27 KiB
پوسٹ اسکرپٹ: مشین لرننگ میں ماڈل کی ڈیبگنگ، ذمہ دار AI ڈیش بورڈ کے اجزاء کے ذریعے
لیکچر سے پہلے کا کوئز
تعارف
مشین لرننگ ہماری روزمرہ زندگی پر اثر انداز ہوتی ہے۔ AI صحت، مالیات، تعلیم، اور روزگار جیسے اہم نظاموں میں شامل ہو رہی ہے جو ہمیں بطور فرد اور ہماری معاشرت پر اثر ڈالتی ہیں۔ مثال کے طور پر، نظام اور ماڈلز روزمرہ کے فیصلے کرنے والے کاموں میں شامل ہیں، جیسے صحت کی تشخیص یا دھوکہ دہی کا پتہ لگانا۔ نتیجتاً، AI کی ترقی اور اس کی تیز رفتار اپنائیت کے ساتھ، سماجی توقعات اور ضوابط بھی بدل رہے ہیں۔ ہم مسلسل دیکھتے ہیں کہ AI نظام کہاں توقعات پر پورا نہیں اترتے؛ وہ نئے چیلنجز کو ظاہر کرتے ہیں؛ اور حکومتیں AI حل کو ریگولیٹ کرنا شروع کر رہی ہیں۔ لہٰذا، یہ ضروری ہے کہ ان ماڈلز کا تجزیہ کیا جائے تاکہ سب کے لیے منصفانہ، قابل اعتماد، شفاف، اور جوابدہ نتائج فراہم کیے جا سکیں۔
اس نصاب میں، ہم عملی ٹولز پر نظر ڈالیں گے جو یہ جانچنے کے لیے استعمال کیے جا سکتے ہیں کہ آیا کسی ماڈل میں ذمہ دار AI کے مسائل ہیں۔ روایتی مشین لرننگ ڈیبگنگ تکنیکیں عام طور پر مقداری حسابات پر مبنی ہوتی ہیں، جیسے مجموعی درستگی یا اوسط غلطی کا نقصان۔ تصور کریں کہ جب آپ کے ماڈلز بنانے کے لیے استعمال ہونے والے ڈیٹا میں کچھ آبادیاتی خصوصیات، جیسے نسل، جنس، سیاسی نظریہ، مذہب، یا ان کی غیر متناسب نمائندگی شامل نہ ہو تو کیا ہو سکتا ہے۔ یا جب ماڈل کے نتائج کسی خاص آبادیاتی گروپ کو ترجیح دیتے ہیں۔ یہ حساس خصوصیات کے گروپس کی زیادہ یا کم نمائندگی کو متعارف کرا سکتا ہے، جس سے ماڈل میں انصاف، شمولیت، یا قابل اعتمادیت کے مسائل پیدا ہو سکتے ہیں۔ ایک اور مسئلہ یہ ہے کہ مشین لرننگ ماڈلز کو "بلیک باکسز" سمجھا جاتا ہے، جس کی وجہ سے یہ سمجھنا اور وضاحت کرنا مشکل ہو جاتا ہے کہ ماڈل کی پیش گوئی کو کیا متاثر کرتا ہے۔ یہ تمام چیلنجز ڈیٹا سائنسدانوں اور AI ڈویلپرز کو درپیش ہوتے ہیں جب ان کے پاس ماڈل کی منصفانہ یا قابل اعتمادیت کو جانچنے کے لیے مناسب ٹولز نہیں ہوتے۔
اس سبق میں، آپ اپنے ماڈلز کو ڈیبگ کرنے کے بارے میں سیکھیں گے:
