|
|
2 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 2 years ago | |
| README.id.md | 2 years ago | |
| README.it.md | 2 years ago | |
| README.ja.md | 2 years ago | |
| README.ko.md | 2 years ago | |
| README.pt-br.md | 2 years ago | |
| README.zh-cn.md | 2 years ago | |
| README.zh-tw.md | 2 years ago | |
| assignment.es.md | 3 years ago | |
| assignment.id.md | 3 years ago | |
| assignment.it.md | 4 years ago | |
| assignment.ja.md | 3 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.pt-br.md | 3 years ago | |
| assignment.zh-cn.md | 3 years ago | |
| assignment.zh-tw.md | 3 years ago | |
README.zh-tw.md
機器學習技術
構建、使用和維護機器學習模型及其使用的數據的過程與許多其他開發工作流程截然不同。 在本課中,我們將揭開該過程的神秘面紗,並概述你需要了解的主要技術。 你會:
- 在高層次上理解支持機器學習的過程。
- 探索基本概念,例如「模型」、「預測」和「訓練數據」。
課前測驗
介紹
在較高的層次上,創建機器學習(ML)過程的工藝包括許多步驟:
- 決定問題。 大多數機器學習過程都是從提出一個簡單的條件程序或基於規則的引擎無法回答的問題開始的。 這些問題通常圍繞基於數據集合的預測展開。
- 收集和準備數據。為了能夠回答你的問題,你需要數據。數據的質量(有時是數量)將決定你回答最初問題的能力。可視化數據是這個階段的一個重要方面。此階段還包括將數據拆分為訓練和測試組以構建模型。
- 選擇一種訓練方法。根據你的問題和數據的性質,你需要選擇如何訓練模型以最好地反映你的數據並對其進行準確預測。這是你的ML過程的一部分,需要特定的專業知識,並且通常需要大量的實驗。
- 訓練模型。使用你的訓練數據,你將使用各種算法來訓練模型以識別數據中的模式。該模型可能會利用可以調整的內部權重來使數據的某些部分優於其他部分,從而構建更好的模型。
- 評估模型。你使用收集到的集合中從未見過的數據(你的測試數據)來查看模型的性能。
- 參數調整。根據模型的性能,你可以使用不同的參數或變量重做該過程,這些參數或變量控製用於訓練模型的算法的行為。
- 預測。使用新輸入來測試模型的準確性。
要問什麽問題
計算機特別擅長發現數據中的隱藏模式。此實用程序對於對給定領域有疑問的研究人員非常有幫助,這些問題無法通過創建基於條件的規則引擎來輕松回答。例如,給定一項精算任務,數據科學家可能能夠圍繞吸煙者與非吸煙者的死亡率構建手工規則。
然而,當將許多其他變量納入等式時,ML模型可能會更有效地根據過去的健康史預測未來的死亡率。一個更令人愉快的例子可能是根據包括緯度、經度、氣候變化、與海洋的接近程度、急流模式等在內的數據對給定位置的4月份進行天氣預報。
✅ 這個關於天氣模型的幻燈片為在天氣分析中使用機器學習提供了一個歷史視角。
預構建任務
在開始構建模型之前,你需要完成多項任務。要測試你的問題並根據模型的預測形成假設,你需要識別和配置多個元素。
Data
為了能夠確定地回答你的問題,你需要大量正確類型的數據。 此時你需要做兩件事:
- 收集數據。記住之前關於數據分析公平性的課程,小心收集數據。請註意此數據的來源、它可能具有的任何固有偏見,並記錄其來源。
- 準備數據。數據準備過程有幾個步驟。如果數據來自不同的來源,你可能需要整理數據並對其進行標準化。你可以通過各種方法提高數據的質量和數量,例如將字符串轉換為數字(就像我們在聚類中所做的那樣)。你還可以根據原始數據生成新數據(正如我們在分類中所做的那樣)。你可以清理和編輯數據(就像我們在 Web App課程之前所做的那樣)。最後,你可能還需要對其進行隨機化和打亂,具體取決於你的訓練技術。
✅ 在收集和處理你的數據後,花點時間看看它的形狀是否能讓你解決你的預期問題。正如我們在聚類課程中發現的那樣,數據可能在你的給定任務中表現不佳!
