You can not select more than 25 topics
Topics must start with a letter or number, can include dashes ('-') and can be up to 35 characters long.
2.1 KiB
2.1 KiB
连续山地车
OpenAI Gym 的设计方式是所有环境都提供相同的 API - 即相同的方法 reset、step 和 render,以及相同的抽象动作空间和观察空间。因此,应该可以通过最少的代码更改使相同的强化学习算法适应不同的环境。
山地车环境
山地车环境 包含一辆卡在山谷中的汽车:
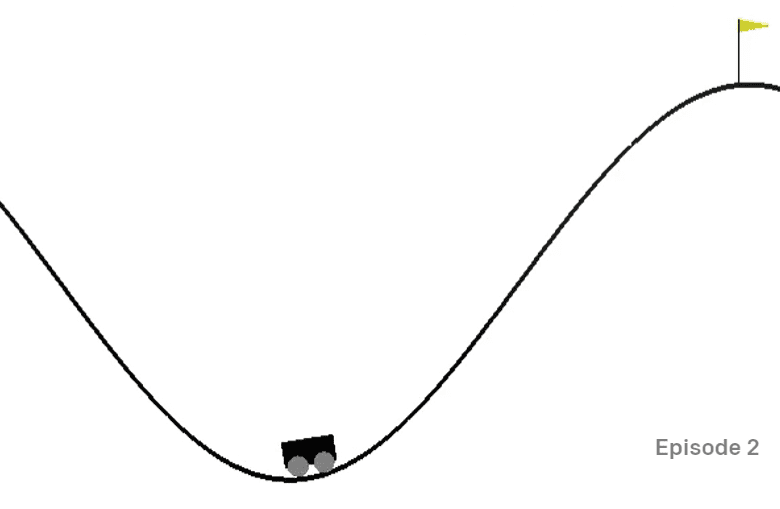
目标是通过在每一步执行以下任一操作来走出山谷并得到旗帜:
| 值 | 含义 |
|---|---|
| 0 | 向左加速 |
| 1 | 不加速 |
| 2 | 向右加速 |
然而,这个问题的主要技巧是,汽车的引擎不够强大,无法一次性翻越这座山。因此,成功的唯一方法是来回驱动以积聚动力。
观察空间仅包含两个值:
| 数量 | 观察 | 最小 | 最大 |
|---|---|---|---|
| 0 | 车位置 | -1.2 | 0.6 |
| 1 | 车速度 | -0.07 | 0.07 |
山地车的奖励系统相当棘手:
- 如果山地车到达山顶的标志(位置 = 0.5)则奖励 0。
- 如果代理的位置小于 0.5,则奖励 -1。
如果汽车位置大于 0.5 或步骤长度大于 200,则游戏终止。
说明
调整我们的强化学习算法来解决山地车问题。从现有的 notebook.ipynb代码开始,替换新环境,更改状态离散化函数,并尝试使现有算法以最少的代码修改进行训练。通过调整超参数来优化结果。
注意:可能需要调整超参数以使算法收敛。
评判标准
| 标准 | 优秀 | 中规中矩 | 仍需努力 |
|---|---|---|---|
| Q-Learning 算法成功地改编自 CartPole 示例,代码修改最少,能够解决 200 步以下得到旗帜的问题。 | 一种新的 Q-Learning 算法已从 Internet 上采用,但有据可查;或采用现有算法,但未达到预期效果 | 学生无法成功采用任何算法,但已经迈出了解决问题的实质性步骤(实现了状态离散化、Q-Table 数据结构等) |