9.7 KiB
機器學習的歷史
作者 Tomomi Imura
課前測驗
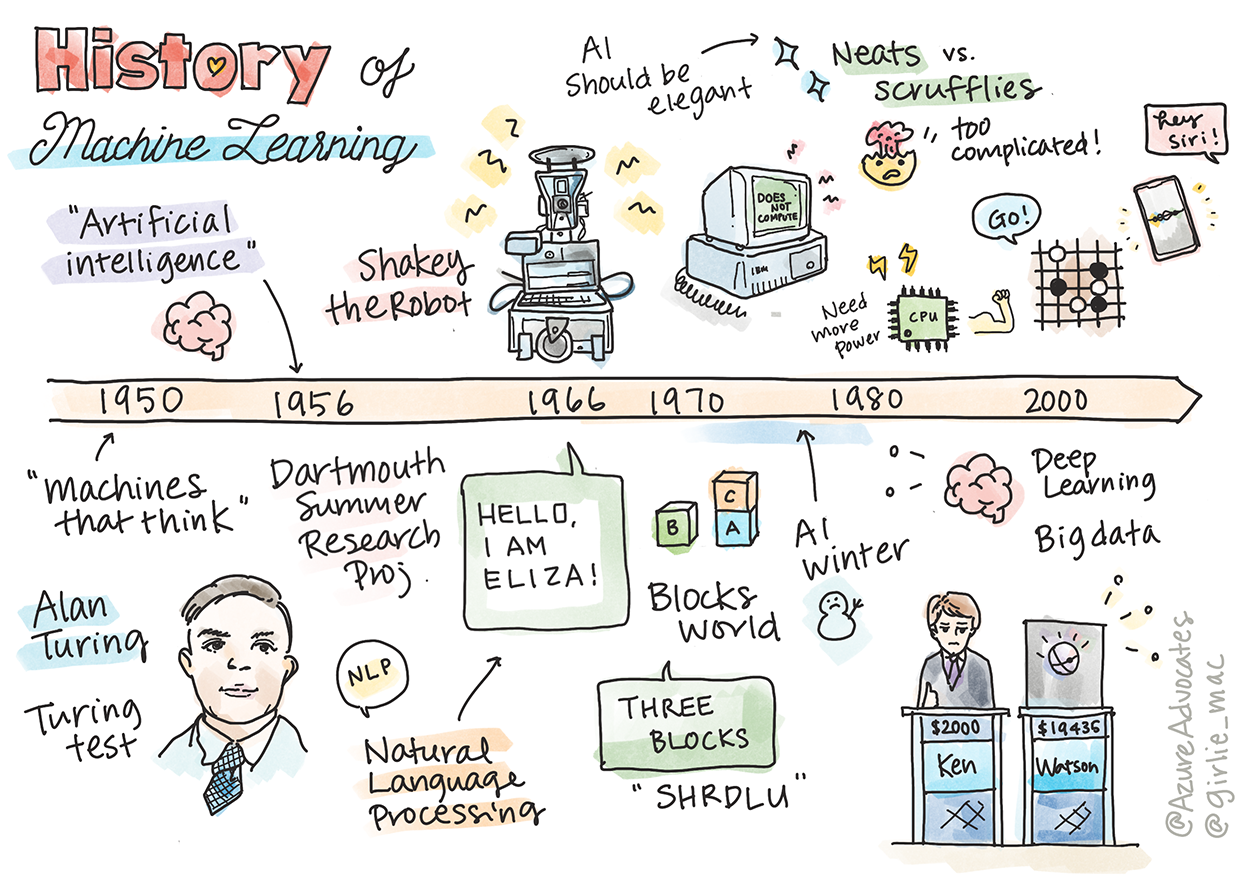
在本課中,我們將走過機器學習和人工智能歷史上的主要裏程碑。
人工智能(AI)作為一個領域的歷史與機器學習的歷史交織在一起,因為支持機器學習的算法和計算能力的進步推動了AI的發展。記住,雖然這些領域作為不同研究領域在 20 世紀 50 年代才開始具體化,但重要的算法、統計、數學、計算和技術發現 要早於和重疊了這個時代。 事實上,數百年來人們一直在思考這些問題:本文討論了「思維機器」這一概念的歷史知識基礎。
主要發現
- 1763, 1812 貝葉斯定理 及其前身。該定理及其應用是推理的基礎,描述了基於先驗知識的事件發生的概率。
- 1805 最小二乘理論由法國數學家 Adrien-Marie Legendre 提出。 你將在我們的回歸單元中了解這一理論,它有助於數據擬合。
- 1913 馬爾可夫鏈以俄羅斯數學家 Andrey Markov 的名字命名,用於描述基於先前狀態的一系列可能事件。
- 1957 感知器是美國心理學家 Frank Rosenblatt 發明的一種線性分類器,是深度學習發展的基礎。
- 1967 最近鄰是一種最初設計用於映射路線的算法。 在 ML 中,它用於檢測模式。
- 1970 反向傳播用於訓練前饋神經網絡。
- 1982 循環神經網絡 是源自產生時間圖的前饋神經網絡的人工神經網絡。
✅ 做點調查。在 ML 和 AI 的歷史上,還有哪些日期是重要的?
