30 KiB
Постскриптум: Налагодження моделей машинного навчання за допомогою компонентів панелі відповідального AI
Тест перед лекцією
Вступ
Машинне навчання впливає на наше повсякденне життя. Штучний інтелект проникає в найважливіші системи, які впливають на нас як особистостей і на суспільство загалом — від охорони здоров’я, фінансів, освіти до працевлаштування. Наприклад, системи та моделі залучені до щоденних процесів прийняття рішень, таких як діагностика в медицині або виявлення шахрайства. У результаті, розвиток штучного інтелекту та його швидке впровадження супроводжуються зростаючими суспільними очікуваннями та регулюванням. Ми постійно бачимо випадки, коли системи штучного інтелекту не відповідають очікуванням, створюють нові виклики, а уряди починають регулювати AI-рішення. Тому важливо аналізувати ці моделі, щоб забезпечити справедливі, надійні, інклюзивні, прозорі та відповідальні результати для всіх.
У цьому курсі ми розглянемо практичні інструменти, які можна використовувати для оцінки наявності проблем відповідального AI у моделі. Традиційні методи налагодження машинного навчання зазвичай базуються на кількісних розрахунках, таких як загальна точність або середня втрата помилки. Уявіть, що може статися, якщо дані, які ви використовуєте для створення моделей, не містять певних демографічних груп, таких як раса, стать, політичні погляди, релігія, або непропорційно представляють ці групи. Або якщо результати моделі інтерпретуються так, що вони надають перевагу одній демографічній групі над іншою. Це може призвести до надмірного або недостатнього представлення чутливих груп ознак, що викликає проблеми справедливості, інклюзивності або надійності моделі. Ще один фактор — моделі машинного навчання часто вважаються "чорними ящиками", що ускладнює розуміння та пояснення того, що впливає на їхні прогнози. Усі ці виклики постають перед дата-сайєнтистами та розробниками AI, коли вони не мають достатніх інструментів для налагодження та оцінки справедливості чи надійності моделі.
У цьому уроці ви дізнаєтеся, як налагоджувати свої моделі за допомогою:
- Аналізу помилок: визначення областей у розподілі даних, де модель має високі показники помилок.
- Огляд моделі: порівняльний аналіз різних когорт даних для виявлення розбіжностей у метриках продуктивності моделі.
- Аналізу даних: дослідження областей, де може бути надмірне або недостатнє представлення даних, що може вплинути на упередженість моделі.
- Важливості ознак: розуміння, які ознаки впливають на прогнози моделі на глобальному або локальному рівні.
Передумови
Як передумову, перегляньте Інструменти відповідального AI для розробників

Аналіз помилок
Традиційні метрики продуктивності моделі, які використовуються для вимірювання точності, здебільшого базуються на розрахунках правильних і неправильних прогнозів. Наприклад, визначення того, що модель є точною на 89% із втратою помилки 0.001, може вважатися хорошим результатом. Однак помилки часто не розподіляються рівномірно в базовому наборі даних. Ви можете отримати оцінку точності моделі 89%, але виявити, що в різних областях даних модель помиляється 42% часу. Наслідки таких шаблонів помилок для певних груп даних можуть призвести до проблем справедливості або надійності. Важливо розуміти області, де модель працює добре або погано. Області даних, де є велика кількість неточностей моделі, можуть виявитися важливими демографічними даними.

Компонент "Аналіз помилок" на панелі RAI показує, як помилки моделі розподіляються серед різних когорт за допомогою візуалізації дерева. Це корисно для визначення ознак або областей, де є високий рівень помилок у вашому наборі даних. Побачивши, звідки походить більшість неточностей моделі, ви можете почати досліджувати причину. Ви також можете створювати когорти даних для аналізу. Ці когорти даних допомагають у процесі налагодження, щоб визначити, чому продуктивність моделі хороша в одній когорті, але помилкова в іншій.

