|
|
3 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 3 years ago | |
| README.id.md | 3 years ago | |
| README.it.md | 3 years ago | |
| README.ja.md | 3 years ago | |
| README.ko.md | 3 years ago | |
| README.pt-br.md | 3 years ago | |
| README.zh-cn.md | 3 years ago | |
| assignment.es.md | 3 years ago | |
| assignment.id.md | 3 years ago | |
| assignment.it.md | 3 years ago | |
| assignment.ja.md | 3 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.pt-br.md | 3 years ago | |
| assignment.zh-cn.md | 3 years ago | |
README.zh-cn.md
机器学习中的公平性
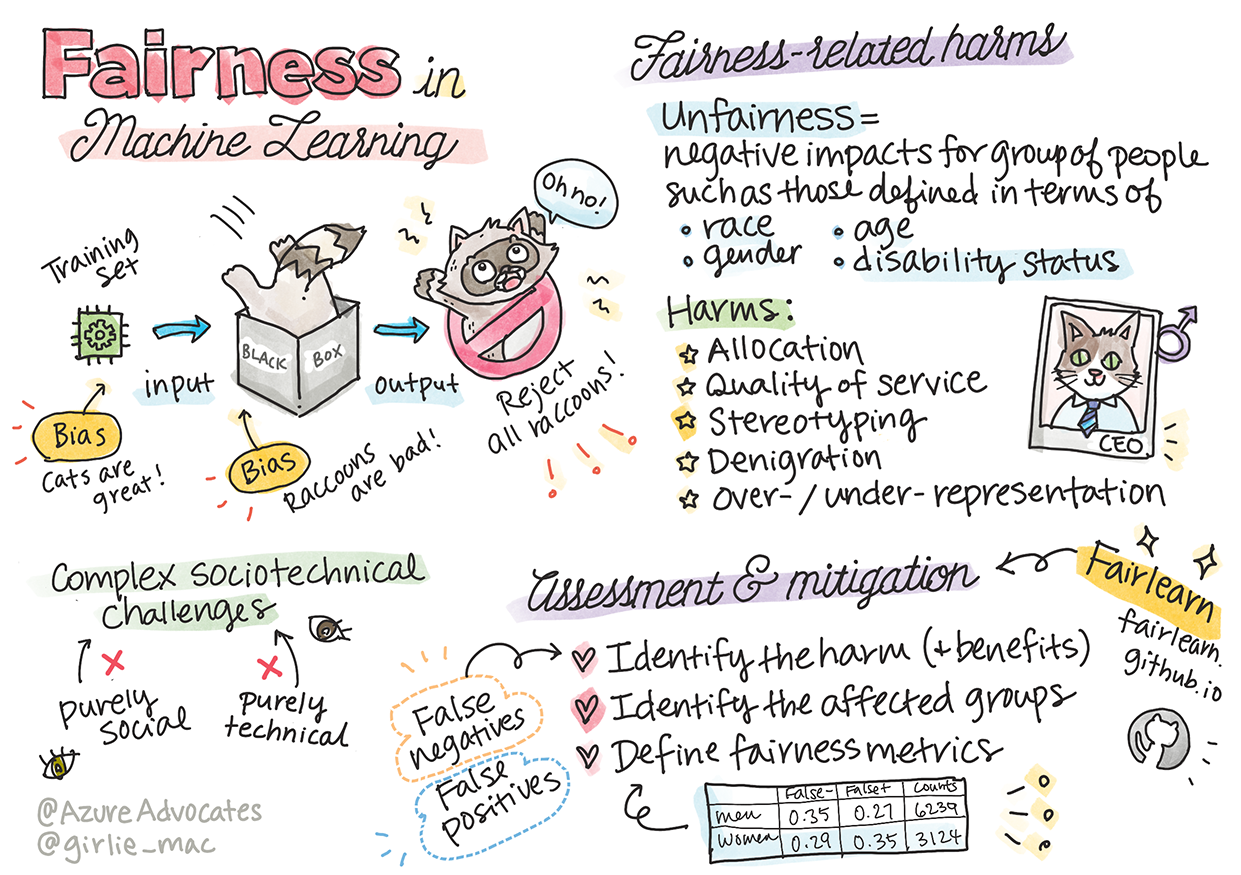
作者 Tomomi Imura
课前测验
介绍
在本课程中,你将开始了解机器学习如何影响我们的日常生活。截至目前,系统和模型已经参与到日常决策任务中,例如医疗诊断或发现欺诈。因此,这些模型运行良好,并为每个人提供公平的结果非常重要。
想象一下,当你用于构建这些模型的数据缺少某些人口统计信息时会发生什么情况,例如种族、性别、政治观点、宗教,或者不成比例地代表了这些人口统计信息。当模型的输出被解释为有利于某些人口统计学的时候呢?申请结果如何?
