17 KiB
Scikit-learnを用いた回帰モデルの構築: 回帰を行う2つの方法
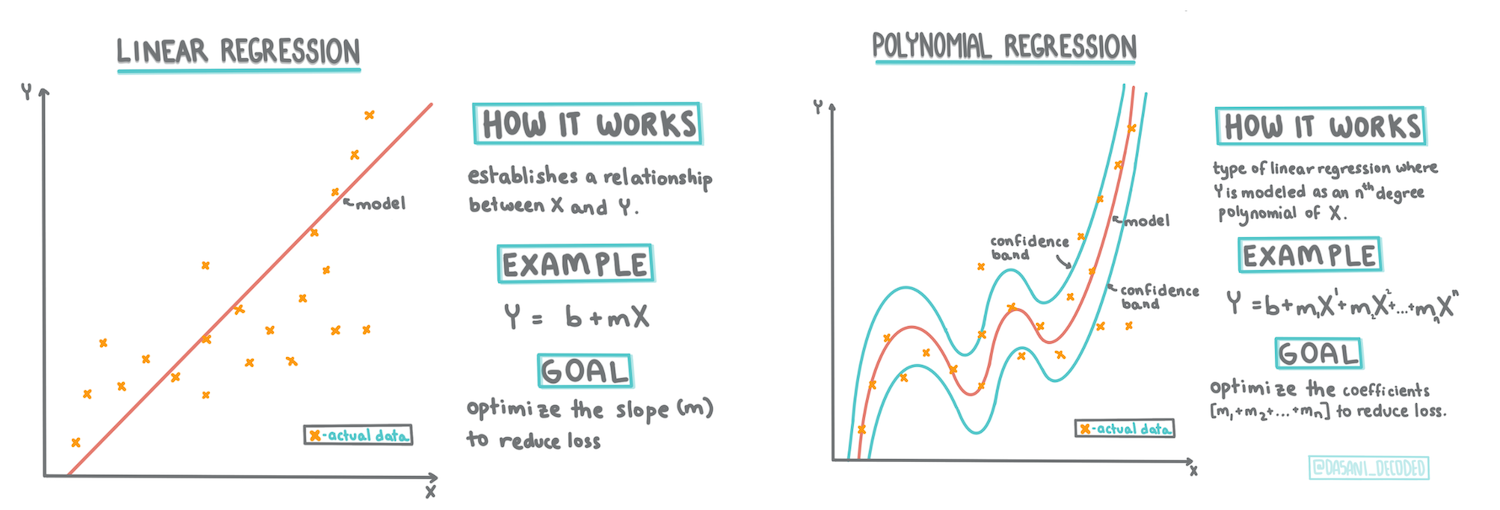
Dasani Madipalli によるインフォグラフィック
講義前のクイズ
イントロダクション
これまで、このレッスンで使用するカボチャの価格データセットから集めたサンプルデータを使って、回帰とは何かを探ってきました。また、Matplotlibを使って可視化を行いました。
これで、MLにおける回帰をより深く理解する準備が整いました。このレッスンでは、2種類の回帰について詳しく説明します。基本的な線形回帰 (basic linear regression)と多項式回帰 (polynomial regression)の2種類の回帰について、その基礎となる数学を学びます。
このカリキュラムでは、最低限の数学の知識を前提とし、他の分野の学生にも理解できるようにしていますので、理解を助けるためのメモ、🧮吹き出し、図などの学習ツールをご覧ください。
事前確認
ここでは、パンプキンデータの構造について説明しています。このレッスンの_notebook.ipynb_ファイルには、事前に読み込まれ、整形されたデータが入っています。このファイルでは、カボチャの価格がブッシェル単位で新しいデータフレームに表示されています。 これらのノートブックを、Visual Studio Codeのカーネルで実行できることを確認してください。
準備
忘れてはならないのは、データを読み込んだら問いかけを行うことです。
- カボチャを買うのに最適な時期はいつですか?
