18 KiB
Regresión logística para predecir categorías
Infografía de Dasani Madipalli
Examen previo a la lección
Esta lección se encuentra disponible en R!
Introducción
En esta lección final de Regresión, una de las técnicas básicas clásicas de aprendizaje automático, echaremos un vistazo a la regresión logística. Usarás esta técnica para descubrir patrones que predigan categorías binarias. ¿Este dulce es un chocolate o no lo es? ¿Ésta enfermedad es contagiosa o no?, ¿Este cliente eligirá este producto o no?
En esta lección, aprenderás:
- Una nueva librería para visualización de datos
- Técnicas para regresión logística
✅ Profundiza tu entendimiento de trabajo con este tipo de regresión en este [módulo de aprendizaje(https://docs.microsoft.com/learn/modules/train-evaluate-classification-models?WT.mc_id=academic-15963-cxa)
Requisitos previos
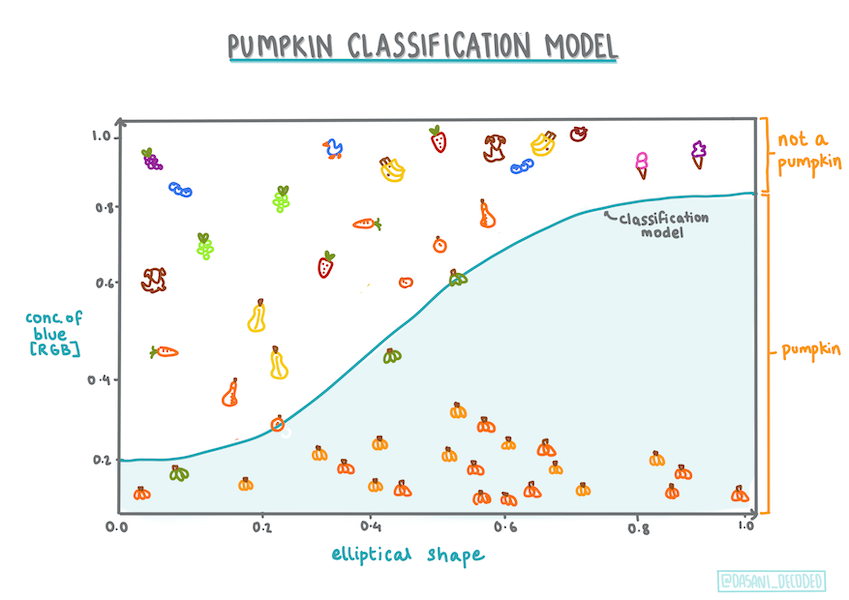
Haber trabajado con los datos de calabazas, ahora estamos suficientemente familiarizados con estos para entender que hay una categoría binaria que podemos trabajar con Color.
Construyamos un modelo de regresión logística para predecirlo, dadas algunas variables, qué color podría tener una calabaza dada (naranja 🎃 o blanca 👻).
¿Porqué estamos hablando acerca de clasificación binaria en un grupo de lecciones acerca de regresión? Sólo por conveniencia ligüística, como la regresión logística es realmente un método de clasificación, aunque de de base lineal. Aprende acerca de otras formas de clasificar los datos en el siguiente grupo de lecciones.
Define la pregunta
Para nuestros propósitos, expresaremos esto como un binario: 'Orange' o 'Not Orange'. También hay una categoría 'striped' en nuestro conjunto de datos pero hay menos instancias de éstas, por lo que no las usaremos. Ésta desaparece una vez que removemos los valores nulos de nuestro conjunto de datos, de cualquier forma.
🎃 Dato gracioso, algunas veces llamamos 'fantasmas' a las calabazas blancas. No son muy fáciles de tallar, por lo que no son tan populares como las calabazas naranjas, ¡pero se ven geniales!
