|
|
3 years ago | |
|---|---|---|
| .. | ||
| README.es.md | 3 years ago | |
| README.id.md | 3 years ago | |
| README.it.md | 3 years ago | |
| README.ja.md | 3 years ago | |
| README.ko.md | 3 years ago | |
| README.pt-br.md | 3 years ago | |
| README.zh-cn.md | 3 years ago | |
| assignment.es.md | 3 years ago | |
| assignment.id.md | 3 years ago | |
| assignment.it.md | 3 years ago | |
| assignment.ja.md | 3 years ago | |
| assignment.ko.md | 3 years ago | |
| assignment.pt-br.md | 3 years ago | |
| assignment.zh-cn.md | 3 years ago | |
README.zh-cn.md
机器学习技术
构建、使用和维护机器学习模型及其使用的数据的过程与许多其他开发工作流程截然不同。 在本课中,我们将揭开该过程的神秘面纱,并概述你需要了解的主要技术。 你会:
- 在高层次上理解支持机器学习的过程。
- 探索基本概念,例如“模型”、“预测”和“训练数据”。
课前测验
介绍
在较高的层次上,创建机器学习(ML)过程的工艺包括许多步骤:
- 决定问题。 大多数机器学习过程都是从提出一个简单的条件程序或基于规则的引擎无法回答的问题开始的。 这些问题通常围绕基于数据集合的预测展开。
- 收集和准备数据。为了能够回答你的问题,你需要数据。数据的质量(有时是数量)将决定你回答最初问题的能力。可视化数据是这个阶段的一个重要方面。此阶段还包括将数据拆分为训练和测试组以构建模型。
- 选择一种训练方法。根据你的问题和数据的性质,你需要选择如何训练模型以最好地反映你的数据并对其进行准确预测。这是你的ML过程的一部分,需要特定的专业知识,并且通常需要大量的实验。
- 训练模型。使用你的训练数据,你将使用各种算法来训练模型以识别数据中的模式。该模型可能会利用可以调整的内部权重来使数据的某些部分优于其他部分,从而构建更好的模型。
- 评估模型。你使用收集到的集合中从未见过的数据(你的测试数据)来查看模型的性能。
- 参数调整。根据模型的性能,你可以使用不同的参数或变量重做该过程,这些参数或变量控制用于训练模型的算法的行为。
- 预测。使用新输入来测试模型的准确性。
要问什么问题
计算机特别擅长发现数据中的隐藏模式。此实用程序对于对给定领域有疑问的研究人员非常有帮助,这些问题无法通过创建基于条件的规则引擎来轻松回答。例如,给定一项精算任务,数据科学家可能能够围绕吸烟者与非吸烟者的死亡率构建手工规则。
然而,当将许多其他变量纳入等式时,ML模型可能会更有效地根据过去的健康史预测未来的死亡率。一个更令人愉快的例子可能是根据包括纬度、经度、气候变化、与海洋的接近程度、急流模式等在内的数据对给定位置的4月份进行天气预报。
✅ 这个关于天气模型的幻灯片为在天气分析中使用机器学习提供了一个历史视角。
预构建任务
在开始构建模型之前,你需要完成多项任务。要测试你的问题并根据模型的预测形成假设,你需要识别和配置多个元素。
Data
为了能够确定地回答你的问题,你需要大量正确类型的数据。 此时你需要做两件事:
- 收集数据。记住之前关于数据分析公平性的课程,小心收集数据。请注意此数据的来源、它可能具有的任何固有偏见,并记录其来源。
- 准备数据。数据准备过程有几个步骤。如果数据来自不同的来源,你可能需要整理数据并对其进行标准化。你可以通过各种方法提高数据的质量和数量,例如将字符串转换为数字(就像我们在聚类中所做的那样)。你还可以根据原始数据生成新数据(正如我们在分类中所做的那样)。你可以清理和编辑数据(就像我们在 Web App课程之前所做的那样)。最后,你可能还需要对其进行随机化和打乱,具体取决于你的训练技术。
✅ 在收集和处理你的数据后,花点时间看看它的形状是否能让你解决你的预期问题。正如我们在聚类课程中发现的那样,数据可能在你的给定任务中表现不佳!