- ミニカボチャ1ケースの価格はどのくらいでしょうか?
- 半ブッシェルのバスケットで買うべきか、1 1/9ブッシェルの箱で買うべきか。
データを掘り下げていきましょう。
前回のレッスンでは、Pandasのデータフレームを作成し、元のデータセットの一部を入力して、ブッシェル単位の価格を標準化しました。しかし、この方法では、約400のデータポイントしか集めることができず、しかもそれは秋の期間のものでした。
このレッスンに付属するノートブックで、あらかじめ読み込んでおいたデータを見てみましょう。データが事前に読み込まれ、月毎のデータが散布図として表示されています。データをもっと綺麗にすることで、データの性質をもう少し知ることができるかもしれません。
線形回帰
レッスン1で学んだように、線形回帰の演習では、以下のような線を描けるようになることが目標です。
- 変数間の関係を示す。
- 予測を行う。 新しいデータポイントが、その線のどこに位置するかを正確に予測することができる。
このような線を描くことは、最小二乗回帰 (Least-Squares Regression) の典型的な例です。「最小二乗」という言葉は、回帰線を囲むすべてのデータポイントとの距離が二乗され、その後加算されることを意味しています。理想的には、最終的な合計ができるだけ小さくなるようにします。これはエラーの数、つまり「最小二乗」の値を小さくするためです。
これは、すべてのデータポイントからの累積距離が最小となる直線をモデル化したいためです。また、方向ではなく大きさに注目しているので、足す前に項を二乗します。
🧮 Show me the math
この線は、line of best fit と呼ばれ、方程式 で表すことができます。
Y = a + bX
Xは「説明変数」です。Yは「目的変数」です。aは切片でbは直線の傾きを表します。X=0のとき、Yの値は切片aとなります。
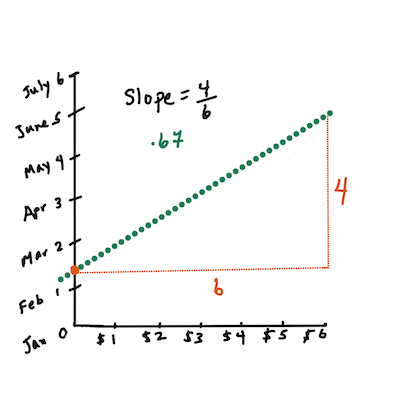
はじめに、傾き
bを計算してみます。Jen Looper によるインフォグラフィック。カボチャのデータに関する最初の質問である、「月毎のブッシェル単位でのカボチャの価格を予測してください」で言い換えてみると、
Xは価格を、Yは販売された月を表しています。
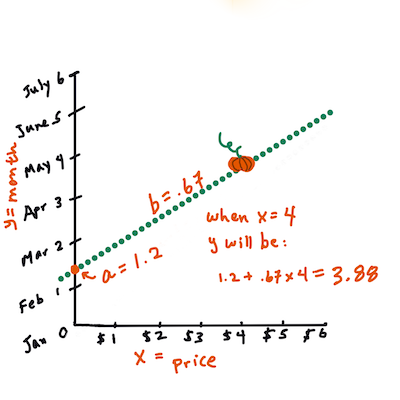
Yの値を計算してみましょう。$4前後払っているなら、4月に違いありません!Jen Looper によるインフォグラフィック。
直線を計算する数学は、直線の傾きを示す必要がありますが、これは切片、つまり「X = 0」のときに「Y」がどこに位置するかにも依存します。
これらの値の計算方法は、Math is Fun というサイトで見ることができます。また、this Least-squares calculator では、値が線にどのような影響を与えるかを見ることができます。
相関関係
もう一つの理解すべき用語は、与えられたXとYの変数間の相関係数 (Correlation Coefficient) です。散布図を使えば、この係数をすぐに可視化することができます。データポイントがきれいな直線上に散らばっているプロットは、高い相関を持っていますが、データポイントがXとYの間のあらゆる場所に散らばっているプロットは、低い相関を持っています。
良い線形回帰モデルとは、最小二乗法によって求めた回帰線が高い相関係数 (0よりも1に近い)を持つものです。
✅ このレッスンのノートを開いて、「都市と価格」の散布図を見てみましょう。散布図の視覚的な解釈によると、カボチャの販売に関する「都市」と「価格」の関連データは、相関性が高いように見えますか、それとも低いように見えますか?
