17 KiB
Regressão logística para prever categorias
Infographic by Dasani Madipalli
Questionário pré-palestra
Esta lição está disponível em R!
Introdução
Nesta lição final sobre Regressão, uma das técnicas básicas classic ML, vamos dar uma olhada na Regressão Logística. Usaria esta técnica para descobrir padrões para prever categorias binárias. Isto é chocolate doce ou não? Esta doença é contagiosa ou não? Este cliente escolherá este produto ou não?
Nesta lição, aprenderá:
- Uma nova biblioteca para visualização de dados
- Técnicas de regressão logística
✅ aprofundar a sua compreensão de trabalhar com este tipo de regressão neste módulo Aprender
Pré-requisito
Tendo trabalhado com os dados da abóbora, estamos agora familiarizados o suficiente para perceber que há uma categoria binária com a qual podemos trabalhar: Cor.
Vamos construir um modelo de regressão logística para prever que, dadas algumas variáveis, what cor de uma dada abóbora é provável que be (🎃 laranja ou 👻 branco).
Porque estamos a falar de classificação binária num agrupamento de aulas sobre regressão? Apenas para conveniência linguística, uma vez que a regressão logística é realmente um método de classificação,embora um linear baseado. Saiba mais sobre outras formas de classificar os dados no próximo grupo de aulas.
Definir a pergunta
Para os nossos propósitos, vamos expressar isto como um binário: "Laranja" ou "Não Laranja". Existe também uma categoria de "listrado" no nosso conjunto de dados, mas há poucos casos dele, pelo que não a utilizaremos. Desaparece assim que removemos os valores nulos do conjunto de dados, de qualquer forma.
🎃 facto divertido, às vezes chamamos abóboras brancas de abóboras "fantasma". Não são muito fáceis de esculpir, por isso não são tão populares como os laranjas, mas são fixes!
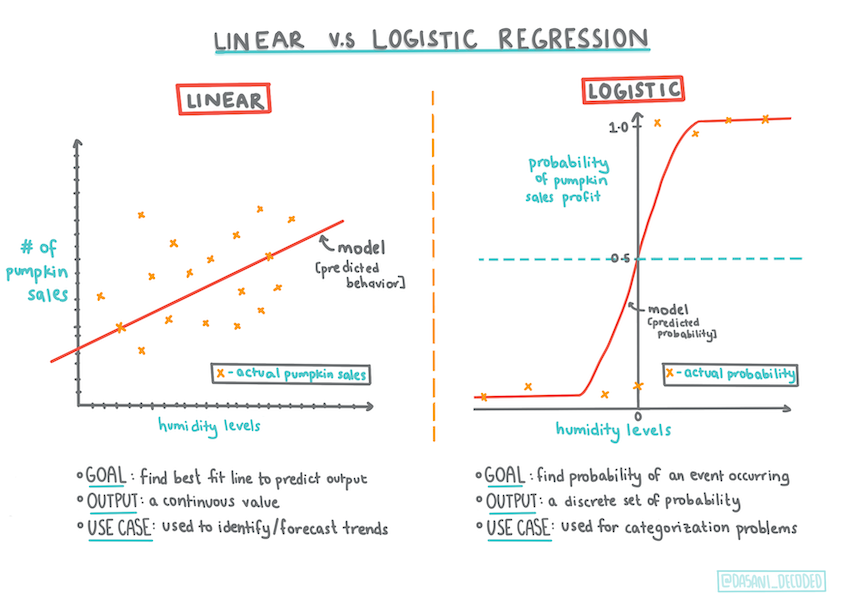
About logistic regression
A regressão logística difere da regressão linear, que aprendeu anteriormente, de algumas formas importantes.
Classificação binária
A regressão logística não oferece as mesmas características que a regressão linear. O primeiro oferece uma previsão sobre uma categoria binária ("laranja ou não laranja"),) enquanto esta é capaz de prever valores contínuos, por exemplo dada a origem de uma abóbora e a hora da colheita, how muito o seu preço irá rise.
