|
|
2 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 2 years ago | |
| README.it.md | 2 years ago | |
| README.ko.md | 2 years ago | |
| README.pt-br.md | 2 years ago | |
| README.tr.md | 2 years ago | |
| README.zh-cn.md | 2 years ago | |
| assignment.es.md | 3 years ago | |
| assignment.it.md | 3 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.pt-br.md | 3 years ago | |
| assignment.tr.md | 3 years ago | |
| assignment.zh-cn.md | 3 years ago | |
README.zh-cn.md
菜品分类器 2
在第二节课程中,您将探索更多方法来对数值数据进行分类。您还将了解选择不同的分类器所带来的结果。
课前测验
先决条件
我们假设您已经完成了前面的课程,并且在本次课程文件夹根路径下的 data 文件夹中有一个经过清洗的名为 cleaned_cuisines.csv 数据集。
准备工作
我们已经将清洗过的数据集加载进您的 notebook.ipynb 文件,并分为 X 和 Y dataframe,为模型构建过程做好准备。
分类学习路线图
在此之前,您已经了解使用 Microsoft 速查表对数据进行分类时可以使用到的各种选项。Scikit-learn 提供了一个类似的,但更细粒度的速查表,可以进一步帮助您调整估计器(分类器的另一个术语):
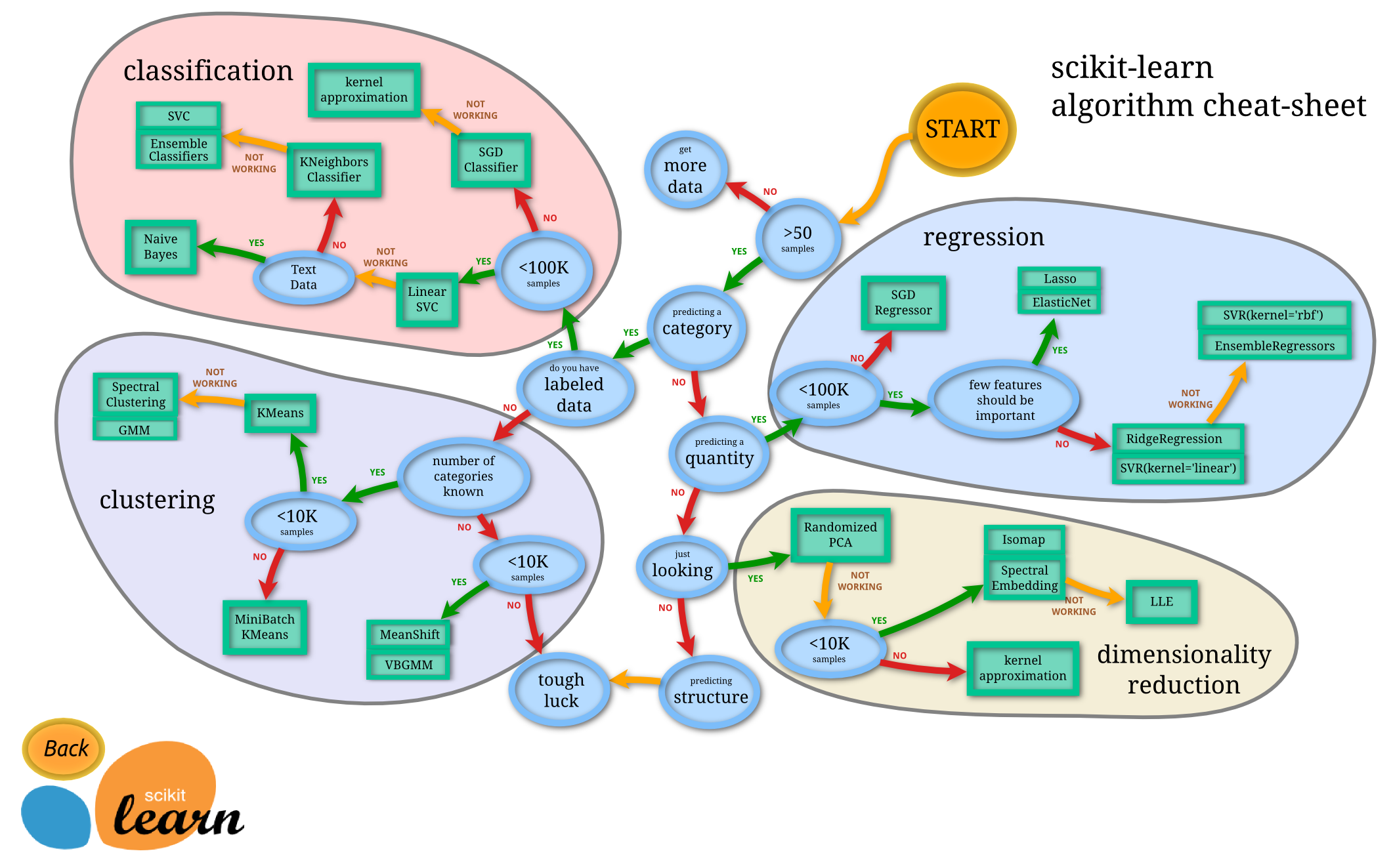
提示:在线查看路线图并沿着路线阅读文档。
计划
一旦您清楚了解了您的数据,这张路线图就非常有用,因为您可以沿着路线并做出决定:
- 我们有超过 50 个样本
- 我们想要预测一个类别
- 我们有标记过的数据
- 我们的样本数少于 100000
- ✨ 我们可以选择线性 SVC
- 如果那不起作用,既然我们有数值数据
- 我们可以尝试 ✨ K-近邻分类器
- 如果那不起作用,试试 ✨ SVC 和 ✨ 集成分类器
- 我们可以尝试 ✨ K-近邻分类器
这是一条非常有用的线索。
练习 - 拆分数据
按照这个路线,我们应该从导入一些要使用的库来开始。
-
导入需要的库:
from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve import numpy as np -
拆分您的训练数据和测试数据:
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
线性 SVC 分类器
支持向量分类(SVC)是机器学习方法支持向量机家族中的一个子类(参阅下方内容,学习更多相关知识)。用这种方法您可以选择一个 kernel 去决定如何聚类标签。C 参数指的是“正则化”,它将参数的影响正则化。kernel 可以是其中的一项;这里我们将 kernel 设置为 linear 来使用线性 SVC。probability 默认为 false,这里我们将其设置为 true 来收集概率估计。我们还将 random_state 设置为 0 去打乱数据来获得概率。
练习 - 使用线性 SVC
我们通过创建一个分类器数组来开始。在我们测试时您可以逐步向这个数组中添加分类器。
-
从一个线性 SVC 开始:
C = 10 # 创建不同的分类器 classifiers = { 'Linear SVC': SVC(kernel='linear', C=C, probability=True,random_state=0) } -
使用线性 SVC 训练您的模型并打印报告:
n_classifiers = len(classifiers) for index, (name, classifier) in enumerate(classifiers.items()): classifier.fit(X_train, np.ravel(y_train)) y_pred = classifier.predict(X_test) accuracy = accuracy_score(y_test, y_pred) print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100)) print(classification_report(y_test,y_pred))结果看上去不错:
Accuracy (train) for Linear SVC: 78.6% precision recall f1-score support chinese 0.71 0.67 0.69 242 indian 0.88 0.86 0.87 234 japanese 0.79 0.74 0.76 254 korean 0.85 0.81 0.83 242 thai 0.71 0.86 0.78 227 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