回帰に用いるデータの準備
この演習の背景にある数学を理解したので、回帰モデルを作成して、どのパッケージのカボチャの価格が最も高いかを予測できるかどうかを確認してください。休日のパンプキンパッチ用にパンプキンを購入する人は、パッチ用のパンプキンパッケージの購入を最適化するために、この情報を必要とするかもしれません。
ここではScikit-learnを使用するので、手作業で行う必要はありません。レッスンノートのメインのデータ処理ブロックに、Scikit-learnのライブラリを追加して、すべての文字列データを自動的に数字に変換します。
from sklearn.preprocessing import LabelEncoder
new_pumpkins.iloc[:, 0:-1] = new_pumpkins.iloc[:, 0:-1].apply(LabelEncoder().fit_transform)
new_pumpkinsデータフレームを見ると、すべての文字列が数値になっているのがわかります。これにより、人が読むのは難しくなりましたが、Scikit-learnにとってはとても分かりやすくなりました。 これで、回帰に最も適したデータについて、(散布図を見ただけではなく)より高度な判断ができるようになりました。
良い予測モデルを構築するために、データの2点間に良い相関関係を見つけようとします。その結果、「都市」と「価格」の間には弱い相関関係しかないことがわかりました。
print(new_pumpkins['City'].corr(new_pumpkins['Price']))
0.32363971816089226
しかし、パッケージと価格の間にはもう少し強い相関関係があります。これは理にかなっていると思いますか?通常、箱が大きければ大きいほど、価格は高くなります。
print(new_pumpkins['Package'].corr(new_pumpkins['Price']))
0.6061712937226021
このデータに対する良い質問は、次のようになります。「あるカボチャのパッケージの価格はどのくらいになるか?」
この回帰モデルを構築してみましょう!
線形モデルの構築
モデルを構築する前に、もう一度データの整理をしてみましょう。NULLデータを削除し、データがどのように見えるかをもう一度確認します。
new_pumpkins.dropna(inplace=True)
new_pumpkins.info()
そして、この最小セットから新しいデータフレームを作成し、それを出力します。
new_columns = ['Package', 'Price']
lin_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns')
lin_pumpkins
Package Price
70 0 13.636364
71 0 16.363636
72 0 16.363636
73 0 15.454545
74 0 13.636364
... ... ...
