22 KiB
Introduction to clustering
Clustering is a type of Unsupervised Learning that presumes that a dataset is unlabelled or that its inputs are not matched with predefined outputs. It uses various algorithms to sort through unlabeled data and provide groupings according to patterns it discerns in the data.

🎥 Click the image above for a video. While you're studying machine learning with clustering, enjoy some Nigerian Dance Hall tracks - this is a highly rated song from 2014 by PSquare.
Pre-lecture quiz
Introduction
Clustering is very useful for data exploration. Let's see if it can help discover trends and patterns in the way Nigerian audiences consume music.
✅ Take a minute to think about the uses of clustering. In real life, clustering happens whenever you have a pile of laundry and need to sort out your family members' clothes 🧦👕👖🩲. In data science, clustering happens when trying to analyze a user's preferences, or determine the characteristics of any unlabeled dataset. Clustering, in a way, helps make sense of chaos, like a sock drawer.

🎥 Click the image above for a video: MIT's John Guttag introduces clustering
In a professional setting, clustering can be used to determine things like market segmentation, determining what age groups buy what items, for example. Another use would be anomaly detection, perhaps to detect fraud from a dataset of credit card transactions. Or you might use clustering to determine tumors in a batch of medical scans.
✅ Think a minute about how you might have encountered clustering 'in the wild', in a banking, e-commerce, or business setting.
🎓 Interestingly, cluster analysis originated in the fields of Anthropology and Psychology in the 1930s. Can you imagine how it might have been used?
Alternately, you could use it for grouping search results - by shopping links, images, or reviews, for example. Clustering is useful when you have a large dataset that you want to reduce and on which you want to perform more granular analysis, so the technique can be used to learn about data before other models are constructed.
✅ Once your data is organized in clusters, you assign it a cluster Id, and this technique can be useful when preserving a dataset's privacy; you can instead refer to a data point by its cluster id, rather than by more revealing identifiable data. Can you think of other reasons why you'd refer to a cluster Id rather than other elements of the cluster to identify it?
Deepen your understanding of clustering techniques in this Learn module
Getting started with clustering
Scikit-learn offers a large array of methods to perform clustering. The type you choose will depend on your use case. According to the documentation, each method has various benefits. Here is a simplified table of the methods supported by Scikit-learn and their appropriate use cases:
| Method name | Use case |
|---|---|
| K-Means | general purpose, inductive |
| Affinity propagation | many, uneven clusters, inductive |
| Mean-shift | many, uneven clusters, inductive |
| Spectral clustering | few, even clusters, transductive |
| Ward hierarchical clustering | many, constrained clusters, transductive |
| Agglomerative clustering | many, constrained, non Euclidean distances, transductive |
| DBSCAN | non-flat geometry, uneven clusters, transductive |
| OPTICS | non-flat geometry, uneven clusters with variable density, transductive |
| Gaussian mixtures | flat geometry, inductive |
| BIRCH | large dataset with outliers, inductive |
🎓 How we create clusters has a lot to do with how we gather up the data points into groups. Let's unpack some vocabulary:
🎓 'Transductive' vs. 'inductive'
Transductive inference is derived from observed training cases that map to specific test cases. Inductive inference is derived from training cases that map to general rules which are only then applied to test cases.
An example: Imagine you have a dataset that is only partially labelled. Some things are 'records', some 'cds', and some are blank. Your job is to provide labels for the blanks. If you choose an inductive approach, you'd train a model looking for 'records' and 'cds', and apply those labels to your unlabeled data. This approach will have trouble classifying things that are actually 'cassettes'. A transductive approach, on the other hand, handles this unknown data more effectively as it works to group similar items together and then applies a label to a group. In this case, clusters might reflect 'round musical things' and 'square musical things'.
🎓 'Non-flat' vs. 'flat' geometry
Derived from mathematical terminology, non-flat vs. flat geometry refers to the measure of distances between points by either 'flat' (Euclidean) or 'non-flat' (non-Euclidean) geometrical methods.
'Flat' in this context refers to Euclidean geometry (parts of which are taught as 'plane' geometry), and non-flat refers to non-Euclidean geometry. What does geometry have to do with machine learning? Well, as two fields that are rooted in mathematics, there must be a common way to measure distances between points in clusters, and that can be done in a 'flat' or 'non-flat' way, depending on the nature of the data. Euclidean distances are measured as the length of a line segment between two points. Non-Euclidean distances are measured along a curve. If your data, visualized, seems to not exist on a plane, you might need to use a specialized algorithm to handle it.
