18 KiB
機械学習における公平さ
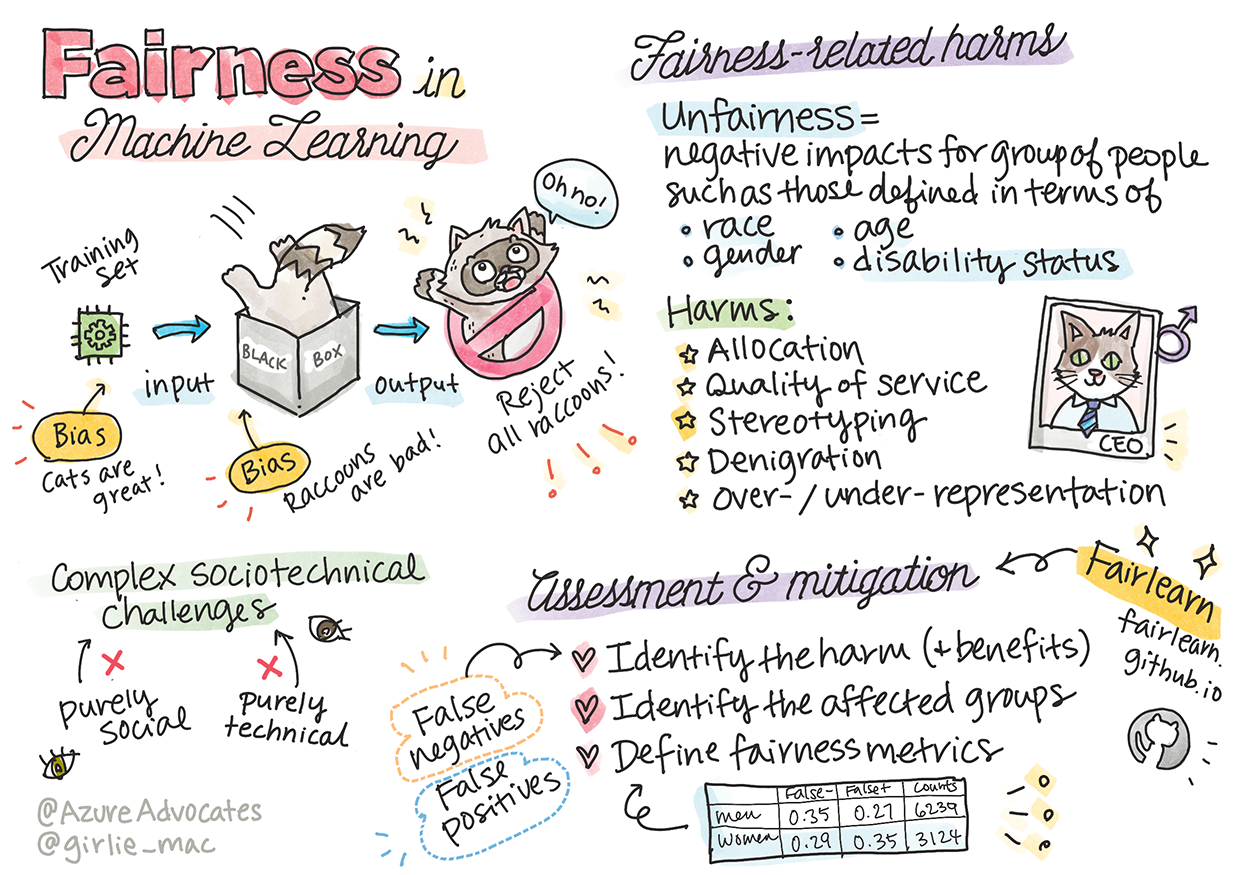
Tomomi Imuraによるスケッチ
Pre-lecture quiz
イントロダクション
このカリキュラムでは、機械学習が私たちの日常生活にどのような影響を与えているかを知ることができます。たった今、医療の診断や不正の検出など、日常の意思決定にシステムやモデルが関わっています。そのため、誰もが公平な結果を得られるようにするためには、これらのモデルがうまく機能することが重要です。
しかし、これらのモデルを構築するために使用しているデータに、人種、性別、政治的見解、宗教などの特定の属性が欠けていたり、そのような属性が偏っていたりすると、何が起こるか想像してみてください。また、モデルの出力が特定の層に有利になるように解釈された場合はどうでしょうか。その結果、アプリケーションはどのような影響を受けるのでしょうか?
