19 KiB
Bắt đầu với Python và Scikit-learn cho các mô hình hồi quy

Sketchnote bởi Tomomi Imura
Câu hỏi trước bài giảng
Bài học này có sẵn bằng R!
Giới thiệu
Trong bốn bài học này, bạn sẽ khám phá cách xây dựng các mô hình hồi quy. Chúng ta sẽ thảo luận về mục đích của chúng trong thời gian ngắn. Nhưng trước khi bắt đầu, hãy đảm bảo rằng bạn đã chuẩn bị đúng công cụ để bắt đầu quá trình!
Trong bài học này, bạn sẽ học cách:
- Cấu hình máy tính của bạn cho các tác vụ học máy cục bộ.
- Làm việc với Jupyter notebooks.
- Sử dụng Scikit-learn, bao gồm cả việc cài đặt.
- Khám phá hồi quy tuyến tính thông qua một bài tập thực hành.
Cài đặt và cấu hình

🎥 Nhấp vào hình ảnh trên để xem video ngắn hướng dẫn cấu hình máy tính của bạn cho ML.
-
Cài đặt Python. Đảm bảo rằng Python đã được cài đặt trên máy tính của bạn. Bạn sẽ sử dụng Python cho nhiều tác vụ khoa học dữ liệu và học máy. Hầu hết các hệ thống máy tính đều đã có sẵn Python. Ngoài ra, có các Python Coding Packs hữu ích để giúp một số người dùng dễ dàng cài đặt.
Tuy nhiên, một số ứng dụng của Python yêu cầu một phiên bản cụ thể của phần mềm, trong khi các ứng dụng khác yêu cầu phiên bản khác. Vì lý do này, việc làm việc trong một môi trường ảo là rất hữu ích.
-
Cài đặt Visual Studio Code. Đảm bảo rằng bạn đã cài đặt Visual Studio Code trên máy tính của mình. Làm theo hướng dẫn này để cài đặt Visual Studio Code cơ bản. Bạn sẽ sử dụng Python trong Visual Studio Code trong khóa học này, vì vậy bạn có thể muốn tìm hiểu cách cấu hình Visual Studio Code cho phát triển Python.
Làm quen với Python bằng cách làm theo bộ sưu tập Learn modules

🎥 Nhấp vào hình ảnh trên để xem video: sử dụng Python trong VS Code.
-
Cài đặt Scikit-learn, bằng cách làm theo hướng dẫn này. Vì bạn cần đảm bảo rằng mình sử dụng Python 3, nên khuyến nghị sử dụng môi trường ảo. Lưu ý, nếu bạn đang cài đặt thư viện này trên Mac M1, có các hướng dẫn đặc biệt trên trang liên kết ở trên.
-
Cài đặt Jupyter Notebook. Bạn sẽ cần cài đặt gói Jupyter.
Môi trường tác giả ML của bạn
Bạn sẽ sử dụng notebooks để phát triển mã Python và tạo các mô hình học máy. Loại tệp này là công cụ phổ biến cho các nhà khoa học dữ liệu, và chúng có thể được nhận diện bởi phần mở rộng .ipynb.
Notebooks là môi trường tương tác cho phép nhà phát triển vừa viết mã vừa thêm ghi chú và tài liệu xung quanh mã, rất hữu ích cho các dự án thử nghiệm hoặc nghiên cứu.

🎥 Nhấp vào hình ảnh trên để xem video ngắn hướng dẫn bài tập này.
Bài tập - làm việc với notebook
Trong thư mục này, bạn sẽ tìm thấy tệp notebook.ipynb.
-
Mở notebook.ipynb trong Visual Studio Code.
Một máy chủ Jupyter sẽ khởi động với Python 3+. Bạn sẽ thấy các khu vực của notebook có thể
chạy, các đoạn mã. Bạn có thể chạy một khối mã bằng cách chọn biểu tượng giống nút phát. -
Chọn biểu tượng
mdvà thêm một chút markdown, với văn bản sau # Chào mừng bạn đến với notebook của mình.Tiếp theo, thêm một số mã Python.
-
Gõ print('hello notebook') trong khối mã.
