14 KiB
Introdução à classificação
Nestas quatro lições, você explorará um foco fundamental da aprendizagem de máquina clássica - classificação. Usaremos vários algoritmos de classificação com um datset (conjunto de dados) sobre todas as cozinhas brilhantes da Ásia e da Índia. Espero que esteja com fome!

Celebre a cozinha pan-asiática nestas aulas! Imagem por Jen Looper.
A classificação é uma forma de aprendizado supervisionado que tem muito em comum com as técnicas de regressão. O aprendizado de máquina tem tudo a ver com prever valores ou nomes para coisas usando datasets. A classificação geralmente se divide em dois grupos: classificação binária e classificação de multiclasse.

🎥 Clique na imagem acima para ver o vídeo: John Guttag do MIT introduz classificação (vídeo em inglês).
Lembre-se:
- A regressão linear ajudou a prever relações entre variáveis e fazer previsões precisas sobre onde um novo ponto de dados cairia em relação a uma linha. Então, você poderia prever que preço teria uma abóbora em setembro vs. dezembro, por exemplo.
- A regressão logística ajudou a descobrir "categorias binárias": em uma faixa de preço, essa abóbora é laranja ou não?
A classificação usa vários algoritmos para determinar outras maneiras de determinar o rótulo ou a classe de um ponto de dados ou objeto. Vamos trabalhar com dados sobre culinária para ver se, observando um grupo de ingredientes, podemos determinar sua culinária de origem.
Questionário inicial
Esta lição está disponível em R!
Introdução
Classificação é uma das atividades fundamentais do pesquisador de aprendizado de máquina e cientista de dados. Desde a classificação básica de um valor binário ("este e-mail é spam ou não?"), até a classificação e segmentação de imagens complexas usando visão computacional, é sempre útil ser capaz de classificar os dados em classes e fazer perguntas sobre eles.
Para declarar o processo de uma maneira mais científica, seu método de classificação cria um modelo preditivo que permite mapear o relacionamento entre as variáveis de entrada e as variáveis de saída.
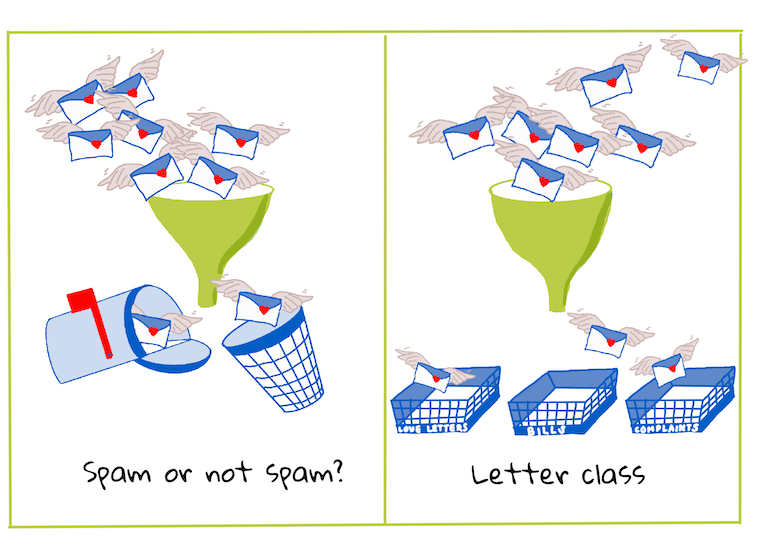
Problemas binários vs. multiclasse para algoritmos de classificação lidarem. Infográfico por Jen Looper.
Antes de iniciar o processo de limpar, visualizar e preparar nossos dados para tarefas de ML, vamos aprender um pouco sobre as várias maneiras pelas quais o aprendizado de máquina pode ser usado ao classificar dados.
Derivado da estatística, a classificação no aprendizado de máquina clássico usa características como fumante, peso e idade para determinar a possibilidade de desenvolver a doença X. Como uma técnica de aprendizado supervisionado semelhante aos exercícios de regressão que você realizou anteriormente, seus dados são rotulados e os algoritmos de ML usam esses rótulos para classificar e prever classes (ou 'características') de um dataset e atribuí-los a um grupo ou resultado.
✅ Imagine um dataset sobre culinárias. O que um modelo multiclasse seria capaz de responder? O que um modelo binário seria capaz de responder? E se você quisesse determinar se uma determinada cozinha usaria feno-grego? E se você quisesse ver se usando uma sacola de supermercado cheia de anis estrelado, alcachofras, couve-flor e raiz-forte, você poderia criar um prato típico indiano?

🎥 Clique na imagem acima para assistir a um vídeo (em inglês). O foco de cada episódio do programa 'Chopped' é a 'cesta misteriosa' onde os chefs têm que fazer um prato a partir de uma escolha aleatória de ingredientes. Certamente um modelo de ML teria ajudado!