Acerca de la regresión logística
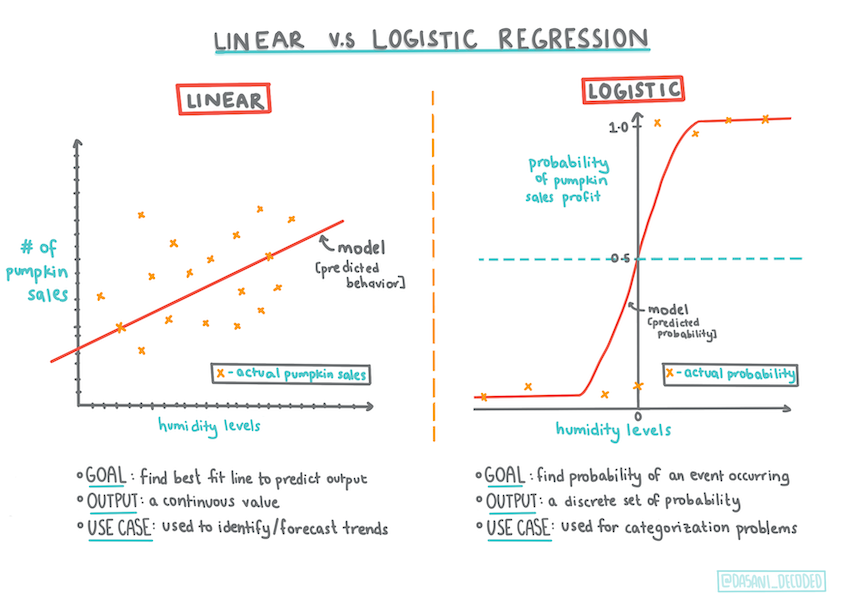
La regresión logística difiere de la regresión lineal, lo cual aprendiste previamentem en unas pocas cosas importantes.
Clasificación binaria
La regresión logística no ofrece las mismas características como la regresión lineal. Las primeras ofrecen una predicción acerca de categorías binarias ("naranja o no naranja") mientras que la segunda es capaz de predecir valores continuos, por ejemplo dado el origen de una calabaza y el tiempo de cosecha, cuánto incrementará su precio.
Infografía de Dasani Madipalli
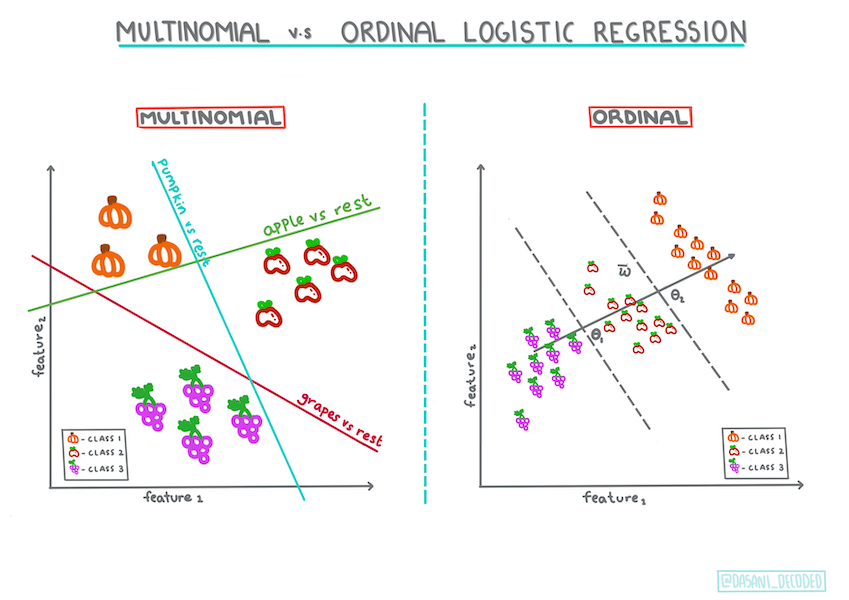
Otras clasificaciones
Existen otros tipo de regresión logística, incluyendo la multinomial y ordinal:
- Multinomial, la cual implica tener más de una categoría - "Orange, White, and Striped".
- Ordinal, la cual implica categorías ordenadas, útil si quisieramos ordenar nuestras resultados logicamente, como nuestras calabazas que están ordenadas por un número finito de tamaños (mini,sm,med,lg,xl,xxl).
Infografía de Dasani Madipalli
Sigue siendo lineal
Aunqeu este tipo de regresión se trata de 'predicciones de categoría', aún funciona mejor cuando hay una relación clara entre la variable dependiente (color) y las otras variables independientes (el resto del conjunto de datos, como el nombre de la ciudad y tamaño). Es bueno tener una idea de si hay alguna linealidad dividiendo estas variables o no.
