19 KiB
Previsione delle serie temporali con ARIMA
Nella lezione precedente, si è imparato qualcosa sulla previsione delle serie temporali e si è caricato un insieme di dati che mostra le fluttuazioni del carico elettrico in un periodo di tempo.

🎥 Fare clic sull'immagine sopra per un video: Una breve introduzione ai modelli ARIMA. L'esempio è fatto in linguaggio R, ma i concetti sono universali.
Quiz Pre-Lezione
Introduzione
In questa lezione si scoprirà un modo specifico per costruire modelli con ARIMA: AutoRegressive Integrated Moving Average (Media mobile integrata autoregressiva). I modelli ARIMA sono particolarmente indicati per l'adattamento di dati che mostrano non stazionarietà.
Concetti generali
Per poter lavorare con ARIMA, ci sono alcuni concetti da conoscere:
-
🎓 Stazionarietà. In un contesto statistico, la stazionarietà si riferisce a dati la cui distribuzione non cambia se spostata nel tempo. I dati non stazionari, poi, mostrano fluttuazioni dovute a andamenti che devono essere trasformati per essere analizzati. La stagionalità, ad esempio, può introdurre fluttuazioni nei dati e può essere eliminata mediante un processo di "differenziazione stagionale".
-
🎓 Differenziazione. I dati differenzianti, sempre in un contesto statistico, si riferiscono al processo di trasformazione dei dati non stazionari per renderli stazionari rimuovendo il loro andamento non costante. "La differenziazione rimuove le variazioni di livello di una serie temporale, eliminando tendenza e stagionalità e stabilizzando di conseguenza la media delle serie temporali." Documento di Shixiong e altri
ARIMA nel contesto delle serie temporali
Si esaminano le parti di ARIMA per capire meglio come aiuta a modellare le serie temporali e a fare previsioni contro di esso.
-
AR - per AutoRegressivo. I modelli autoregressivi, come suggerisce il nome, guardano "indietro" nel tempo per analizzare i valori precedenti nei dati e fare ipotesi su di essi. Questi valori precedenti sono chiamati "ritardi". Un esempio potrebbero essere i dati che mostrano le vendite mensili di matite. Il totale delle vendite di ogni mese sarebbe considerato una "variabile in evoluzione" nell'insieme di dati. Questo modello è costruito come "la variabile di interesse in evoluzione è regredita sui propri valori ritardati (cioè precedenti)". wikipedia
-
I - per integrato. A differenza dei modelli simili "ARMA", la "I" in ARIMA si riferisce al suo aspetto integrato . I dati vengono "integrati" quando vengono applicati i passaggi di differenziazione in modo da eliminare la non stazionarietà.
-
MA - per Media Mobile. L'aspetto della media mobile di questo modello si riferisce alla variabile di output che è determinata osservando i valori attuali e passati dei ritardi.
In conclusione: ARIMA viene utilizzato per adattare il più possibile un modello alla forma speciale dei dati delle serie temporali.
Esercizio: costruire un modello ARIMA
Aprire la cartella /working in questa lezione e trovare il file notebook.ipynb.
-
Eseguire il notebook per caricare la libreria Python
statsmodels; servirà per i modelli ARIMA. -
Caricare le librerie necessarie
-
Ora caricare molte altre librerie utili per tracciare i dati:
import os import warnings import matplotlib.pyplot as plt import numpy as np import pandas as pd import datetime as dt import math from pandas.plotting import autocorrelation_plot from statsmodels.tsa.statespace.sarimax import SARIMAX from sklearn.preprocessing import MinMaxScaler from common.utils import load_data, mape from IPython.display import Image %matplotlib inline pd.options.display.float_format = '{:,.2f}'.format np.set_printoptions(precision=2) warnings.filterwarnings("ignore") # specificare per ignorare messaggi di avvertimento -
Caricare i dati dal file
/data/energy.csvin un dataframe Pandas e dare un'occhiata:energy = load_data('./data')[['load']] energy.head(10) -
Tracciare tutti i dati energetici disponibili da gennaio 2012 a dicembre 2014. Non dovrebbero esserci sorprese poiché questi dati sono stati visti nell'ultima lezione:
energy.plot(y='load', subplots=True, figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()Ora si costruisce un modello!
