12 KiB
Costruire un modello di regressione usando Scikit-learn: preparare e visualizzare i dati
Infografica di Dasani Madipalli
Quiz pre-lezione
Introduzione
Ora che si hanno a disposizione gli strumenti necessari per iniziare ad affrontare la creazione di modelli di machine learning con Scikit-learn, si è pronti per iniziare a porre domande sui propri dati. Mentre si lavora con i dati e si applicano soluzioni ML, è molto importante capire come porre la domanda giusta per sbloccare correttamente le potenzialità del proprio insieme di dati.
In questa lezione, si imparerà:
- Come preparare i dati per la creazione del modello.
- Come utilizzare Matplotlib per la visualizzazione dei dati.
Fare la domanda giusta ai propri dati
La domanda a cui si deve rispondere determinerà il tipo di algoritmi ML che verranno utilizzati. La qualità della risposta che si riceverà dipenderà fortemente dalla natura dei propri dati.
Si dia un'occhiata ai dati forniti per questa lezione. Si può aprire questo file .csv in VS Code. Una rapida scrematura mostra immediatamente che ci sono spazi vuoti e un mix di stringhe e dati numerici. C'è anche una strana colonna chiamata "Package" (pacchetto) in cui i dati sono un mix tra "sacks" (sacchi), "bins" (contenitori) e altri valori. I dati, infatti, sono un po' un pasticcio.
In effetti, non è molto comune ricevere un insieme di dati completamente pronto per creare un modello ML pronto all'uso. In questa lezione si imparerà come preparare un insieme di dati non elaborato utilizzando le librerie standard di Python. Si impareranno anche varie tecniche per visualizzare i dati.
Caso di studio: 'il mercato della zucca'
In questa cartella si troverà un file .csv nella cartella data radice chiamato US-pumpkins.csv che include 1757 righe di dati sul mercato delle zucche, ordinate in raggruppamenti per città. Si tratta di dati grezzi estratti dai Report Standard dei Mercati Terminali delle Colture Speciali distribuiti dal Dipartimento dell'Agricoltura degli Stati Uniti.
Preparazione dati
Questi dati sono di pubblico dominio. Possono essere scaricati in molti file separati, per città, dal sito web dell'USDA. Per evitare troppi file separati, sono stati concatenati tutti i dati della città in un unico foglio di calcolo, quindi un po' i dati sono già stati preparati . Successivamente, si darà un'occhiata più da vicino ai dati.
I dati della zucca - prime conclusioni
Cosa si nota riguardo a questi dati? Si è già visto che c'è un mix di stringhe, numeri, spazi e valori strani a cui occorre dare un senso.
Che domanda si puà fare a questi dati, utilizzando una tecnica di Regressione? Che dire di "Prevedere il prezzo di una zucca in vendita durante un dato mese". Esaminando nuovamente i dati, ci sono alcune modifiche da apportare per creare la struttura dati necessaria per l'attività.
Esercizio: analizzare i dati della zucca
Si usa Pandas, (il nome sta per Python Data Analysis) uno strumento molto utile per dare forma ai dati, per analizzare e preparare questi dati sulla zucca.
Innanzitutto, controllare le date mancanti
Prima si dovranno eseguire i passaggi per verificare le date mancanti:
- Convertire le date in un formato mensile (queste sono date statunitensi, quindi il formato è
MM/GG/AAAA). - Estrarre il mese in una nuova colonna.
Aprire il file notebook.ipynb in Visual Studio Code e importare il foglio di calcolo in un nuovo dataframe Pandas.
-
Usare la funzione
head()per visualizzare le prime cinque righe.import pandas as pd pumpkins = pd.read_csv('../data/US-pumpkins.csv') pumpkins.head()✅ Quale funzione si userebbe per visualizzare le ultime cinque righe?
-
Controllare se mancano dati nel dataframe corrente:
pumpkins.isnull().sum()Ci sono dati mancanti, ma forse non avrà importanza per l'attività da svolgere.
-
Per rendere più facile lavorare con il dataframe, si scartano molte delle sue colonne, usando
drop(), mantenendo solo le colonne di cui si ha bisogno:new_columns = ['Package', 'Month', 'Low Price', 'High Price', 'Date'] pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
Secondo, determinare il prezzo medio della zucca
Si pensi a come determinare il prezzo medio di una zucca in un dato mese. Quali colonne si sceglierebbero per questa attività? Suggerimento: serviranno 3 colonne.
Soluzione: prendere la media delle colonne Low Price e High Price per popolare la nuova colonna Price e convertire la colonna Date per mostrare solo il mese. Fortunatamente, secondo il controllo di cui sopra, non mancano dati per date o prezzi.