このレッスンでは、以下のことを行います:
- 機械学習における公平性の重要性に対する意識を高める。
- 公平性に関連する問題について学ぶ。
- 公平性の評価と緩和について学ぶ。
前提条件
前提条件として、"Responsible AI Principles"のLearn Pathを受講し、このトピックに関する以下のビデオを視聴してください。
こちらのLearning Pathより、責任のあるAIについて学ぶ。

🎥 上の画像をクリックすると動画が表示されます:Microsoftの責任あるAIに対する取り組み
データやアルゴリズムの不公平さ
「データを長く拷問すれば、何でも自白するようになる」 - Ronald Coase
この言葉は極端に聞こえますが、データがどんな結論をも裏付けるように操作できることは事実です。しかし、そのような操作は、時に意図せずに行われることがあります。人間は誰でもバイアスを持っており、自分がいつデータにバイアスを導入しているかを意識的に知ることは難しいことが多いのです。
AIや機械学習における公平性の保証は、依然として複雑な社会技術的課題です。つまり、純粋に社会的な視点や技術的な視点のどちらからも対処できないということです。
公平性に関連した問題
不公平とはどういう意味ですか?不公平とは、人種、性別、年齢、障害の有無などで定義された人々のグループに悪影響を与えること、あるいは、被害を与えることです。
主な不公平に関連する問題は以下のように分類されます。:
- アロケーション。ある性別や民族が他の性別や民族よりも優遇されている場合。
- サービスの質。ある特定のシナリオのためにデータを訓練しても、現実がより複雑な場合にはサービスの質の低下につながります。
- 固定観念。特定のグループにあらかじめ割り当てられた属性を関連させること。
- 誹謗中傷。何かや誰かを不当に批判したり、レッテルを貼ること。
- 過剰表現または過小表現。特定のグループが特定の職業に就いている姿が見られず、それを宣伝し続けるサービスや機能は被害を助長しているという考え。
それでは、いくつか例を見ていきましょう。
アロケーション
ローン申請を審査する仮想的なシステムを考えてみましょう。このシステムでは、他のグループよりも白人男性を優秀な候補者として選ぶ傾向があります。その結果、特定の申請者にはローンが提供されませんでした。
もう一つの例は、大企業が候補者を審査するために開発した実験的な採用ツールです。このツールは、ある性別に関連する言葉を好むように訓練されたモデルを使って、ある性別をシステム的に差別していました。その結果、履歴書に「女子ラグビーチーム」などの単語が含まれている候補者にペナルティを課すものとなっていました。
✅ ここで、上記のような実例を少し調べてみてください。
サービスの質
研究者は、いくつかの市販のジェンダー分類法は、明るい肌色の男性の画像と比較して、暗い肌色の女性の画像では高い不正解率を示したことを発見した。参照
また、肌の色が暗い人を感知できなかったハンドソープディスペンサーの例も悪い意味で有名です。参照
固定観念