- غلطی کا تجزیہ: یہ شناخت کریں کہ آپ کے ڈیٹا کی تقسیم میں ماڈل کہاں زیادہ غلطی کی شرح رکھتا ہے۔
- ماڈل کا جائزہ: مختلف ڈیٹا گروپس کے درمیان تقابلی تجزیہ کریں تاکہ اپنے ماڈل کی کارکردگی کے میٹرکس میں فرق معلوم ہو سکے۔
- ڈیٹا کا تجزیہ: یہ جانچیں کہ آپ کے ڈیٹا میں کہاں زیادہ یا کم نمائندگی ہو سکتی ہے، جو آپ کے ماڈل کو ایک ڈیٹا گروپ کے حق میں جھکا سکتی ہے۔
- خصوصیات کی اہمیت: یہ سمجھیں کہ کون سی خصوصیات آپ کے ماڈل کی پیش گوئی کو عالمی یا مقامی سطح پر متاثر کر رہی ہیں۔
پیشگی شرط
پیشگی شرط کے طور پر، براہ کرم ڈویلپرز کے لیے ذمہ دار AI ٹولز کا جائزہ لیں۔

غلطی کا تجزیہ
روایتی ماڈل کی کارکردگی کے میٹرکس، جو درستگی کی پیمائش کے لیے استعمال ہوتے ہیں، عام طور پر درست اور غلط پیش گوئیوں پر مبنی حسابات ہوتے ہیں۔ مثال کے طور پر، یہ طے کرنا کہ ایک ماڈل 89% وقت درست ہے اور اس کی غلطی کا نقصان 0.001 ہے، اچھی کارکردگی سمجھا جا سکتا ہے۔ غلطیاں آپ کے بنیادی ڈیٹا سیٹ میں یکساں طور پر تقسیم نہیں ہوتیں۔ آپ کو 89% ماڈل کی درستگی کا اسکور مل سکتا ہے لیکن یہ معلوم ہو سکتا ہے کہ آپ کے ڈیٹا کے مختلف حصے ایسے ہیں جہاں ماڈل 42% وقت ناکام ہو رہا ہے۔ ان ناکامی کے نمونوں کے نتائج، خاص ڈیٹا گروپس کے ساتھ، انصاف یا قابل اعتمادیت کے مسائل پیدا کر سکتے ہیں۔ یہ سمجھنا ضروری ہے کہ ماڈل کہاں اچھی کارکردگی دکھا رہا ہے اور کہاں نہیں۔ وہ ڈیٹا کے حصے جہاں آپ کے ماڈل میں زیادہ غلطیاں ہیں، اہم ڈیٹا گروپس ثابت ہو سکتے ہیں۔

RAI ڈیش بورڈ پر غلطی کے تجزیے کا جزو مختلف گروپس میں ماڈل کی ناکامی کو درخت کی بصری شکل میں تقسیم کرتا ہے۔ یہ آپ کے ڈیٹا سیٹ کے ساتھ زیادہ غلطی کی شرح والے خصوصیات یا علاقوں کی شناخت میں مددگار ہے۔ یہ دیکھ کر کہ ماڈل کی زیادہ تر غلطیاں کہاں سے آ رہی ہیں، آپ جڑ کے مسئلے کی تحقیقات شروع کر سکتے ہیں۔ آپ ڈیٹا کے گروپس بھی بنا سکتے ہیں تاکہ ان پر تجزیہ کیا جا سکے۔ یہ ڈیٹا گروپس ڈیبگنگ کے عمل میں مدد کرتے ہیں تاکہ یہ معلوم کیا جا سکے کہ ماڈل کی کارکردگی ایک گروپ میں اچھی ہے لیکن دوسرے میں خراب ہے۔