Las variables NO tienen correlación
¿Recuerdas cómo la regresión lineal funcionó mejor con variables correlacionadas? La regresión logística es lo opuesto - las variables no se tienen que alinear. Eso funciona para estos datos los cuales tienen correlaciones algo débiles.
Necesitas muchos datos limpios
La regresión logística te dará resultados más precisos si usas más datos; nuestro pequeño conjunto de datos no es óptimo para esta tarea, así que tenlo en mente.
✅ piensa en los tipos de datos que se prestarían bien para la regresión logística
Ejercicio - arregla los datos
Primero, limpia los datos un poco, remueve los valores nulos y selecciona sólo algunas de las columnas:
-
Agrega el siguiente código:
from sklearn.preprocessing import LabelEncoder new_columns = ['Color','Origin','Item Size','Variety','City Name','Package'] new_pumpkins = pumpkins.drop([c for c in pumpkins.columns if c not in new_columns], axis=1) new_pumpkins.dropna(inplace=True) new_pumpkins = new_pumpkins.apply(LabelEncoder().fit_transform)Siempre puedes echar un vistazo a tu nuevo dataframe:
new_pumpkins.info
Visualización - cuadrícula lado a lado
Por ahora has cargado el starter notebook con datos de calabazas una vez más y los has limpiado para así preservar el conjunto de datos que contiene unas pocas variables, incluyendo Color. Visualizaremos el dataframe en el notebook usando una librería diferente: Seaborn, el cual es construido en Matplotlib que ya usamos anteriormente.
Seaborn ofrece algunas formas ingeniosas de visualizar tus datos. Por ejemplo, puedes comparar distribuciones de los datos para cada punto en una cuadrícula lado a lado.
-
Crea dicha cuadrícula instanciando
PairGrid, usando nuestros datos de calabazasnew_pumpkins, seguido de la llamada amap():import seaborn as sns g = sns.PairGrid(new_pumpkins) g.map(sns.scatterplot)
Al observar los datos lado a lado, puedes ver como los datos de Color se relacionan con las otras columnas.
✅ Dada la cuadrícula del gráfico de dispersión, ¿cuáles son algunas exploraciones interesantes que puedes visualizar?
Usa un gráfico de enjambre
Dado que Color es una categoría binaria (Naranja o no), se le llaman 'datos categóricos' y necesita 'un enfoque más especializado para visualización. Hay otras formas de visualizar las relaciones de esta categoría con otras variables.
Puedes visualizar variables lado a lado con los gráficos Seaborn.
-
Prueba un gráfico de 'enjambre' (swarm) para mostrar la distribución de valores:
sns.swarmplot(x="Color", y="Item Size", data=new_pumpkins)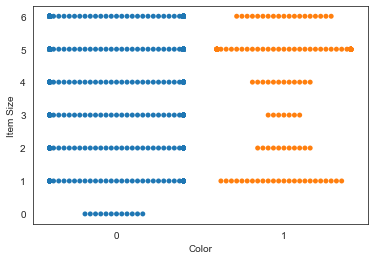
Gráfico de Violín
Un gráfico tipo 'violín' es útil ya que puedes visualizar fácilmente la forma en que los datos se distribuyen en las dos categorías. Los gŕaficos de violín no funcionan muy bien con conjuntos de datos muy pequeños ya que la distribución se muestra más 'suavemente'.
-
Como parámetros
x=Color,kind="violin"y llamadacatplot():sns.catplot(x="Color", y="Item Size", kind="violin", data=new_pumpkins)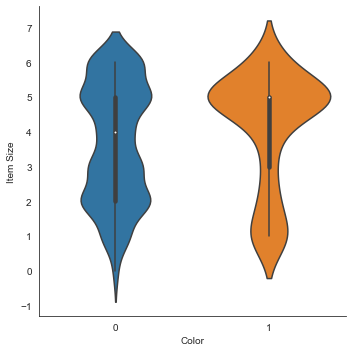
✅ Prueba a crear este gráfico, y otros gráficos de Seaborn, usando otras variables.
Ahora que tenemos una idea de la relación entre las categorías binarias de color y el grupo mayor de tamaños, exploremos la regresión logística para determinar el color probable de cierta calabaza.