Візуальні індикатори на карті дерева допомагають швидше знаходити проблемні області. Наприклад, чим темніший червоний колір вузла дерева, тим вищий рівень помилок.
Теплова карта — це ще одна функція візуалізації, яку користувачі можуть використовувати для дослідження рівня помилок за допомогою однієї або двох ознак, щоб знайти фактори, що сприяють помилкам моделі в усьому наборі даних або когорті.

Використовуйте аналіз помилок, коли вам потрібно:
- Глибоко зрозуміти, як помилки моделі розподіляються в наборі даних і серед кількох вхідних і ознакових вимірів.
- Розбити агреговані метрики продуктивності, щоб автоматично виявити помилкові когорти для інформування про ваші цільові кроки з пом’якшення.
Огляд моделі
Оцінка продуктивності моделі машинного навчання вимагає отримання цілісного розуміння її поведінки. Це можна досягти, переглянувши більше ніж одну метрику, таку як рівень помилок, точність, відгук, точність або MAE (середня абсолютна помилка), щоб знайти розбіжності серед метрик продуктивності. Одна метрика продуктивності може виглядати чудово, але неточності можуть бути виявлені в іншій метриці. Крім того, порівняння метрик для розбіжностей у всьому наборі даних або когорті допомагає пролити світло на те, де модель працює добре або погано. Це особливо важливо для оцінки продуктивності моделі серед чутливих і нечутливих ознак (наприклад, раса пацієнта, стать або вік), щоб виявити потенційну несправедливість моделі. Наприклад, виявлення того, що модель є більш помилковою в когорті з чутливими ознаками, може виявити потенційну несправедливість моделі.
Компонент "Огляд моделі" на панелі RAI допомагає не лише аналізувати метрики продуктивності представлення даних у когорті, але й дає користувачам можливість порівнювати поведінку моделі серед різних когорт.

Функціональність аналізу на основі ознак компонента дозволяє користувачам звужувати підгрупи даних у межах певної ознаки, щоб виявляти аномалії на детальному рівні. Наприклад, панель має вбудований інтелект для автоматичного створення когорт для ознаки, вибраної користувачем (наприклад, "time_in_hospital < 3" або "time_in_hospital >= 7"). Це дозволяє користувачеві ізолювати певну ознаку з більшої групи даних, щоб побачити, чи є вона ключовим фактором помилкових результатів моделі.

Компонент "Огляд моделі" підтримує два класи метрик розбіжностей:
Розбіжність у продуктивності моделі: Ці набори метрик обчислюють розбіжність (різницю) у значеннях вибраної метрики продуктивності серед підгруп даних. Ось кілька прикладів:
- Розбіжність у рівні точності
- Розбіжність у рівні помилок
- Розбіжність у точності
- Розбіжність у відгуку
- Розбіжність у середній абсолютній помилці (MAE)
Розбіжність у рівні вибору: Ця метрика містить різницю в рівні вибору (сприятливий прогноз) серед підгруп. Наприклад, розбіжність у рівнях схвалення кредитів. Рівень вибору означає частку точок даних у кожному класі, класифікованих як 1 (у бінарній класифікації) або розподіл значень прогнозу (у регресії).
Аналіз даних
"Якщо достатньо довго катувати дані, вони зізнаються у всьому" — Рональд Коуз
Це твердження звучить радикально, але правда в тому, що дані можна маніпулювати для підтримки будь-якого висновку. Така маніпуляція іноді може відбуватися ненавмисно. Як люди, ми всі маємо упередження, і часто важко свідомо усвідомлювати, коли ви вводите упередження в дані. Гарантування справедливості в AI і машинному навчанні залишається складним завданням.
