML Cheat sheet scaricabile. Qui si scopre che, per questo problema multiclasse, si dispone di alcune scelte:

Una sezione dell'Algorithm Cheat Sheet di Microsoft, che descrive in dettaglio le opzioni di classificazione multiclasse
✅ Scaricare questo cheat sheet, stamparlo e appenderlo alla parete!
Motivazione
Si prova a ragionare attraverso diversi approcci dati i vincoli presenti:
- Le reti neurali sono troppo pesanti. Dato l'insieme di dati pulito, ma minimo, e il fatto che si sta eseguendo l'addestramento localmente tramite notebook, le reti neurali sono troppo pesanti per questo compito.
- Nessun classificatore a due classi. Non si usa un classificatore a due classi, quindi questo esclude uno contro tutti.
- L'albero decisionale o la regressione logistica potrebbero funzionare. Potrebbe funzionare un albero decisionale o una regressione logistica per dati multiclasse.
- Gli alberi decisionali potenziati multiclasse risolvono un problema diverso. L'albero decisionale potenziato multiclasse è più adatto per attività non parametriche, ad esempio attività progettate per costruire classifiche, quindi non è utile in questo caso.
Utilizzo di Scikit-learn
Si userà Scikit-learn per analizzare i dati. Tuttavia, ci sono molti modi per utilizzare la regressione logistica in Scikit-learn. Dare un'occhiata ai parametri da passare.
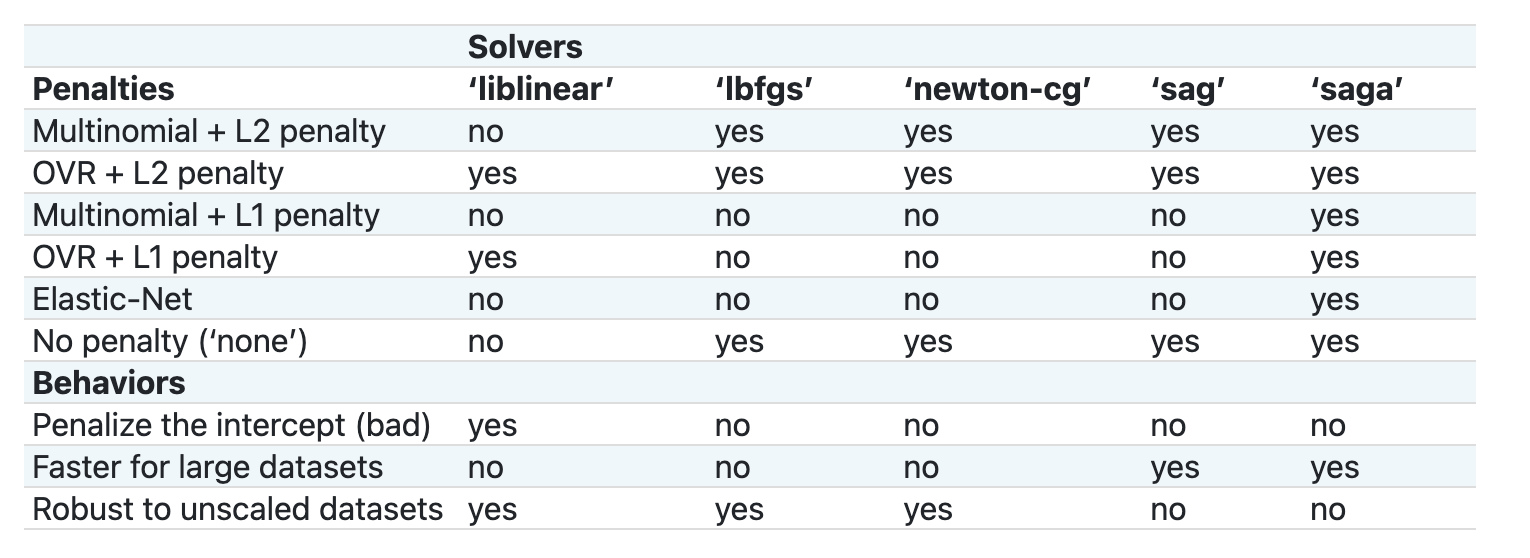
Essenzialmente ci sono due importanti parametri multi_class e solver, che occorre specificare, quando si chiede a Scikit-learn di eseguire una regressione logistica. Il valore multi_class si applica un certo comportamento. Il valore del risolutore è quale algoritmo utilizzare. Non tutti i risolutori possono essere associati a tutti i valori multi_class .