درخت کے نقشے پر گہرے سرخ رنگ کے شیڈز والے نوڈز مسئلے کے علاقوں کو جلدی تلاش کرنے میں مدد دیتے ہیں۔
ہیٹ میپ ایک اور بصری فعالیت ہے جسے صارفین ایک یا دو خصوصیات کے ذریعے غلطی کی شرح کی تحقیقات کے لیے استعمال کر سکتے ہیں تاکہ پورے ڈیٹا سیٹ یا گروپس میں ماڈل کی غلطیوں کے عوامل معلوم کیے جا سکیں۔

غلطی کے تجزیے کا استعمال کریں جب آپ کو ضرورت ہو:
- یہ سمجھنے کی کہ ماڈل کی ناکامیاں ڈیٹا سیٹ اور مختلف ان پٹ اور خصوصیات کے طول و عرض میں کیسے تقسیم ہوتی ہیں۔
- مجموعی کارکردگی کے میٹرکس کو توڑ کر غلط گروپس کو خودکار طور پر دریافت کریں تاکہ اپنے ہدفی اصلاحی اقدامات کی معلومات حاصل کر سکیں۔
ماڈل کا جائزہ
مشین لرننگ ماڈل کی کارکردگی کا جائزہ لینے کے لیے اس کے رویے کو جامع طور پر سمجھنا ضروری ہے۔ یہ ایک سے زیادہ میٹرکس کا جائزہ لے کر حاصل کیا جا سکتا ہے، جیسے غلطی کی شرح، درستگی، یادداشت، درستگی، یا MAE (Mean Absolute Error) تاکہ کارکردگی کے میٹرکس میں فرق معلوم ہو سکے۔ ایک کارکردگی کا میٹرک اچھا لگ سکتا ہے، لیکن دوسرے میٹرک میں غلطیاں ظاہر ہو سکتی ہیں۔ مزید برآں، پورے ڈیٹا سیٹ یا گروپس میں میٹرکس کا موازنہ کرنے سے یہ معلوم کرنے میں مدد ملتی ہے کہ ماڈل کہاں اچھی کارکردگی دکھا رہا ہے اور کہاں نہیں۔ یہ خاص طور پر حساس اور غیر حساس خصوصیات (جیسے مریض کی نسل، جنس، یا عمر) کے درمیان ماڈل کی کارکردگی کو دیکھنے میں اہم ہے تاکہ ممکنہ غیر منصفانہیت کو ظاہر کیا جا سکے۔ مثال کے طور پر، یہ معلوم کرنا کہ ماڈل ایک گروپ میں زیادہ غلطیاں کر رہا ہے جس میں حساس خصوصیات ہیں، ماڈل کی ممکنہ غیر منصفانہیت کو ظاہر کر سکتا ہے۔
RAI ڈیش بورڈ کا ماڈل جائزہ جزو نہ صرف ڈیٹا گروپ میں کارکردگی کے میٹرکس کا تجزیہ کرنے میں مدد کرتا ہے بلکہ یہ صارفین کو مختلف گروپس میں ماڈل کے رویے کا موازنہ کرنے کی صلاحیت بھی دیتا ہے۔

