12 KiB
Scikit-learn 사용한 regression 모델 만들기: 데이터 준비와 시각화
Infographic by Dasani Madipalli
강의 전 퀴즈
소개
이제 Scikit-learn으로 머신러닝 모델을 만들기 시작할 때 필요한 도구를 세팅했으므로, 데이터에 대한 질문을 할 준비가 되었습니다. 데이터로 작업하고 ML 솔루션을 적용하려면, 데이터셋의 잠재력을 잘 분석하기 위하여 올바른 질문 방식을 이해하는 것이 매우 중요합니다.
이 강의에서, 다음을 배웁니다:
- 모델-제작 위한 데이터 준비하는 방식.
- 데이터 시각화 위한 Matplotlib 사용하는 방식.
데이터에 올바른 질문하기
답변이 필요한 질문에 따라서 활용할 ML 알고리즘의 타입이 결정됩니다. 그리고 받는 답변의 퀄리티는 데이터의 성격에 크게 의존됩니다.
이 강의에서 제공되는 data를 보세요. VS Code에서 .csv 파일을 열 수 있습니다. 빠르게 흝어보면 공백과 문자열과 숫자 데이터가 섞여진 것을 보여줍니다. 'Package'라고 불리는 이상한 열에 'sacks', 'bins'과 다른 값 사이에 섞인 데이터가 있습니다. 사실은, 조금 엉성합니다.
실제로, ML 모델을 바로 꺼내 만들면서 완벽하게 사용할 준비가 된 데이터셋을 주는 건 매우 평범하지 않습니다. 이 강의에서는, 표준 Python 라이브러리로 원본 데이터셋을 준비하는 과정을 배우게 됩니다. 데이터 시각화하는 다양한 기술을 배웁니다.
케이스 스터디: 'the pumpkin market'
이 폴더에서는 호박 시장에 대한 데이터 1757 라인이 도시별로 분류된 US-pumpkins.csv 라고 불리는 최상위 data 폴더에서 .csv 파일을 찾을 수 있습니다. United States Department of Agriculture가 배포한 Specialty Crops Terminal Markets Standard Reports에서 원본 데이터를 추출했습니다.
데이터 준비하기
이 데이터는 공개 도메인에 존재합니다. USDA 웹사이트에서, 도시별로, 많은 여러개 파일을 내려받을 수 있습니다. 너무 많이 분리된 파일들을 피하기 위해서, 모든 도시 데이터를 한 개의 스프레드 시트에 연결했으므로, 미리 데이터를 조금 준비 했습니다. 다음으로, 데이터를 가까이 봅니다.
호박 데이터 - 이른 결론
데이터에서 어떤 것을 눈치챘나요? 이해할 문자열, 숫자, 공백과 이상한 값이 섞여있다는 것을 이미 봤습니다.
Regression 기술을 사용해서, 데이터에 물어볼 수 있는 질문인가요? "Predict the price of a pumpkin for sale during a given month"는 어떤가요. 데이터를 다시보면, 작업에 필요한 데이터 구조를 만들기 위하여 조금 바꿀 점이 있습니다.
연습 - 호박 데이터 분석하기
호박 데이터를 분석하고 준비하며, 데이터를 구성할 때 매우 유용한 도구인, Pandas (Python Data Analysis의 약자)를 사용해봅시다.
먼저, 누락된 날짜를 확인합니다.
먼저 누락된 데이터들을 확인하는 단계가 필요합니다:
- 날짜를 월 포맷으로 변환합니다 (US 날짜라서
MM/DD/YYYY포맷). - month를 새로운 열로 추출합니다.
visual Studio Code에서 notebook.ipynb 파일을 열고 새로운 Pandas 데아터프레임에 spreadsheet를 가져옵니다.
-
처음 5개 행을 보기 위하여
head()함수를 사용합니다.import pandas as pd pumpkins = pd.read_csv('../data/US-pumpkins.csv') pumpkins.head()✅ 마지막 5개 행을 보려면 어떤 함수를 사용하나요?