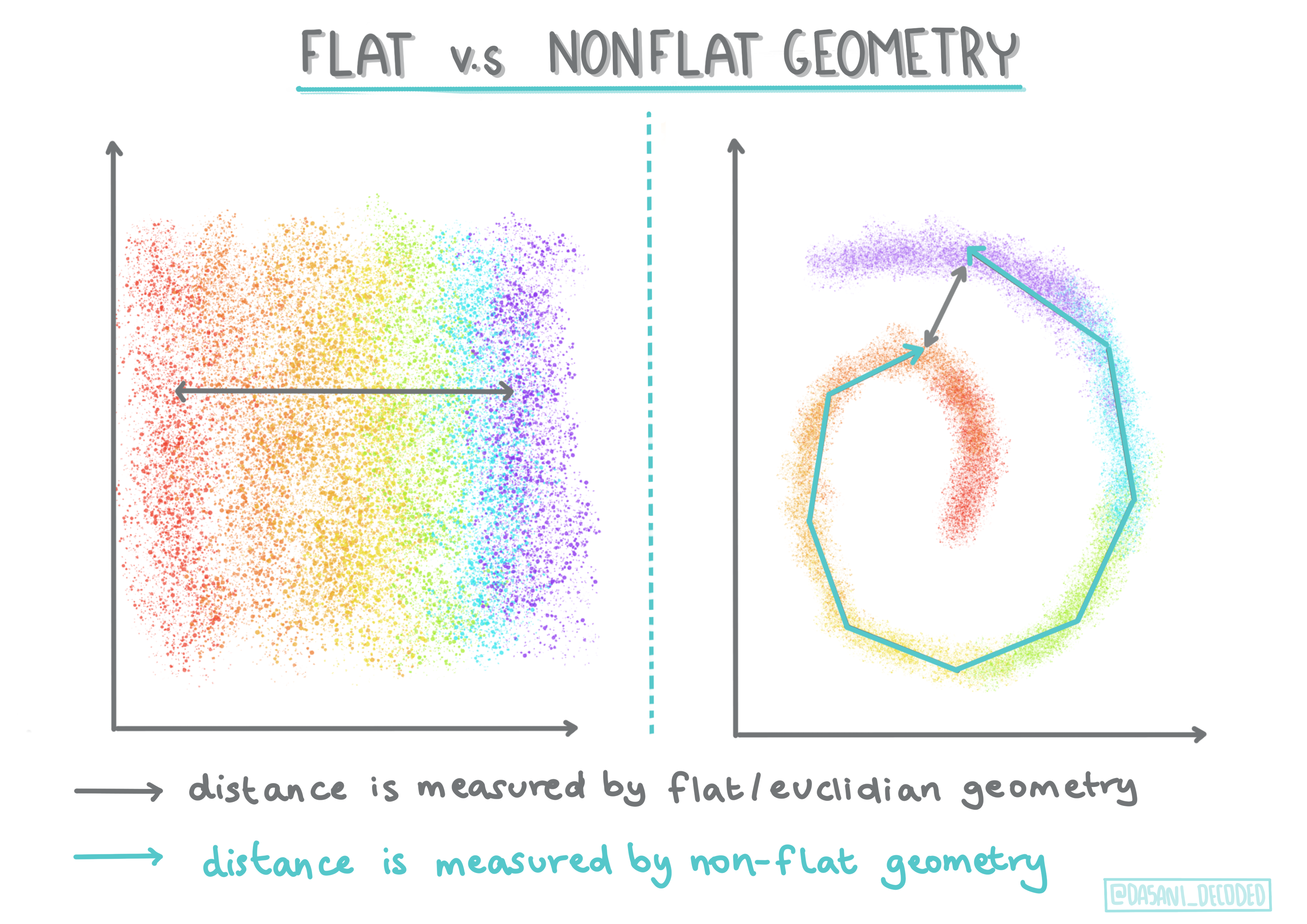
Infographic by Dasani Madipalli
Clusters are defined by their distance matrix, e.g. the distances between points. This distance can be measured a few ways. Euclidean clusters are defined by the average of the point values, and contain a 'centroid' or center point. Distances are thus measured by the distance to that centroid. Non-Euclidean distances refer to 'clustroids', the point closest to other points. Clustroids in turn can be defined in various ways.