Infographic by Dasani Madipalli
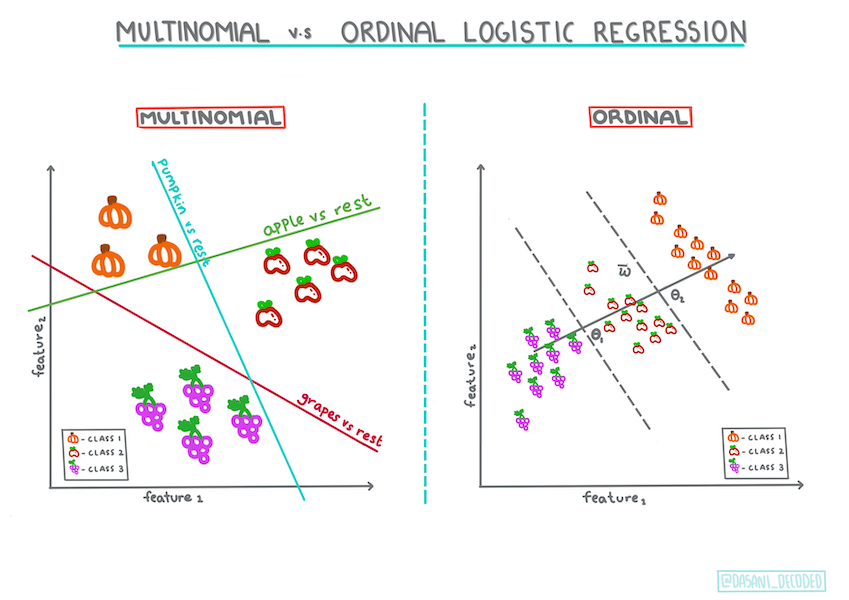
Outras classificações
Existem outros tipos de regressão logística, incluindo multinóia e ordinária:
- Multinomial, que envolve ter mais de uma categoria - "Laranja, Branco e Listrado".
- Ordinal, que envolve categorias ordenadas, úteis se quiséssemos encomendar os nossos resultados logicamente, como as nossas abóboras que são encomendadas por um número finito de tamanhos (mini,sm,med,lg,xl,xxl).
Infographic by Dasani Madipalli
Ainda é linear
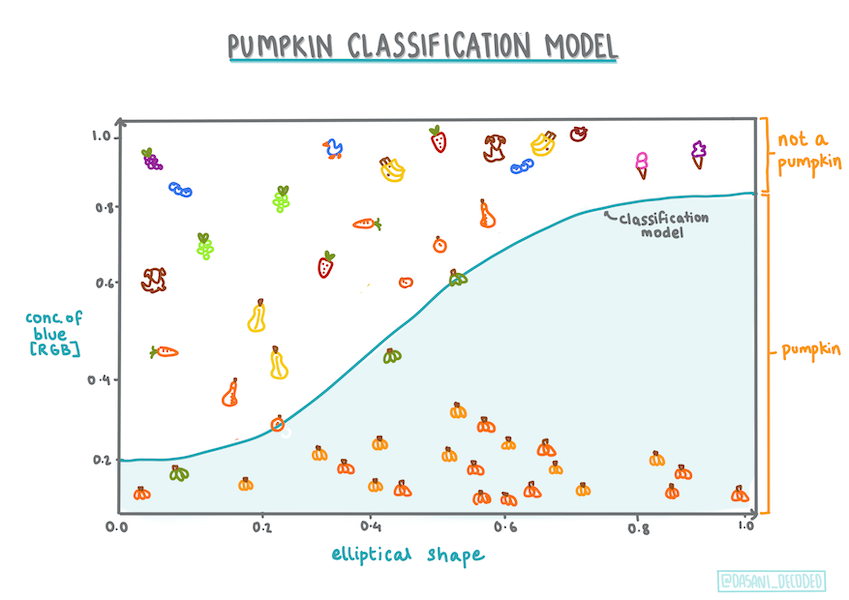
Embora este tipo de Regressão seja tudo sobre "previsões de categoria", ainda funciona melhor quando há uma relação linear clara entre a variável dependente (cor) e as outras variáveis independentes (o resto do conjunto de dados, como o nome e o tamanho da cidade). É bom ter uma ideia de se há alguma linearidade dividindo estas variáveis ou não.