جزو کی خصوصیات پر مبنی تجزیے کی فعالیت صارفین کو کسی خاص خصوصیت کے اندر ڈیٹا کے ذیلی گروپس کو محدود کرنے کی اجازت دیتی ہے تاکہ تفصیلی سطح پر بے ضابطگیوں کی شناخت کی جا سکے۔ مثال کے طور پر، ڈیش بورڈ میں صارف کے منتخب کردہ خصوصیت کے لیے گروپس خودکار طور پر بنانے کی ذہانت موجود ہے (جیسے "time_in_hospital < 3" یا "time_in_hospital >= 7"). یہ صارف کو بڑے ڈیٹا گروپ سے کسی خاص خصوصیت کو الگ کرنے کی اجازت دیتا ہے تاکہ یہ دیکھا جا سکے کہ آیا یہ ماڈل کے غلط نتائج کا کلیدی اثر انداز ہے۔

ماڈل جائزہ جزو دو قسم کے فرق کے میٹرکس کی حمایت کرتا ہے:
ماڈل کی کارکردگی میں فرق: یہ میٹرکس ڈیٹا کے ذیلی گروپس میں منتخب کردہ کارکردگی کے میٹرک کی اقدار میں فرق (اختلاف) کا حساب لگاتے ہیں۔ یہاں چند مثالیں ہیں:
- درستگی کی شرح میں فرق
- غلطی کی شرح میں فرق
- درستگی میں فرق
- یادداشت میں فرق
- Mean Absolute Error (MAE) میں فرق
انتخاب کی شرح میں فرق: یہ میٹرک ذیلی گروپس کے درمیان انتخاب کی شرح (موافق پیش گوئی) میں فرق پر مشتمل ہے۔ اس کی ایک مثال قرض کی منظوری کی شرح میں فرق ہے۔ انتخاب کی شرح کا مطلب ہے ہر کلاس میں ڈیٹا پوائنٹس کا حصہ جو 1 کے طور پر درجہ بندی کیا گیا ہے (بائنری درجہ بندی میں) یا پیش گوئی کی اقدار کی تقسیم (ریگریشن میں)۔
ڈیٹا کا تجزیہ
"اگر آپ ڈیٹا کو کافی دیر تک اذیت دیں، تو یہ کسی بھی چیز کا اعتراف کر لے گا" - رونالڈ کوس
یہ بیان انتہائی لگتا ہے، لیکن یہ سچ ہے کہ ڈیٹا کو کسی بھی نتیجے کی حمایت کے لیے جوڑ توڑ کیا جا سکتا ہے۔ ایسا جوڑ توڑ کبھی کبھار غیر ارادی طور پر بھی ہو سکتا ہے۔ بطور انسان، ہم سب میں تعصب ہوتا ہے، اور یہ جاننا اکثر مشکل ہوتا ہے کہ آپ ڈیٹا میں کب تعصب متعارف کروا رہے ہیں۔ AI اور مشین لرننگ میں انصاف کی ضمانت دینا ایک پیچیدہ چیلنج ہے۔
ڈیٹا روایتی ماڈل کی کارکردگی کے میٹرکس کے لیے ایک بڑا اندھا دھند مقام ہے۔ آپ کے پاس اعلیٰ درستگی کے اسکور ہو سکتے ہیں، لیکن یہ ہمیشہ آپ کے ڈیٹا سیٹ میں موجود بنیادی ڈیٹا تعصب کی عکاسی نہیں کرتے۔ مثال کے طور پر، اگر کسی کمپنی میں ایگزیکٹو پوزیشنز پر خواتین کا تناسب 27% اور مردوں کا تناسب 73% ہے، تو اس ڈیٹا پر تربیت یافتہ AI ماڈل زیادہ تر مردوں کو سینئر سطح کی ملازمتوں کے لیے ہدف بنا سکتا ہے۔ ڈیٹا میں اس عدم توازن نے ماڈل کی پیش گوئی کو ایک جنس کے حق میں جھکا دیا۔ یہ انصاف کا مسئلہ ظاہر کرتا ہے جہاں AI ماڈل میں جنس کا تعصب موجود ہے۔