K-近邻分类器
K-近邻是机器学习方法最近邻家族的一部分,可以用来进行有监督和无监督学习。这种方法创建了预定个数的点,并且数据被聚集在这些点的四周,这样数据的大致标签可以被预测出来。
练习 - 使用 K-近邻分类器
前面的分类器都很不错,并且能在数据集上起作用,但是我们可能需要更好的精度。来试试 K-近邻分类器。
-
给您的分类器数组添加一行(在线性 SVC 分类器后添加逗号):
'KNN classifier': KNeighborsClassifier(C),结果有点糟糕:
Accuracy (train) for KNN classifier: 73.8% precision recall f1-score support chinese 0.64 0.67 0.66 242 indian 0.86 0.78 0.82 234 japanese 0.66 0.83 0.74 254 korean 0.94 0.58 0.72 242 thai 0.71 0.82 0.76 227 accuracy 0.74 1199 macro avg 0.76 0.74 0.74 1199 weighted avg 0.76 0.74 0.74 1199✅ 了解 K-近邻
Support Vector 分类器
Support-Vector 分类器是机器学习方法支持向量机家族的一部分,被用于分类和回归任务。为了最大化两个类别之间的距离,支持向量机将“训练样例映射为空间中不同的点”。然后数据被映射为距离,所以它们的类别可以得到预测。
练习 - 使用 Support Vector 分类器
为了更好的精度,我们尝试 Support Vector 分类器。
-
在 K-近邻分类器后添加逗号,然后添加下面一行:
'SVC': SVC(),结果相当不错!
Accuracy (train) for SVC: 83.2% precision recall f1-score support chinese 0.79 0.74 0.76 242 indian 0.88 0.90 0.89 234 japanese 0.87 0.81 0.84 254 korean 0.91 0.82 0.86 242 thai 0.74 0.90 0.81 227 accuracy 0.83 1199 macro avg 0.84 0.83 0.83 1199 weighted avg 0.84 0.83 0.83 1199✅ 了解 Support-Vectors
集成分类器
尽管之前的测试结果相当不错,我们还是沿着路线走到最后吧。我们来尝试一些集成分类器,特别是随机森林和 AdaBoost:
'RFST': RandomForestClassifier(n_estimators=100),
'ADA': AdaBoostClassifier(n_estimators=100)
结果非常好,尤其是随机森林方法的:
Accuracy (train) for RFST: 84.5%
precision recall f1-score support
chinese 0.80 0.77 0.78 242
indian 0.89 0.92 0.90 234
japanese 0.86 0.84 0.85 254
korean 0.88 0.83 0.85 242
thai 0.80 0.87 0.83 227
accuracy 0.84 1199
macro avg 0.85 0.85 0.84 1199
weighted avg 0.85 0.84 0.84 1199
Accuracy (train) for ADA: 72.4%
precision recall f1-score support
chinese 0.64 0.49 0.56 242
indian 0.91 0.83 0.87 234
japanese 0.68 0.69 0.69 254
korean 0.73 0.79 0.76 242
thai 0.67 0.83 0.74 227
accuracy 0.72 1199
macro avg 0.73 0.73 0.72 1199
weighted avg 0.73 0.72 0.72 1199
✅ 学习集成分类器
这种机器学习方法"组合了各种基本估计器的预测"来提高模型质量。在我们的示例中,我们使用随机森林和 AdaBoost。
-
随机森林是一种平均化方法,它建立了一个注入了随机性的“决策树森林”以避免过度拟合。n_estimators 参数设置了随机森林中树的数量。
-
AdaBoost 在数据集上拟合一个分类器,然后在同一数据集上拟合分类器的额外副本。它关注并调整错误分类实例的权重,以便后续的分类器更多地关注和修正。
🚀挑战
这些技术方法每个都有很多能够让您微调的参数。研究每一个的默认参数,并思考调整这些参数对模型质量有何意义。
课后测验
回顾与自学
课程中出现了很多术语,花点时间浏览术语表来复习一下它们吧!