功能和目標
功能是數據的可測量屬性。在許多數據集中,它表示為標題為"日期""大小"或"顏色"的列。您的功能變量(通常在代碼中表示為 X)表示用於訓練模型的輸入變量。
目標就是你試圖預測的事情。目標通常表示為代碼中的 y,代表您試圖詢問數據的問題的答案:在 12 月,什麽顏色的南瓜最便宜?在舊金山,哪些街區的房地產價格最好?有時目標也稱為標簽屬性。
選擇特征變量
🎓 特征選擇和特征提取 構建模型時如何知道選擇哪個變量?你可能會經歷一個特征選擇或特征提取的過程,以便為性能最好的模型選擇正確的變量。然而,它們不是一回事:「特征提取是從基於原始特征的函數中創建新特征,而特征選擇返回特征的一個子集。」(來源)
可視化數據
數據科學家工具包的一個重要方面是能夠使用多個優秀的庫(例如 Seaborn 或 MatPlotLib)將數據可視化。直觀地表示你的數據可能會讓你發現可以利用的隱藏關聯。 你的可視化還可以幫助你發現偏見或不平衡的數據(正如我們在 分類中發現的那樣)。
拆分數據集
在訓練之前,你需要將數據集拆分為兩個或多個大小不等但仍能很好地代表數據的部分。
- 訓練。這部分數據集適合你的模型進行訓練。這個集合構成了原始數據集的大部分。
- 測試。測試數據集是一組獨立的數據,通常從原始數據中收集,用於確認構建模型的性能。
- 驗證。驗證集是一個較小的獨立示例組,用於調整模型的超參數或架構,以改進模型。根據你的數據大小和你提出的問題,你可能不需要構建第三組(正如我們在時間序列預測中所述)。
建立模型
使用你的訓練數據,你的目標是構建模型或數據的統計表示,並使用各種算法對其進行訓練。訓練模型將其暴露給數據,並允許它對其發現、驗證和接受或拒絕的感知模式做出假設。
決定一種訓練方法
根據你的問題和數據的性質,你將選擇一種方法來訓練它。逐步完成 Scikit-learn的文檔 - 我們在本課程中使用 - 你可以探索多種訓練模型的方法。 根據你的經驗,你可能需要嘗試多種不同的方法來構建最佳模型。你可能會經歷一個過程,在該過程中,數據科學家通過提供未見過的數據來評估模型的性能,檢查準確性、偏差和其他降低質量的問題,並為手頭的任務選擇最合適的訓練方法。
訓練模型
有了您的培訓數據,您就可以"適應"它來創建模型。您會註意到,在許多 ML 庫中,您會發現代碼"model.fit"-此時,您將功能變量作為一系列值(通常是X)和目標變量(通常是y)發送。
評估模型
訓練過程完成後(訓練大型模型可能需要多次叠代或「時期」),你將能夠通過使用測試數據來衡量模型的性能來評估模型的質量。此數據是模型先前未分析的原始數據的子集。 你可以打印出有關模型質量的指標表。
🎓 模型擬合
在機器學習的背景下,模型擬合是指模型在嘗試分析不熟悉的數據時其底層功能的準確性。
🎓 欠擬合和過擬合是降低模型質量的常見問題,因為模型擬合得不夠好或太好。這會導致模型做出與其訓練數據過於緊密對齊或過於松散對齊的預測。 過擬合模型對訓練數據的預測太好,因為它已經很好地了解了數據的細節和噪聲。欠擬合模型並不準確,因為它既不能準確分析其訓練數據,也不能準確分析尚未「看到」的數據。
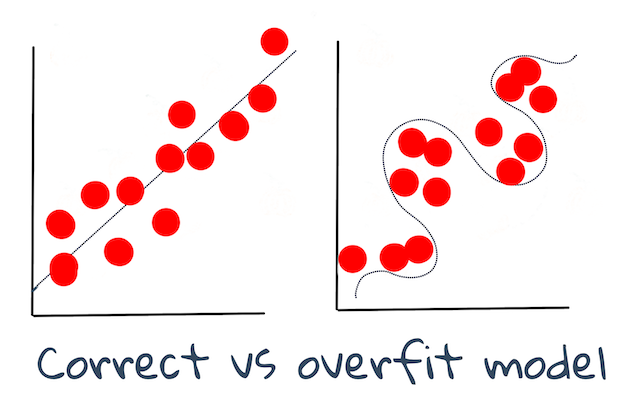
作者 Jen Looper
參數調優
初始訓練完成後,觀察模型的質量並考慮通過調整其「超參數」來改進它。在此文檔中閱讀有關該過程的更多信息。
預測
這是你可以使用全新數據來測試模型準確性的時刻。在「應用」ML設置中,你正在構建Web資源以在生產中使用模型,此過程可能涉及收集用戶輸入(例如按下按鈕)以設置變量並將其發送到模型進行推理,或者評估。
在這些課程中,你將了解如何使用這些步驟來準備、構建、測試、評估和預測—所有這些都是數據科學家的姿態,而且隨著你在成為一名「全棧」ML工程師的旅程中取得進展,你將了解更多。
🚀挑戰
畫一個流程圖,反映ML的步驟。在這個過程中,你認為自己現在在哪裏?你預測你在哪裏會遇到困難?什麽對你來說很容易?
閱讀後測驗
復習與自學
在線搜索對討論日常工作的數據科學家的采訪。 這是其中之一。