Constrained Clustering introduces 'semi-supervised' learning into this unsupervised method. The relationships between points are flagged as 'cannot link' or 'must-link' so some rules are forced on the dataset.
An example: If an algorithm is set free on a batch of unlabelled or semi-labelled data, the clusters it produces may be of poor quality. In the example above, the clusters might group 'round music things' and 'square music things' and 'triangular things' and 'cookies'. If given some constraints, or rules to follow ("the item must be made of plastic", "the item needs to be able to produce music") this can help 'constrain' the algorithm to make better choices.
🎓 'Density'
Data that is 'noisy' is considered to be 'dense'. The distances between points in each of its clusters may prove, on examination, to be more or less dense, or 'crowded' and thus this data needs to be analyzed with the appropriate clustering method. This article demonstrates the difference between using K-Means clustering vs. HDBSCAN algorithms to explore a noisy dataset with uneven cluster density.
Clustering algorithms
There are over 100 clustering algorithms, and their use depends on the nature of the data at hand. Let's discuss some of the major ones:
Hierarchical clustering
If an object is classified by its proximity to a nearby object, rather than to one farther away, clusters are formed based on their members' distance to and from other objects. Scikit-learn's agglomerative clustering is hierarchical.
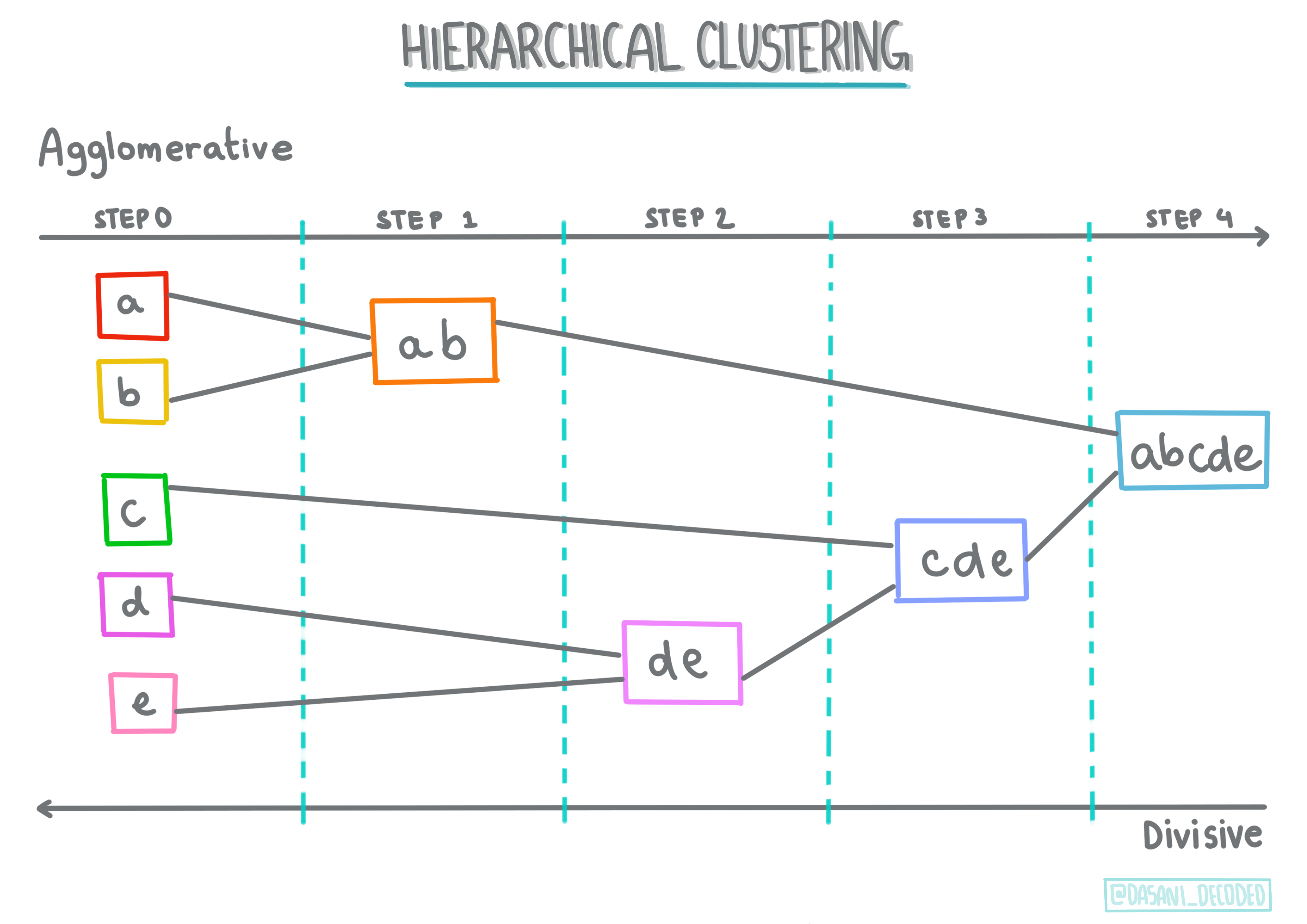
Infographic by Dasani Madipalli
Centroid clustering
This popular algorithm requires the choice of 'k', or the number of clusters to form, after which the algorithm determines the center point of a cluster and gathers data around that point. K-means clustering is a popular version of centroid clustering. The center is determined by the nearest mean, thus the name. The squared distance from the cluster is minimized.