Дані є великою "сліпою зоною" для традиційних метрик продуктивності моделі. Ви можете мати високі показники точності, але це не завжди відображає базове упередження даних, яке може бути у вашому наборі даних. Наприклад, якщо набір даних співробітників містить 27% жінок на керівних посадах у компанії та 73% чоловіків на тому ж рівні, модель AI для реклами вакансій, навчена на цих даних, може орієнтуватися переважно на чоловічу аудиторію для вакансій високого рівня. Ця диспропорція в даних вплинула на прогноз моделі, надаючи перевагу одній статі. Це виявляє проблему справедливості, де є гендерне упередження в моделі AI.
Компонент "Аналіз даних" на панелі RAI допомагає визначити області, де є надмірне або недостатнє представлення в наборі даних. Він допомагає користувачам діагностувати причину помилок і проблем справедливості, спричинених дисбалансом даних або відсутністю представлення певної групи даних. Це дає користувачам можливість візуалізувати набори даних на основі прогнозованих і фактичних результатів, груп помилок і конкретних ознак. Іноді виявлення недостатньо представленої групи даних також може показати, що модель не навчається належним чином, що призводить до високих неточностей. Модель із упередженістю даних — це не лише проблема справедливості, але й показник того, що модель не є інклюзивною чи надійною.

Використовуйте аналіз даних, коли вам потрібно:
- Досліджувати статистику вашого набору даних, вибираючи різні фільтри для розбиття даних на різні виміри (також відомі як когорти).
- Зрозуміти розподіл вашого набору даних серед різних когорт і груп ознак.
- Визначити, чи є ваші висновки, пов’язані зі справедливістю, аналізом помилок і причинністю (отримані з інших компонентів панелі), результатом розподілу вашого набору даних.
- Вирішити, в яких областях потрібно зібрати більше даних, щоб зменшити помилки, спричинені проблемами представлення, шумом міток, шумом ознак, упередженням міток та іншими факторами.
Інтерпретація моделі
Моделі машинного навчання часто вважаються "чорними ящиками". Розуміння того, які ключові ознаки даних впливають на прогноз моделі, може бути складним завданням. Важливо забезпечити прозорість того, чому модель робить певний прогноз. Наприклад, якщо система AI прогнозує, що пацієнт із діабетом має ризик повторної госпіталізації протягом менше ніж 30 днів, вона повинна надати підтверджуючі дані, які привели до цього прогнозу. Наявність підтверджуючих даних забезпечує прозорість, допомагаючи лікарям або лікарням приймати обґрунтовані рішення. Крім того, можливість пояснити, чому модель зробила прогноз для окремого пацієнта, забезпечує відповідність медичним регуляціям. Коли ви використовуєте моделі машинного навчання в способах, які впливають на життя людей, важливо розуміти та пояснювати, що впливає на поведінку моделі. Інтерпретація та пояснення моделі допомагають відповісти на запитання в таких сценаріях:
- Налагодження моделі: Чому моя модель зробила цю помилку? Як я можу покращити свою модель?
- Співпраця людини та AI: Як я можу зрозуміти та довіряти рішенням моделі?
- Відповідність регуляціям: Чи відповідає моя модель юридичним вимогам?
Компонент "Важливість ознак" на панелі RAI допомагає налагоджувати та отримувати всебічне розуміння того, як модель робить прогнози. Це також корисний інструмент для професіоналів машинного навчання та осіб, які приймають рішення, щоб пояснити та показати докази впливу ознак на поведінку моделі для відповідності регуляціям. Далі користувачі можуть досліджувати як глобальні, так і локальні пояснення, щоб перевірити, які ознаки впливають на прогнози моделі. Глобальні пояснення показують основні ознаки, які вплинули на загальний прогноз моделі. Локальні пояснення показують, які ознаки привели до прогнозу моделі для окремого випадку. Можливість оцінювати локальні пояснення також корисна для налагодження або аудиту конкретного випадку, щоб краще зрозуміти та інтерпретувати, чому модель зробила точний або неточний прогноз.