Creare insiemi di dati di addestramento e test
Ora i dati sono stati caricati, quindi si possono separare in insiemi di addestramento e test. Si addestrerà il modello sull'insieme di addestramento. Come al solito, dopo che il modello ha terminato l'addestramento, se ne valuterà l'accuratezza utilizzando l'insieme di test. È necessario assicurarsi che l'insieme di test copra un periodo successivo dall'insieme di addestramento per garantire che il modello non ottenga informazioni da periodi di tempo futuri.
-
Assegnare un periodo di due mesi dal 1 settembre al 31 ottobre 2014 all'insieme di addestramento. L'insieme di test comprenderà il bimestre dal 1 novembre al 31 dicembre 2014:
train_start_dt = '2014-11-01 00:00:00' test_start_dt = '2014-12-30 00:00:00'Poiché questo dato riflette il consumo giornaliero di energia, c'è un forte andamento stagionale, ma il consumo è più simile al consumo nei giorni più recenti.
-
Visualizzare le differenze:
energy[(energy.index < test_start_dt) & (energy.index >= train_start_dt)][['load']].rename(columns={'load':'train'}) \ .join(energy[test_start_dt:][['load']].rename(columns={'load':'test'}), how='outer') \ .plot(y=['train', 'test'], figsize=(15, 8), fontsize=12) plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()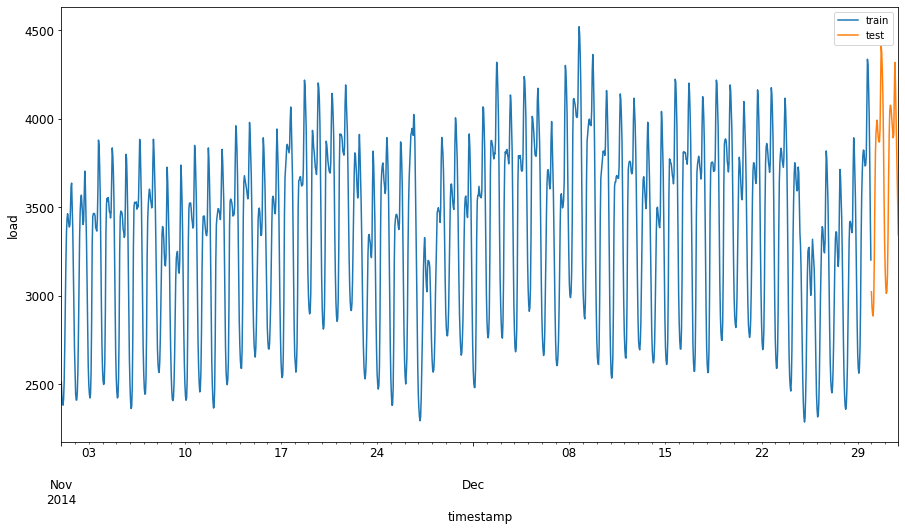
Pertanto, l'utilizzo di una finestra di tempo relativamente piccola per l'addestramento dei dati dovrebbe essere sufficiente.
Nota: poiché la funzione utilizzata per adattare il modello ARIMA usa la convalida nel campione durante l'adattamento, si omettono i dati di convalida.
Preparare i dati per l'addestramento
Ora è necessario preparare i dati per l'addestramento eseguendo il filtraggio e il ridimensionamento dei dati. Filtrare l'insieme di dati per includere solo i periodi di tempo e le colonne che servono e il ridimensionamento per garantire che i dati siano proiettati nell'intervallo 0,1.
-
Filtrare l'insieme di dati originale per includere solo i suddetti periodi di tempo per insieme e includendo solo la colonna necessaria "load" più la data:
train = energy.copy()[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']] test = energy.copy()[energy.index >= test_start_dt][['load']] print('Training data shape: ', train.shape) print('Test data shape: ', test.shape)Si può vedere la forma dei dati:
Training data shape: (1416, 1) Test data shape: (48, 1) -
Ridimensionare i dati in modo che siano nell'intervallo (0, 1).
scaler = MinMaxScaler() train['load'] = scaler.fit_transform(train) train.head(10) -
Visualizzare i dati originali rispetto ai dati in scala:
energy[(energy.index >= train_start_dt) & (energy.index < test_start_dt)][['load']].rename(columns={'load':'original load'}).plot.hist(bins=100, fontsize=12) train.rename(columns={'load':'scaled load'}).plot.hist(bins=100, fontsize=12) plt.show()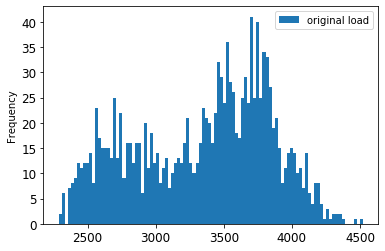
I dati originali.