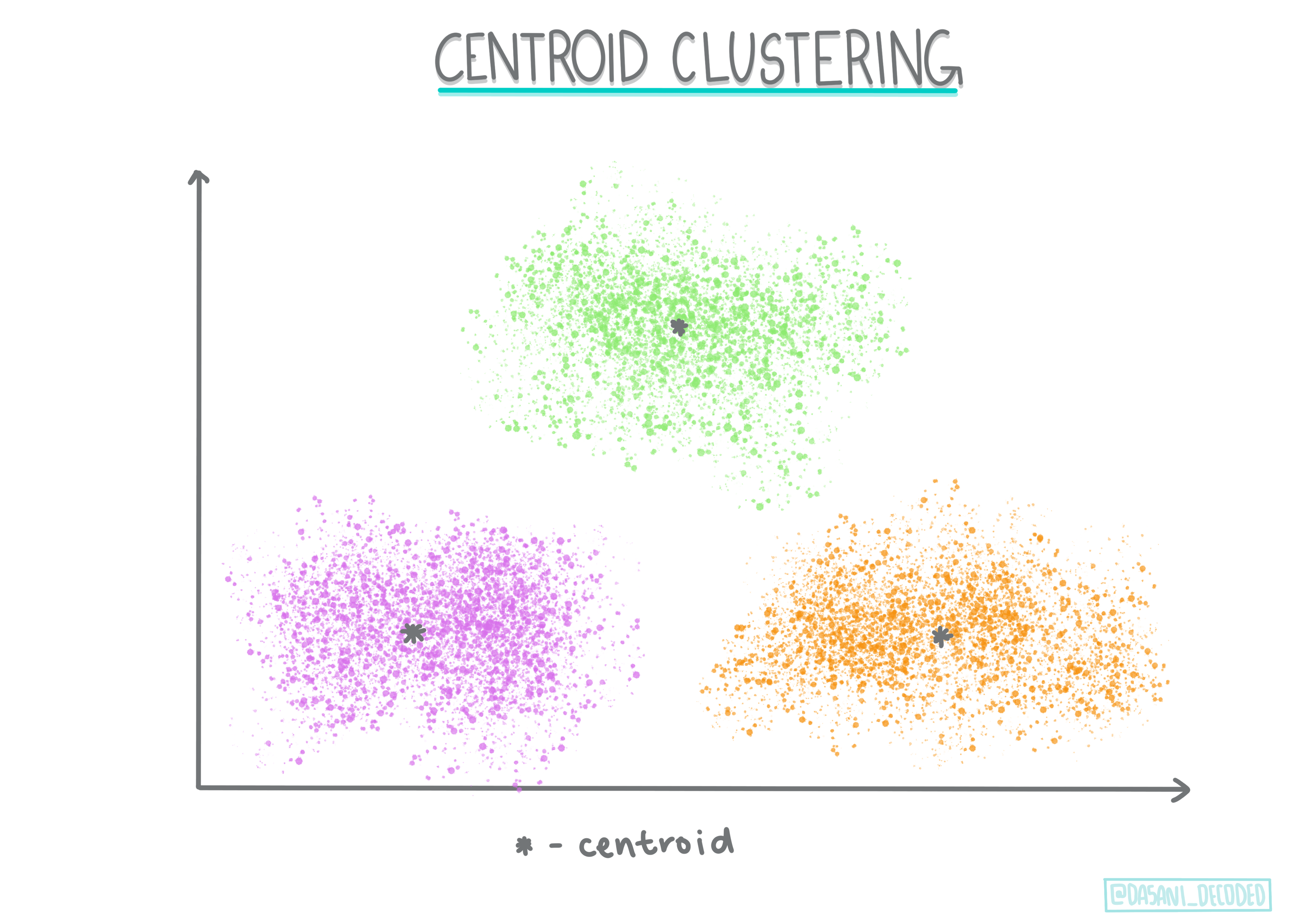
Infographic by Dasani Madipalli
Distribution-based clustering
Based in statistical modeling, distribution-based clustering centers on determining the probability that a data point belongs to a cluster, and assigning it accordingly. Gaussian mixture methods belong to this type.