1738 2 30.000000
1739 2 28.750000
1740 2 25.750000
1741 2 24.000000
1742 2 24.000000
415 rows × 2 columns
-
これで、XとYの座標データを割り当てることができます。
X = lin_pumpkins.values[:, :1] y = lin_pumpkins.values[:, 1:2]
✅ ここでは何をしていますか? Pythonのスライス記法 を使って、Xとyの配列を作成しています。
-
次に、回帰モデル構築のためのルーチンを開始します。
from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) lin_reg = LinearRegression() lin_reg.fit(X_train,y_train) pred = lin_reg.predict(X_test) accuracy_score = lin_reg.score(X_train,y_train) print('Model Accuracy: ', accuracy_score)相関関係があまり良くないので、生成されたモデルもあまり正確ではありません。
Model Accuracy: 0.3315342327998987 -
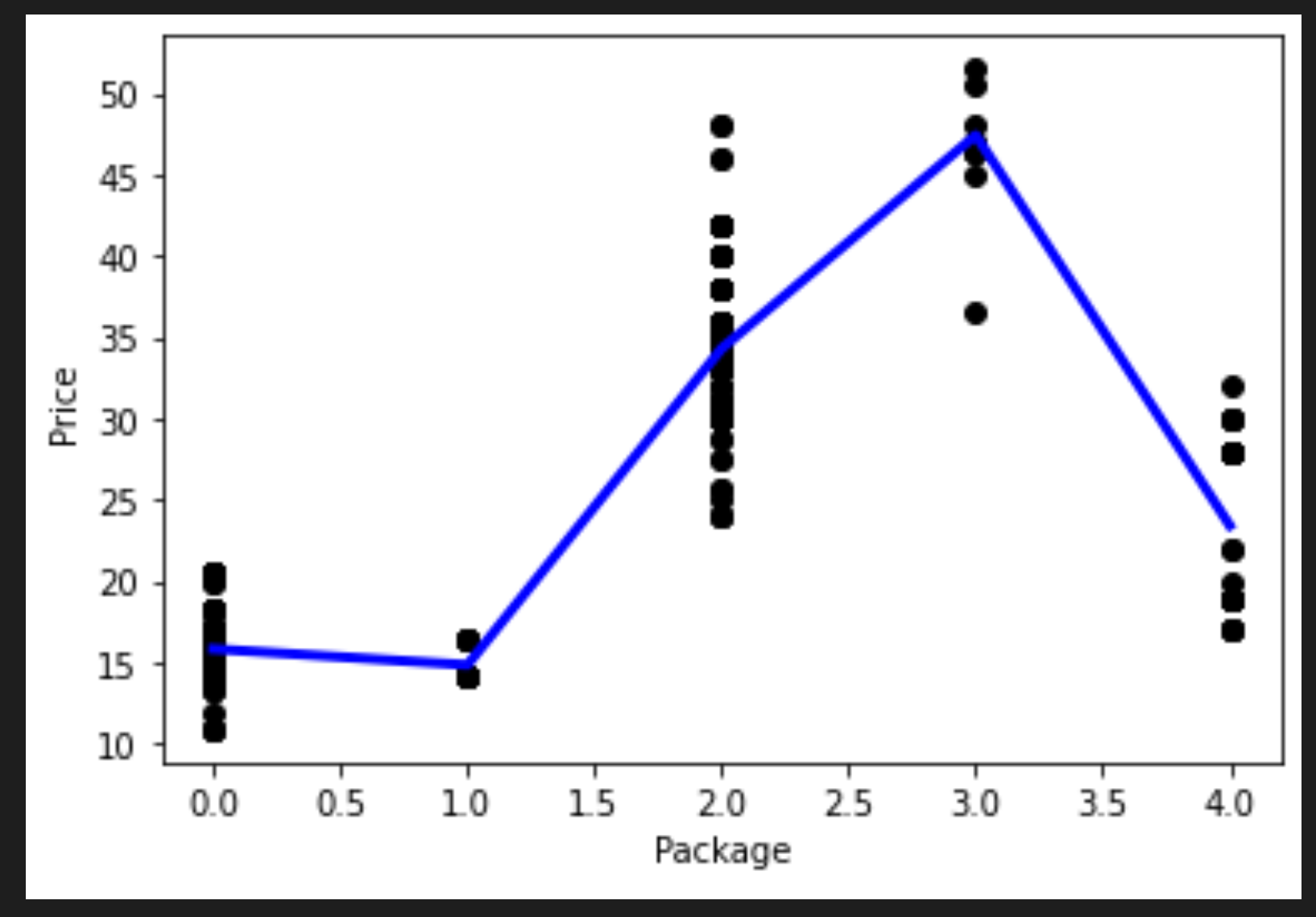
今回の過程で描かれた線を可視化します。
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, pred, color='blue', linewidth=3) plt.xlabel('Package') plt.ylabel('Price') plt.show()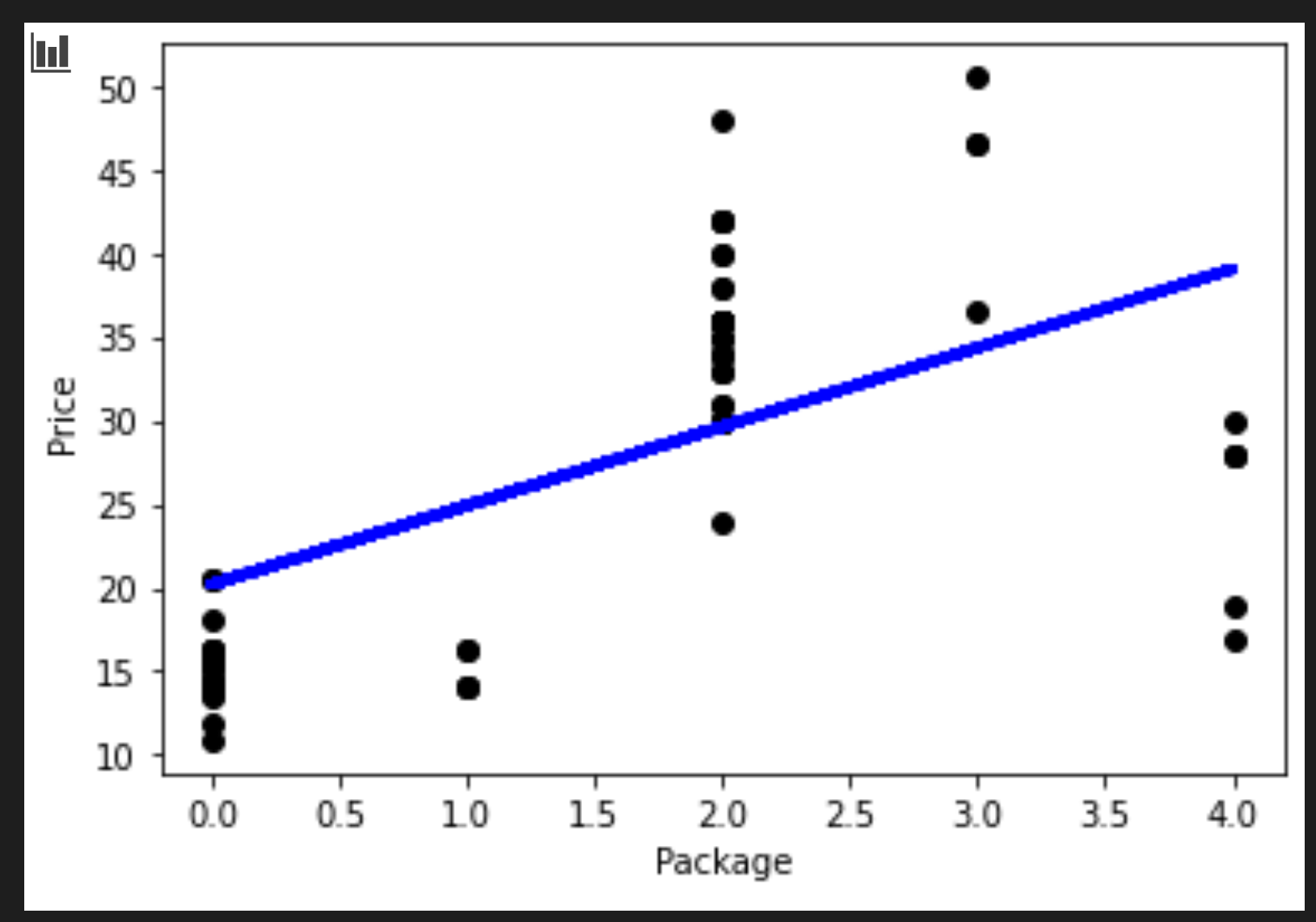
-
架空の値に対してモデルをテストする。
lin_reg.predict( np.array([ [2.75] ]) )この架空の値に対して、以下の価格が返されます。
