14 KiB
Memulai dengan Python dan Scikit-learn untuk model regresi
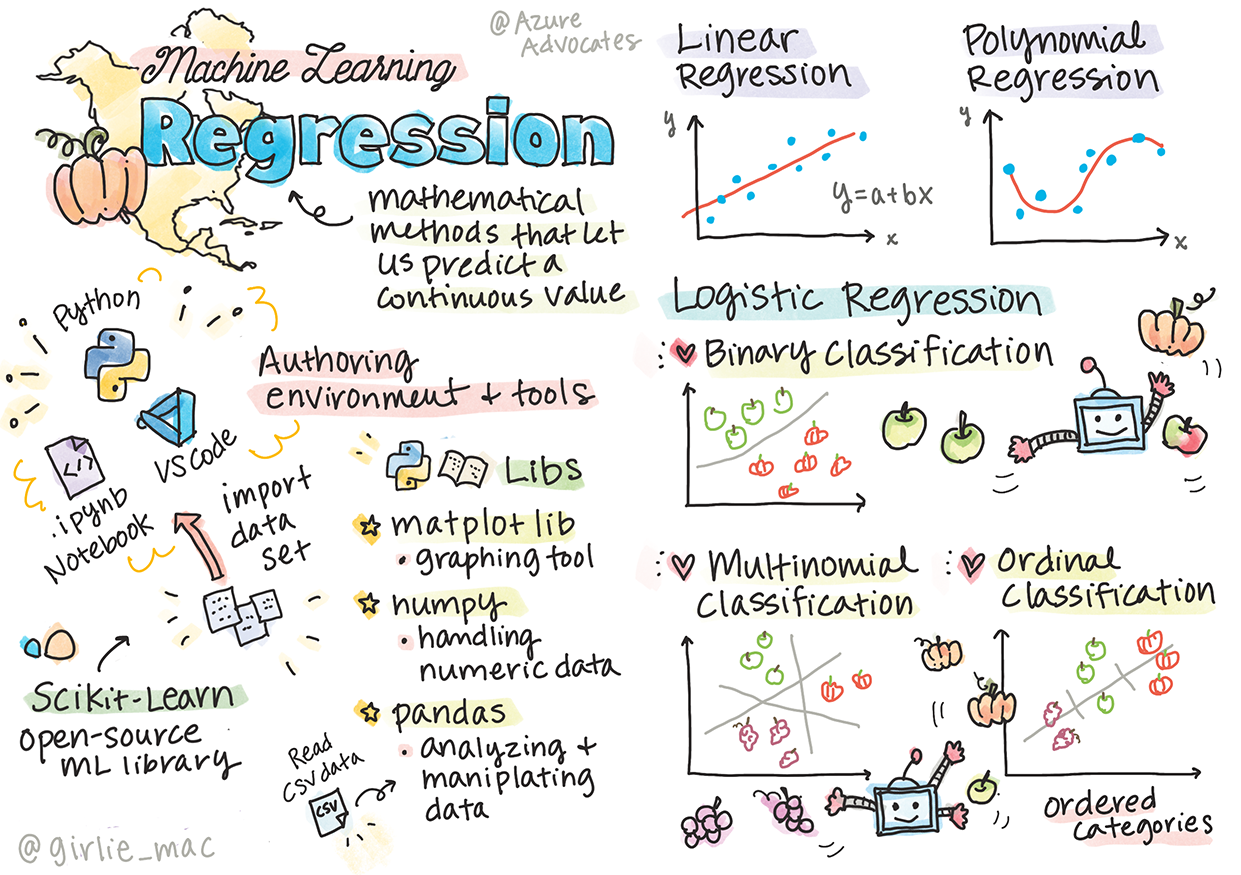
Catatan sketsa oleh Tomomi Imura
Kuis Pra-ceramah
Pembukaan
Dalam keempat pelajaran ini, kamu akan belajar bagaimana membangun model regresi. Kita akan berdiskusi apa fungsi model tersebut dalam sejenak. Tetapi sebelum kamu melakukan apapun, pastikan bahwa kamu sudah mempunyai alat-alat yang diperlukan untuk memulai!
Dalam pelajaran ini, kamu akan belajar bagaimana untuk:
- Konfigurasi komputermu untuk tugas pembelajaran.
- Bekerja dengan Jupyter notebooks.
- Menggunakan Scikit-learn, termasuk instalasi.
- Menjelajahi regresi linear dengan latihan hands-on.
Instalasi dan konfigurasi

🎥 Klik foto di atas untuk sebuah video: menggunakan Python dalam VS Code
-
Pasang Python. Pastikan bahwa Python telah dipasang di komputermu. Kamu akan menggunakan Python untuk banyak tugas data science dan machine learning. Python sudah dipasang di kebanyakan sistem komputer. Adapula Python Coding Packs yang berguna untuk membantu proses pemasangan untuk beberapa pengguna.
Beberapa penggunaan Python memerlukan satu versi perangkat lunak tersebut, sedangkan beberapa penggunaan lainnya mungkin memerlukan versi Python yang beda lagi. Oleh sebab itulah akan sangat berguna untuk bekerja dalam sebuah virtual environment (lingkungan virtual).
-
Pasang Visual Studio Code. Pastikan kamu sudah memasangkan Visual Studio Code di komputermu. Ikuti instruksi-instruksi ini untuk memasangkan Visual Studio Code untuk instalasi dasar. Kamu akan menggunakan Python dalam Visual Studio Code dalam kursus ini, jadi kamu mungkin akan ingin mencari tahu cara mengkonfigurasi Visual Studio Code untuk menggunakan Python.
Nyamankan diri dengan Python dengan mengerjakan koleksi modul pembelajaran ini
-
Pasang Scikit-learn, dengan mengikuti instruksi di sini. Karena harus dipastikan bahwa kamu sedang menggunakan Python 3, kami anjurkan kamu menggunakan sebuah virtual environment. Ingatlah juga bahwa jika kamu ingin memasangkan ini di sebuah M1 Mac, ada instruksi khusus dalam laman yang ditautkan di atas.
-
Pasang Jupyter Notebook. Kamu akan harus memasang paket Jupyter.
Lingkungan penulisan ML-mu
Kamu akan menggunakan notebooks untuk bekerja dengan kode Python-mu dan membuat model machine learning-mu. Jenis file ini adalah alat yang sering digunakan data scientists dan dapat diidentifikasikan dengan akhiran/ekstensi .ipynb.
Notebook adalah sebuah lingkungan interaktif yang memungkinkan seorang developer untuk menulis kode, catatan, dan dokumentasi mengenai kode tersebut sehingga menjadi sangat berguna untuk proyek eksperimental ataupun riset.
Latihan - bekerja dengan sebuah notebook
Dalam folder ini, kamu akan menemukan file notebook.ipynb.
-
Buka notebook.ipynb dalam Visual Studio Code.
Sebuah server Jupyter akan mulai dengan Python 3+. Kamu akan menemukan bagian-bagian notebook yang dapat di-
run(dijalankan). Bagian-bagian tersebut adalah carikan-carikan kode. Kamu bisa menjalankan secarik kode dengan mengklik tombol ▶. -
Pilih ikon
mddan tambahlah sedikit markdown: # Selamat datang di notebook saya!Lalu, tambahlah sedikit kode Python.
-
Ketik print('hello notebook') dalam blok kode.
-
Klik ▶ untuk menjalankan kode.
Hasilnya harusnya ini:
hello notebook

Kamu bisa menyelipkan catatan-catatan antara kodemu untuk mendokumentasi notebook-nya.
✅ Pikirkanlah sejenak bagaimana lingkungan seorang web developer berbeda dengan lingkungan seorang data scientist.
Berjalan dengan Scikit-learn
Sekarang, Python sudah siap dalam lingkungan lokalmu, dan kamu sudah nyaman bekerja dengan Jupyter notebook. Marilah membiasakan diri dengan Scikit-learn (dilafalkan saikit lern; huruf e dalam lern seperti e dalam kata Perancis). Scikit-learn menyediakan sebuah API ekstensif untuk membantu kamu mengerjakan tugas ML.
Berdasarkan situs mereka, "Scikit-learn" adalah sebuah open-source library untuk machine-learning yang dapat digunakan untuk supervised dan unsupervised learning. Scikit-learn juga menyediakan beragam alat untuk model-fitting, data preprocessing, seleksi dan evaluasi model, dll.
Dalam kursus ini, kamu akan menggunakan Scikit-learn dan beberapa alat lainnya untuk membangun model machine-learning untuk mengerjakan apa yang kami panggil tugas 'machine-learning tradisional'. Kami sengaja menghindari neural networks dan deep learning sebab mereka akan dibahas dengan lebih lengkap dalam kurikulum 'AI untuk pemula' nanti.
Scikit-learn memudahkan pembangunan dan evaluasi model-model. Dia terutama fokus pada menggunakan data numerik dan mempunyai beberapa dataset yang siap sedia untuk digunakan sebagai alat belajar. Dia juga mempunyai model yang sudah dibangun untuk murid-murid untuk langsung coba. Mari menjelajahi proses memuat data yang sudah disiapkan dan menggunakan model ML pengestimasian pertama menggunakan Scikit-learn dengan data sederhana.
Latihan - Scikit-learn notebook pertamamu
Tutorial ini terinspirasi contoh regresi linear ini di situs Scikit-learn.
Dalam file notebook.ipynb dari pelajaran ini, kosongkan semua sel dengan mengklik tombol berlambang 'tempat sampah'.
Dalam bagian ini, kamu akan bekerja dengan sebuah dataset kecil tentang diabetes yang datang bersama dengan Scikit-learn yang dimaksud sebagai bahan ajaran. Bayangkan bahwa kamu ingin mencoba sebuah cara pengobatan untuk pasien diabetes. Model machine learning mungkin dapat membantu kamu menentukan pasien mana merespon lebih baik pada pengobatan tersebut berdasarkan kombinasi-kombinasi variabel. Bahkan sebuah model regresi yang sederhana, saat divisualisasikan, dapat menunjukkanmu informasi tentang variabel-variabel yang dapat membantu kamu mengorganisasikan uji-uji klinis teoritismu.
✅ Ada banyak macam metode regresi, dan yang mana yang kamu pilih tergantung pada jawaban yang kamu sedang cari. Kalau kamu ingin memprediksi tinggi badan seseorang dari usianya, kamu bisa menggunakan regresi linear, karena kamu mencari sebuah nilai numerik. Kalau kamu tertarik pada apa sebuah jenis kuliner sebaiknya dianggap sebagai vegan atau tidak, kamu sedang mencari sebuah kategorisasi/klasifikasi; kamu bisa menggunakan regresi logistik. Kamu akan belajar lebih banyak tentang regresi logistik nanti. Pikirkan dahulu beberapa pertanyaan yang kamu bisa tanyakan dari data yang ada dan metode yang mana akan paling cocok.
Mari mulai mengerjakan tugas ini.
Impor library
Untuk tugas ini, kita akan mengimpor beberapa library:
- matplotlib. Sebuah alat untuk membuat grafik yang kita akan gunakan untuk membuat sebuah grafik garis.
- numpy. numpy adalah sebuah library berguna untuk menangani data numerik di Python.
- sklearn. Ini adalah library Scikit-learn.
Imporlah library-library yang akan membantu dengan tugasmu.
-
Tambahlah impor dengan mengetik kode berikut:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionDi atas, kamu sedang mengimpor
matplottlib,numpy. Selain itu, kamu juga sedang mengimpordatasets,linear_modeldanmodel_selectiondarisklearn.model_selectiondigunakan untuk memisahkan data menjadi set latihan dan set ujian.
Dataset diabetes
Dataset diabetes mencakupi 442 sampel data mengenai diabetes dengan 10 variabel utama, termasuk:
- age: usia dalam tahun
- bmi: body mass index
- bp: tekanan darah rata-rata
- s1 tc: Sel T (sejenis cel darah putih)
✅ Dataset ini juga mempunyai konsep 'jenis kelamin' sebagai sebuah variabel utama yang penting dalam riset diabetes. Banyak dataset medis mempunyai klasifikasi binari ini. Pikirkan sejenak bagaimana kategorisasi seperti yang ini dapat mengecualikan bagian tertentu dari sebuah populasi dari pengobatan.
Sekarang, muatkan data X dan y.
🎓 Ingatlah, ini adalah supervised learning, jadi kita perlu sebuah target (dinamakan 'y').
Dalam sebuah sel kode yang baru, muatkan dataset diabetes dengan memanggil load_diabetes(). Input return_X_y=True menunjukkan bahwa X adalah sebuah matriks data dan y adalah target regresi.
-
Tambah beberapa instruksi print untuk menunjukkan ukuran data matriks dan elemen pertama matriks tersebut.
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Respon yang didapati adalah sebuah tuple. Kamu sedang menetapkan kedua nilai pertama dalam tuple itu ke dalam
Xdanysecara berturut. Pelajari lebih banyak tentant tuples.Kamu bisa melihat bahwa data ini berupa 422 nilai yang disusun menjadi beberapa
arraydengan 10 elemen:(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Pikirkan sejenak tentang hubungan antara data dan target regresi. Apa kamu bisa menemukan targetnya untuk database diabetes dalam dokumentasinya? Mengetahui targetnya, apa yang dataset ini sedang mendemonstrasikan?
-
Lalu, pilih sebuah porsi dataset ini untuk digambarkan dengan menyusuninya menjadi sebuah
arraybaru dengan fungsinewaxisdarinumpy. Kita akan menggunakan regresi linear untuk menggambar sebuah garis antara nilai-nilai dalam data ini sesuai dengan pola yang ditentukannya.X = X[:, np.newaxis, 2]✅ Kapanpun, print-lah datanya untuk memeriksa bentuknya.
-
Sekarang datanya sudah siap untuk digambar. Kamu bisa melihat jikalau sebuah mesin dapat menentukan sebuah perpisahan logika dari nomor-nomor dataset ini. Untuk melakukan itu, kamu harus memisahkan data (X) dan target (y) menjadi set latihan dan set ujian. Scikit-learn juga memberi cara untuk melakukan itu; kamu bisa memisahkan data ujianmu pada titik tertentu.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Sekarang, kamu sudah siap untuk melatihkan modelmu! Muatkan dahulu data regresi linear dan latihkan modelmu dengan set X dan y-mu dengan
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()adalah sebuah fungsi yang akan kamu temukan dalam banyak library ML seperti TensorFlow. -
Lalu, buatlah sebuah prediksi dengan data ujianmu dengan fungsi
predict(). Ini akan digunakan untuk menggambar sebuah garis antara grup-grup data.y_pred = model.predict(X_test) -
Sekarang waktunya untuk menggambar data dalam sebuah grafik. Matplotlib adalah sebuah alat yang sangat berguna untuk melakukan itu. Buatlah sebuah petak sebar dari semua X dan y dari set ujian dan gunakan prediksi yang dihasilkan untuk menggambar sebuah garis di tempat yang paling cocok antara grup-grup data modelnya.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.show()
✅ Pikirkan sejenak tentang apa yang sedang terjadi di sini. Sebuah garis lurus membentang tengah-tengah titik-titik kecil data. Tetapi apa yang sedang garis itu lakukan? Apa kamu bisa melihat bagaimana kamu bisa menggunakan garis ini untuk memprediksi di mana sebuah titik data baru yang tidak pernah dilihat sebelumnya kemungkinan besar akan terletak berhubungan dengan sumbu y grafik ini? Coba jelaskan dalam kata-kata kegunaan praktis model ini.
Selamat, kamu telah membangun model regresi linear pertamamu, membuat sebuah prediksi darinya, dan menunjukkannya dalam sebuah grafik!
Tantangan
Gambarkan sebuah variabel yang beda dari dataset ini. Petunjuk: edit baris ini: X = X[:, np.newaxis, 2]. Mengetahui target dataset ini, apa yang kamu bisa menemukan tentang kemajuan diabetes sebagai sebuah penyakit?
Kuis pasca-ceramah
Review & Pembelajaran Mandiri
Dalam tutorial ini, kamu bekerja dengan sebuah model regresi linear yang sederhana daripada regresi linear univariat atau berganda. Bacalah sedikit tentang perbedaan antara metode-metode ini atau tontonlah video ini.
Bacalah lebih banyak tentang konsep regresi dan pikirkanlah tentang jenis pertanyaan apa saja yang bisa dijawab teknik ini. Cobalah tutorial ini untuk memperdalam pemahamanmu.