-
Chọn mũi tên để chạy mã.
Bạn sẽ thấy câu lệnh được in ra:
hello notebook

Bạn có thể xen kẽ mã của mình với các nhận xét để tự tài liệu hóa notebook.
✅ Hãy nghĩ một chút về sự khác biệt giữa môi trường làm việc của nhà phát triển web và của nhà khoa học dữ liệu.
Bắt đầu với Scikit-learn
Bây giờ Python đã được thiết lập trong môi trường cục bộ của bạn, và bạn đã quen thuộc với Jupyter notebooks, hãy làm quen với Scikit-learn (phát âm là sci như trong science). Scikit-learn cung cấp một API phong phú để giúp bạn thực hiện các tác vụ ML.
Theo trang web của họ, "Scikit-learn là một thư viện học máy mã nguồn mở hỗ trợ học có giám sát và không giám sát. Nó cũng cung cấp nhiều công cụ cho việc xây dựng mô hình, tiền xử lý dữ liệu, lựa chọn và đánh giá mô hình, cùng nhiều tiện ích khác."
Trong khóa học này, bạn sẽ sử dụng Scikit-learn và các công cụ khác để xây dựng các mô hình học máy nhằm thực hiện các tác vụ 'học máy truyền thống'. Chúng tôi đã cố tình tránh các mạng nơ-ron và học sâu, vì chúng sẽ được đề cập trong chương trình 'AI cho người mới bắt đầu' sắp tới của chúng tôi.
Scikit-learn giúp việc xây dựng mô hình và đánh giá chúng trở nên đơn giản. Nó chủ yếu tập trung vào việc sử dụng dữ liệu số và chứa một số bộ dữ liệu sẵn có để sử dụng như công cụ học tập. Nó cũng bao gồm các mô hình được xây dựng sẵn để sinh viên thử nghiệm. Hãy khám phá quy trình tải dữ liệu được đóng gói sẵn và sử dụng một bộ ước lượng để tạo mô hình ML đầu tiên với Scikit-learn bằng một số dữ liệu cơ bản.
Bài tập - notebook Scikit-learn đầu tiên của bạn
Hướng dẫn này được lấy cảm hứng từ ví dụ hồi quy tuyến tính trên trang web của Scikit-learn.

🎥 Nhấp vào hình ảnh trên để xem video ngắn hướng dẫn bài tập này.
Trong tệp notebook.ipynb liên quan đến bài học này, xóa tất cả các ô bằng cách nhấn vào biểu tượng 'thùng rác'.
Trong phần này, bạn sẽ làm việc với một bộ dữ liệu nhỏ về bệnh tiểu đường được tích hợp trong Scikit-learn để học tập. Hãy tưởng tượng rằng bạn muốn thử nghiệm một phương pháp điều trị cho bệnh nhân tiểu đường. Các mô hình học máy có thể giúp bạn xác định bệnh nhân nào sẽ phản ứng tốt hơn với phương pháp điều trị, dựa trên sự kết hợp của các biến. Ngay cả một mô hình hồi quy rất cơ bản, khi được trực quan hóa, cũng có thể cung cấp thông tin về các biến giúp bạn tổ chức các thử nghiệm lâm sàng lý thuyết.
✅ Có nhiều loại phương pháp hồi quy, và việc chọn loại nào phụ thuộc vào câu trả lời bạn đang tìm kiếm. Nếu bạn muốn dự đoán chiều cao có thể xảy ra của một người ở một độ tuổi nhất định, bạn sẽ sử dụng hồi quy tuyến tính, vì bạn đang tìm kiếm một giá trị số. Nếu bạn muốn xác định liệu một loại ẩm thực có nên được coi là thuần chay hay không, bạn đang tìm kiếm một phân loại danh mục, vì vậy bạn sẽ sử dụng hồi quy logistic. Bạn sẽ học thêm về hồi quy logistic sau này. Hãy nghĩ một chút về các câu hỏi bạn có thể đặt ra với dữ liệu, và phương pháp nào sẽ phù hợp hơn.
Hãy bắt đầu nhiệm vụ này.