Density-based clustering
Data points are assigned to clusters based on their density, or their grouping around each other. Data points far from the group are considered outliers or noise. DBSCAN, Mean-shift and OPTICS belong to this type of clustering.
Grid-based clustering
For multi-dimensional datasets, a grid is created and the data is divided amongst the grid's cells, thereby creating clusters.
Preparing the data
Clustering as a technique is greatly aided by proper visualization, so let's get started by visualizing our music data. This exercise will help us decide which of the methods of clustering we should most effectively use for the nature of this data.
Open the notebook.ipynb file in this folder. Import the Seaborn package for good data visualization.
pip install seaborn
Append the song data .csv file. Load up a dataframe with some data about the songs. Get ready to explore this data by importing the libraries and dumping out the data:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv("../data/nigerian-songs.csv")
df.head()
Check the first few lines of data:
| name | album | artist | artist_top_genre | release_date | length | popularity | danceability | acousticness | energy | instrumentalness | liveness | loudness | speechiness | tempo | time_signature | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Sparky | Mandy & The Jungle | Cruel Santino | alternative r&b | 2019 | 144000 | 48 | 0.666 | 0.851 | 0.42 | 0.534 | 0.11 | -6.699 | 0.0829 | 133.015 | 5 |
| 1 | shuga rush | EVERYTHING YOU HEARD IS TRUE | Odunsi (The Engine) | afropop | 2020 | 89488 | 30 | 0.71 | 0.0822 | 0.683 | 0.000169 | 0.101 | -5.64 | 0.36 | 129.993 | 3 |
| 2 | LITT! | LITT! | AYLØ | indie r&b | 2018 | 207758 | 40 | 0.836 | 0.272 | 0.564 | 0.000537 | 0.11 | -7.127 | 0.0424 | 130.005 | 4 |
| 3 | Confident / Feeling Cool | Enjoy Your Life | Lady Donli | nigerian pop | 2019 | 175135 | 14 | 0.894 | 0.798 | 0.611 | 0.000187 | 0.0964 | -4.961 | 0.113 | 111.087 | 4 |
| 4 | wanted you | rare. | Odunsi (The Engine) | afropop | 2018 | 152049 | 25 | 0.702 | 0.116 | 0.833 | 0.91 | 0.348 | -6.044 | 0.0447 | 105.115 | 4 |
Get some information about the dataframe:
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 530 entries, 0 to 529
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 530 non-null object
1 album 530 non-null object
2 artist 530 non-null object
3 artist_top_genre 530 non-null object
4 release_date 530 non-null int64
5 length 530 non-null int64
6 popularity 530 non-null int64
7 danceability 530 non-null float64
8 acousticness 530 non-null float64