功能和目标
功能是数据的可测量属性。在许多数据集中,它表示为标题为"日期""大小"或"颜色"的列。您的功能变量(通常在代码中表示为 X)表示用于训练模型的输入变量。
目标就是你试图预测的事情。目标通常表示为代码中的 y,代表您试图询问数据的问题的答案:在 12 月,什么颜色的南瓜最便宜?在旧金山,哪些街区的房地产价格最好?有时目标也称为标签属性。
选择特征变量
🎓 特征选择和特征提取 构建模型时如何知道选择哪个变量?你可能会经历一个特征选择或特征提取的过程,以便为性能最好的模型选择正确的变量。然而,它们不是一回事:“特征提取是从基于原始特征的函数中创建新特征,而特征选择返回特征的一个子集。”(来源)
可视化数据
数据科学家工具包的一个重要方面是能够使用多个优秀的库(例如 Seaborn 或 MatPlotLib)将数据可视化。直观地表示你的数据可能会让你发现可以利用的隐藏关联。 你的可视化还可以帮助你发现偏见或不平衡的数据(正如我们在 分类中发现的那样)。
拆分数据集
在训练之前,你需要将数据集拆分为两个或多个大小不等但仍能很好地代表数据的部分。
- 训练。这部分数据集适合你的模型进行训练。这个集合构成了原始数据集的大部分。
- 测试。测试数据集是一组独立的数据,通常从原始数据中收集,用于确认构建模型的性能。
- 验证。验证集是一个较小的独立示例组,用于调整模型的超参数或架构,以改进模型。根据你的数据大小和你提出的问题,你可能不需要构建第三组(正如我们在时间序列预测中所述)。
建立模型
使用你的训练数据,你的目标是构建模型或数据的统计表示,并使用各种算法对其进行训练。训练模型将其暴露给数据,并允许它对其发现、验证和接受或拒绝的感知模式做出假设。
决定一种训练方法
根据你的问题和数据的性质,你将选择一种方法来训练它。逐步完成 Scikit-learn的文档 - 我们在本课程中使用 - 你可以探索多种训练模型的方法。 根据你的经验,你可能需要尝试多种不同的方法来构建最佳模型。你可能会经历一个过程,在该过程中,数据科学家通过提供未见过的数据来评估模型的性能,检查准确性、偏差和其他降低质量的问题,并为手头的任务选择最合适的训练方法。
训练模型
有了您的培训数据,您就可以"适应"它来创建模型。您会注意到,在许多 ML 库中,您会发现代码"model.fit"-此时,您将功能变量作为一系列值(通常是X)和目标变量(通常是y)发送。
评估模型
训练过程完成后(训练大型模型可能需要多次迭代或“时期”),你将能够通过使用测试数据来衡量模型的性能来评估模型的质量。此数据是模型先前未分析的原始数据的子集。 你可以打印出有关模型质量的指标表。
🎓 模型拟合
在机器学习的背景下,模型拟合是指模型在尝试分析不熟悉的数据时其底层功能的准确性。
🎓 欠拟合和过拟合是降低模型质量的常见问题,因为模型拟合得不够好或太好。这会导致模型做出与其训练数据过于紧密对齐或过于松散对齐的预测。 过拟合模型对训练数据的预测太好,因为它已经很好地了解了数据的细节和噪声。欠拟合模型并不准确,因为它既不能准确分析其训练数据,也不能准确分析尚未“看到”的数据。
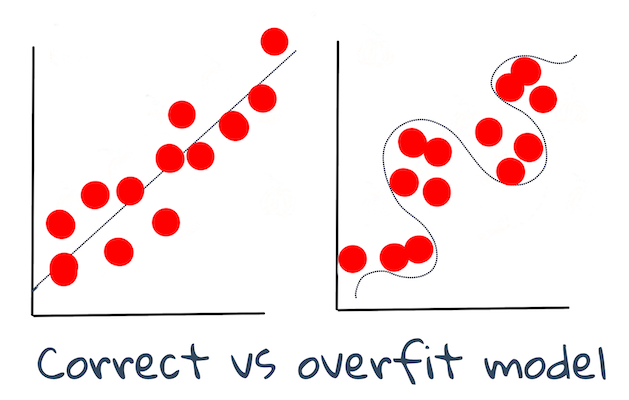
作者 Jen Looper
参数调优
初始训练完成后,观察模型的质量并考虑通过调整其“超参数”来改进它。在此文档中阅读有关该过程的更多信息。
预测
这是你可以使用全新数据来测试模型准确性的时刻。在“应用”ML设置中,你正在构建Web资源以在生产中使用模型,此过程可能涉及收集用户输入(例如按下按钮)以设置变量并将其发送到模型进行推理,或者评估。
在这些课程中,你将了解如何使用这些步骤来准备、构建、测试、评估和预测—所有这些都是数据科学家的姿态,而且随着你在成为一名“全栈”ML工程师的旅程中取得进展,你将了解更多。
🚀挑战
画一个流程图,反映ML的步骤。在这个过程中,你认为自己现在在哪里?你预测你在哪里会遇到困难?什么对你来说很容易?
阅读后测验
复习与自学
在线搜索对讨论日常工作的数据科学家的采访。 这是其中之一。