機械翻訳には、ステレオタイプな性別観が見られます。「彼はナースで、彼女は医者です。(“he is a nurse and she is a doctor”)」という文をトルコ語に翻訳する際、問題が発生しました。トルコ語は単数の三人称を表す代名詞「o」が1つあるのみで、性別の区別のない言語で、この文章をトルコ語から英語に翻訳し直すと、「彼女はナースで、彼は医者です。(“she is a nurse and he is a doctor”)」というステレオタイプによる正しくない文章になってしまいます。
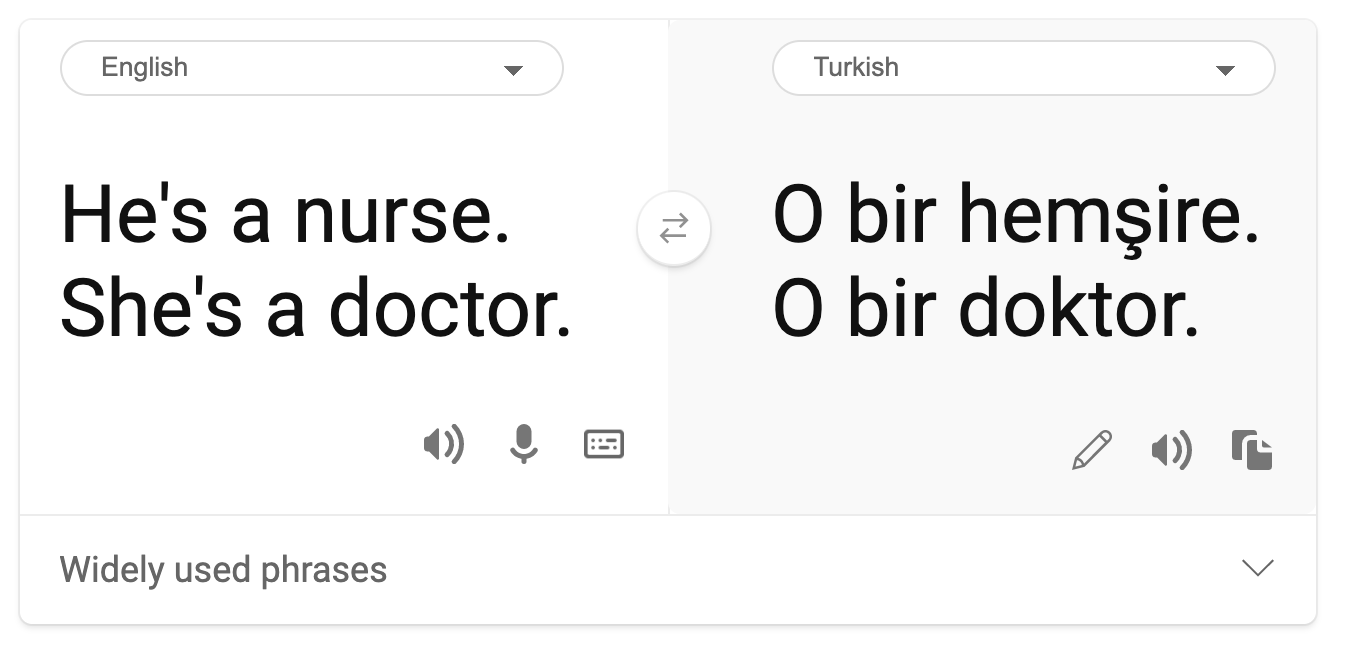
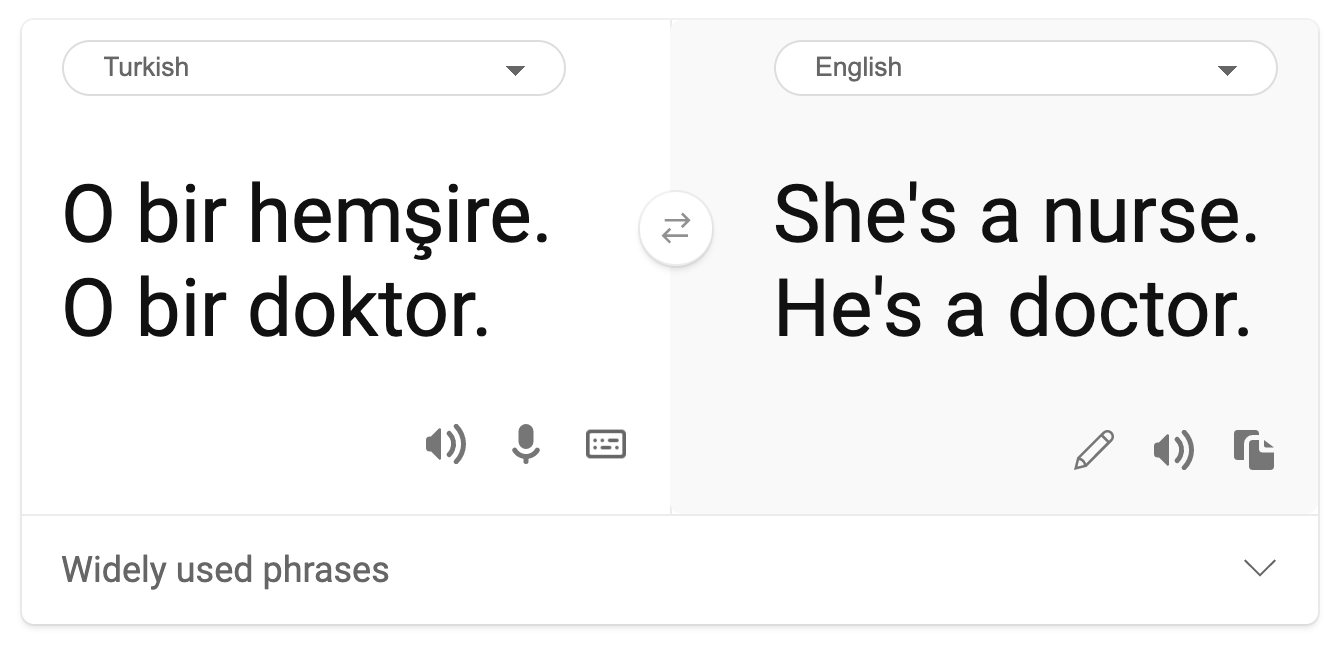
誹謗中傷
画像ラベリング技術により、肌の色が黒い人の画像をゴリラと誤表示したことが有名です。誤表示は、システムが単に間違いをしたというだけでなく、黒人を誹謗中傷するためにこの表現が意図的に使われてきた長い歴史を持っていたため、有害である。

🎥 上の画像をクリックすると動画が表示されます: AI: 自分は女性ではないの? - AIによる人種差別的な誹謗中傷による被害を示すパフォーマンス
過剰表現または過小表現
異常な画像検索の結果はこの問題の良い例です。エンジニアやCEOなど、男性と女性の割合が同じかそれ以上の職業の画像を検索すると、どちらかの性別に大きく偏った結果が表示されるので注意が必要です。

Bing での「CEO」の検索結果は包摂的な結果が表示されています
これらの5つの主要なタイプの問題は、相互に排他的なものではなく、1つのシステムが複数のタイプの害を示すこともあります。さらに、それぞれのケースでは、その重大性が異なります。例えば、ある人に不当に犯罪者のレッテルを貼ることは、画像を誤って表示することよりもはるかに深刻な問題です。しかし、比較的深刻ではない被害であっても、人々が疎外感を感じたり、特別視されていると感じたりすることがあり、その累積的な影響は非常に抑圧的なものになりうることを覚えておくことは重要でしょう。
✅ ディスカッション: いくつかの例を再検討し、異なる害を示しているかどうかを確認してください。
| アロケーション | サービスの質 | 固定観念 | 誹謗中傷 | 過剰表現/過小表現 | |
|---|---|---|---|---|---|
| 採用システムの自動化 | x | x | x | x | |
| 機械翻訳 | |||||
| 写真のラベリング |
不公平の検出
あるシステムが不公平な動作をする理由はさまざまです。例えば、社会的なバイアスが、学習に使われたデータセットに反映されているかもしれないですし、過去のデータに頼りすぎたために、採用の不公平が悪化したかもしれません。あるモデルは、10年間に会社に提出された履歴書のパターンを利用して、男性からの履歴書が大半を占めていたことから、男性の方が適格であると判断しました。
特定のグループに関するデータが不十分であることも、不公平の原因となります。例えば、肌の色が濃い人のデータが少ないために、画像分類において肌の色が濃い人の画像のエラー率が高くなります。
また、開発時の誤った仮定も不公平の原因となります。例えば、人の顔の画像から犯罪を犯す人を予測することを目的とした顔分析システムでは、有害な推測をしてしまうことがあります。その結果、誤った分類をされた人が大きな被害を受けることになりかねません。