Variáveis NÃO têm que correlacionar
Lembras-te de como a regressão linear funcionou melhor com variáveis mais correlacionadas? A regressão logística é o oposto - as variáveis não têm que se alinhar. Isso funciona para estes dados que têm correlações um pouco fracas.
Precisa de muitos dados limpos
A regressão logística dará resultados mais precisos se utilizar mais dados; nosso pequeno conjunto de dados não é o ideal para esta tarefa, por isso tenha isso em mente.
✅ Pense nos tipos de dados que se emprestariam bem à regressão logística
Exercício - arrumar os dados
Primeiro, limpe um pouco os dados, baixando os valores nulos e selecionando apenas algumas das colunas:
-
Adicione o seguinte código:
from sklearn.preprocessing import LabelEncoder new_columns = ['Color','Origin','Item Size','Variety','City Name','Package'] new_pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1) new_pumpkins.dropna(inplace=True) new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)Pode sempre dar uma olhada no seu novo dataframe:
new_pumpkins.info
Visualização - grelha lado a lado
Por esta altura já já carregou o caderno de entrada com dados de abóbora mais uma vez e limpou-os de modo a preservar um conjunto de dados contendo algumas variáveis, incluindo Color. Vamos visualizar o quadro de dados no caderno usando uma biblioteca diferente: Seaborn, que é construída em Matplotlib que usamos anteriormente.
Seaborn oferece algumas maneiras limpas de visualizar os seus dados. Por exemplo, pode comparar distribuições dos dados por cada ponto numa grelha lado a lado.
-
Crie tal rede através da instantânea
PairGrid, utilizando os nossos dados de abóboranew_pumpkins, seguidos demap():import seaborn as sns g = sns.PairGrid(new_pumpkins) g.map(sns.scatterplot)
Ao observar dados lado a lado, pode ver como os dados de Cor se relacionam com as outras colunas.
✅ Dada esta grelha de dispersão, quais são algumas explorações interessantes que podes imaginar?
Use um enredo de enxame
Uma vez que a Cor é uma categoria binária (Laranja ou Não), chama-se "dados categóricos" e precisa de "uma abordagem mais especializada à visualização". Há outras formas de visualizar a relação desta categoria com outras variáveis.
Você pode visualizar variáveis lado a lado com parcelas seaborn.
-
Experimente um plano de 'enxame' para mostrar a distribuição de valores:
sns.swarmplot(x="Color", y="Item Size", data=new_pumpkins)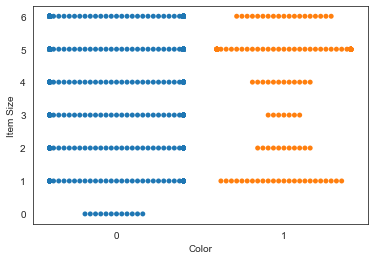
Enredo de violino
Um gráfico de tipo 'violino' é útil, pois você pode visualizar facilmente a forma como os dados nas duas categorias são distribuídos. Os gráficos de violino não funcionam tão bem com conjuntos de dados menores, pois a distribuição é exibida mais 'suavemente'.
-
Como parâmetros
x=Color,kind="violin"e chamadacatplot():sns.catplot(x="Color", y="Item Size", kind="violin", data=new_pumpkins)
✅ Tente criar este enredo, e outros enredos de Seaborn, usando outras variáveis.
Agora que temos uma ideia da relação entre as categorias binárias de cor e o grupo maior de tamanhos, vamos explorar a regressão logística para determinar a cor provável de uma dada abóbora.