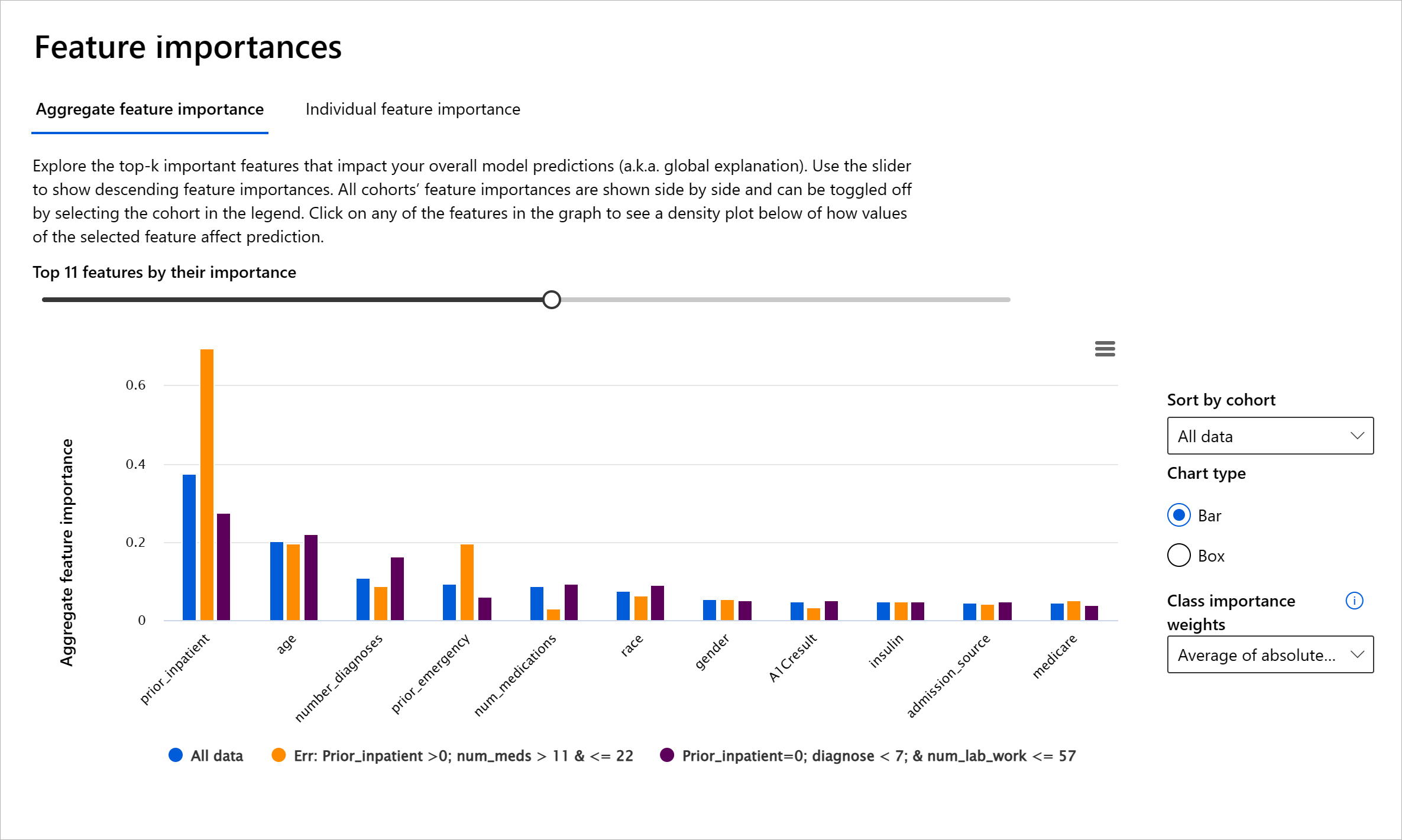
- Глобальні пояснення: Наприклад, які ознаки впливають на загальну поведінку моделі повторної госпіталізації пацієнтів із діабетом?