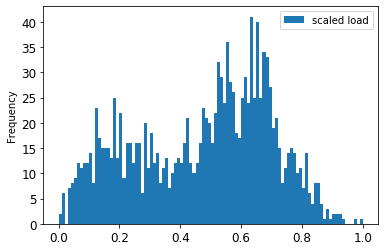
I dati in scala
-
Ora che si è calibrato i dati scalati, si possono scalare i dati del test:
test['load'] = scaler.transform(test) test.head()
Implementare ARIMA
È tempo di implementare ARIMA! Si utilizzerà ora la libreria statsmodels installata in precedenza.
Ora occorre seguire diversi passaggi
- Definire il modello chiamando
SARIMAX()passando i parametri del modello: parametri p, d e q e parametri P, D e Q. - Preparare il modello per i dati di addestramento chiamando la funzione fit().
- Effettuare previsioni chiamando la funzione
forecast()specificando il numero di passaggi (l'orizzonte -horizon) da prevedere.
🎓 A cosa servono tutti questi parametri? In un modello ARIMA ci sono 3 parametri che vengono utilizzati per aiutare a modellare gli aspetti principali di una serie temporale: stagionalità, tendenza e rumore. Questi parametri sono:
p: il parametro associato all'aspetto autoregressivo del modello, che incorpora i valori passati.
d: il parametro associato alla parte integrata del modello, che incide sulla quantità di differenziazione (🎓 si ricorda la differenziazione 👆?) da applicare a una serie temporale.
q: il parametro associato alla parte a media mobile del modello.
Nota: se i dati hanno un aspetto stagionale, come questo, si utilizza un modello ARIMA stagionale (SARIMA). In tal caso è necessario utilizzare un altro insieme di parametri:
P,DeQche descrivono le stesse associazioni dip,deq, ma corrispondono alle componenti stagionali del modello.
-
Iniziare impostando il valore di orizzonte preferito. Si prova 3 ore:
# Specificare il numero di passaggi per prevedere in anticipo HORIZON = 3 print('Forecasting horizon:', HORIZON, 'hours')La selezione dei valori migliori per i parametri di un modello ARIMA può essere difficile in quanto è in qualche modo soggettiva e richiede molto tempo. Si potrebbe prendere in considerazione l'utilizzo di una funzione
auto_arima()dalla libreriapyramid, -
Per ora provare alcune selezioni manuali per trovare un buon modello.
order = (4, 1, 0) seasonal_order = (1, 1, 0, 24) model = SARIMAX(endog=train, order=order, seasonal_order=seasonal_order) results = model.fit() print(results.summary())Viene stampata una tabella dei risultati.
Si è costruito il primo modello! Ora occorre trovare un modo per valutarlo.
Valutare il modello
Per valutare il modello, si può eseguire la cosiddetta convalida walk forward . In pratica, i modelli di serie temporali vengono riaddestrati ogni volta che diventano disponibili nuovi dati. Ciò consente al modello di effettuare la migliore previsione in ogni fase temporale.
A partire dall'inizio della serie temporale utilizzando questa tecnica, addestrare il modello sull'insieme di dati di addestramento Quindi fare una previsione sul passaggio temporale successivo. La previsione viene valutata rispetto al valore noto. L'insieme di addestramento viene quindi ampliato per includere il valore noto e il processo viene ripetuto.
Nota: è necessario mantenere fissa la finestra dell'insieme di addestramento per un addestramento più efficiente in modo che ogni volta che si aggiunge una nuova osservazione all'insieme di addestramento, si rimuove l'osservazione dall'inizio dell'insieme.