1950: 會思考的機器
Alan Turing,一個真正傑出的人,在 2019 年被公眾投票選出 作為 20 世紀最偉大的科學家,他認為有助於為「會思考的機器」的概念打下基礎。他通過創建 圖靈測試來解決反對者和他自己對這一概念的經驗證據的需求,你將在我們的 NLP 課程中進行探索。
1956: 達特茅斯夏季研究項目
「達特茅斯夏季人工智能研究項目是人工智能領域的一個開創性事件,」正是在這裏,人們創造了「人工智能」一詞(來源)。
原則上,學習的每個方面或智能的任何其他特征都可以被精確地描述,以至於可以用機器來模擬它。 首席研究員、數學教授 John McCarthy 希望「基於這樣一種猜想,即學習的每個方面或智能的任何其他特征原則上都可以如此精確地描述,以至於可以製造出一臺機器來模擬它。」 參與者包括該領域的另一位傑出人物 Marvin Minsky。
研討會被認為發起並鼓勵了一些討論,包括「符號方法的興起、專註於有限領域的系統(早期專家系統),以及演繹系統與歸納系統的對比。」(來源)。
1956 - 1974: 「黃金歲月」
從 20 世紀 50 年代到 70 年代中期,樂觀情緒高漲,希望人工智能能夠解決許多問題。1967 年,Marvin Minsky 自信地說,「一代人之內...創造『人工智能』的問題將得到實質性的解決。」(Minsky,Marvin(1967),《計算:有限和無限機器》,新澤西州恩格伍德克利夫斯:Prentice Hall)
自然語言處理研究蓬勃發展,搜索被提煉並變得更加強大,創造了「微觀世界」的概念,在這個概念中,簡單的任務是用簡單的語言指令完成的。
這項研究得到了政府機構的充分資助,在計算和算法方面取得了進展,並建造了智能機器的原型。其中一些機器包括:
-
機器人 Shakey,他們可以「聰明地」操縱和決定如何執行任務。

1972 年的 Shakey
-
Eliza,一個早期的「聊天機器人」,可以與人交談並充當原始的「治療師」。 你將在 NLP 課程中了解有關 Eliza 的更多信息。
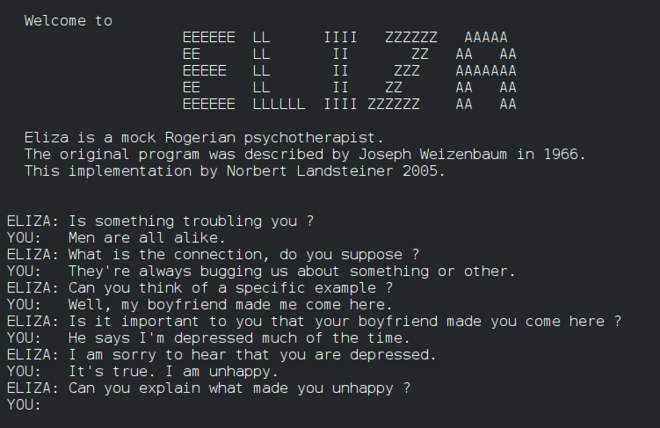
Eliza 的一個版本,一個聊天機器人
-
「積木世界」是一個微觀世界的例子,在那裏積木可以堆疊和分類,並且可以測試教機器做出決策的實驗。 使用 SHRDLU 等庫構建的高級功能有助於推動語言處理向前發展。

🎥 點擊上圖觀看視頻: 積木世界與 SHRDLU
1974 - 1980: AI 的寒冬
到了 20 世紀 70 年代中期,很明顯製造「智能機器」的復雜性被低估了,而且考慮到可用的計算能力,它的前景被誇大了。資金枯竭,市場信心放緩。影響信心的一些問題包括:
- 限製。計算能力太有限了
- 組合爆炸。隨著對計算機的要求越來越高,需要訓練的參數數量呈指數級增長,而計算能力卻沒有平行發展。