モデルを理解し、公平性を構築する
公平性の多くの側面は定量的な指標では捉えられず、公平性を保証するためにシステムからバイアスを完全に取り除くことは不可能ですが、公平性の問題を可能な限り検出し、軽減する責任があります。
機械学習モデルを扱う際には、モデルの解釈可能性を保証し、不公平さを評価・軽減することで、モデルを理解することが重要です。
ここでは、ローン選択の例を使ってケースを切り分け、各要素が予測に与える影響の度合いを把握してみましょう。
評価方法
-
危害(と利益)を特定する。最初のステップは、危害と利益を特定することです。行動や決定が、潜在的な顧客とビジネスそのものの両方にどのような影響を与えるかを考えてみましょう。
-
影響を受けるグループを特定する。どのような害や利益が発生しうるかを理解したら、影響を受ける可能性のあるグループを特定します。これらのグループは、性別、民族、または社会的グループによって定義されるでしょうか。
-
公正さの測定基準を定義する。最後に、状況を改善する際に何を基準にするかの指標を定義します。
有害性(および利益)を特定する
貸与に関連する有害性と利益は何か?偽陰性と偽陽性のシナリオについて考えてみましょう。
偽陰性(認可しないが、Y=1) - この場合、ローンを返済できるであろう申請者が拒否されます。これは、融資が資格のある申請者になされなくなるため、不利な事象となります。
偽陽性(受け入れるが、Y=0) - この場合、申請者は融資を受けたが、最終的には返済不能(デフォルト)になる。その結果、申請者の事例は債権回収会社に送られ、将来のローン申請に影響を与える可能性があります。
影響を受けるグループの特定
次のステップでは、どのグループが影響を受ける可能性があるかを判断します。例えば、クレジットカードの申請の場合、家計の資産を共有している配偶者と比較して、女性の与信限度額は大幅に低くすべきだとモデルが判断するかもしれません。これにより、ジェンダーで定義される層全体が影響を受けることになります。
公正さの測定基準を定義する
あなたは有害性と影響を受けるグループ(この場合は、性別で定義されている)をここまでに特定しました。次に、定量化された要素を使って、その評価基準を分解します。例えば、以下のデータを使用すると、女性の偽陽性率が最も大きく、男性が最も小さいこと、そしてその逆が偽陰性の場合に当てはまることがわかります。
✅ 今後の"クラスタリング"のレッスンでは、この"混同行列"をコードで構築する方法をご紹介します。
| 偽陽性率 | 偽陰性率 | サンプル数 | |
|---|---|---|---|
| 女性 | 0.37 | 0.27 | 54032 |
| 男性 | 0.31 | 0.35 | 28620 |
| どちらにも属さない | 0.33 | 0.31 | 1266 |
この表から、いくつかのことがわかります。まず、データに含まれる男性と女性どちらでもない人が比較的少ないことがわかります。従ってこのデータは歪んでおり、この数字をどう解釈するかに注意が必要です。