-
지금 데이터프레임에 누락된 데이터가 있다면 확인합니다:
pumpkins.isnull().sum()누락된 데이터이지만, 당장 앞에 있는 작업에는 중요하지 않을 수 있습니다.
-
데이터프레임 작업을 더 쉽게 하려면,
drop()으로, 여러 열을 지우고, 필요한 행만 둡니다.new_columns = ['Package', 'Month', 'Low Price', 'High Price', 'Date'] pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1)
두번째로, 호박의 평균 가격을 결정합니다.
주어진 달에 호박의 평균 가격을 결정하는 방식에 대하여 생각합니다. 이 작업을 하기 위하여 어떤 열을 선택할까요? 힌트: 3개의 열이 필요합니다.
솔루션: Low Price와 High Price 열의 평균으로 새로운 가격 열을 채우고, 이 달만 보여주기 위해 날짜 열을 변환합니다. 다행히, 확인해보니, 누락된 날짜나 가격 데이터가 없습니다.
-
평균을 계산하려면, 해당 코드를 추가합니다:
price = (pumpkins['Low Price'] + pumpkins['High Price']) / 2 month = pd.DatetimeIndex(pumpkins['Date']).month✅
print(month)로 확인하려는 데이터를 마음껏 출력해보세요. -
이제, 새로 만든 Pandas 데이터프레임으로 변환한 데이터를 복사해보세요:
new_pumpkins = pd.DataFrame({'Month': month, 'Package': pumpkins['Package'], 'Low Price': pumpkins['Low Price'],'High Price': pumpkins['High Price'], 'Price': price})데이터프레임을 출력해보면 새로운 regression 모델을 만들 수 있는 깨끗하고, 단정한 데이터셋이 보여집니다.
하지만 기다려주세요! 여기 무언가 있습니다
Package 열을 보면, 호박이 많이 다양한 구성으로 팔린 것을 볼 수 있습니다. 일부는 '1 1/9 bushel' 단위로 팔고, '1/2 bushel' 단위로 팔고, 호박 단위, 파운드 단위, 그리고 다양한 넓이의 큰 박스에도 넣어서 팔고 있습니다.
호박은 일정한 무게로 이루어지기 꽤 어려운 것 같습니다.
원본 데이터를 파다보면, 모든 항목에 인치, 박스 당, 또는 'each'로 이루어져서 Unit of Sale이 'EACH' 또는 'PER BIN'이라는 사실은 흥미롭습니다. 호박은 일정하게 무게를 달기가 매우 어려워서, Package 열에 'bushel' 문자열이 있는 호박만 선택해서 필터링하겟습니다.
-
파일 상단, 처음 .csv import 하단에 필터를 추가합니다:
pumpkins = pumpkins[pumpkins['Package'].str.contains('bushel', case=True, regex=True)]지금 데이터를 출력해보면, bushel 호박 포함한 대략 415개의 행만 가져올 수 있습니다.
하지만 기다려주세요! 하나 더 있습니다
bushel 수량이 행마다 다른 것을 알았나요? bushel 단위로 가격을 보여줄 수 있도록 가격을 노말라이즈해야 되므로, 수학으로 일반화해야 합니다.
-
new_pumpkins 데이터프레임을 만드는 블록 뒤에 이 라인들을 추가합니다:
new_pumpkins.loc[new_pumpkins['Package'].str.contains('1 1/9'), 'Price'] = price/(1 + 1/9) new_pumpkins.loc[new_pumpkins['Package'].str.contains('1/2'), 'Price'] = price/(1/2)
✅ The Spruce Eats에 따르면, bushel의 무게는 볼륨 측정이므로, 농산물 타입에 따릅니다. "A bushel of tomatoes, for example, is supposed to weigh 56 pounds... Leaves and greens take up more space with less weight, so a bushel of spinach is only 20 pounds." 모든 게 정말 복잡합니다! bushel에서 파운드로 변환하면서 신경쓰지 말고, bushel로 가격을 정합니다. 호박 bushels의 모든 연구는, 데이터의 특성을 이해하는 게 매우 중요하다는 것을 보여줍니다.