array([[33.15655975]])
回帰の線が正しく引かれていれば、その数字は理にかなっています。
🎃 おめでとうございます!あなたは、数種類のカボチャの価格を予測するモデルを作成しました。あなたの休日のパンプキンパッチは美しいものになるでしょう。でも、もっと良いモデルを作れるかもしれません。
多項式回帰
線形回帰のもう一つのタイプは、多項式回帰です。時には変数の間に直線的な関係 (カボチャの量が多いほど、価格は高くなる)があることもありますが、これらの関係は、平面や直線としてプロットできないこともあります。
✅ 多項式回帰を使うことができるデータのさらにいくつかの例 を示します。
先ほどの散布図の「品種」と「価格」の関係をもう一度見てみましょう。この散布図は、必ずしも直線で分析しなければならないように見えますか?そうではないかもしれません。このような場合は、多項式回帰を試してみましょう。
✅ 多項式とは、1つ以上の変数と係数で構成される数学的表現である。
多項式回帰では、非線形データをよりよく適合させるために曲線を作成します。
-
元のカボチャのデータの一部を入力したデータフレームを作成してみましょう。
new_columns = ['Variety', 'Package', 'City', 'Month', 'Price'] poly_pumpkins = new_pumpkins.drop([c for c in new_pumpkins.columns if c not in new_columns], axis='columns') poly_pumpkins
データフレーム内のデータ間の相関関係を視覚化するには、「coolwarm」チャートで表示するのが良いでしょう。
-
Background_gradient()メソッドの引数にcoolwarmを指定して使用します。corr = poly_pumpkins.corr() corr.style.background_gradient(cmap='coolwarm')
このコードはヒートマップを作成します。