RAI ڈیش بورڈ پر ڈیٹا تجزیے کا جزو ان علاقوں کی شناخت میں مدد کرتا ہے جہاں ڈیٹا سیٹ میں زیادہ یا کم نمائندگی موجود ہے۔ یہ صارفین کو ڈیٹا کے عدم توازن یا کسی خاص ڈیٹا گروپ کی نمائندگی کی کمی سے پیدا ہونے والے غلطیوں اور انصاف کے مسائل کی جڑ کی وجہ کی تشخیص کرنے میں مدد دیتا ہے۔ یہ صارفین کو پیش گوئی اور حقیقی نتائج، غلطی کے گروپس، اور مخصوص خصوصیات کی بنیاد پر ڈیٹا سیٹ کو بصری طور پر دیکھنے کی صلاحیت دیتا ہے۔ کبھی کبھار کسی کم نمائندگی والے ڈیٹا گروپ کو دریافت کرنا یہ بھی ظاہر کر سکتا ہے کہ ماڈل اچھی طرح سے نہیں سیکھ رہا، جس کی وجہ سے زیادہ غلطیاں ہو رہی ہیں۔ ڈیٹا تعصب رکھنے والا ماڈل نہ صرف انصاف کا مسئلہ ظاہر کرتا ہے بلکہ یہ بھی ظاہر کرتا ہے کہ ماڈل شامل یا قابل اعتماد نہیں ہے۔

ڈیٹا تجزیے کا استعمال کریں جب آپ کو ضرورت ہو:
- اپنے ڈیٹا سیٹ کے اعدادوشمار کو مختلف فلٹرز منتخب کر کے مختلف طول و عرض (جسے گروپس بھی کہا جاتا ہے) میں تقسیم کریں۔
- مختلف گروپس اور خصوصیات کے گروپس میں اپنے ڈیٹا سیٹ کی تقسیم کو سمجھیں۔
- یہ طے کریں کہ انصاف، غلطی کے تجزیے، اور سببیت سے متعلق آپ کے نتائج (جو دوسرے ڈیش بورڈ اجزاء سے حاصل کیے گئے ہیں) آپ کے ڈیٹا سیٹ کی تقسیم کا نتیجہ ہیں۔
- یہ فیصلہ کریں کہ کن علاقوں میں مزید ڈیٹا جمع کرنا ہے تاکہ نمائندگی کے مسائل، لیبل شور، خصوصیت شور، لیبل تعصب، اور اسی طرح کے عوامل سے پیدا ہونے والی غلطیوں کو کم کیا جا سکے۔
ماڈل کی وضاحت
مشین لرننگ ماڈلز کو عام طور پر "بلیک باکسز" سمجھا جاتا ہے۔ یہ سمجھنا کہ کون سی کلیدی ڈیٹا خصوصیات ماڈل کی پیش گوئی کو متاثر کرتی ہیں، ایک چیلنج ہو سکتا ہے۔ یہ ضروری ہے کہ ماڈل کی کسی خاص پیش گوئی کے پیچھے شفافیت فراہم کی جائے۔ مثال کے طور پر، اگر AI نظام پیش گوئی کرتا ہے کہ ایک ذیابیطس کے مریض کو 30 دن سے کم وقت میں دوبارہ اسپتال میں داخل ہونے کا خطرہ ہے، تو اسے اپنی پیش گوئی کے پیچھے معاون ڈیٹا فراہم کرنا چاہیے۔ معاون ڈیٹا کے اشارے شفافیت لاتے ہیں تاکہ معالجین یا اسپتالوں کو اچھی طرح سے معلوماتی فیصلے کرنے میں مدد ملے۔ مزید برآں، یہ وضاحت کرنے کے قابل ہونا کہ ماڈل نے کسی فرد مریض کے لیے پیش گوئی کیوں کی، صحت کے ضوابط کے ساتھ جوابدہی کو فعال کرتا ہے۔ جب آپ مشین لرننگ ماڈلز کو ایسے طریقوں سے استعمال کر رہے ہیں جو لوگوں کی زندگیوں پر اثر ڈالتے ہیں، تو یہ سمجھنا اور وضاحت کرنا ضروری ہے کہ ماڈل کے رویے کو کیا متاثر کرتا ہے۔ ماڈل کی وضاحت اور تشریح درج ذیل منظرناموں میں سوالات کے جواب دینے میں مدد کرتی ہے:
- ماڈل کی ڈیبگنگ: میرے ماڈل نے یہ غلطی کیوں کی؟ میں اپنے ماڈل کو کیسے بہتر بنا سکتا ہوں؟
- انسان-AI تعاون: میں ماڈل کے فیصلوں کو کیسے سمجھ سکتا ہوں اور ان پر اعتماد کر سکتا ہوں؟
- ضابطہ جاتی تعمیل: کیا میرا ماڈل قانونی تقاضوں کو پورا کرتا ہے؟
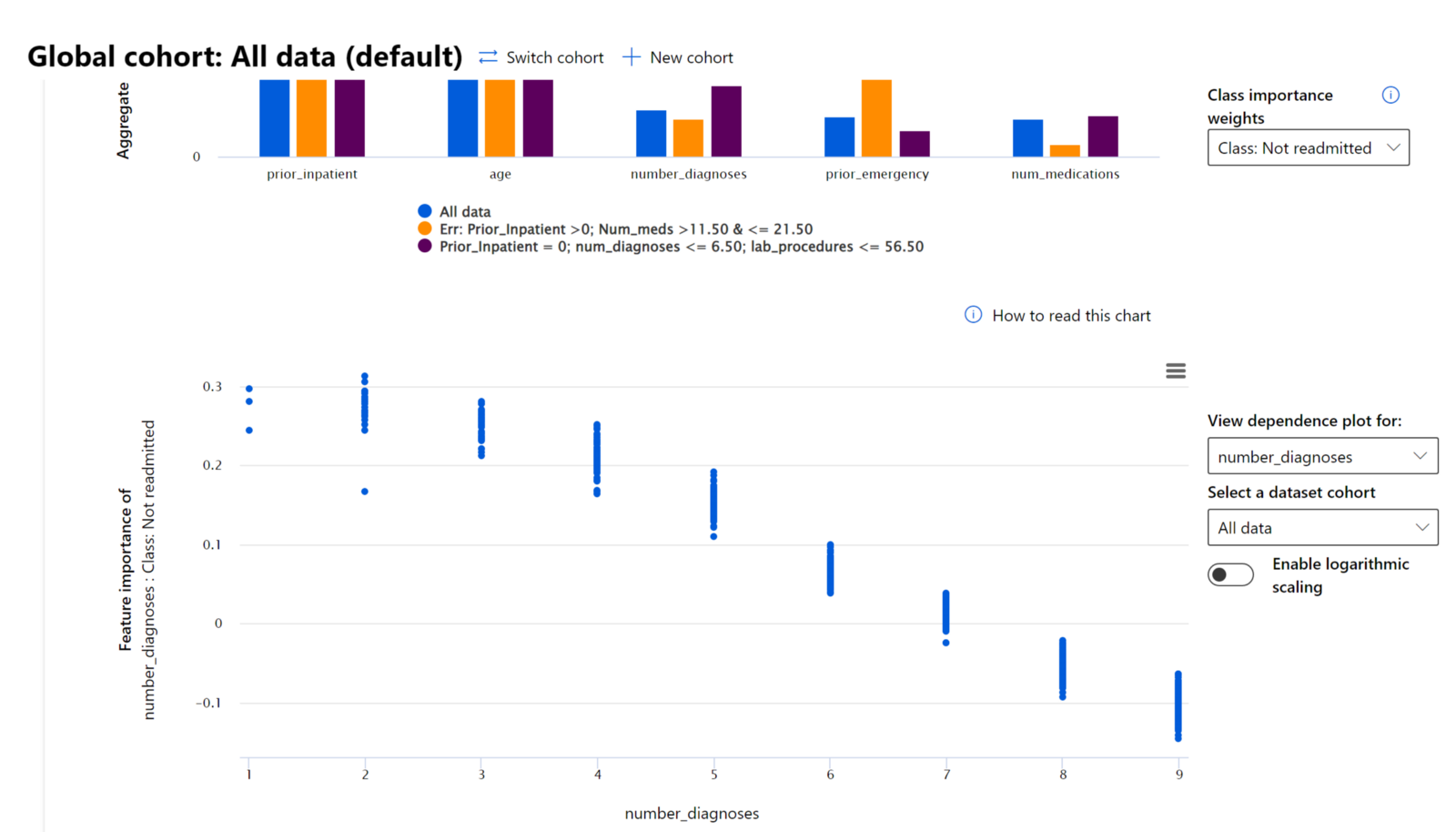
RAI ڈیش بورڈ کا خصوصیات کی اہمیت کا جزو آپ کو ڈیبگ کرنے اور یہ جامع سمجھنے میں مدد دیتا ہے کہ ماڈل پیش گوئیاں کیسے کرتا ہے۔ یہ مشین لرننگ کے پیشہ ور افراد اور فیصلہ سازوں کے لیے ایک مفید ٹول ہے تاکہ ماڈل کے رویے کو متاثر کرنے والی خصوصیات کے شواہد کو وضاحت اور ضابطہ جاتی تعمیل کے لیے دکھایا جا سکے۔ اگلا، صارفین عالمی اور مقامی وضاحتوں کو دریافت کر سکتے ہیں تاکہ یہ تصدیق کی جا سکے کہ کون سی خصوصیات ماڈل کی پیش گوئی کو متاثر کرتی ہیں۔ عالمی وضاحتیں ان خصوصیات کی فہرست دیتی ہیں جنہوں نے ماڈل کی مجموعی پیش گوئی کو متاثر کیا۔ مقامی وضاحتیں دکھاتی ہیں کہ کسی خاص کیس کے لیے ماڈل کی پیش گوئی میں کون سی خصوصیات شامل تھیں۔ مقامی وضاحتوں کا جائزہ لینے کی صلاحیت کسی خاص کیس کو ڈیبگ یا آڈٹ کرنے میں بھی مددگار ہے تاکہ یہ بہتر طور پر سمجھا جا سکے اور وضاحت کی جا سکے کہ ماڈل نے درست یا غلط پیش گوئی کیوں کی۔
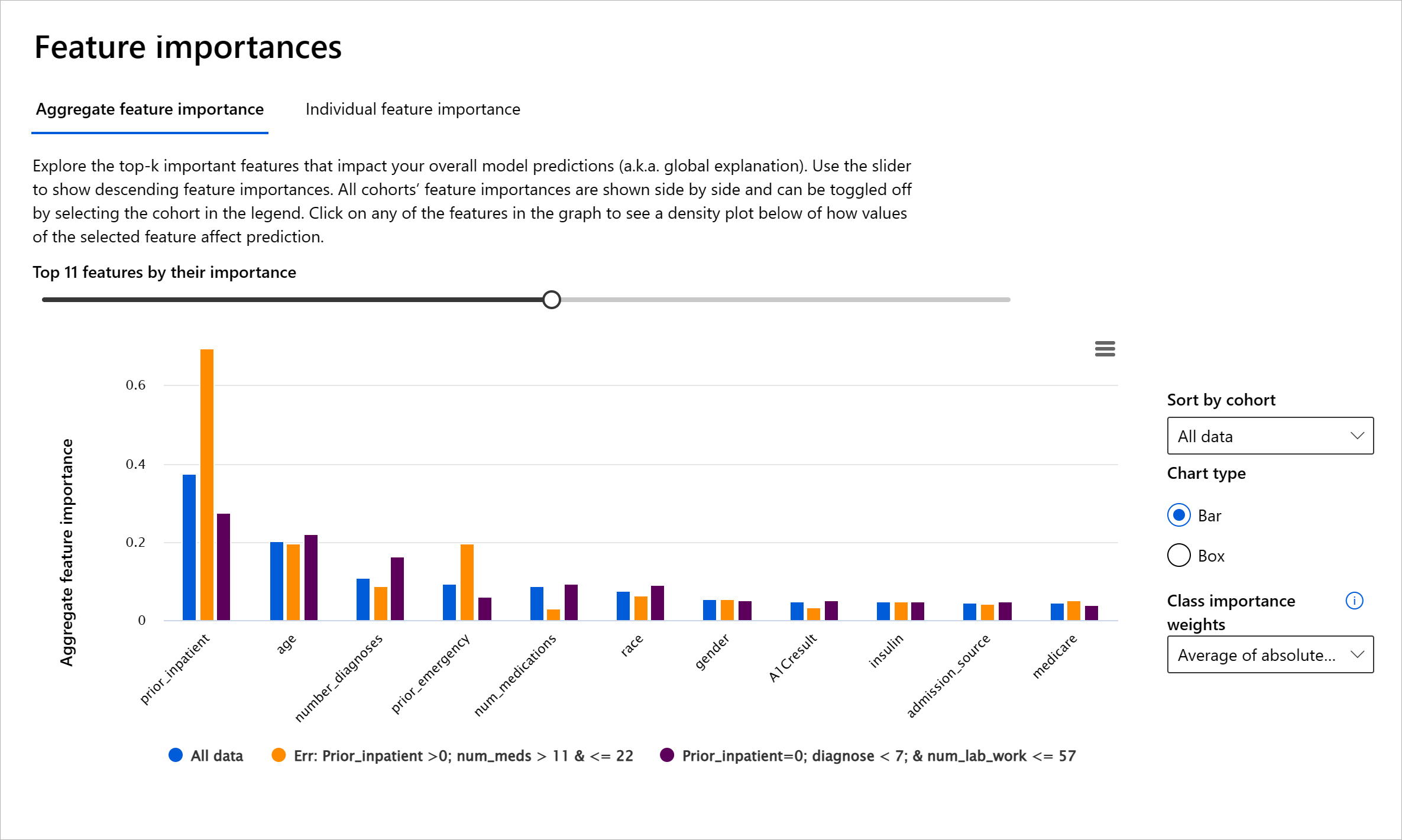
- عالمی وضاحتیں: مثال کے طور پر، کون سی خصوصیات ذیابیطس اسپتال کے دوبارہ داخلے کے ماڈل کے مجموعی رویے کو متاثر کرتی ہیں؟
