14 KiB
Primeiros passos com Python e Scikit-learn para modelos de regressão
Sketchnote por Tomomi Imura
Questionário inicial
Esta lição está disponível em R!
Introdução
Nestas quatro lições, você irá descobrir como construir modelos de regressão. Discutiremos o que eles são daqui a pouco. Antes de mais nada, certifique-se que tem as ferramentas de que precisa para começar!
Nesta lição, você aprenderá como:
- Configurar seu computador para tarefas de machine learning.
- Trabalhar com Jupyter notebooks.
- Usar Scikit-learn, incluindo como fazer sua instalação.
- Explorar regressão linear com exercícios práticos.
Instalação e configuração

🎥 Clique na imagem acima para assistir o vídeo: usando Python no VS Code (vídeo em inglês).
-
Instale Python. Verifique se você já instalou Python em seu computador. Você usará Python para muitas tarefas de data science (ciência de dados) e machine learning. A maioria dos sistemas de computador já possui Python instalado. Existem Pacotes de Código em Python disponíveis para ajudar na instalação.
Algumas aplicações em Python exigem versões diferentes da linguagem. Portanto, será útil trabalhar com ambiente virtual.
-
Instale o Visual Studio Code. Verifique se já existe o Visual Studio Code instalado em seu computador. Siga essas instruções para instalar o Visual Studio Code com uma instalação básica. Você usará Python no Visual Studio Code neste curso e precisará configurar o Visual Studio Code para isso.
Fique mais confortável em usar Python trabalhando nessa coleção de módulos de aprendizagem.
-
Instale a Scikit-learn, seguindo estas instruções. Visto que você precisa ter certeza que está usando o Python 3, é recomendável usar um ambiente virtual. Note que se você estiver usando essa biblioteca em um M1 Mac, há instruções específicas na página linkada acima.
-
Instale o Jupyter Notebook. Você precisará instalar o pacote Jupyter.
Seu ambiente de ML
Você irá usar notebooks para desenvolver código em Python e criar modelos de machine learning. Esse tipo de arquivo é uma ferramenta comum para data scientists, e pode ser identificado pelo sufixo ou extensão .ipynb.
Notebooks são ambientes interativos que permitem a construção de código de programação e notas de markdown para documentá-lo, o que pode ser muito útil para projetos experimentais ou de pesquisa.
Exercício - Trabalhando com um notebook
Nesta pasta, você encontrará o arquivo notebook.ipynb.
-
Abra notebook.ipynb no Visual Studio Code.
Um servidor Jupyter será iniciado com Python 3+ carregado. Você encontrará áreas do notebook que podem ser executadas (
run). Para executar uma célula de código, basta clicar no ícone que parece um botão play ▶. -
Adicione uma célula de markdown (ícone
md) e escreva o texto: "# Boas-vindas ao seu notebook" (Welcome to your Notebook).Em seguida, adicionaremos algum código em Python.
-
Crie e escreva print('hello notebook') numa célula de código.
-
Clique no ícone ▶ para executar o código.
O resultado ficará assim:
hello notebook
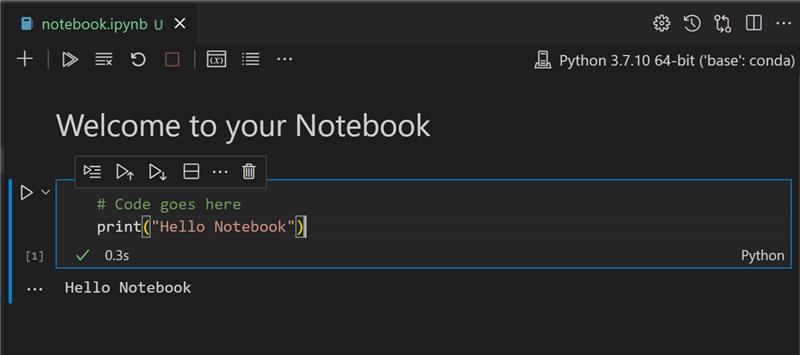
Você pode adicionar comentários para documentar seu notebook.