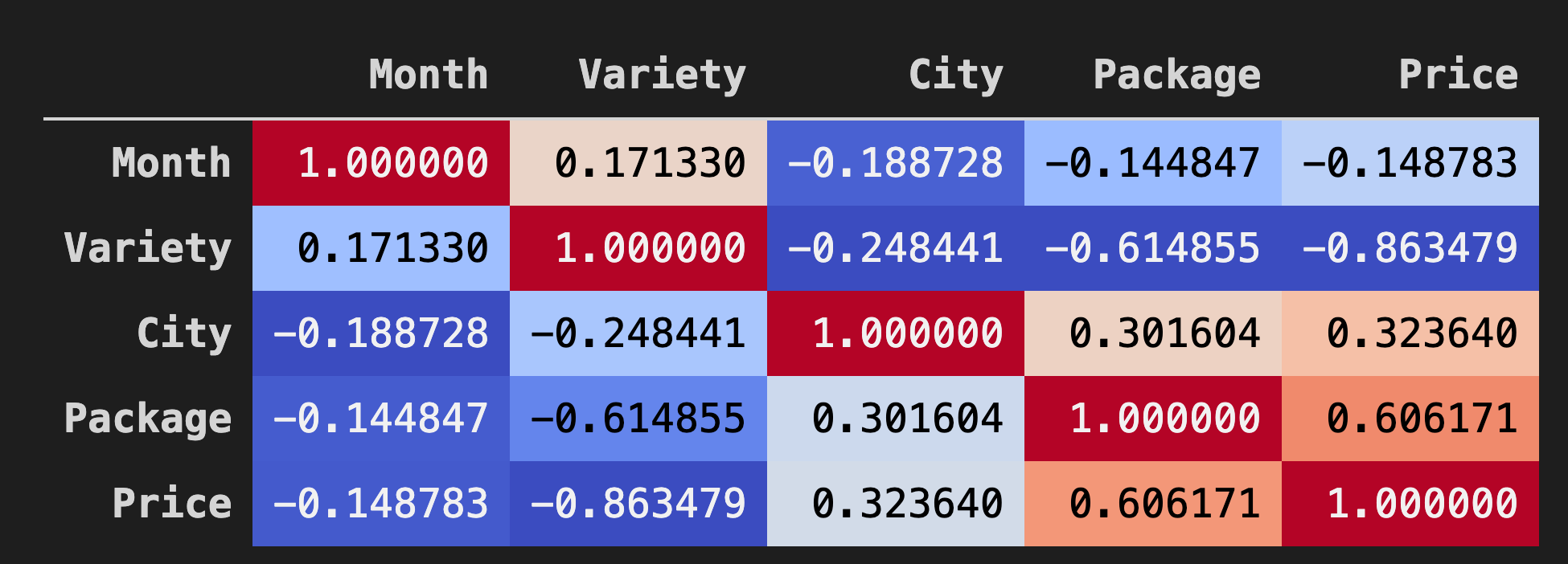
このチャートを見ると、「パッケージ」と「価格」の間に正の相関関係があることが視覚化されています。つまり、前回のモデルよりも多少良いモデルを作ることができるはずです。
パイプラインの作成
Scikit-learnには、多項式回帰モデルを構築するための便利なAPIであるmake_pipeline API が用意されています。「パイプライン」は推定量の連鎖で作成されます。今回の場合、パイプラインには多項式の特徴量、非線形の経路を形成する予測値が含まれます。
-
X列とy列を作ります。
X=poly_pumpkins.iloc[:,3:4].values y=poly_pumpkins.iloc[:,4:5].values -
make_pipeline()メソッドを呼び出してパイプラインを作成します。from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import make_pipeline pipeline = make_pipeline(PolynomialFeatures(4), LinearRegression()) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) pipeline.fit(np.array(X_train), y_train) y_pred=pipeline.predict(X_test)
系列の作成
この時点で、パイプラインが系列を作成できるように、ソートされたデータで新しいデータフレームを作成する必要があります。
以下のコードを追加します。
df = pd.DataFrame({'x': X_test[:,0], 'y': y_pred[:,0]})
df.sort_values(by='x',inplace = True)
points = pd.DataFrame(df).to_numpy()
plt.plot(points[:, 0], points[:, 1],color="blue", linewidth=3)