在本课中,你将:
- 提高你对机器学习中公平的重要性的认识。
- 了解公平相关的危害。
- 了解不公平评估和缓解措施。
先决条件
作为先决条件,请选择“负责任的人工智能原则”学习路径并观看以下主题视频:
按照此学习路径了解有关负责任 AI 的更多信息

🎥 点击上图观看视频:微软对负责任人工智能的做法
数据和算法的不公平性
“如果你折磨数据足够长的时间,它会坦白一切” - Ronald Coase
这种说法听起来很极端,但数据确实可以被操纵以支持任何结论。这种操纵有时可能是无意中发生的。作为人类,我们都有偏见,当你在数据中引入偏见时,往往很难有意识地知道。
保证人工智能和机器学习的公平性仍然是一项复杂的社会技术挑战。这意味着它不能从纯粹的社会或技术角度来解决。
与公平相关的危害
你说的不公平是什么意思?“不公平”包括对一群人的负面影响或“伤害”,例如根据种族、性别、年龄或残疾状况定义的那些人。
与公平相关的主要危害可分为:
- 分配,如果一个性别或种族比另一个更受青睐。
- 服务质量。 如果你针对一种特定场景训练数据,但实际情况要复杂得多,则会导致服务性能不佳。
- 刻板印象。 将给定的组与预先分配的属性相关联。
- 诋毁。 不公平地批评和标记某事或某人。
- 代表性过高或过低。这种想法是,某个群体在某个行业中不被看到,而这个行业一直在提升,这是造成伤害的原因。
让我们来看看这些例子。
分配
考虑一个用于筛选贷款申请的假设系统。该系统倾向于选择白人男性作为比其他群体更好的候选人。因此,某些申请人的贷款被拒。
另一个例子是一家大型公司开发的一种实验性招聘工具,用于筛选应聘者。通过使用这些模型,该工具系统地歧视了一种性别,并被训练为更喜欢与另一种性别相关的词。这导致了对简历中含有“女子橄榄球队”等字样的候选人的不公正地对待。