今回の場合、3つのグループと2つの指標があります。このシステムがローン申請者であるお客様のグループにどのような影響を与えるかを考えるときにはこれで十分かもしれません。しかし、より多くのグループを定義したい場合は、これをより小さな要約のまとまりに抽出したいと思うかもしれません。そのためには、偽陰性と偽陽性それぞれの最大値の差や最小の比率など、より多くの要素を追加することができます。
✅ 一旦ここで考えてみてください:ローン申請の際に影響を受けそうな他のグループは?
不公平の緩和
不公平を緩和するためには、モデルを探索して様々な緩和モデルを生成し、精度と公平性の間で行うトレードオフを比較して、最も公平なモデルを選択します。
この入門編では、後処理やリダクションのアプローチといったアルゴリズムによる不公平の緩和の詳細については深く触れていませんが、試していきたいツールをここで紹介します。
Fairlearn
FairlearnはオープンソースのPythonパッケージで、システムの公平性を評価し、不公平を緩和することができます。
このツールは、モデルの予測が異なるグループにどのような影響を与えるかを評価し、公平性とパフォーマンスの指標を用いて複数のモデルを比較することを可能にし、二項分類(binary classification)と回帰(regression)における不公平さを緩和するためのアルゴリズムを提供します。
-
FairlearnのGitHubでは、各要素の使用方法を紹介しています。
-
サンプルノートブックを試す。
-
Azure Machine Learningで機械学習モデルの公平性評価を可能にする方法を学ぶ。
-
Azure Machine Learningでサンプルノートブックをチェックして、公平性評価の流れを確認する。
🚀 Challenge
そもそも偏りが生じないようにするためには、次のようなことが必要です。
- システムに携わる人たちの背景や考え方を多様化する。
- 社会の多様性を反映したデータセットに投資する。
- バイアスが発生したときに、それを検知して修正するためのより良い方法を開発する。
モデルの構築や使用において、不公平が明らかになるような現実のシナリオを考えてみてください。他にどのようなことを考えるべきでしょうか?
Post-lecture quiz
Review & Self Study
このレッスンでは、機械学習における公平、不公平の概念の基礎を学びました。
このワークショップを見て、トピックをより深く理解してください:
-
YouTube: AIシステムにおける公平性に関連した被害: Hanna Wallach、Miro Dudikによる、事例、評価、緩和策についてAIシステムにおける公平性に関連した被害: Hanna Wallach、Miro Dudikによる、事例、評価、緩和策について - YouTube
-
MicrosoftのRAIリソースセンター: 責任あるAIリソース – Microsoft AI
-
MicrosoftのFATE研究グループ: AIにおけるFATE: Fairness(公平性), Accountability(説明責任), Transparency(透明性), and Ethics(倫理)- Microsoft Research
Fairlearnのツールキットを調べてみましょう
Azure Machine Learningによる、公平性を確保するためのツールについて読む