Nhập thư viện
Đối với nhiệm vụ này, chúng ta sẽ nhập một số thư viện:
- matplotlib. Đây là một công cụ vẽ đồ thị hữu ích và chúng ta sẽ sử dụng nó để tạo biểu đồ đường.
- numpy. numpy là một thư viện hữu ích để xử lý dữ liệu số trong Python.
- sklearn. Đây là thư viện Scikit-learn.
Nhập một số thư viện để hỗ trợ nhiệm vụ của bạn.
-
Thêm các lệnh nhập bằng cách gõ mã sau:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionỞ trên, bạn đang nhập
matplotlib,numpyvà bạn đang nhậpdatasets,linear_modelvàmodel_selectiontừsklearn.model_selectionđược sử dụng để chia dữ liệu thành tập huấn luyện và tập kiểm tra.
Bộ dữ liệu tiểu đường
Bộ dữ liệu tiểu đường tích hợp bao gồm 442 mẫu dữ liệu về bệnh tiểu đường, với 10 biến đặc trưng, một số trong đó bao gồm:
- age: tuổi tính bằng năm
- bmi: chỉ số khối cơ thể
- bp: huyết áp trung bình
- s1 tc: T-Cells (một loại tế bào bạch cầu)
✅ Bộ dữ liệu này bao gồm khái niệm 'giới tính' như một biến đặc trưng quan trọng trong nghiên cứu về bệnh tiểu đường. Nhiều bộ dữ liệu y tế bao gồm loại phân loại nhị phân này. Hãy nghĩ một chút về cách các phân loại như vậy có thể loại trừ một số phần của dân số khỏi các phương pháp điều trị.
Bây giờ, hãy tải dữ liệu X và y.
🎓 Nhớ rằng, đây là học có giám sát, và chúng ta cần một mục tiêu 'y' được đặt tên.
Trong một ô mã mới, tải bộ dữ liệu tiểu đường bằng cách gọi load_diabetes(). Đầu vào return_X_y=True báo hiệu rằng X sẽ là ma trận dữ liệu, và y sẽ là mục tiêu hồi quy.
-
Thêm một số lệnh in để hiển thị hình dạng của ma trận dữ liệu và phần tử đầu tiên của nó:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Những gì bạn nhận được là một tuple. Bạn đang gán hai giá trị đầu tiên của tuple cho
Xvàytương ứng. Tìm hiểu thêm về tuple.Bạn có thể thấy rằng dữ liệu này có 442 mục được định hình trong các mảng gồm 10 phần tử:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Hãy nghĩ một chút về mối quan hệ giữa dữ liệu và mục tiêu hồi quy. Hồi quy tuyến tính dự đoán mối quan hệ giữa đặc trưng X và biến mục tiêu y. Bạn có thể tìm thấy mục tiêu cho bộ dữ liệu tiểu đường trong tài liệu không? Bộ dữ liệu này đang thể hiện điều gì, dựa trên mục tiêu?
-
Tiếp theo, chọn một phần của bộ dữ liệu này để vẽ bằng cách chọn cột thứ 3 của bộ dữ liệu. Bạn có thể làm điều này bằng cách sử dụng toán tử
:để chọn tất cả các hàng, và sau đó chọn cột thứ 3 bằng cách sử dụng chỉ số (2). Bạn cũng có thể định hình lại dữ liệu thành mảng 2D - như yêu cầu để vẽ - bằng cách sử dụngreshape(n_rows, n_columns). Nếu một trong các tham số là -1, kích thước tương ứng sẽ được tính tự động.X = X[:, 2] X = X.reshape((-1,1))✅ Bất cứ lúc nào, hãy in dữ liệu ra để kiểm tra hình dạng của nó.