Questo processo fornisce una stima più solida di come il modello si comporterà in pratica. Tuttavia, ciò comporta il costo computazionale della creazione di così tanti modelli. Questo è accettabile se i dati sono piccoli o se il modello è semplice, ma potrebbe essere un problema su larga scala.
La convalida walk-forward è lo standard di riferimento per valutazione del modello di serie temporali ed è consigliata per i propri progetti.
-
Innanzitutto, creare un punto dati di prova per ogni passaggio HORIZON.
test_shifted = test.copy() for t in range(1, HORIZON): test_shifted['load+'+str(t)] = test_shifted['load'].shift(-t, freq='H') test_shifted = test_shifted.dropna(how='any') test_shifted.head(5)load load 1 load 2 2014/12/30 00:00:00 0,33 0.29 0,27 2014/12/30 00:01:00:00 0.29 0,27 0,27 2014/12/30 02:00:00 0,27 0,27 0,30 2014/12/30 03:00:00 0,27 0,30 0.41 2014/12/30 04:00 0,30 0.41 0,57 I dati vengono spostati orizzontalmente in base al loro punto horizon.
-
Fare previsioni sui dati di test utilizzando questo approccio a finestra scorrevole in un ciclo della dimensione della lunghezza dei dati del test:
%%time training_window = 720 # dedicare 30 giorni (720 ore) for l'addestramento train_ts = train['load'] test_ts = test_shifted history = [x for x in train_ts] history = history[(-training_window):] predictions = list() order = (2, 1, 0) seasonal_order = (1, 1, 0, 24) for t in range(test_ts.shape[0]): model = SARIMAX(endog=history, order=order, seasonal_order=seasonal_order) model_fit = model.fit() yhat = model_fit.forecast(steps = HORIZON) predictions.append(yhat) obs = list(test_ts.iloc[t]) # move the training window history.append(obs[0]) history.pop(0) print(test_ts.index[t]) print(t+1, ': predicted =', yhat, 'expected =', obs)Si può guardare l'addestramento in corso:
2014-12-30 00:00:00 1 : predicted = [0.32 0.29 0.28] expected = [0.32945389435989236, 0.2900626678603402, 0.2739480752014323] 2014-12-30 01:00:00 2 : predicted = [0.3 0.29 0.3 ] expected = [0.2900626678603402, 0.2739480752014323, 0.26812891674127126] 2014-12-30 02:00:00 3 : predicted = [0.27 0.28 0.32] expected = [0.2739480752014323, 0.26812891674127126, 0.3025962399283795] -
Confrontare le previsioni con il carico effettivo:
eval_df = pd.DataFrame(predictions, columns=['t+'+str(t) for t in range(1, HORIZON+1)]) eval_df['timestamp'] = test.index[0:len(test.index)-HORIZON+1] eval_df = pd.melt(eval_df, id_vars='timestamp', value_name='prediction', var_name='h') eval_df['actual'] = np.array(np.transpose(test_ts)).ravel() eval_df[['prediction', 'actual']] = scaler.inverse_transform(eval_df[['prediction', 'actual']]) eval_df.head()| | | timestamp | h | prediction | actual | | --- | ---------- | --------- | --- | ---------- | -------- | | 0 | 2014-12-30 | 00:00:00 | t+1 | 3,008.74 | 3,023.00 | | 1 | 2014-12-30 | 01:00:00 | t+1 | 2,955.53 | 2,935.00 | | 2 | 2014-12-30 | 02:00:00 | t+1 | 2,900.17 | 2,899.00 | | 3 | 2014-12-30 | 03:00:00 | t+1 | 2,917.69 | 2,886.00 | | 4 | 2014-12-30 | 04:00:00 | t+1 | 2,946.99 | 2,963.00 |Osservare la previsione dei dati orari, rispetto al carico effettivo. Quanto è accurato questo?
Controllare la precisione del modello
Controllare l'accuratezza del modello testando il suo errore percentuale medio assoluto (MAPE) su tutte le previsioni.
🧮 Mostrami la matematica!