9 energy 530 non-null float64
10 instrumentalness 530 non-null float64
11 liveness 530 non-null float64
12 loudness 530 non-null float64
13 speechiness 530 non-null float64
14 tempo 530 non-null float64
15 time_signature 530 non-null int64
dtypes: float64(8), int64(4), object(4)
memory usage: 66.4+ KB
Double-check for null values:
df.isnull().sum()
Looking good:
name 0
album 0
artist 0
artist_top_genre 0
release_date 0
length 0
popularity 0
danceability 0
acousticness 0
energy 0
instrumentalness 0
liveness 0
loudness 0
speechiness 0
tempo 0
time_signature 0
dtype: int64
Describe the data:
df.describe()
| release_date | length | popularity | danceability | acousticness | energy | instrumentalness | liveness | loudness | speechiness | tempo | time_signature | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 530 | 530 | 530 | 530 | 530 | 530 | 530 | 530 | 530 | 530 | 530 | 530 |
| mean | 2015.390566 | 222298.1698 | 17.507547 | 0.741619 | 0.265412 | 0.760623 | 0.016305 | 0.147308 | -4.953011 | 0.130748 | 116.487864 | 3.986792 |
| std | 3.131688 | 39696.82226 | 18.992212 | 0.117522 | 0.208342 | 0.148533 | 0.090321 | 0.123588 | 2.464186 | 0.092939 | 23.518601 | 0.333701 |
| min | 1998 | 89488 | 0 | 0.255 | 0.000665 | 0.111 | 0 | 0.0283 | -19.362 | 0.0278 | 61.695 | 3 |
| 25% | 2014 | 199305 | 0 | 0.681 | 0.089525 | 0.669 | 0 | 0.07565 | -6.29875 | 0.0591 | 102.96125 | 4 |
| 50% | 2016 | 218509 | 13 | 0.761 | 0.2205 | 0.7845 | 0.000004 | 0.1035 | -4.5585 | 0.09795 | 112.7145 | 4 |
| 75% | 2017 | 242098.5 | 31 | 0.8295 | 0.403 | 0.87575 | 0.000234 | 0.164 | -3.331 | 0.177 | 125.03925 | 4 |
| max | 2020 | 511738 | 73 | 0.966 | 0.954 | 0.995 | 0.91 | 0.811 | 0.582 | 0.514 | 206.007 | 5 |
🤔 If we are working with clustering, an unsupervised method that does not require labeled data, why are we showing this data with labels? In the data exploration phase, they come in handy, but they are not necessary for the clustering algorithms to work. You could just as well remove the column headers and refer to the data by column number.
Look at the general values of the data. Note that popularity can be '0', which show songs that have no ranking. Let's remove those shortly.
Use a barplot to find out the most popular genres:
import seaborn as sns
top = df['artist_top_genre'].value_counts()
plt.figure(figsize=(10,7))
sns.barplot(x=top[:5].index,y=top[:5].values)
plt.xticks(rotation=45)
plt.title('Top genres',color = 'blue')
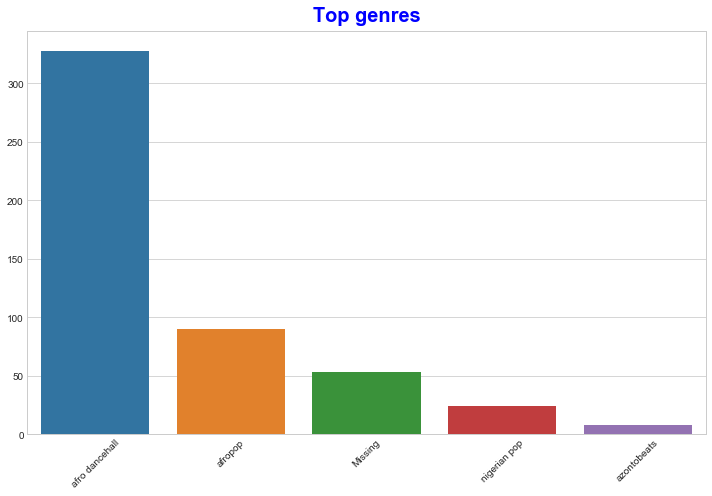
✅ If you'd like to see more top values, change the top [:5] to a bigger value, or remove it to see all.