✅ 做一点研究,找出一个真实的例子
服务质量
研究人员发现,与肤色较浅的男性相比,一些商业性的性别分类工具在肤色较深的女性图像上的错误率更高。参考
另一个臭名昭著的例子是洗手液分配器,它似乎无法感知皮肤黝黑的人。参考
刻板印象
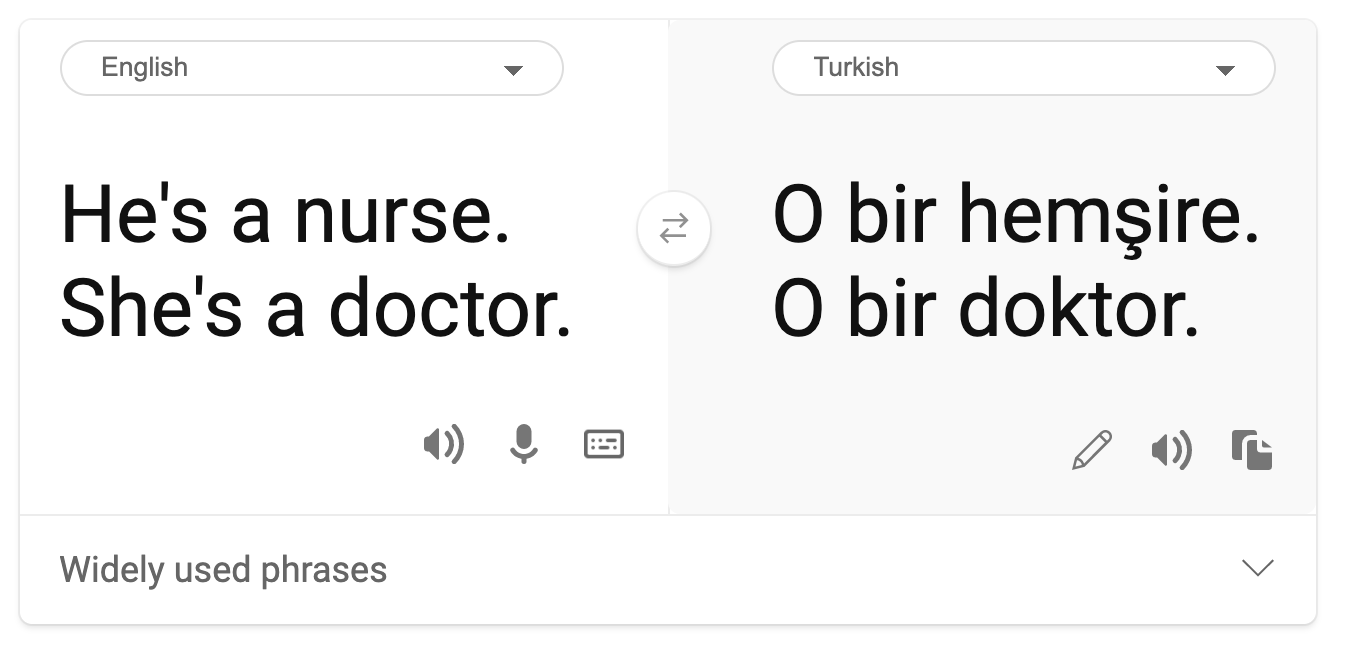
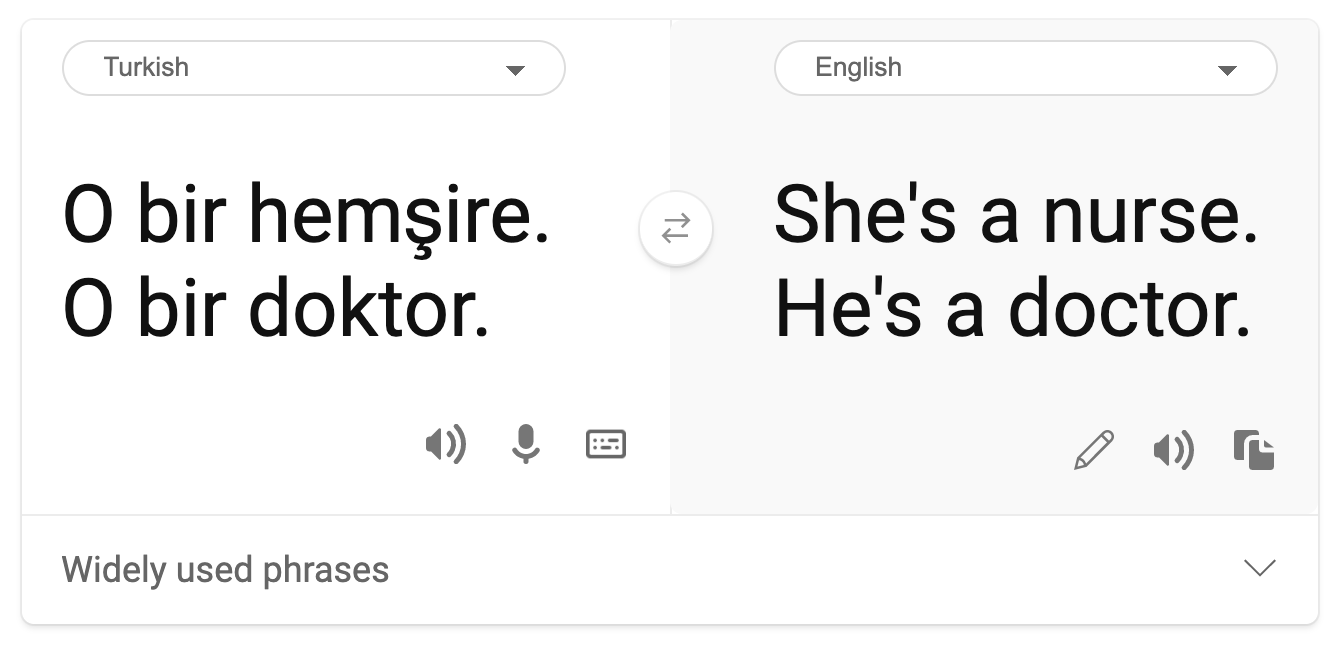
机器翻译中存在着刻板的性别观。在将“他是护士,她是医生”翻译成土耳其语时,遇到了一些问题。土耳其语是一种无性别的语言,它有一个代词“o”来表示单数第三人称,但把这个句子从土耳其语翻译成英语,会产生“她是护士,他是医生”这样的刻板印象和错误。
诋毁
一种图像标记技术,臭名昭著地将深色皮肤的人的图像错误地标记为大猩猩。错误的标签是有害的,不仅仅是因为这个系统犯了一个错误,而且它还特别使用了一个长期以来被故意用来诋毁黑人的标签。

🎥 点击上图观看视频:AI,我不是女人吗 - 一场展示 AI 种族主义诋毁造成的伤害的表演
代表性过高或过低
有倾向性的图像搜索结果就是一个很好的例子。在搜索男性比例等于或高于女性的职业的图片时,比如工程或首席执行官,要注意那些更倾向于特定性别的结果。

在 Bing 上搜索“CEO”会得到非常全面的结果
这五种主要类型的危害不是相互排斥的,一个单一的系统可以表现出一种以上的危害。此外,每个案例的严重程度各不相同。例如,不公平地给某人贴上罪犯的标签比给形象贴上错误的标签要严重得多。然而,重要的是要记住,即使是相对不严重的伤害也会让人感到疏远或被孤立,累积的影响可能会非常压抑。
