11 KiB
Clasificadores de cocina 2
En esta segunda lección de clasificación, explorarás más formas de clasificar datos numéricos. También aprenderás acerca de las ramificaciones para elegir un clasificador en lugar de otro.
Examen previo a la lección
Prerrequisito
Asumimos que has completado las lecciones anteriores y has limpiado el conjunto de datos en tu directorio data llamado cleaned_cuisines.csv en la raíz de este directorio 4-lesson.
Preparación
Hemos cargado tu archivo notebook.ipynb con el conjunto de datos limpio y lo hemos dividido en los dataframes X e Y, listo para el proceso de construcción del modelo.
Un mapa de clasificación
Anteriormente, aprendiste acerca de las distintas opciones que tienes al clasificar los datos usando la hoja de trucos de Microsoft. Scikit-learn ofrece algo similar, pero la hoja de trucos es más granular que puede ayudar a reducir tus estimadores (otro término para clasificadores):
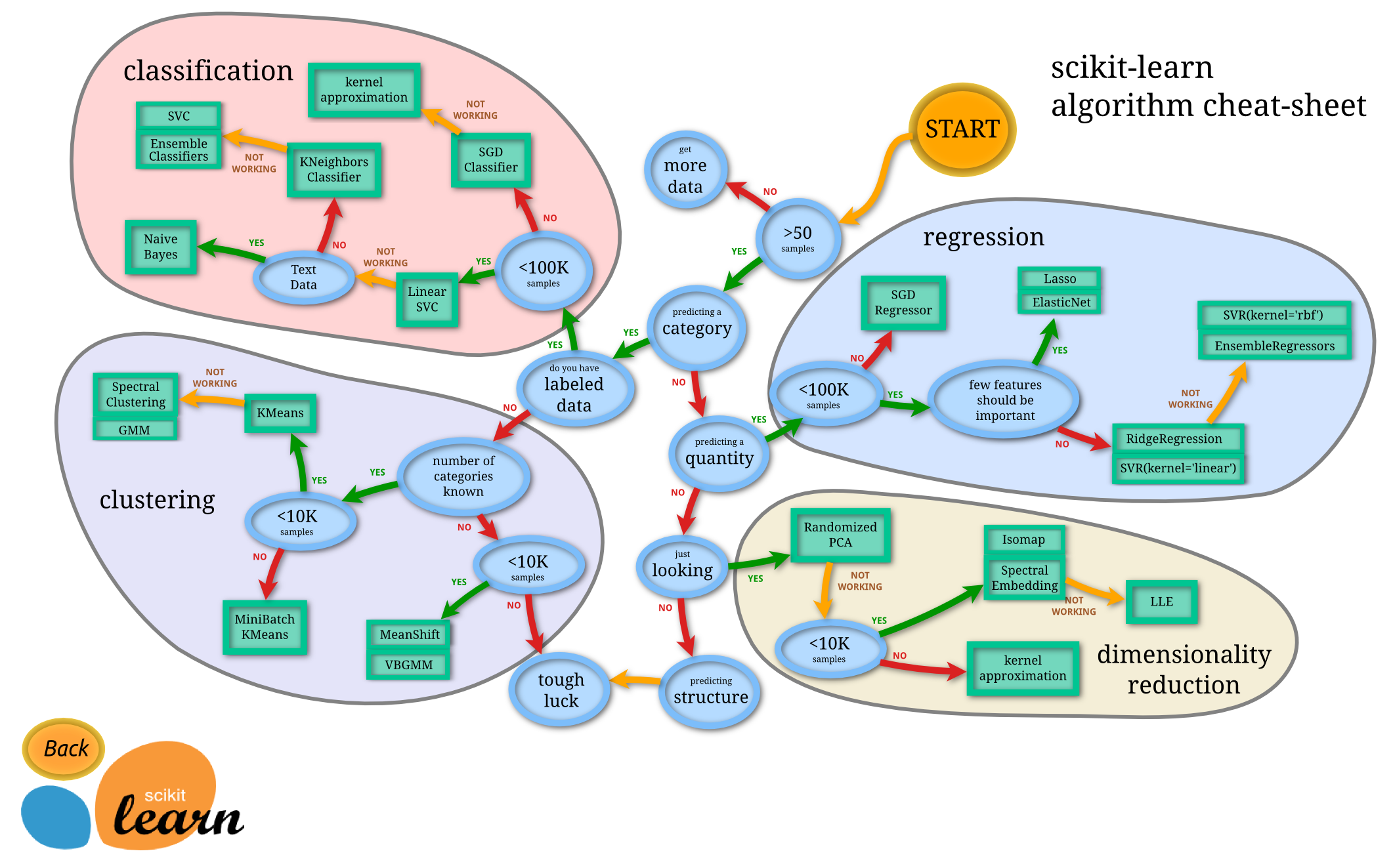
Consejo: Visita este mapa en línea y haz clic en la ruta para leer la documentación.