✅ Pense por um momento em como o ambiente de uma pessoa desenvolvedora web difere do ambiente para data scientists.
Scikit-learn instalado e funcionando
Agora que Python está funcionando em seu ambiente local e você está mais confortável com Jupyter notebooks, vamos nos familizar com a Scikit-learn (a pronúncia de sci é a mesma do verbo sair conjugado na forma sai). Scikit-learn fornece uma API abrangente para te ajudar com tarefas de ML.
De acordo com o seu website, "Scikit-learn é uma bibilioteca de código aberto para machine learning que suporta aprendizado supervisionado e não supervisionado. Também fornece várias ferramentas para ajuste de modelo, processamento de dados, seleção e validação de modelo, etc."
Nesse curso, você irá usar a Scikit-learn e outras ferramentas para construir modelos de machine learning para fazer as chamadas tarefas "tradicionais" de machine learning. Nós evitamos usar neural networks (redes neurais) e deep learning (aprendizagem profunda) por que serão abordadas de uma forma mais completa no curso de "AI para iniciantes".
Scikit-learn facilita a construção e validação de modelos. O foco principal é no uso de dados numéricos mas também contém vários conjuntos de dados prontos para serem usados como ferramenta de estudo. Também possui modelos pré-construídos para os alunos experimentarem. Vamos explorar o processo de carregar dados predefinidos e usar um modelo com estimador integrado com a Scikit-learn e alguns dados básicos.
Exercício - Seu primeiro notebook Scikit-learn
Este tutorial foi inspirado pelo exemplo de regressão linear do site da Scikit-learn.
No arquivo notebook.ipynb, limpe todas as células clicando no ícone que parece uma lata de lixo 🗑️.
Nesta seção, você irá trabalhar com um pequeno conjunto de dados sobre diabetes que foi produzido para a Scikit-learn com fins de aprendizagem. Imagine que você queira testar um tratamento para pessoas diabéticas. Modelos de machine learning podem te ajudar a escolher quais pacientes irão responder melhor ao tratamento, baseado em combinações de variáveis. Mesmo um modelo de regressão simples, quando visualizado, pode mostrar informações sobre variáveis que ajudarão a organizar ensaios clínicos teóricos.
✅ Existem muitos tipos de métodos de regressão, e a escolha dentre eles dependerá da resposta que você procura. Se você quer prever a altura provável de uma pessoa de uma determinada idade, você deve usar a regressão linear, pois está sendo usado um valor numérico. Se você quer descobrir se um tipo de cozinha pode ser considerado vegano ou não, isso está relacionado a uma atribuição de categoria, então usa-se a regressão logística. Você irá aprender mais sobre regressão logística em breve. Pense um pouco nas questões que aparecem com os dados que você tem e qual desses métodos seria mais apropriado usar.
Vamos começar a tarefa.
Importe as bibliotecas
Para esta tarefa nós importaremos algumas bibliotecas:
- matplotlib. É uma ferramenta gráfica que usaremos para criar um gráfico de linha.
- numpy. Numpy é uma biblioteca útil que lida com dados numéricos em Python.
- sklearn. Essa é a bilioteca Scikit-learn.
Importe essas bibliotecas pois te ajudarão na tarefa.
-
Para importar você pode usar o código abaixo:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionAcima, você está importando
matplottlib,numpye tambémdatasets,linear_modelemodel_selectiondasklearn. A funçãomodel_selectioné usada para dividir os dados em conjuntos de dados de treinamento e teste.
O conjunto de dados sobre diabetes
O conjunto de dados sobre diabetes inclui 442 exemplos de dados sobre diabetes, com 10 variáveis de características, algumas delas incluem:
- age: idade em anos
- bmi (body mass index): índice de massa corporal
- bp (blood pressure): média de pressão sanguínea
- s1 tc: Células T (um tipo de glóbulo branco)
✅ Esse conjunto de dados inclui o conceito de "sexo" como variável de característica importante no contexto de diabetes. Muitos conjuntos de dados médicos incluem tipos de classificação binária. Pense um pouco sobre como categorizações como essa podem excluir partes de uma população dos tratamentos.