🧮 Mostre-Me A Matemática
Lembram-se como a regressão linear frequentemente usava mínimos quadrados ordinários para chegar a um valor? A regressão logística baseia-se no conceito de "máxima verossimilhança" utilizando funções sigmoides. Uma 'Função Sigmoide' em uma trama se parece com uma forma 'S'. Ele pega um valor e o mapeia para algum lugar entre 0 e 1. Sua curva também é chamada de "curva logística". Sua fórmula é assim:
onde o ponto médio do sigmoide se encontra no ponto 0 de x, L é o valor máximo da curva, e k é a inclinação da curva. Se o resultado da função for maior que 0,5, o rótulo em questão receberá a classe '1' da escolha binária. Caso contrário, será classificado como "0".

Crie o seu modelo
Construir um modelo para encontrar essas classificações binárias é surpreendentemente simples no Scikit-learn.
-
Selecione as variáveis que deseja utilizar no seu modelo de classificação e divida os conjuntos de treino e teste que chamam
train_test_split():from sklearn.model_selection import train_test_split Selected_features = ['Origin','Item Size','Variety','City Name','Package'] X = new_pumpkins[Selected_features] y = new_pumpkins['Color'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) -
Agora você pode treinar seu modelo, chamando
fit()com seus dados de treinamento e imprimir o resultado:from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test) print(classification_report(y_test, predictions)) print('Predicted labels: ', predictions) print('Accuracy: ', accuracy_score(y_test, predictions))Dê uma olhada no placar do seu modelo. Não é tão ruim, considerando que você tem apenas cerca de 1000 linhas de dados:
precision recall f1-score support 0 0.85 0.95 0.90 166 1 0.38 0.15 0.22 33 accuracy 0.82 199 macro avg 0.62 0.55 0.56 199 weighted avg 0.77 0.82 0.78 199 Predicted labels: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 1 0]
Melhor compreensão através de uma matriz de confusão
Enquanto você pode obter um relatório de placar termos imprimindo os itens acima, você pode ser capaz de entender seu modelo mais facilmente usando uma matriz confusão para nos ajudar a entender como o modelo está se saindo.
🎓 A 'matriz de confusão' (ou 'matriz de erros') é uma tabela que expressa os verdadeiros versus falsos positivos e negativos do seu modelo, avaliando assim a precisão das previsões.
-
Para usar uma métrica de confusão, chame
confusion_matrix():from sklearn.metrics import confusion_matrix confusion_matrix(y_test, predictions)Dê uma olhada na matriz de confusão do seu modelo:
array([[162, 4], [ 33, 0]])
No Scikit-learn, matrizes de confusão Linhas (eixo 0) são rótulos reais e colunas (eixo 1) são rótulos previstos.
| 0 | 1 | |
|---|---|---|
| 0 | TN | FP |
| 1 | FN | TP |
O que está acontecendo aqui? Digamos que nosso modelo é solicitado a classificar abóboras entre duas categorias binárias, categoria 'laranja' e categoria 'não-laranja'.
- Se o seu modelo prevê uma abóbora como não laranja e pertence à categoria 'não-laranja' na realidade chamamos-lhe um verdadeiro negativo, mostrado pelo número superior esquerdo.
- Se o seu modelo prevê uma abóbora como laranja e pertence à categoria 'não-laranja' na realidade chamamos-lhe um falso negativo, mostrado pelo número inferior esquerdo.
- Se o seu modelo prevê uma abóbora como não laranja e pertence à categoria 'laranja' na realidade chamamos-lhe um falso positivo, mostrado pelo número superior direito.
- Se o seu modelo prevê uma abóbora como laranja e ela pertence à categoria 'laranja' na realidade nós chamamos de um verdadeiro positivo, mostrado pelo número inferior direito.
Como vocês devem ter adivinhado, é preferível ter um número maior de verdadeiros positivos e verdadeiros negativos e um número menor de falsos positivos e falsos negativos, o que implica que o modelo tem melhor desempenho.
Como a matriz de confusão se relaciona com precisão e evocação? Lembre-se, o relatório de classificação impresso acima mostrou precisão (0,83) e recuperação (0,98).