Note, when the top genre is described as 'Missing', that means that Spotify did not classify it, so let's get rid of it:
df = df[df['artist_top_genre'] != 'Missing']
top = df['artist_top_genre'].value_counts()
plt.figure(figsize=(10,7))
sns.barplot(x=top.index,y=top.values)
plt.xticks(rotation=45)
plt.title('Top genres',color = 'blue')
Now recheck the genres:
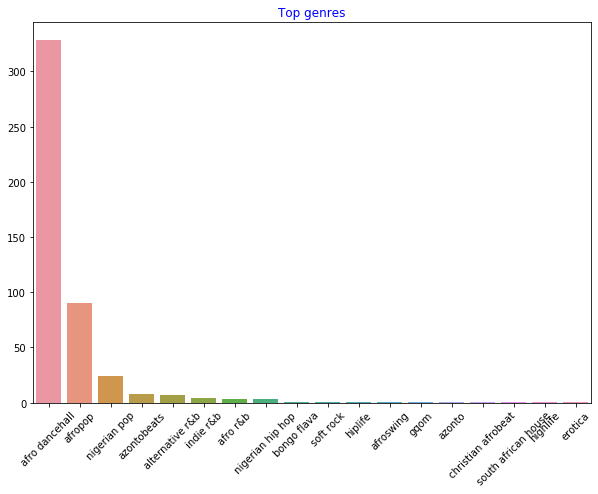
By far, the top three genres dominate this dataset, so let's concentrate on afro dancehall, afropop, and nigerian pop, also filtering the dataset to remove anything with a 0 popularity value (meaning it was not classified with a popularity in the dataset and can be considered noise for our purposes):
df = df[(df['artist_top_genre'] == 'afro dancehall') | (df['artist_top_genre'] == 'afropop') | (df['artist_top_genre'] == 'nigerian pop')]
df = df[(df['popularity'] > 0)]
top = df['artist_top_genre'].value_counts()
plt.figure(figsize=(10,7))
sns.barplot(x=top.index,y=top.values)
plt.xticks(rotation=45)
plt.title('Top genres',color = 'blue')
Do a quick test to see if the data correlates in any particularly strong way:
corrmat = df.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);

The only strong correlation is between energy and loudness, which is not too surprising, given that loud music is usually pretty energetic. Otherwise, the correlations are relatively weak. It will be interesting to see what a clustering algorithm can make of this data.
🎓 Note that correlation does not imply causation! We have proof of correlation but no proof of causation. An amusing web site has some visuals that emphasize this point.
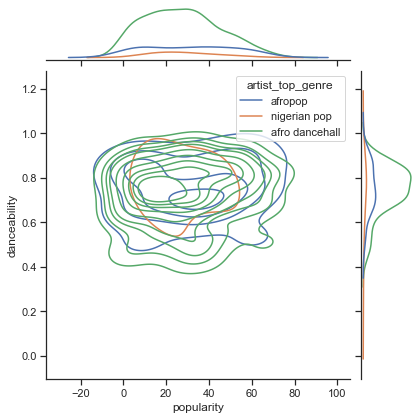
Is there any convergence in this dataset around a song's perceived popularity and danceability? A FacetGrid shows that there are concentric circles that line up, regardless of genre. Could it be that Nigerian tastes converge at a certain level of danceability for this genre?
✅ Try different datapoints (energy, loudness, speechiness) and more or different musical genres. What can you discover? Take a look at the df.describe() table to see the general spread of the data points.
Data distribution
Are these three genres significantly different in the perception of their danceability, based on their popularity? Examine our top three genres data distribution for popularity and danceability along a given x and y axis.
sns.set_theme(style="ticks")
g = sns.jointplot(
data=df,
x="popularity", y="danceability", hue="artist_top_genre",
kind="kde",
)
You can discover concentric circles around a general point of convergence, showing the distribution of points.
🎓 Note that this example uses a KDE (Kernel Density Estimate) graph that represents the data using a continuous probability density curve. This allows us to interpret data when working with multiple distributions.
In general, the three genres align loosely in terms of their popularity and danceability. Determining clusters in this loosely-aligned data will be a challenge:
A scatterplot of the same axes shows a similar pattern of convergence:
sns.FacetGrid(df, hue="artist_top_genre", size=5) \
.map(plt.scatter, "popularity", "danceability") \
.add_legend()
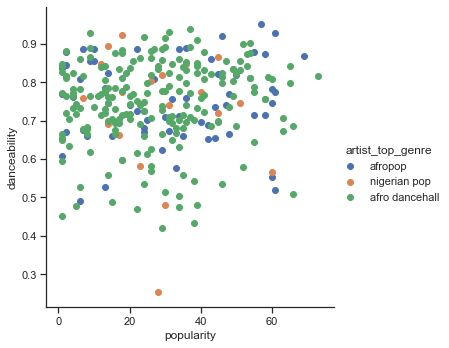
In general, for clustering, you can use scatterplots to show clusters of data, so mastering this type of visualization is very useful. In the next lesson, we will take this filtered data and use k-means clustering to discover groups in this data that see to overlap in interesting ways.
🚀Challenge
In preparation for the next lesson, make a chart about the various clustering algorithms you might discover and use in a production environment. What kinds of problems is the clustering trying to address?
Post-lecture quiz
Review & Self Study
Before you apply clustering algorithms, as we have learned, it's a good idea to understand the nature of your dataset. Read more onn this topic here
This helpful article walks you through the different ways that various clustering algorithms behave, given different data shapes.