✅ 讨论:重温一些例子,看看它们是否显示出不同的危害。
| 分配 | 服务质量 | 刻板印象 | 诋毁 | 代表性过高或过低 | |
|---|---|---|---|---|---|
| 自动招聘系统 | x | x | x | x | |
| 机器翻译 | |||||
| 照片加标签 |
检测不公平
给定系统行为不公平的原因有很多。例如,社会偏见可能会反映在用于训练它们的数据集中。例如,过度依赖历史数据可能会加剧招聘不公平。通过使用过去 10 年提交给公司的简历中的模式,该模型确定男性更合格,因为大多数简历来自男性,这反映了过去男性在整个科技行业的主导地位。
关于特定人群的数据不足可能是不公平的原因。例如,图像分类器对于深肤色人的图像具有较高的错误率,因为数据中没有充分代表较深的肤色。
开发过程中做出的错误假设也会导致不公平。例如,旨在根据人脸图像预测谁将犯罪的面部分析系统可能会导致破坏性假设。这可能会对错误分类的人造成重大伤害。
了解你的模型并建立公平性
尽管公平性的许多方面都没有包含在量化公平性指标中,并且不可能从系统中完全消除偏见以保证公平性,但你仍然有责任尽可能多地检测和缓解公平性问题。
当你使用机器学习模型时,通过确保模型的可解释性以及评估和减轻不公平性来理解模型非常重要。
让我们使用贷款选择示例来作为分析案例,以确定每个因素对预测的影响程度。
评价方法
-
识别危害(和好处)。第一步是找出危害和好处。思考行动和决策如何影响潜在客户和企业本身。
-
确定受影响的群体。一旦你了解了什么样的伤害或好处可能会发生,找出可能受到影响的群体。这些群体是按性别、种族或社会群体界定的吗?