Olá 'classificador'
A pergunta que queremos fazer sobre este dataset de culinária é, na verdade, uma questão multiclasse, pois temos várias cozinhas nacionais em potencial para trabalhar. Dado um lote de ingredientes, em qual dessas muitas classes os dados se encaixam?
Dependendo do tipo de problema que você deseja resolver, o Scikit-learn oferece vários algoritmos diferentes para classificar dados. Nas próximas tarefas, você aprenderá sobre esses algoritmos.
Exercício - limpe e balanceie seus dados
A primeira tarefa, antes de iniciar este projeto, é limpar e balancear seus dados para obter melhores resultados. Comece com o arquivo notebook.ipynb na raiz da pasta desta tarefa.
A primeira coisa a instalar é o imblearn. O imblearn é um pacote Scikit-learn que permitirá que você balanceie melhor os dados (vamos aprender mais sobre isso já já).
-
Para instalar o
imblearn, rodepip install:pip install imblearn -
Importe os pacotes que você precisa para obter seus dados e visualizá-los, importe também a classe
SMOTE.import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl import numpy as np from imblearn.over_sampling import SMOTEAgora você está pronto para obter os dados do dataset.
-
O próximo passo é obter os dados do dataset a ser usado:
df = pd.read_csv('../data/cuisines.csv')Usando o método
read_csv(), leremos o conteúdo do arquivo csv cusines.csv e colocaremos na variáveldf. -
Vamos observar o formato dos dados:
df.head()As primeiras cinco linhas são assim:
| | Unnamed: 0 | cuisine | almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | | --- | ---------- | ------- | ------ | -------- | ----- | ---------- | ----- | ------------ | ------- | -------- | --- | ------- | ----------- | ---------- | ----------------------- | ---- | ---- | --- | ----- | ------ | -------- | | 0 | 65 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 1 | 66 | indian | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 2 | 67 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 3 | 68 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | | 4 | 69 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | -
Conseguimos informações sobre esses dados chamando
info():df.info()O resultado será mais ou menos assim:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 2448 entries, 0 to 2447 Columns: 385 entries, Unnamed: 0 to zucchini dtypes: int64(384), object(1) memory usage: 7.2+ MB
Exercício - aprendendo sobre cozinhas
Agora o trabalho começa a ficar mais interessante. Vamos descobrir a distribuição de dados por cozinha.
-
Plote os dados como gráfico de barras chamando o método
barh():df.cuisine.value_counts().plot.barh()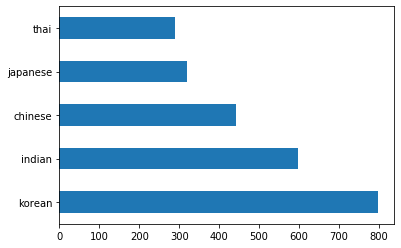
Há um número finito de cozinhas, mas a distribuição de dados é desigual. Você pode consertar isso! Mas antes, explore um pouco mais.
-
Descubra quantos dados estão disponíveis por cozinha e imprima-os:
thai_df = df[(df.cuisine == "thai")] japanese_df = df[(df.cuisine == "japanese")] chinese_df = df[(df.cuisine == "chinese")] indian_df = df[(df.cuisine == "indian")] korean_df = df[(df.cuisine == "korean")] print(f'thai df: {thai_df.shape}') print(f'japanese df: {japanese_df.shape}') print(f'chinese df: {chinese_df.shape}') print(f'indian df: {indian_df.shape}') print(f'korean df: {korean_df.shape}')O resultado será mais ou menos assim:
thai df: (289, 385) japanese df: (320, 385) chinese df: (442, 385) indian df: (598, 385) korean df: (799, 385)
Descobrindo ingredientes
Vamos nos aprofundar nos dados e aprender quais são os ingredientes típicos de cada cozinha. Para isso, devemos limpar os dados recorrentes que criam confusão entre cozinhas.
-
Crie uma função em Python chamada
create_ingredient()para criar um dataframe de ingredientes. Esta função começará eliminando uma coluna inútil ("Unnamed: 0") e classificando os ingredientes por quantidade:def create_ingredient_df(df): ingredient_df = df.T.drop(['cuisine','Unnamed: 0']).sum(axis=1).to_frame('value') ingredient_df = ingredient_df[(ingredient_df.T != 0).any()] ingredient_df = ingredient_df.sort_values(by='value', ascending=False, inplace=False) return ingredient_dfVocê pode usar essa função para ter uma ideia dos dez ingredientes mais populares de uma culinária.