🧮 Muéstrame las matemáticas
¿Recuerdas cómo la regresión lineal suele ser usó mínimos cuadrados ordinarios para llegar al valor? La regresión logística se basa en el concepto de 'máxima probabilidad' usando funciones sigmoides. Una 'Función Sigmoide' en una gráfico tiene la forma de una 'S'. Toma una valor lo asigna entre 0 y 1. Su curva también es llamada 'curva logística'. Su fórmula luce así:
Donde el punto medio del sigmoide se encuentra en el punt 0 de las x, L es el valor máximo de la curva, k es la pendiente de la curva. Si el resultado de la función es más de 0.5, la etiqueta en cuestión se le dará la clase '1' de la elección binaria. Si no, será clasificada como '0'.
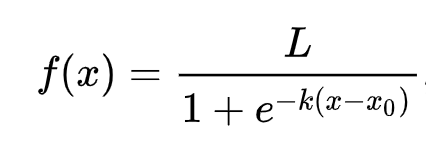
Construye tu modelo
Construir un modelo para encontrar estas clasificaciones binarias es sorprendentemente fácil en Scikit-learn.
-
Elige las variable que quieres usar en tu modelo de clasificación y divide el modelo y los conjuntos de pruebas llamando
train_test_split():from sklearn.model_selection import train_test_split Selected_features = ['Origin','Item Size','Variety','City Name','Package'] X = new_pumpkins[Selected_features] y = new_pumpkins['Color'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) -
Ahora puedes entrenar tu modelo, llamando
fit()con tus datos entrenados, e imprimir su resultado:from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test) print(classification_report(y_test, predictions)) print('Predicted labels: ', predictions) print('Accuracy: ', accuracy_score(y_test, predictions))Echa un vistazo al marcador de tu modelo. No es tan malo, considerando tienes solo 1000 filas de datos:
precision recall f1-score support 0 0.85 0.95 0.90 166 1 0.38 0.15 0.22 33 accuracy 0.82 199 macro avg 0.62 0.55 0.56 199 weighted avg 0.77 0.82 0.78 199 Predicted labels: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 1 0]
Mejor comprensión a través e una matriz de confusión
Mientras puedes obtener un reporte de términos del marcador imprimiendo los elementos de arriba, serás capaz de entender tu modelo más fácilmente usando una matriz de confusión para ayudarnos a entender cómo se desempeña el modelo.
🎓 Una 'matriz de confusión' (o 'matriz de error') es una table que expresa los verdaderos vs los falsos positivos y negativos de tu modelo, para así medir la precisión de las predicciones.
-
Para usar métricas de confusión, llama
confusion_matrix():from sklearn.metrics import confusion_matrix confusion_matrix(y_test, predictions)Echa un vistazo a la matriz de confusión de tu modelo:
array([[162, 4], [ 33, 0]])
En Scikit-learn, las filas de las matriaces de confusión (eje 0) son etiquetas reales y las columnas (eje 1) son etiquetas previstas.
| 0 | 1 | |
|---|---|---|
| 0 | TN | FP |
| 1 | FN | TP |
¿Qué pasa aquí? Digamos que se le pidió a tu modelo clasificar las calabaas entre dos categorías binarias, la categoría 'orange' y la categoría 'not-orange'.
- Si tu modelo predice una calabaza como no naranja y esta pertenece a la categoría 'not-orange' en realidad la llamamos como un verdadero negativo, mostrado por el número superior izquierdo.
- Si tu modelo precice una calabaza como naranja y esta pertenece a la categoría 'not-orange' en realidad la llamamos como un falso negativo, mostrado por el número inferior izquierdo.
- Si tu modelo predice una calabaza como no naranja y este pertenece a la categoría 'orange' en realidad la llamamos como un falso positivo, mostrado por el número superior derecho.
- Si tu modelo predice una calabaza como naranja y esta pertenece a la categoría 'naranja' en realidad la llamamos como un verdadero positivo, mostrado por el número inferior derecho.
Como habrás adivinado, es preferible tener un número mayor de verdaderos positivos y verdaderos negativos, y un número menor de falsos positivos y falsos negativos, lo cual implica que el modelo se desempeña mejor.
¿Cómo se relaciona la matriz de confusión con precision (precisión) y recall (recuerdo)? Recuerda, el reporte de clasificación impreso arriba mostró precisión (0.83) y recuerdo (0.98).