El plan
Este mapa es muy útil una vez que tengas una compresión clara de tus datos, como puedas 'caminar' junto a sus rutas para una decisión:
- Tenemos >50 muestras
- Queremos predecir una categoría
- Tenemos datos etiquetados
- Tenemos menos de 100K muestras
- ✨ Podemos elegir un SVC lineal
- Si eso no funciona, ya que tenemos datos numéricos
- Podemos probar un ✨ clasificador KNeighbors
- Si eso no funciona, intenta los clasificadores ✨ SVC y ✨ conjunto
- Podemos probar un ✨ clasificador KNeighbors
Este es un camino muy útil a seguir.
Ejercicio - divide los datos
Siguiendo este camino, deberías empezar importando algunas bibliotecas a usar.
-
Importa las bibliotecas necesarias:
from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve import numpy as np -
Divide tus datos de entrenamiento y prueba:
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
Clasificador lineal SVC
El agrupamiento de vectores de soporte (SVC) es un hijo de la familia de máquinas de vectores de soporte de las técnicas de aprendizaje automático (aprende más acerca de estos más adelante). En este método, puedes elegir un 'kernel' para decidir cómo agrupar las etiquetas. El parámetro 'C' se refiere a 'regularization' el cual regula la influencia de los parámetros. El kernel puede ser uno de varios; aquí lo configuramos a 'linear' para asegurar que aprovechamos la clasificación lineal SVC. La probabilidad por defecto es 'false'; aquí lo configuramos a 'true' para reunir estimaciones de probabilidad. Configuramos el estado aleatorio a '0' para revolver los datos para obtener probabilidades.
Ejercicio - aplica SVC lineal
Comienza creando un arreglo de clasificadores. Agregarás progresivamente a este arreglo mientras probamos.
-
Empieza con un SVC lineal:
C = 10 # Create different classifiers. classifiers = { 'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0) } -
Entrena tu modelo usando el SVC lineal e imprime un reporte:
n_classifiers = len(classifiers) for index, (name, classifier) in enumerate(classifiers.items()): classifier.fit(X_train, np.ravel(y_train)) y_pred = classifier.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100)) print(classification_report(y_test,y_pred))El resultado es bastante bueno:
Accuracy (train) for Linear SVC: 78.6% precision recall f1-score support chinese 0.71 0.67 0.69 242 indian 0.88 0.86 0.87 234 japanese 0.79 0.74 0.76 254 korean 0.85 0.81 0.83 242 thai 0.71 0.86 0.78 227 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
Clasificador K-Neighbors
K-neighbors es parte de la familia de "vecinos" de métodos de aprendizaje automático, el cual puede ser usado para el aprendizaje supervisado y no supervisado. En este método, se crea un número predefinido de puntos y se reúnen los datos alrededor de estos puntos de modo que se puedan predecir etiquetas generalizadas para los datos.
Ejercicio - aplica el clasificador K-Neighbors
El clasificador previo era bueno, y funcionó bien con los datos, pero quizá podemos obtener mejor precisión. Prueba el clasificador K-Neighbors.