- 缺乏數據。 缺乏數據阻礙了測試、開發和改進算法的過程。
- 我們是否在問正確的問題?。 被問到的問題也開始受到質疑。 研究人員開始對他們的方法提出批評:
- 圖靈測試受到質疑的方法之一是「中國房間理論」,該理論認為,「對數字計算機進行編程可能使其看起來能理解語言,但不能產生真正的理解。」 (來源)
- 將「治療師」ELIZA 這樣的人工智能引入社會的倫理受到了挑戰。
與此同時,各種人工智能學派開始形成。 在 「scruffy」 與 「neat AI」 之間建立了二分法。 Scruffy 實驗室對程序進行了數小時的調整,直到獲得所需的結果。 Neat 實驗室「專註於邏輯和形式問題的解決」。 ELIZA 和 SHRDLU 是眾所周知的 scruffy 系統。 在 1980 年代,隨著使 ML 系統可重現的需求出現,neat 方法逐漸走上前沿,因為其結果更易於解釋。
1980s 專家系統
隨著這個領域的發展,它對商業的好處變得越來越明顯,在 20 世紀 80 年代,『專家系統』也開始廣泛流行起來。「專家系統是首批真正成功的人工智能 (AI) 軟件形式之一。」 (來源)。
這種類型的系統實際上是混合系統,部分由定義業務需求的規則引擎和利用規則系統推斷新事實的推理引擎組成。
在這個時代,神經網絡也越來越受到重視。
1987 - 1993: AI 的冷靜期
專業的專家系統硬件的激增造成了過於專業化的不幸後果。個人電腦的興起也與這些大型、專業化、集中化系統展開了競爭。計算機的平民化已經開始,它最終為大數據的現代爆炸鋪平了道路。
1993 - 2011
這個時代見證了一個新的時代,ML 和 AI 能夠解決早期由於缺乏數據和計算能力而導致的一些問題。數據量開始迅速增加,變得越來越廣泛,無論好壞,尤其是 2007 年左右智能手機的出現,計算能力呈指數級增長,算法也隨之發展。這個領域開始變得成熟,因為過去那些隨心所欲的日子開始具體化為一種真正的紀律。
現在
今天,機器學習和人工智能幾乎觸及我們生活的每一個部分。這個時代要求仔細了解這些算法對人類生活的風險和潛在影響。正如微軟的 Brad Smith 所言,「信息技術引發的問題觸及隱私和言論自由等基本人權保護的核心。這些問題加重了製造這些產品的科技公司的責任。在我們看來,它們還呼籲政府進行深思熟慮的監管,並圍繞可接受的用途製定規範」(來源)。
未來的情況還有待觀察,但了解這些計算機系統以及它們運行的軟件和算法是很重要的。我們希望這門課程能幫助你更好的理解,以便你自己決定。

🎥 點擊上圖觀看視頻:Yann LeCun 在本次講座中討論深度學習的歷史
🚀挑戰
深入了解這些歷史時刻之一,並更多地了解它們背後的人。這裏有許多引人入勝的人物,沒有一項科學發現是在文化真空中創造出來的。你發現了什麽?
課後測驗
復習與自學
以下是要觀看和收聽的節目:
