15 KiB
Clasificadores de cocina 1
En esta lección, usarás el conjunto de datos que guardaste en la última lección llena de equilibrio, datos limpios todo sobre cocinas.
Usarás este conjunto de datos con una variedad de clasificadores para predecir una cocina nacional dada basado en un grupo de ingredientes. Mientras lo haces, aprenderás más acerca de algunas formas en que los algoritmos pueden ser aprovechados para las tareas de clasificación.
Examen previo a la lección
Preparación
Asumiendo que completaste la Lección 1, asegura que existe un archivo cleaned_cuisines.csv en el directorio raíz /data para estas cuatro lecciones.
Ejercicio - predice una cocina nacional
-
Trabaja en el directorio notebook.ipynb de la lección, importa ese archivo junto con la biblioteca Pandas:
import pandas as pd cuisines_df = pd.read_csv("../data/cleaned_cuisines.csv") cuisines_df.head()Los datos lucen así:
| Unnamed: 0 | cuisine | almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | indian | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 3 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 4 | indian | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
-
Ahora, importa varias bibliotecas más:
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report, precision_recall_curve from sklearn.svm import SVC import numpy as np -
Divide las coordenadas X e Y en dos diferentes dataframes para entrenar.
cuisinepuede ser el dataframe de las etiquetas:cuisines_label_df = cuisines_df['cuisine'] cuisines_label_df.head()Se verá así:
0 indian 1 indian 2 indian 3 indian 4 indian Name: cuisine, dtype: object -
Elimina la columna
Unnamed: 0y la columnacuisine, llamando adrop(). Guarda el resto de los datos como características entrenables:cuisines_feature_df = cuisines_df.drop(['Unnamed: 0', 'cuisine'], axis=1) cuisines_feature_df.head()Tus características lucen así:
| almond | angelica | anise | anise_seed | apple | apple_brandy | apricot | armagnac | artemisia | artichoke | ... | whiskey | white_bread | white_wine | whole_grain_wheat_flour | wine | wood | yam | yeast | yogurt | zucchini | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
¡Ahora ya estás listo para entrenar tu modelo!
Eligiendo tu clasificador
Ahora que tus datos están limpios y listos para entrenamiento, tienes que decidir qué algoritmo usar para hacer el trabajo.
Scikit-learn agrupa clasificaciones bajo aprendizaje supervisado, y en esa categoría encontrarás muchas formas de clasificar. La variedad es bastante abrumadora a primera vista. Los siguientes métodos incluyen técnicas de clasificación:
- Modelos lineales
- Máquinas de vectores de soporte
- Descenso de gradiente estocástico
- Vecinos más cercanos
- Procesos Gaussianos
- Árboles de decisión
- Métodos de conjunto (clasificador de votos)
- Algoritmos multiclase y multisalida (clasificación multiclase y multietiqueta, clasificación multiclase-multisalida)
También puedes usar redes neuronales para clasificar los datos, pero eso está fuera del alcance de esta lección.
¿Qué clasificador usar?
Así que, ¿qué clasificador deberías elegir? A menudo, el ejecutar varios y buscar un buen resultado es una forma de probar. Scikit-lean ofrece una comparación lado a lado en un conjunto de datos creado, comparando KNeighbors, SVC two ways, GaussianProcessClassifier, DecisionTreeClassifier, RandomForestClassifier, MLPClassifier, AdaBoostClassifier, GaussianNB y QuadraticDiscrinationAnalysis, mostrando los resultados visualizados:
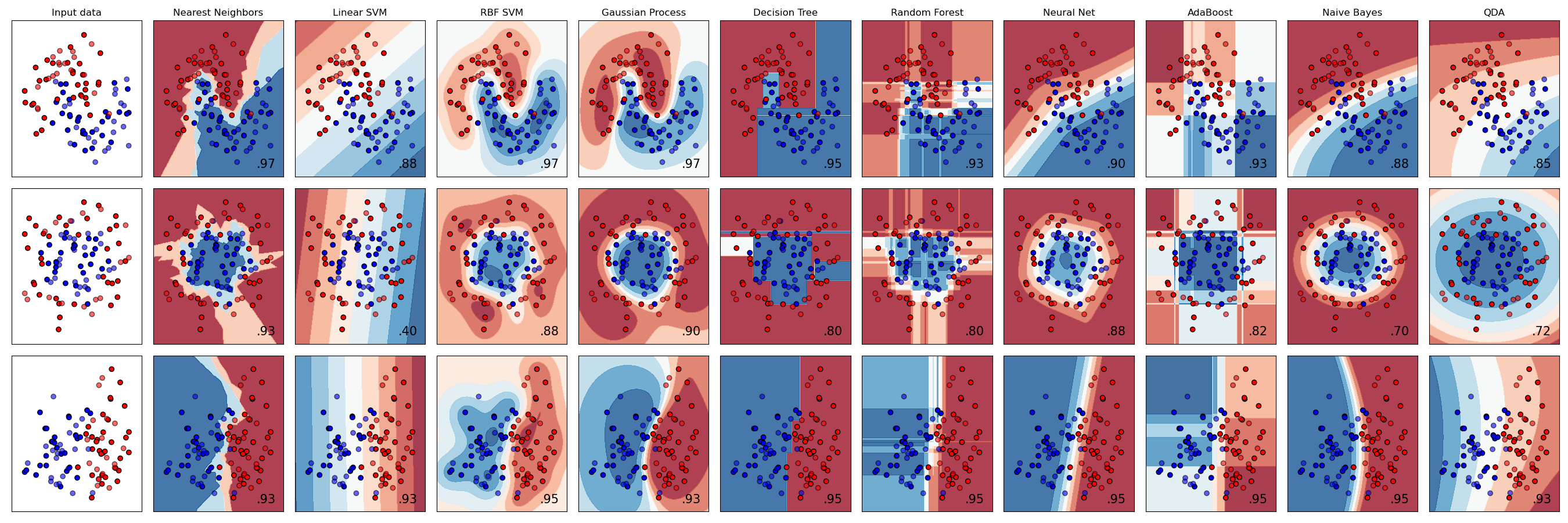
Gráficos generados en la documentación de Scikit-learn
AutoML resuelve este problema de forma pulcra al ejecutar estas comparaciones en la nube, permitiéndote elegir el mejor algoritmo para tus datos. Pruébalo aquí
Un mejor enfoque
Una mejor forma a estar adivinando, es seguir las ideas de esta hoja de trucos de ML. Aquí, descubrimos que, para nuestro problema multiclase, tenemos algunas opciones:

Una sección de la hoja de trucos de algoritmos de Microsoft, detallando opciones de clasificación multiclase.
✅ ¡Descarga esta hoja de trucos, imprímela y cuélgala en tu pared!
Razonamiento
Veamos si podemos razonar nuestro camino a través de diferentes enfoques dadas las restricciones que tenemos:
- Las redes neuronales son muy pesadas. Dado nuestro conjunto de datos limpio aunque mínimo, y el hecho que estamos ejecutando el entrenamiento de forma local vía los notebooks, las redes neuronales son demasiado pesadas para esta tarea.
- Sin clasificador de dos clases. No usamos clasificador de dos clases, por lo que descarta un uno-contra-todos.
- El árbol de decisión o la regresión logística podría funcionar. Un árbol de decisión podría funcionar, o la regresión logística para datos multiclase.
- Los árboles de decisión potenciados multiclase resuelven un problema diferente. El árbol de decisión potenciado multiclase es el más adecuado para tareas no paramétricas, por ejemplo, las tareas designadas para construir clasificaciones, por lo que no es útil para nosotros.
Usando Scikit-learn
Usaremos Scikit-learn para analizar nuestros datos. Sin embargo, hay varias formas de usar la regresión logística en Scikit-learn. Da un vistazo a los parámetros a pasar.
En esencia, hay dos parámetros importantes - multi_class y solver - que necesitamos especificar, cuando le pedimos a Scikit-learn realice una regresión logística. El valor multi_class aplica cierto comportamiento. El valor del solucionador (solver) es el algoritmo a usar. No todos los solucionadores pueden ser emparejados con todos los valores multi_class.
De acuerdo a la documentación, en el caso multiclase, el algoritmo de entrenamiento:
- Usa el esquema uno contra el resto (OvsR), si la opción
multi_classse configura aovr - Usa la pérdida de entropía cruzada, si la opción
multi_classse configura amultinomial(Actualmente la opciónmultinomiales soportada sólo por los solucionadores ‘lbfgs’, ‘sag’, ‘saga’ y ‘newton-cg’.).
🎓 Aquí, el 'esquema' puede ser 'ovr' (one-vs-rest) o 'multinomial'. Ya que la regresión logística está diseñada realmente para soportar la clasificación binaria, estos esquemas te permiten manejar mejor las tareas de clasificación multiclase [fuente](https://machinelea rningmastery.com/one-vs-rest-and-one-vs-one-for-multi-class-classification/).
🎓 El 'solucionador' es definido como "el algoritmo a usar en el problema de optimización" fuente.
Scikit-learn ofrece esta tabla para explicar como los solucionadores manejan distintos desafíos presentados por distintas clases de datos estructurados:
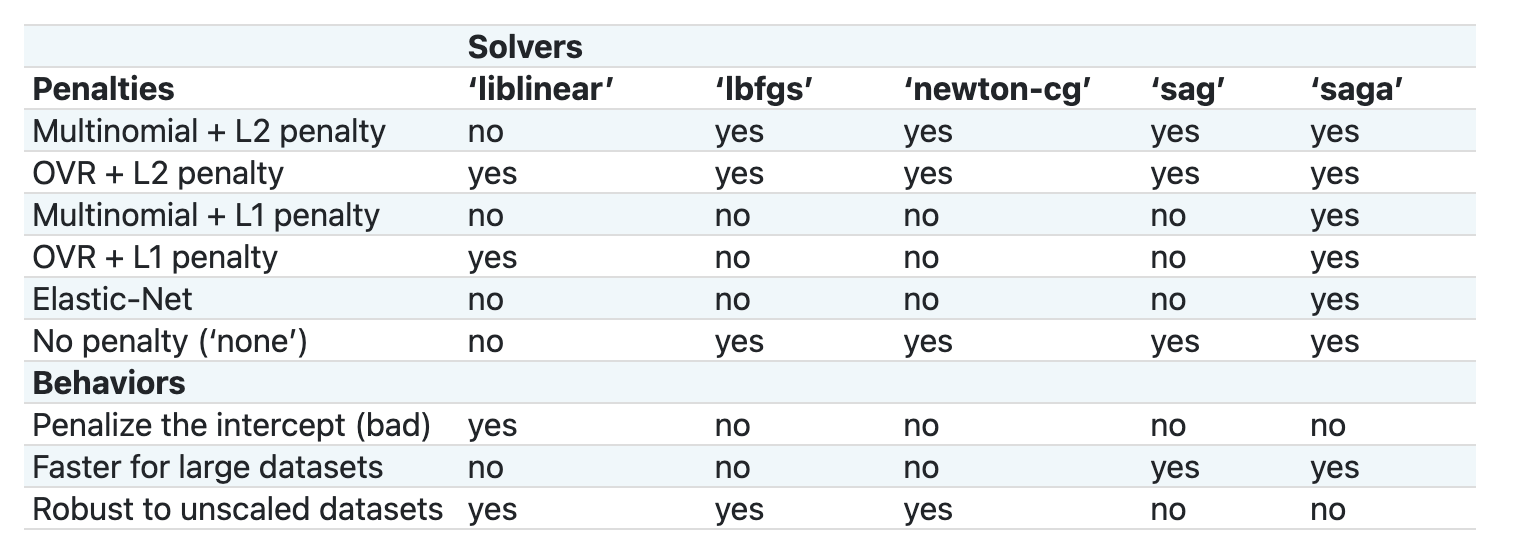
Ejercicio - divide los datos
Nos podemos enfocar en la regresión logística para nuestra primer prueba de entrenamiento ya que recién aprendiste sobre esto último en la lección anterior.
Divide tus datos en los grupos 'training' y 'testing' al llamar a train_test_split():
X_train, X_test, y_train, y_test = train_test_split(cuisines_feature_df, cuisines_label_df, test_size=0.3)
Ejercicio - aplica la regresión logística
Ya que estás usando un caso multiclase, necesitas elegir qué esquema usar y qué solucionador configurar. Usa LogisticRegression con un ajuste multiclase y el solucionador liblinear para entrenar.
-
Crea un regresión logística con un multi_class configurado a
ovry el solucionador ajustado aliblinear:lr = LogisticRegression(multi_class='ovr',solver='liblinear') model = lr.fit(X_train, np.ravel(y_train)) accuracy = model.score(X_test, y_test) print ("Accuracy is {}".format(accuracy))✅ Prueba un solucionador diferente como
lbfgs, el cual suele ser configurado por defectoNota, usa la función de Pandas
ravelpara aplanar tus datos cuando sea necesario.¡La precisión es buena por enciam del **80%*!
-
Puedes ver este modelo en acción al probar una fila de datos (#50):
print(f'ingredients: {X_test.iloc[50][X_test.iloc[50]!=0].keys()}') print(f'cuisine: {y_test.iloc[50]}')El resultado es impreso:
ingredients: Index(['cilantro', 'onion', 'pea', 'potato', 'tomato', 'vegetable_oil'], dtype='object') cuisine: indian✅ Prueba un número de fila distinto y revisa los resultados
-
Indagando más, puedes revisar la precisión de esta predicción:
test= X_test.iloc[50].values.reshape(-1, 1).T proba = model.predict_proba(test) classes = model.classes_ resultdf = pd.DataFrame(data=proba, columns=classes) topPrediction = resultdf.T.sort_values(by=[0], ascending = [False]) topPrediction.head()El resultado es impreso - La cocina India es su mejor conjetura, con buena probabilidad:
0 indian 0.715851 chinese 0.229475 japanese 0.029763 korean 0.017277 thai 0.007634 ✅ ¿Puedes explicar por qué el modelo está muy seguro de que esta es una cocina India?
-
Obtén mayor detalle al imprimir un reporte de clasificación, como lo hiciste en las lecciones de regresión:
y_pred = model.predict(X_test) print(classification_report(y_test,y_pred))precision recall f1-score support chinese 0.73 0.71 0.72 229 indian 0.91 0.93 0.92 254 japanese 0.70 0.75 0.72 220 korean 0.86 0.76 0.81 242 thai 0.79 0.85 0.82 254 accuracy 0.80 1199 macro avg 0.80 0.80 0.80 1199 weighted avg 0.80 0.80 0.80 1199
🚀Desafío
En esta lección, usaste tus datos limpios para construir un modelo de aprendizaje automático que puede predecir una cocina nacional basado en una serie de ingredientes. Toma un tiempo para leer las diversas opciones que provee Scikit-learn para clasificar los datos. Profundiza en el concepto de 'solucionador' para comprender que sucede detrás de escena.
Examen posterior a la lección
Revisión y autoestudio
Indaga un poco más en las matemáticas detrás de la regresión logística en esta lección