지금, bushel 측정을 기반으로 가격을 분석하는 게 가능해졌습니다. 만약 한 번 데이터를 출력하면, 표준화된 상태로 볼 수 있습니다.
✅ half-bushel로 파는 게 매우 비싸다는 사실을 파악했나요? 왜 그런 지 알 수 있나요? 힌트: 작은 호박은 큰 호박보다 비쌉니다, 큰 hollow 파이 호박 하나가 차지하는 빈 공간을 생각해보면, bushel 당 더 많습니다.
시각화 전략
데이터 사이언티스트 룰의 일부는 작업하고 있는 데이터의 품질과 특성을 증명하는 것입니다. 데이터의 다양한 측면을 보여주는, 흥미로운 시각화, 또는 plots, 그래프 그리고 차트를 만드는 경우가 자주 있습니다. 이렇게, 다른 방식으로 밝히기 힘든 관계와 간격을 시각적으로 표현할 수 있습니다.
시각화는 데이터에 가장 적합한 머신러닝 기술의 결정을 돕습니다. 라인을 따라가는 것처럼 보이는 scatterplot을(산점도) 예시로, 데이터가 linear regression 연습에 좋은 후보군이라는 것을 나타냅니다.
Jupyter notebooks에서 잘 작동하는 데이터 시각화 라이브러리는 (이전 강의에서 보았던) Matplotlib입니다.