Precision = tp / (tp + fp) = 162 / (162 + 33) = 0.8307692307692308
Recall = tp / (tp + fn) = 162 / (162 + 4) = 0.9759036144578314
✅ Q: De acuerdo a la matriz de confusión, ¿cómo lo hizo el modelo? A: No tan mal; existe un buen número de verdaderos positivos pero también varios falsos negativos.
Repasemos los término que vimos anteriormente con la ayuda de la asignación de la matriz de confusión de TP/TN y FP/FN:
🎓 Precision: TP/(TP + FP) La fración de instancias relevantes entre las instancias recuperadas (ejemplo, qué etiquetas fueron bien etiquetadas)
🎓 Recall: TP/(TP + FN) La fracción de instancias relevantes que fueron recuperadas, bien etiquetadas o no
🎓 f1-score: (2 * precision * recall)/(precision + recall) Un promedio ponderado de precisión y recuerdo, siendo lo mejor 1 y lo pero 0
🎓 Soporte: El número de ocurrencias de cada etiqueta recuperada
🎓 Precisión: (TP + TN)/(TP + TN + FP + FN) El porcentaje de etiquetas previstas de forma precisa para la muestra.
🎓 Promedio de macros: El cálculo de métricas medias no ponderadas para cada etiqueta, no tomando en cuenta el desequilibrio de etiquetas.
🎓 Promedio ponderado: El cálculo de las métricas medias para cada etiqueta, tomando en cuenta el desequilibrio de etiquetas al ponderarlas po su soporte (el número de instancias verdaderas para cada etiqueta).
✅ ¿Puedes pensar cuáles métrcias debes observar si quieres que tu modelo para reducir el número de falsos negativos?
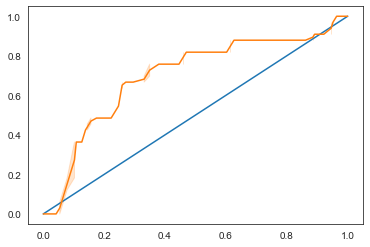
Visualiza la curva ROC de este modelo
Este no es un mal modelo; su precisión está en el rango de 80% ya que idealmente puedes usarlo para precedir el color de una calabaza dado un conjunto de variables.
Hagamos una visualización más para ver el así llamado puntaje 'ROC':
from sklearn.metrics import roc_curve, roc_auc_score
y_scores = model.predict_proba(X_test)
# calculate ROC curve
fpr, tpr, thresholds = roc_curve(y_test, y_scores[:,1])
sns.lineplot([0, 1], [0, 1])
sns.lineplot(fpr, tpr)
Usando de nuevo Seaborn, grafica la característica operativa de recepción del modelo o ROC. Las curvas ROC curves son usadas comúnmente para obtener una vista de la salida de un clasificador en términos de sus verdaderos positivos vs falsos positivos. "Las curvas ROC presentan típicamente la tasa de verdaderos positivos en el eje Y, y la tasa falsos positivos en el eje X." Así, la inclinación de la curvay el espeacio entre la línea del punto medio y la curva importan: quieres una curva que suba rápidamente y sobre la línea. En nuestro caso, hay falsos positivos para empezar, y luego la línea sube hacía arriba y continua propiamente:
Finalmente, usa la API roc_auc_score de Scikit-learn para calcular el 'Área bajo la curva' real (AUC):
auc = roc_auc_score(y_test,y_scores[:,1])
print(auc)
El resultado es 0.6976998904709748. Dado que la AUC varía entre 0 y 1, quieres un puntaje grande, ya que un modelo que es 100% correcto en sus predicciones tendrá un AUC de 1; en este caso el modelo es bastante bueno.
En futuras lecciones de clasificación, aprenderás cómo iterar para mejorar los puntajes de tus modelos. Pero por ahora, ¡felicitaciones!, ¡Haz completado estas lecciones de regresión!
🚀Desafío
¡Hay mucho más para desempacar respecto a la regresión logística! Pero la mejor forma de aprender es experimentar. Encuentra un conjunto de datos que se preste para este tipo de análisis y construye un modelo con él. ¿Qué aprendes? tipo: prueba Kaggle por conjuntos de datos interesantes.
Examen posterior a la lección
Revisión & autoestudio
Lee las primeras páginas de este artículo de Stanford de algunos usos prácticos para la regresión logística. Piensa en las tareas que se ajustan mejor para uno u otro tipo de tareas de regresión que estudiamos hasta el momento. ¿Que funcionaría mejor?