-
定义公平性度量。最后,定义一个度量标准,这样你就可以在工作中衡量一些东西来改善这种情况。
识别危害(和好处)
与贷款相关的危害和好处是什么?想想假阴性和假阳性的情况:
假阴性(拒绝,但 Y=1)-在这种情况下,将拒绝有能力偿还贷款的申请人。这是一个不利的事件,因为贷款的资源是从合格的申请人扣留。
假阳性(接受,但 Y=0)-在这种情况下,申请人确实获得了贷款,但最终违约。因此,申请人的案件将被送往一个债务催收机构,这可能会影响他们未来的贷款申请。
确定受影响的群体
下一步是确定哪些群体可能受到影响。例如,在信用卡申请的情况下,模型可能会确定女性应获得比共享家庭资产的配偶低得多的信用额度。因此,由性别定义的整个人口统计数据都会受到影响。
定义公平性度量
你已经确定了伤害和受影响的群体,在本例中,是按性别划分的。现在,使用量化因子来分解它们的度量。例如,使用下面的数据,你可以看到女性的假阳性率最大,男性的假阳性率最小,而对于假阴性则相反。
✅ 在以后关于聚类的课程中,你将看到如何在代码中构建这个“混淆矩阵”
| 假阳性率 | 假阴性率 | 数量 | |
|---|---|---|---|
| 女性 | 0.37 | 0.27 | 54032 |
| 男性 | 0.31 | 0.35 | 28620 |
| 未列出性别 | 0.33 | 0.31 | 1266 |
这个表格告诉我们几件事。首先,我们注意到数据中的未列出性别的人相对较少。数据是有偏差的,所以你需要小心解释这些数字。
在本例中,我们有 3 个组和 2 个度量。当我们考虑我们的系统如何影响贷款申请人的客户群时,这可能就足够了,但是当你想要定义更多的组时,你可能需要将其提取到更小的摘要集。为此,你可以添加更多的度量,例如每个假阴性和假阳性的最大差异或最小比率。
✅ 停下来想一想:还有哪些群体可能会受到贷款申请的影响?
减轻不公平
为了缓解不公平,探索模型生成各种缓解模型,并比较其在准确性和公平性之间的权衡,以选择最公平的模型。
这个介绍性的课程并没有深入探讨算法不公平缓解的细节,比如后处理和减少方法,但是这里有一个你可能想尝试的工具。
Fairlearn
Fairlearn 是一个开源 Python 包,可让你评估系统的公平性并减轻不公平性。
该工具可帮助你评估模型的预测如何影响不同的组,使你能够通过使用公平性和性能指标来比较多个模型,并提供一组算法来减轻二元分类和回归中的不公平性。
-
通过查看 Fairlearn 的 GitHub 了解如何使用不同的组件
-
尝试一些 示例 Notebook.
-
了解Azure机器学习中机器学习模型如何启用公平性评估。
-
看看这些示例 Notebook了解 Azure 机器学习中的更多公平性评估场景。
🚀 挑战
为了防止首先引入偏见,我们应该:
-
在系统工作人员中有不同的背景和观点
-
获取反映我们社会多样性的数据集
-
开发更好的方法来检测和纠正偏差
想想现实生活中的场景,在模型构建和使用中明显存在不公平。我们还应该考虑什么?
课后测验
复习与自学
在本课中,你学习了机器学习中公平和不公平概念的一些基础知识。
观看本次研讨会,深入探讨以下主题:
- YouTube:人工智能系统中与公平相关的危害:示例、评估和缓解 Hanna Wallach 和 Miro Dudik人工智能系统中与公平相关的危害:示例、评估和缓解-YouTube
另外,请阅读:
-
微软RAI资源中心:负责人工智能资源-微软人工智能
-
微软 FATE 研究小组:FATE:AI 中的公平、问责、透明和道德-微软研究院
探索 Fairlearn 工具箱
了解 Azure 机器学习的工具以确保公平性