plt.xlabel('Package')
plt.ylabel('Price')
plt.scatter(X,y, color="black")
plt.show()
pd.DataFrame を呼び出して新しいデータフレームを作成しました。次にsort_values() を呼び出して値をソートしました。最後に多項式のプロットを作成しました。
よりデータにフィットした曲線を確認することができます。
モデルの精度を確認してみましょう。
accuracy_score = pipeline.score(X_train,y_train)
print('Model Accuracy: ', accuracy_score)
これで完成です!
Model Accuracy: 0.8537946517073784
いい感じです!価格を予測してみましょう。
予測の実行
新しい値を入力し、予測値を取得できますか?
predict() メソッドを呼び出して、予測を行います。
pipeline.predict( np.array([ [2.75] ]) )
以下の予測結果が得られます。
array([[46.34509342]])
プロットを見てみると、納得できそうです!そして、同じデータを見て、これが前のモデルよりも良いモデルであれば、より高価なカボチャのために予算を組む必要があります。
🏆 お疲れ様でした!1つのレッスンで2つの回帰モデルを作成しました。回帰に関する最後のセクションでは、カテゴリーを決定するためのロジスティック回帰について学びます。
🚀チャレンジ
このノートブックでいくつかの異なる変数をテストし、相関関係がモデルの精度にどのように影響するかを確認してみてください。
講義後クイズ
レビュー & 自主学習
このレッスンでは、線形回帰について学びました。回帰には他にも重要な種類があります。Stepwise、Ridge、Lasso、Elasticnetなどのテクニックをご覧ください。より詳しく学ぶには、Stanford Statistical Learning course が良いでしょう。