Secondo la documentazione, nel caso multiclasse, l'algoritmo di addestramento:
- Utilizza lo schema one-vs-rest (OvR) - uno contro tutti, se l'opzione
multi_classè impostata suovr - Utilizza la perdita di entropia incrociata, se l 'opzione
multi_classè impostata sumultinomial. (Attualmente l'opzione multinomiale è supportata solo dai solutori 'lbfgs', 'sag', 'saga' e 'newton-cg')."
🎓 Lo 'schema' qui può essere 'ovr' (one-vs-rest) - uno contro tutti - o 'multinomiale'. Poiché la regressione logistica è realmente progettata per supportare la classificazione binaria, questi schemi consentono di gestire meglio le attività di classificazione multiclasse. fonte
🎓 Il 'solver' è definito come "l'algoritmo da utilizzare nel problema di ottimizzazione". fonte.
Scikit-learn offre questa tabella per spiegare come i risolutori gestiscono le diverse sfide presentate da diversi tipi di strutture dati:
Esercizio: dividere i dati
Ci si può concentrare sulla regressione logistica per la prima prova di addestramento poiché di recente si è appreso di quest'ultima in una lezione precedente.
Dividere i dati in gruppi di addestramento e test chiamando train_test_split():
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
Esercizio: applicare la regressione logistica
Poiché si sta utilizzando il caso multiclasse, si deve scegliere quale schema utilizzare e quale solutore impostare. Usare LogisticRegression con un'impostazione multiclasse e il solutore liblinear da addestrare.
-
Creare una regressione logistica con multi_class impostato su
ovre il risolutore impostato suliblinear:lr = LogisticRegression(multi_class='ovr',solver='liblinear') model = lr.fit(X_train, np.ravel(y_train)) accuracy = model.score(X_test, y_test) print ("Accuracy is {}".format(accuracy))✅ Provare un risolutore diverso come
lbfgs, che è spesso impostato come predefinitoNota, usare la funzione
raveldi Pandas per appiattire i dati quando necessario.La precisione è buona oltre l'80%!
-
Si può vedere questo modello in azione testando una riga di dati (#50):
print(f'ingredients: {X_test.iloc[50][X_test.iloc[50]!=0].keys()}') print(f'cuisine: {y_test.iloc[50]}')Il risultato viene stampato:
ingredients: Index(['cilantro', 'onion', 'pea', 'potato', 'tomato', 'vegetable_oil'], dtype='object') cuisine: indian✅ Provare un numero di riga diverso e controllare i risultati
-
Scavando più a fondo, si può verificare l'accuratezza di questa previsione:
test= X_test.iloc[50].values.reshape(-1, 1).T proba = model.predict_proba(test) classes = model.classes_ resultdf = pd.DataFrame(data=proba, columns=classes) topPrediction = resultdf.T.sort_values(by=[0], ascending = [False]) topPrediction.head()Il risultato è stampato: la cucina indiana è la sua ipotesi migliore, con buone probabilità:
0 indiano 0,715851 cinese 0.229475 Giapponese 0,029763 Coreano 0.017277 thai 0.007634 ✅ Si è in grado di spiegare perché il modello è abbastanza sicuro che questa sia una cucina indiana?
-
Ottenere maggiori dettagli stampando un rapporto di classificazione, come fatto nelle lezioni di regressione:
y_pred = model.predict(X_test) print(classification_report(y_test,y_pred))precisione recall punteggio f1 supporto cinese 0,73 0,71 0,72 229 indiano 0,91 0,93 0,92 254 Giapponese 0.70 0,75 0,72 220 Coreano 0,86 0,76 0,81 242 thai 0,79 0,85 0.82 254 accuratezza 0,80 1199 macro media 0,80 0,80 0,80 1199 Media ponderata 0,80 0,80 0,80 1199
🚀 Sfida
In questa lezione, sono stati utilizzati dati puliti per creare un modello di apprendimento automatico in grado di prevedere una cucina nazionale basata su una serie di ingredienti. Si prenda del tempo per leggere le numerose opzioni fornite da Scikit-learn per classificare i dati. Approfondire il concetto di "risolutore" per capire cosa succede dietro le quinte.
Quiz post-lezione
Revisione e Auto Apprendimento
Approfondire un po' la matematica alla base della regressione logistica in questa lezione