-
Bây giờ bạn đã có dữ liệu sẵn sàng để vẽ, bạn có thể xem liệu máy có thể giúp xác định một đường phân chia hợp lý giữa các số trong bộ dữ liệu này hay không. Để làm điều này, bạn cần chia cả dữ liệu (X) và mục tiêu (y) thành tập kiểm tra và tập huấn luyện. Scikit-learn có cách đơn giản để làm điều này; bạn có thể chia dữ liệu kiểm tra của mình tại một điểm nhất định.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Bây giờ bạn đã sẵn sàng để huấn luyện mô hình của mình! Tải mô hình hồi quy tuyến tính và huấn luyện nó với các tập huấn luyện X và y của bạn bằng cách sử dụng
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()là một hàm bạn sẽ thấy trong nhiều thư viện ML như TensorFlow. -
Sau đó, tạo một dự đoán bằng cách sử dụng dữ liệu kiểm tra, sử dụng hàm
predict(). Điều này sẽ được sử dụng để vẽ đường giữa các nhóm dữ liệu.y_pred = model.predict(X_test) -
Bây giờ là lúc hiển thị dữ liệu trong một biểu đồ. Matplotlib là một công cụ rất hữu ích cho nhiệm vụ này. Tạo biểu đồ scatterplot của tất cả dữ liệu kiểm tra X và y, và sử dụng dự đoán để vẽ một đường ở vị trí thích hợp nhất, giữa các nhóm dữ liệu của mô hình.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()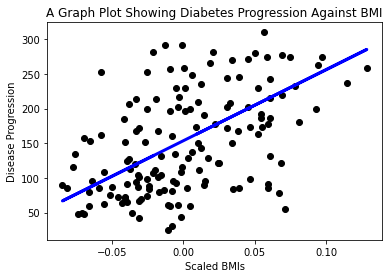 ✅ Hãy suy nghĩ một chút về điều đang diễn ra ở đây. Một đường thẳng đang chạy qua nhiều điểm dữ liệu nhỏ, nhưng nó thực sự đang làm gì? Bạn có thể thấy cách sử dụng đường thẳng này để dự đoán vị trí của một điểm dữ liệu mới, chưa được nhìn thấy, trong mối quan hệ với trục y của biểu đồ không? Hãy thử diễn đạt bằng lời về ứng dụng thực tế của mô hình này.
✅ Hãy suy nghĩ một chút về điều đang diễn ra ở đây. Một đường thẳng đang chạy qua nhiều điểm dữ liệu nhỏ, nhưng nó thực sự đang làm gì? Bạn có thể thấy cách sử dụng đường thẳng này để dự đoán vị trí của một điểm dữ liệu mới, chưa được nhìn thấy, trong mối quan hệ với trục y của biểu đồ không? Hãy thử diễn đạt bằng lời về ứng dụng thực tế của mô hình này.
Chúc mừng bạn, bạn đã xây dựng mô hình hồi quy tuyến tính đầu tiên, tạo ra một dự đoán với nó, và hiển thị nó trên biểu đồ!
🚀Thử thách
Vẽ biểu đồ cho một biến khác từ tập dữ liệu này. Gợi ý: chỉnh sửa dòng này: X = X[:,2]. Với mục tiêu của tập dữ liệu này, bạn có thể khám phá được điều gì về sự tiến triển của bệnh tiểu đường?
Câu hỏi sau bài giảng
Ôn tập & Tự học
Trong hướng dẫn này, bạn đã làm việc với hồi quy tuyến tính đơn giản, thay vì hồi quy đơn biến hoặc hồi quy đa biến. Hãy đọc thêm một chút về sự khác biệt giữa các phương pháp này, hoặc xem video này.
Tìm hiểu thêm về khái niệm hồi quy và suy nghĩ về những loại câu hỏi có thể được trả lời bằng kỹ thuật này. Hãy tham gia hướng dẫn này để nâng cao hiểu biết của bạn.
Bài tập
Tuyên bố miễn trừ trách nhiệm:
Tài liệu này đã được dịch bằng dịch vụ dịch thuật AI Co-op Translator. Mặc dù chúng tôi cố gắng đảm bảo độ chính xác, xin lưu ý rằng các bản dịch tự động có thể chứa lỗi hoặc không chính xác. Tài liệu gốc bằng ngôn ngữ bản địa nên được coi là nguồn thông tin chính thức. Đối với các thông tin quan trọng, khuyến nghị sử dụng dịch vụ dịch thuật chuyên nghiệp bởi con người. Chúng tôi không chịu trách nhiệm cho bất kỳ sự hiểu lầm hoặc diễn giải sai nào phát sinh từ việc sử dụng bản dịch này.