-
Agrega una línea a tu arreglo de clasificadores (agrega una coma después del elemento Linear SVC):
'KNN classifier': KNeighborsClassifier(C),El resultado es ligeramente peor:
Accuracy (train) for KNN classifier: 73.8% precision recall f1-score support chinese 0.64 0.67 0.66 242 indian 0.86 0.78 0.82 234 japanese 0.66 0.83 0.74 254 korean 0.94 0.58 0.72 242 thai 0.71 0.82 0.76 227 accuracy 0.74 1199 macro avg 0.76 0.74 0.74 1199 weighted avg 0.76 0.74 0.74 1199✅ Aprende acerca de K-Neighbors
Clasificador de vectores de soporte
Los clasificadores de vectores de soporte son parte de la familia de máquinas de vectores de soporte (SVM) de métodos de aprendizaje automático que son usados para las tareas de clasificación y regresión. Los SVMs "asignan ejemplos de entrenamiento a puntos en el espacio" para maximizar la distancia entre dos categorías. Los datos subsecuentes son asignados en este espacio para que su categoría pueda ser predecida.
Ejercicio - aplica un clasificador de vectores de soporte
Intentemos un poco más de precisión con un clasificador de vectores de soporte.
-
Agrega una coma después del elemento K-Neighbors, y luego agrega esta línea:
'SVC': SVC(),¡El resultado es bastante bueno!
Accuracy (train) for SVC: 83.2% precision recall f1-score support chinese 0.79 0.74 0.76 242 indian 0.88 0.90 0.89 234 japanese 0.87 0.81 0.84 254 korean 0.91 0.82 0.86 242 thai 0.74 0.90 0.81 227 accuracy 0.83 1199 macro avg 0.84 0.83 0.83 1199 weighted avg 0.84 0.83 0.83 1199✅ Aprende acerca de los vectores de soporte
Clasificadores de conjuntos
Sigamos el camino hasta el final, aunque la prueba anterior fue bastante buena. Probemos algunos clasificadores de conjuntos, específicamente Random Forest y AdaBoost:
'RFST': RandomForestClassifier(n_estimators=100),
'ADA': AdaBoostClassifier(n_estimators=100)
El resultado es muy bueno, especialmente para Random Forest:
Accuracy (train) for RFST: 84.5%
precision recall f1-score support
chinese 0.80 0.77 0.78 242
indian 0.89 0.92 0.90 234
japanese 0.86 0.84 0.85 254
korean 0.88 0.83 0.85 242
thai 0.80 0.87 0.83 227
accuracy 0.84 1199
macro avg 0.85 0.85 0.84 1199
weighted avg 0.85 0.84 0.84 1199
Accuracy (train) for ADA: 72.4%
precision recall f1-score support
chinese 0.64 0.49 0.56 242
indian 0.91 0.83 0.87 234
japanese 0.68 0.69 0.69 254
korean 0.73 0.79 0.76 242
thai 0.67 0.83 0.74 227
accuracy 0.72 1199
macro avg 0.73 0.73 0.72 1199
weighted avg 0.73 0.72 0.72 1199
✅ Aprende acerca de los clasificadores de conjuntos
Este método de aprendizaje automático "combina las predicciones de varios estimadores base" para mejorar la calidad del modelo. En nuestro ejemplo, usamos Random Trees y AdaBoost.
- Random Forest, un método de promedio, construye un 'bosque' de 'árboles de decisión' infundido con aleatoriedad para evitar sobreajuste. El parámetro n_estimators es configurado a el número de árboles.
- AdaBoost ajusta un clasificador a un conjunto de datos y luego ajusta copias de ese clasificador a el mismo conjunto de datos. Se enfoca en los pesos de los elementos clasificados erróneamente y realiza el ajuste para que el siguiente clasificador lo corrija.
🚀Desafío
Cada una de estas técnicas tiene un gran número de parámetros que puedes modificar. Investiga los parámetros predeterminados de cada uno y piensa en lo que significaría el ajuste de estos parámetros para la calidad del modelo.
Examen posterior a la lección
Revisión y autoestudio
Existe mucha jerga en esta lecciones, ¡así que toma unos minutos para revisar esta lista de términos útiles!