-
Chame a função
create_ingredient()usando os dados de cozinha tailandesa, e plote-os usando o métodobarh():thai_ingredient_df = create_ingredient_df(thai_df) thai_ingredient_df.head(10).plot.barh()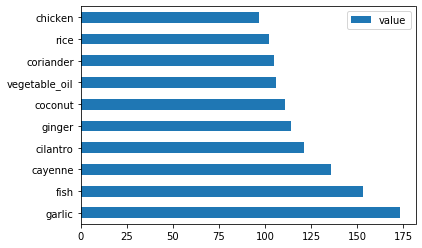
-
Faça o mesmo para cozinha japonesa:
japanese_ingredient_df = create_ingredient_df(japanese_df) japanese_ingredient_df.head(10).plot.barh()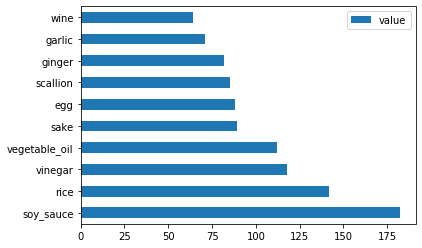
-
E para cozinha chinesa:
chinese_ingredient_df = create_ingredient_df(chinese_df) chinese_ingredient_df.head(10).plot.barh()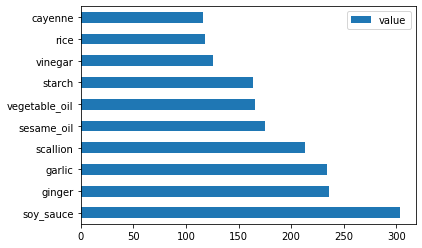
-
Plote os ingredientes indianos:
indian_ingredient_df = create_ingredient_df(indian_df) indian_ingredient_df.head(10).plot.barh()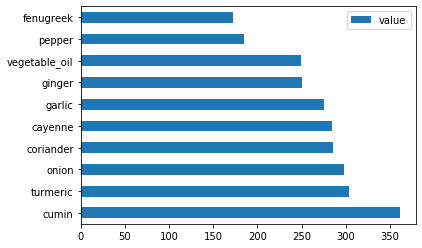
-
Por fim, os ingredientes da cozinha coreana:
korean_ingredient_df = create_ingredient_df(korean_df) korean_ingredient_df.head(10).plot.barh()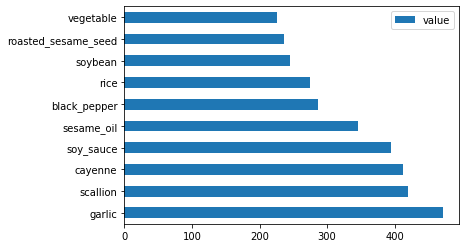
-
Agora, remova os ingredientes mais comuns que criam confusão entre cozinhas distintas, chamando
drop():Todo mundo adora arroz, alho e gengibre!
feature_df = df.drop(['cuisine','Unnamed: 0','rice','garlic','ginger'], axis=1) labels_df = df.cuisine #.unique() feature_df.head()
Balanceie o dataset
Agora que você limpou os dados, use a SMOTE - "Técnica de sobreamostragem de minoria sintética" - para balancear.
-
Chame o método
fit_resample(), esta estratégia gera novas amostras por interpolação.oversample = SMOTE() transformed_feature_df, transformed_label_df = oversample.fit_resample(feature_df, labels_df)Ao balancear seus dados, você terá melhores resultados ao classificá-los. Pense em uma classificação binária. Se a maioria dos seus dados for uma classe, um modelo de ML vai prever essa classe com mais frequência, simplesmente porque há mais dados para ela. O balanceamento de dados pega todos os dados distorcidos e ajuda a remover esse desequilíbrio.
-
Verifique o número de rótulos por ingrediente:
print(f'new label count: {transformed_label_df.value_counts()}') print(f'old label count: {df.cuisine.value_counts()}')O resultado será mais ou menos assim:
new label count: korean 799 chinese 799 indian 799 japanese 799 thai 799 Name: cuisine, dtype: int64 old label count: korean 799 indian 598 chinese 442 japanese 320 thai 289 Name: cuisine, dtype: int64Os dados são bons e limpos, equilibrados e muito deliciosos!
-
A última etapa é salvar seus dados balanceados, incluindo rótulos e características, em um novo dataframe que pode ser exportado para um arquivo:
transformed_df = pd.concat([transformed_label_df,transformed_feature_df],axis=1, join='outer') -
Você pode dar mais uma olhada nos dados usando o método
transform_df.head()etransform_df.info(). Salve uma cópia desses dados para usar nas próximas tarefas:transformed_df.head() transformed_df.info() transformed_df.to_csv("../data/cleaned_cuisines.csv")Este novo csv pode ser encontrado na pasta raiz, onde estão todos os arquivos com os dados dos datasets.
🚀Desafio
Esta lição contém vários datasets interessantes. Explore os arquivos da pasta data e veja quais datasets seriam apropriados para classificação binária ou multiclasse. Quais perguntas você faria sobre estes datasets?
Questionário para fixação
Revisão e Auto Aprendizagem
Explore a API do SMOTE. Para quais casos de uso ela é melhor usada? Quais problemas resolve?