-
Per calcolare la media, aggiungere il seguente codice:
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2 month = pd.DatetimeIndex(pumpkins['Date']).month✅ Si possono di stampare tutti i dati che si desidera controllare utilizzando
print(month). -
Ora copiare i dati convertiti in un nuovo dataframe Pandas:
new_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})La stampa del dataframe mostrerà un insieme di dati pulito e ordinato su cui si può costruire il nuovo modello di regressione.
Ma non è finita qui! C'è qualcosa di strano qui.
Osservando la colonna Package, le zucche sono vendute in molte configurazioni diverse. Alcune sono venduti in misure '1 1/9 bushel' (bushel = staio) e alcuni in misure '1/2 bushel', alcuni per zucca, alcuni per libbra e alcuni in grandi scatole con larghezze variabili.
Le zucche sembrano molto difficili da pesare in modo coerente
Scavando nei dati originali, è interessante notare che qualsiasi cosa con Unit of Sale (Unità di vendita) uguale a 'EACH' o 'PER BIN' ha anche il tipo di Package per 'inch' (pollice), per 'bin' (contenitore) o 'each' (entrambi). Le zucche sembrano essere molto difficili da pesare in modo coerente, quindi si filtrano selezionando solo zucche con la stringa "bushel" nella colonna Package.
-
Aggiungere un filtro nella parte superiore del file, sotto l'importazione .csv iniziale:
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]Se si stampano i dati ora, si può vedere che si stanno ricevendo solo le circa 415 righe di dati contenenti zucche per bushel.
Ma non è finita qui! C'è un'altra cosa da fare.
Si è notato che la quantità di bushel varia per riga? Si deve normalizzare il prezzo in modo da mostrare il prezzo per bushel, quindi si facciano un po' di calcoli per standardizzarlo.
-
Aggiungere queste righe dopo il blocco che crea il dataframe new_pumpkins:
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9) new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
✅ Secondo The Spruce Eats, il peso di un bushel dipende dal tipo di prodotto, poiché è una misura di volume. "Un bushel di pomodori, per esempio, dovrebbe pesare 56 libbre... Foglie e verdure occupano più spazio con meno peso, quindi un bushel di spinaci è solo 20 libbre". È tutto piuttosto complicato! Non occorre preoccuparsi di fare una conversione da bushel a libbra, e invece si valuta a bushel. Tutto questo studio sui bushel di zucche, però, dimostra quanto sia importante capire la natura dei propri dati!
Ora si può analizzare il prezzo per unità in base alla misurazione del bushel. Se si stampano i dati ancora una volta, si può vedere come sono standardizzati.
✅ Si è notato che le zucche vendute a metà bushel sono molto costose? Si riesce a capire perché? Suggerimento: le zucche piccole sono molto più costose di quelle grandi, probabilmente perché ce ne sono molte di più per bushel, dato lo spazio inutilizzato occupato da una grande zucca cava.
Strategie di Visualizzazione
Parte del ruolo del data scientist è dimostrare la qualità e la natura dei dati con cui sta lavorando. Per fare ciò, si creano spesso visualizzazioni interessanti o tracciati, grafici e diagrammi, che mostrano diversi aspetti dei dati. In questo modo, sono in grado di mostrare visivamente relazioni e lacune altrimenti difficili da scoprire.
Le visualizzazioni possono anche aiutare a determinare la tecnica di machine learning più appropriata per i dati. Un grafico a dispersione che sembra seguire una linea, ad esempio, indica che i dati sono un buon candidato per un esercizio di regressione lineare.
Una libreria di visualizzazione dei dati che funziona bene nei notebook Jupyter è Matplotlib (che si è visto anche nella lezione precedente).
Per fare più esperienza con la visualizzazione dei dati si seguano questi tutorial.
Esercizio - sperimentare con Matplotlib
Provare a creare alcuni grafici di base per visualizzare il nuovo dataframe appena creato. Cosa mostrerebbe un grafico a linee di base?
-
Importare Matplotlib nella parte superiore del file, sotto l'importazione di Pandas:
import matplotlib.pyplot as plt -
Rieseguire l'intero notebook per aggiornare.