Agora, carregue os dados X e y.
🎓 Lembre-se que esse é um processo de aprendizado supervisionado, portanto, precisamos de um alvo 'y'.
Em uma célula de código, carregue o conjunto de dados sobre diabetes chamando a função load_diabetes(). O parâmetro return_X_y=True indica que X será uma matriz de dados e y é o alvo da regressão.
-
Adicione alguns comandos print para mostrar a forma da matriz e seu primeiro elemento:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])A função retorna uma estrutura chamada tupla. Na primeira linha, os dois primeiros valores da tupla são atribuidos a
Xey, respectivamente. Saiba mais sobre tuplas.Você pode observar que os dados possuem 442 elementos divididos em matrizes de 10 elementos:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Pense sobre a relação entre os dados e o alvo da regressão. Regressão linear sugere a relação entre a característica X e a característica alvo y. Você pode achar o alvo para o conjunto de dados sobre diabetes na documentação? Conhecendo o alvo, o que este conjunto de dados demonstra?
-
Em seguida, selecione uma parte do conjunto de dados para plotar em um gráfico, colocando-o em uma nova matriz usando a função
newaxisda numpy. Iremos usar regressão linear para gerar uma linha entre os valores do conjunto de dados, de acordo com o padrão que ela é definida.X = X[:, np.newaxis, 2]✅ Você pode adicionar comandos print para imprimir e visualizar os dados e verificar seus formatos.
-
Agora que os dados estão prontos para serem plotados, podemos usar uma máquina para ajudar a determinar a divisão lógica entre os dados no conjunto de dados. Para isso, é necessário dividir os dados (X) e o alvo (y) em conjuntos de teste e treinamento e a Scikit-learn oferece uma maneira de fazer isso.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Seu modelo está pronto para ser treinado! Carregue o modelo de regressão linear e treine-o usando seus conjuntos de treinamento X e Y usando a função
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()é uma função que aparece em muitas biblioteas de ML, como a TensorFlow. -
Por fim, faça uma previsão com seus dados de teste, usando a função
predict(). Isso será usado para traçar uma linha entre os grupos de dados.y_pred = model.predict(X_test) -
Chegou a hora de mostrar os resultados em um gráfico. Matplotlib é a ferramenta perfeita para essa tarefa. Crie um gráfico de dispersão (
scatter) de todos os dados de teste de X e y, e use a previsão feita para traçar no lugar mais adequado, entre os grupos de dados do modelo.plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()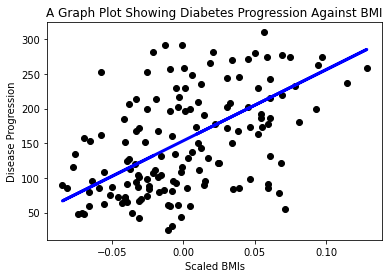
✅ Observe o que está acontecendo. Uma linha reta está atravessando os pequenos pontos de dados, mas o que significa isso? Você consegue ver como pode usar essa linha para prever onde um ponto de dados novo ficaria em relação ao eixo y deste gráfico? Tente colocar em palavras o uso prático desse modelo.
Parabéns, usando um conjunto de dados, você construiu seu primeiro modelo de regressão linear, pediu que ele fizesse uma previsão e a mostrou em forma de gráfico!
🚀Desafio
Plote uma variável diferente desse mesmo conjunto de dados. Dica: edite a linha: X = X[:, np.newaxis, 2]. Dado o conjunto de dados alvo, o que pode ser descoberto sobre o progresso da diabetes como uma doença?
Questionário para fixação
Revisão e Auto Aprendizagem
Neste tutorial, você trabalhou com regressão linear simples, ao invés de regressão univariada ou múltipla. Leia sobre as diferença desses métodos, ou assista esse vídeo.
Leia mais sobre o conceito de regressão e pense sobre os tipos de questões que podem ser respondidas usando essa técnica. Faça esse tutorial para aprender mais.