MAPE viene utilizzato per mostrare l'accuratezza della previsione come un rapporto definito dalla formula qui sopra. La differenza tra actualt e predictedt viene divisa per actualt. "Il valore assoluto in questo calcolo viene sommato per ogni punto nel tempo previsto e diviso per il numero di punti adattati n." wikipedia

-
Equazione espressa in codice:
if(HORIZON > 1): eval_df['APE'] = (eval_df['prediction'] - eval_df['actual']).abs() / eval_df['actual'] print(eval_df.groupby('h')['APE'].mean()) -
Calcolare il MAPE di un passo:
print('One step forecast MAPE: ', (mape(eval_df[eval_df['h'] == 't+1']['prediction'], eval_df[eval_df['h'] == 't+1']['actual']))*100, '%')Previsione a un passo MAPE: 0,5570581332313952 %
-
Stampare la previsione a più fasi MAPE:
print('Multi-step forecast MAPE: ', mape(eval_df['prediction'], eval_df['actual'])*100, '%')Multi-step forecast MAPE: 1.1460048657704118 %Un bel numero basso è il migliore: si consideri che una previsione che ha un MAPE di 10 è fuori dal 10%.
-
Ma come sempre, è più facile vedere visivamente questo tipo di misurazione dell'accuratezza, quindi si traccia:
if(HORIZON == 1): ## Tracciamento previsione passo singolo eval_df.plot(x='timestamp', y=['actual', 'prediction'], style=['r', 'b'], figsize=(15, 8)) else: ## Tracciamento posizione passo multiplo plot_df = eval_df[(eval_df.h=='t+1')][['timestamp', 'actual']] for t in range(1, HORIZON+1): plot_df['t+'+str(t)] = eval_df[(eval_df.h=='t+'+str(t))]['prediction'].values fig = plt.figure(figsize=(15, 8)) ax = plt.plot(plot_df['timestamp'], plot_df['actual'], color='red', linewidth=4.0) ax = fig.add_subplot(111) for t in range(1, HORIZON+1): x = plot_df['timestamp'][(t-1):] y = plot_df['t+'+str(t)][0:len(x)] ax.plot(x, y, color='blue', linewidth=4*math.pow(.9,t), alpha=math.pow(0.8,t)) ax.legend(loc='best') plt.xlabel('timestamp', fontsize=12) plt.ylabel('load', fontsize=12) plt.show()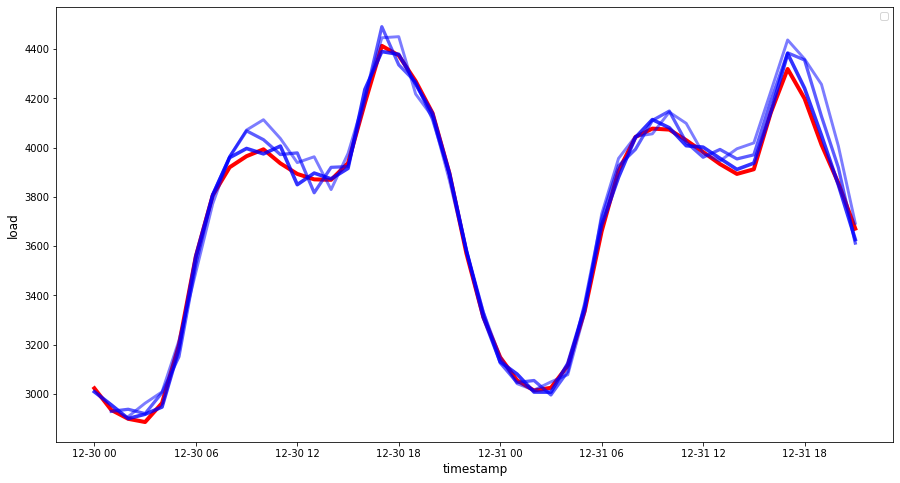
🏆 Un grafico molto bello, che mostra un modello con una buona precisione. Ottimo lavoro!
🚀 Sfida
Scoprire i modi per testare l'accuratezza di un modello di serie temporali. Si esamina MAPE in questa lezione, ma ci sono altri metodi che si potrebbero usare? Ricercarli e annotarli. Un documento utile può essere trovato qui
Quiz post-lezione
Revisione e Auto Apprendimento
Questa lezione tratta solo le basi della previsione delle serie temporali con ARIMA. SI prenda del tempo per approfondire le proprie conoscenze esaminando questo repository e i suoi vari tipi di modelli per imparare altri modi per costruire modelli di serie temporali.