-
Nella parte inferiore del notebook, aggiungere una cella per tracciare i dati come una casella:
price = new_pumpkins.Price month = new_pumpkins.Month plt.scatter(price, month) plt.show()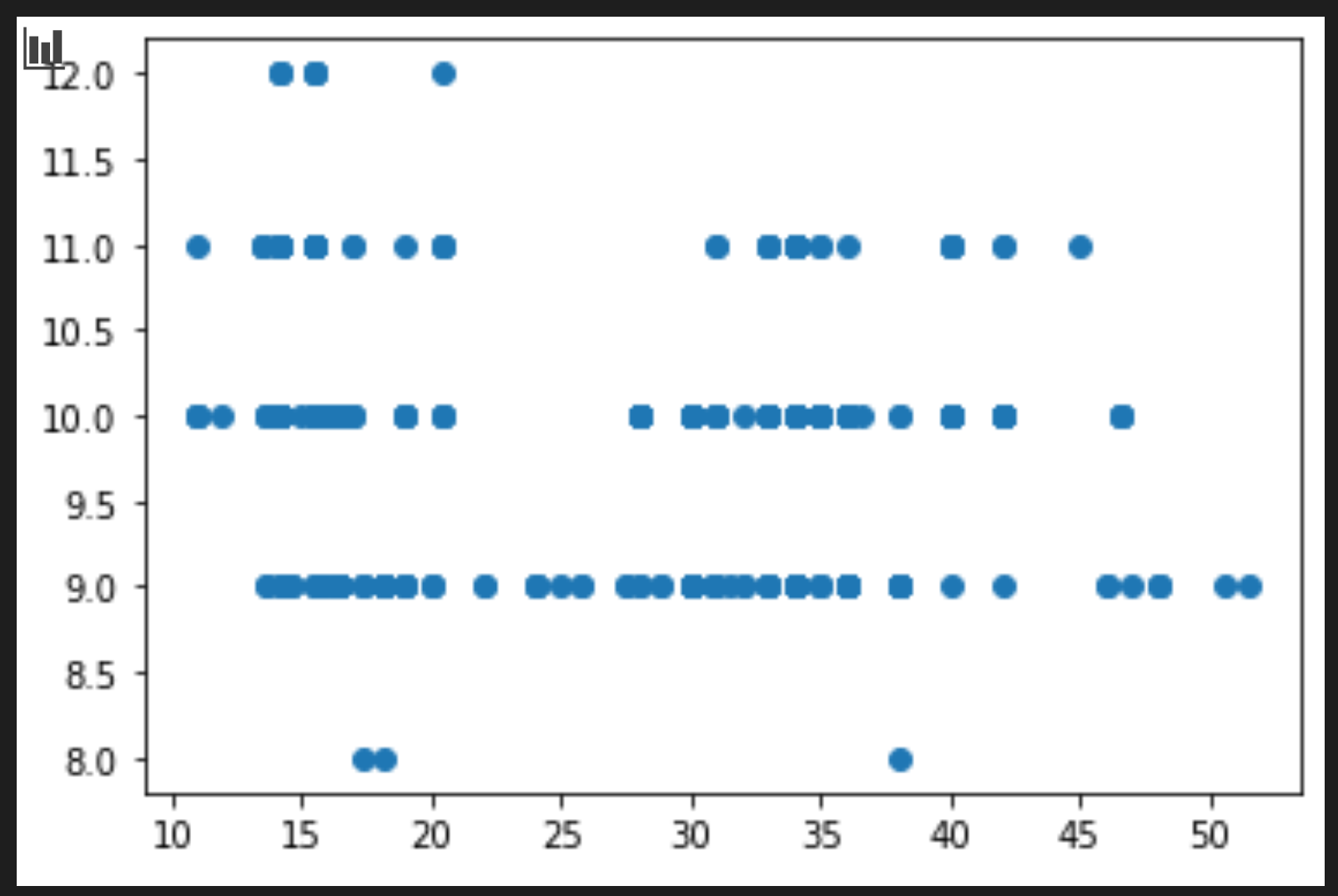
È un tracciato utile? C'è qualcosa che sorprende?
Non è particolarmente utile in quanto tutto ciò che fa è visualizzare nei propri dati come una diffusione di punti in un dato mese.
Renderlo utile
Per fare in modo che i grafici mostrino dati utili, di solito è necessario raggruppare i dati in qualche modo. Si prova a creare un grafico che mostra la distribuzione dei dati dove l'asse x mostra i mesi.
-
Aggiungere una cella per creare un grafico a barre raggruppato:
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar') plt.ylabel("Pumpkin Price")
Questa è una visualizzazione dei dati più utile! Sembra indicare che il prezzo più alto per le zucche si verifica a settembre e ottobre. Questo soddisfa le proprie aspettative? Perché o perché no?
🚀 Sfida
Esplorare i diversi tipi di visualizzazione offerti da Matplotlib. Quali tipi sono più appropriati per i problemi di regressione?
Quiz post-lezione
Revisione e Auto Apprendimento
Dare un'occhiata ai molti modi per visualizzare i dati. Fare un elenco delle varie librerie disponibili e annotare quali sono le migliori per determinati tipi di attività, ad esempio visualizzazioni 2D rispetto a visualizzazioni 3D. Cosa si è scoperto?