- مقامی وضاحتیں: مثال کے طور پر، کیوں ایک ذیابیطس کے مریض، جو 60 سال سے زیادہ عمر کا ہے اور پہلے اسپتال میں داخل ہو چکا ہے، کو 30 دن کے اندر دوبارہ اسپتال میں داخل ہونے یا نہ ہونے کی پیش گوئی کی گئی؟
مختلف گروپس میں ماڈل کی کارکردگی کا جائزہ لینے کے عمل میں، خصوصیات کی اہمیت یہ دکھاتی ہے کہ گروپس میں کسی خصوصیت کا اثر کس سطح پر ہے۔ یہ ماڈل کی غلط پیش گوئیوں کو متاثر کرنے والی خصوصیت کے اثر کی سطح کا موازنہ کرتے وقت بے ضابطگیوں کو ظاہر کرنے میں مدد کرتا ہے۔ خصوصیات کی اہمیت کا جزو یہ دکھا سکتا ہے کہ کسی خصوصیت میں کون سی اقدار ماڈل کے نتائج کو مثبت یا منفی طور پر متاثر کرتی ہیں۔ مثال کے طور پر، اگر ماڈل نے غلط پیش گوئی کی، تو جزو آپ کو یہ صلاحیت دیتا ہے کہ آپ ڈرل ڈاؤن کریں اور یہ معلوم کریں کہ کون سی خصوصیات یا خصوصیت کی اقدار نے پیش گوئی کو متاثر کیا۔ یہ تفصیل نہ صرف ڈیبگنگ میں مدد کرتی ہے بلکہ آڈٹ کے حالات میں شفافیت اور جوابدہی فراہم کرتی ہے۔ آخر میں، جزو انصاف کے مسائل کی شناخت میں مدد کر سکتا ہے۔ مثال کے طور پر، اگر کوئی حساس خصوصیت، جیسے نسل یا جنس، ماڈل کی پیش گوئی کو متاثر کرنے میں بہت زیادہ اثر رکھتی ہے، تو یہ ماڈل میں نسل یا جنس کے تعصب کی علامت ہو سکتی ہے۔
وضاحت کا استعمال کریں جب آپ کو ضرورت ہو
- زیادہ یا کم نمائندگی۔ یہ خیال ہے کہ ایک مخصوص گروپ کو کسی خاص پیشے میں نہیں دیکھا جاتا، اور کوئی بھی خدمت یا کام جو اس کو فروغ دیتا ہے، نقصان پہنچانے میں معاون ہے۔
Azure RAI ڈیش بورڈ
Azure RAI ڈیش بورڈ کھلے ذرائع کے اوزاروں پر مبنی ہے جو معروف تعلیمی اداروں اور تنظیموں بشمول Microsoft نے تیار کیے ہیں۔ یہ ڈیٹا سائنسدانوں اور AI ڈویلپرز کے لیے ماڈل کے رویے کو بہتر طور پر سمجھنے، مسائل کو دریافت کرنے اور AI ماڈلز سے غیر مطلوبہ مسائل کو کم کرنے میں مددگار ہیں۔
-
مختلف اجزاء کو استعمال کرنے کا طریقہ سیکھنے کے لیے RAI ڈیش بورڈ دستاویزات دیکھیں۔
-