these tutorials에서 데이터 시각화 연습을 더 해보세요.
연습 - Matplotlib으로 실험하기
직전에 만든 새로운 데이터프레임을 출력하려면 기초 plot을 만듭시다. 기초 라인 plot은 어떻게 보여주나요?
-
파일의 상단에, Pandas import 밑에서 Matplotlib을 Import 합니다:
import matplotlib.pyplot as plt -
전체 노트북을 다시 실행해서 새로 고칩니다.
-
노트북의 하단에, 데이터를 박스로 plot할 셀을 추가합니다:
price = new_pumpkins.Price month = new_pumpkins.Month plt.scatter(price, month) plt.show()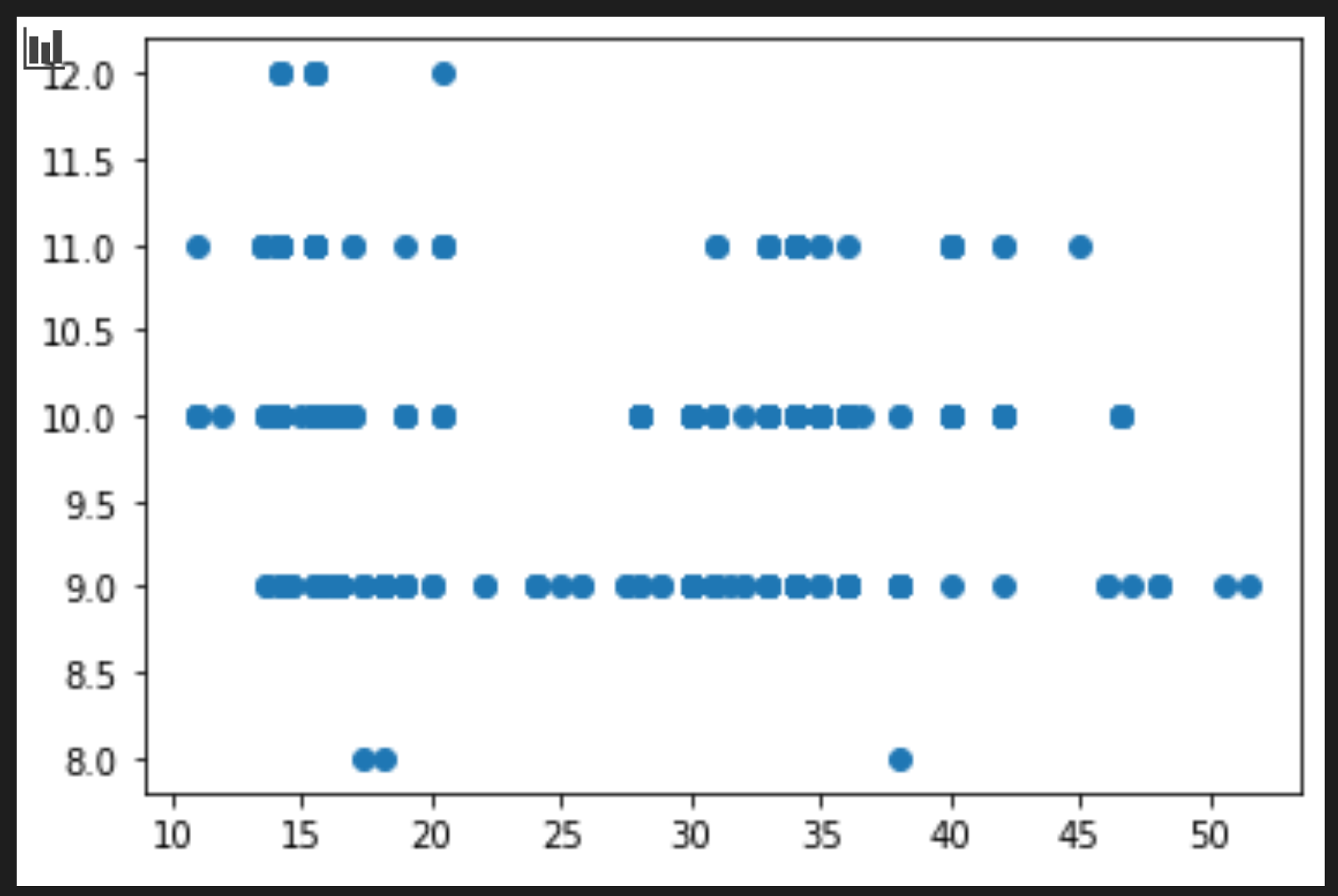
쓸모있는 plot인가요? 어떤 것에 놀랬나요?
주어진 달에 대하여 점의 발산은 데이터에 보여질 뿐이므로 특별히 유용하지 않습니다.
유용하게 만들기
차트에서 유용한 데이터를 보여지게 하려면, 데이터를 어떻게든지 그룹으로 묶어야 합니다. y축이 달을 나타내면서 데이터의 분포를 나타내는 데이터로 plot을 만들어 보겠습니다.