Precision = tp / (tp + fp) = 162 / (162 + 33) = 0.8307692307692308
Recall = tp / (tp + fn) = 162 / (162 + 4) = 0.9759036144578314
✅ Q: De acordo com a matriz de confusão, como foi o modelo? A: Nada mal. há um bom número de verdadeiros negativos, mas também vários falsos negativos.
Vamos revisitar os termos que vimos anteriormente com a ajuda do mapeamento da matriz confusão de TP/TN e FP/FN:
🎓 precisão: TP/(TP + FP) A fração de instâncias relevantes entre as instâncias recuperadas (por exemplo, quais rótulos estavam bem rotulados)
🎓 Chamada: TP/(TP + FN) A fração de instâncias relevantes que foram recuperadas, sejam bem rotuladas ou não
🎓 f1- score: (2 * precisão * recolha)/(precisão + recolha) Uma média ponderada da precisão e recolha, sendo a melhor 1 e a pior 0
Suporte 🎓: O número de ocorrências de cada rótulo recuperado
🎓 precisão: (TP + TN)/(TP + TN + FP + FN) A percentagem de rótulos previstos com precisão para uma amostra.
🎓 Méd. de Macro: O cálculo das métricas médias não ponderadas para cada rótulo, sem levar em conta o desequilíbrio do rótulo.
🎓 Média Ponderada: O cálculo das métricas médias para cada label, levando em conta o desequilíbrio de label ponderando-as pelo suporte (o número de instâncias verdadeiras para cada label).
Consegue pensar qual métrica deve observar se quiser que o seu modelo reduza o número de falsos negativos?
Visualizar a curva de ROC deste modelo
Este não é um mau modelo; sua precisão está na faixa de 80%, então idealmente você poderia usá-lo para prever a cor de uma abóbora dado um conjunto de variáveis.
Vamos fazer mais uma visualização para ver a chamada pontuação 'ROC':
from sklearn.metrics import roc_curve, roc_auc_score
y_scores = model.predict_proba(X_test)
# calculate ROC curve
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:,1])
sns.lineplot([0, 1], [0, 1])
sns.lineplot(fpr, tpr)
Usando Seaborn novamente, plote a Característica de operação de recepção ou ROC do modelo. Curvas ROC são frequentemente usadas para obter uma visão da saída de um classificador em termos de seus verdadeiros versus falsos positivos. "As curvas ROC geralmente apresentam taxa positiva verdadeira no eixo Y e taxa positiva falsa no eixo X." Assim, a inclinação da curva e o espaço entre a linha do ponto médio e a matéria da curva: você quer uma curva que rapidamente se encaminha para cima e sobre a linha. No nosso caso, há falsos positivos para começar, e então a linha se encaminha para cima e para cima corretamente:

Finalmente, use o Scikit-learn roc_auc_score API para calcular a 'Área sob a curva' (AUC) real:
auc = roc_auc_score(y_test,y_scores[:,1])
print(auc)
O resultado é 0,6976998904709748. Dado que a AUC varia de 0 a 1, você quer uma grande pontuação, uma vez que um modelo que é 100% correto em suas previsões terá uma AUC de 1; nesse caso, o modelo é muito bom.
Em lições futuras sobre classificações, você aprenderá a iterar para melhorar as pontuações do seu modelo. Mas por enquanto, parabéns! Você completou essas lições de regressão!
🚀Desafio
Há muito mais a desempacotar em relação à regressão logística! Mas a melhor maneira de aprender é experimentar. Encontre um conjunto de dados que se preste a esse tipo de análise e construa um modelo com ele. O que você aprende? dica: tente Kaggle para obter conjuntos de dados interessantes.
Teste pós-aula
Análise e autoestudo
Leia as primeiras páginas de este artigo de Stanford sobre alguns usos práticos para regressão logística. Pense em tarefas que são mais adequadas para um ou outro tipo de tarefas de regressão que estudamos até agora. O que funcionaria melhor?