Azure Machine Learning میں زیادہ ذمہ دار AI منظرناموں کو ڈیبگ کرنے کے لیے RAI ڈیش بورڈ کے کچھ نمونہ نوٹ بکس دیکھیں۔
🚀 چیلنج
اعدادی یا ڈیٹا کے تعصبات کو شروع میں ہی روکنے کے لیے، ہمیں چاہیے:
- نظاموں پر کام کرنے والے لوگوں میں مختلف پس منظر اور نقطہ نظر ہوں
- ایسے ڈیٹا سیٹس میں سرمایہ کاری کریں جو ہماری معاشرت کی تنوع کو ظاہر کریں
- تعصب کو پہچاننے اور درست کرنے کے بہتر طریقے تیار کریں جب یہ ظاہر ہو
حقیقی زندگی کے منظرناموں کے بارے میں سوچیں جہاں ماڈل بنانے اور استعمال کرنے میں غیر منصفانہ رویہ واضح ہو۔ ہمیں اور کیا غور کرنا چاہیے؟
لیکچر کے بعد کا کوئز
جائزہ اور خود مطالعہ
اس سبق میں، آپ نے مشین لرننگ میں ذمہ دار AI کو شامل کرنے کے کچھ عملی اوزار سیکھے ہیں۔
ان موضوعات پر مزید گہرائی سے جانے کے لیے یہ ورکشاپ دیکھیں:
- ذمہ دار AI ڈیش بورڈ: عملی طور پر RAI کو نافذ کرنے کے لیے ایک مکمل حل، پیشکش از Besmira Nushi اور Mehrnoosh Sameki

🎥 اوپر دی گئی تصویر پر کلک کریں ویڈیو کے لیے: ذمہ دار AI ڈیش بورڈ: عملی طور پر RAI کو نافذ کرنے کے لیے ایک مکمل حل، پیشکش از Besmira Nushi اور Mehrnoosh Sameki
ذمہ دار AI کے بارے میں مزید جاننے اور زیادہ قابل اعتماد ماڈلز بنانے کے لیے درج ذیل مواد کا حوالہ دیں:
-
ML ماڈلز کو ڈیبگ کرنے کے لیے Microsoft کے RAI ڈیش بورڈ کے اوزار: ذمہ دار AI اوزار وسائل
-
ذمہ دار AI ٹول کٹ کو دریافت کریں: Github
-
Microsoft کا RAI وسائل مرکز: ذمہ دار AI وسائل – Microsoft AI
-
Microsoft کا FATE تحقیقاتی گروپ: FATE: انصاف، جوابدہی، شفافیت، اور AI میں اخلاقیات - Microsoft Research
اسائنمنٹ
ڈسکلیمر:
یہ دستاویز AI ترجمہ سروس Co-op Translator کا استعمال کرتے ہوئے ترجمہ کی گئی ہے۔ ہم درستگی کے لیے کوشش کرتے ہیں، لیکن براہ کرم آگاہ رہیں کہ خودکار ترجمے میں غلطیاں یا غیر درستیاں ہو سکتی ہیں۔ اصل دستاویز کو اس کی اصل زبان میں مستند ذریعہ سمجھا جانا چاہیے۔ اہم معلومات کے لیے، پیشہ ور انسانی ترجمہ کی سفارش کی جاتی ہے۔ ہم اس ترجمے کے استعمال سے پیدا ہونے والی کسی بھی غلط فہمی یا غلط تشریح کے ذمہ دار نہیں ہیں۔