-
그룹화된 바 차트를 만들기 위한 셀을 추가합니다:
new_pumpkins.groupby(['Month'])['Price'].mean().plot(kind='bar') plt.ylabel("Pumpkin Price")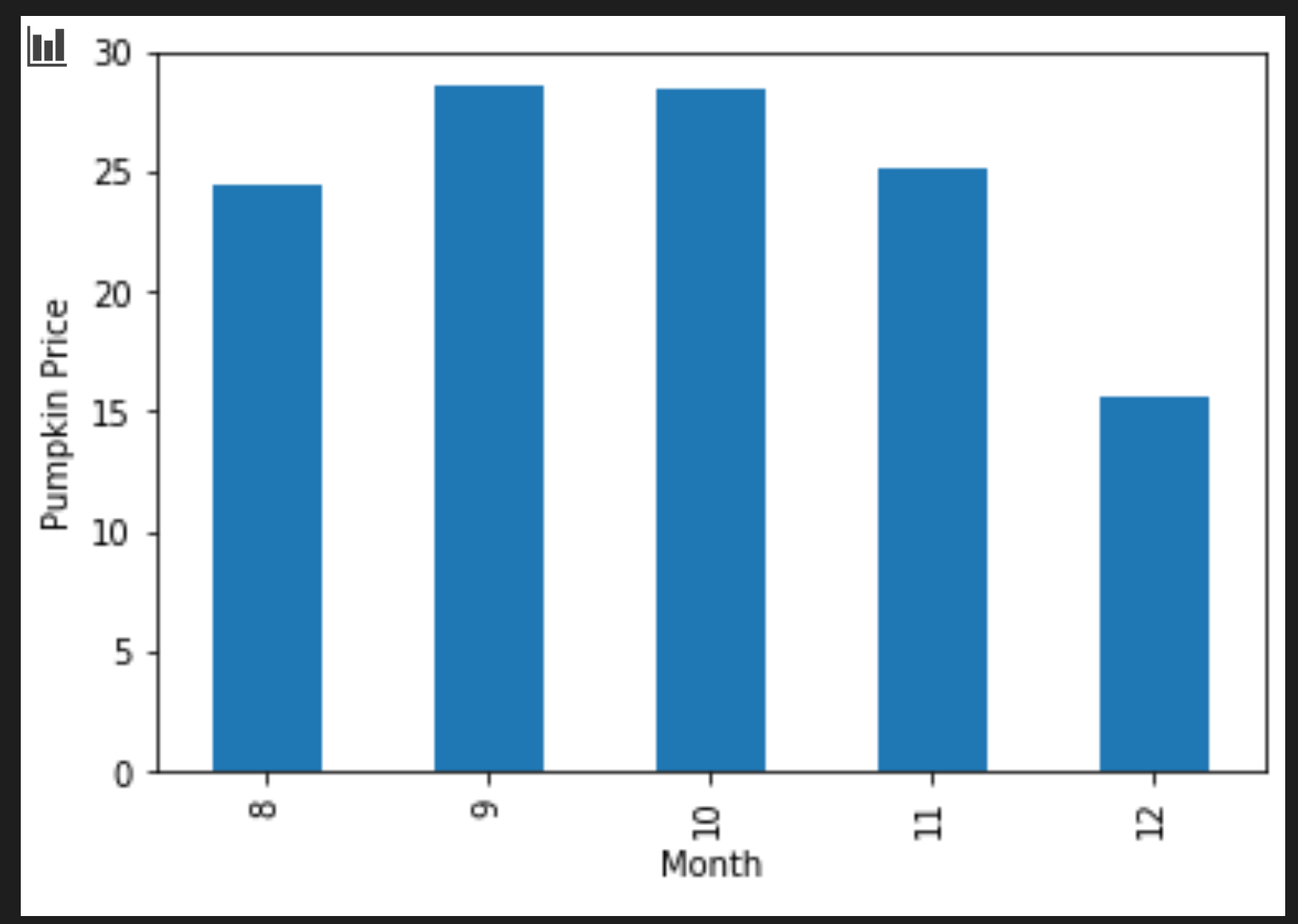
조금 더 유용한 데이터 시각화힙니다! 호박 가격이 가장 높았을 때는 9월과 10월로 보여집니다. 기대하던 목표에 부합하나요? 왜 그렇게 생각하나요?
🚀 도전
Matplotlib에서 제공하는 다양한 시각화 타입을 찾아보세요. regression 문제에 가장 적당한 타입은 무엇인가요?
강의 후 퀴즈
검토 & 자기주도 학습
데이터 시각화하는 많은 방식을 찾아보세요. 사용할 수 있는 다양한 라이브러리 목록을 만들고 2D visualizations vs. 3D visualizations 예시처럼, 주어진 작업의 타입에 적당한 라이브러리를 확인합니다. 어떤 것을 찾았나요?