- Локальні пояснення: Наприклад, чому пацієнт із діабетом старше 60 років із попередніми госпіталізаціями був прогнозований як повторно госпіталізований або не госпіталізований протягом 30 днів?
У процесі налагодження продуктивності моделі серед різних когорт "Важливість ознак" показує, який рівень впливу має ознака серед когорт. Це допомагає виявляти аномалії при порівнянні рівня впливу ознаки на помилкові прогнози моделі. Компонент "Важливість ознак" може показати, які значення в ознаці позитивно або негативно вплинули на результат моделі. Наприклад, якщо модель зробила неточний прогноз, компонент дає змогу деталізувати та визначити, які ознаки або значення ознак вплинули на прогноз. Такий рівень деталізації допомагає не лише в налагодженні, але й забезпечує прозорість і
- Надмірне або недостатнє представлення. Ідея полягає в тому, що певна група не представлена в певній професії, і будь-яка послуга чи функція, яка продовжує це підтримувати, сприяє завданню шкоди.
Панель інструментів Azure RAI
Панель інструментів Azure RAI побудована на основі інструментів з відкритим кодом, розроблених провідними академічними установами та організаціями, включаючи Microsoft. Вона є важливим інструментом для науковців з даних та розробників штучного інтелекту, щоб краще розуміти поведінку моделей, виявляти та усувати небажані проблеми в моделях штучного інтелекту.
-
Дізнайтеся, як використовувати різні компоненти, переглянувши документацію панелі інструментів RAI.
-
Ознайомтеся з зразковими блокнотами панелі інструментів RAI для налагодження більш відповідальних сценаріїв штучного інтелекту в Azure Machine Learning.
🚀 Виклик
Щоб запобігти введенню статистичних або даних упереджень, ми повинні:
- забезпечити різноманітність досвіду та перспектив серед людей, які працюють над системами
- інвестувати в набори даних, які відображають різноманітність нашого суспільства
- розробляти кращі методи для виявлення та виправлення упереджень, коли вони виникають
Подумайте про реальні сценарії, де несправедливість очевидна у створенні та використанні моделей. Що ще ми повинні врахувати?
Тест після лекції
Огляд і самостійне навчання
У цьому уроці ви дізналися про деякі практичні інструменти для впровадження відповідального штучного інтелекту в машинне навчання.
Перегляньте цей семінар, щоб глибше зануритися в тему:
- Панель інструментів відповідального штучного інтелекту: універсальне рішення для впровадження RAI на практиці від Бесміри Нуші та Мехрнуш Самекі

🎥 Натисніть на зображення вище, щоб переглянути відео: Панель інструментів відповідального штучного інтелекту: універсальне рішення для впровадження RAI на практиці від Бесміри Нуші та Мехрнуш Самекі
Ознайомтеся з наступними матеріалами, щоб дізнатися більше про відповідальний штучний інтелект і як створювати більш надійні моделі:
-
Інструменти панелі інструментів Microsoft RAI для налагодження моделей машинного навчання: Ресурси інструментів відповідального штучного інтелекту
-
Досліджуйте набір інструментів відповідального штучного інтелекту: Github
-
Центр ресурсів Microsoft RAI: Ресурси відповідального штучного інтелекту – Microsoft AI
-
Дослідницька група Microsoft FATE: FATE: Справедливість, підзвітність, прозорість та етика в штучному інтелекті - Microsoft Research
Завдання
Ознайомтеся з панеллю інструментів RAI
Відмова від відповідальності:
Цей документ було перекладено за допомогою сервісу автоматичного перекладу Co-op Translator. Хоча ми прагнемо до точності, зверніть увагу, що автоматичні переклади можуть містити помилки або неточності. Оригінальний документ мовою оригіналу слід вважати авторитетним джерелом. Для критично важливої інформації рекомендується професійний людський переклад. Ми не несемо відповідальності за будь-які непорозуміння або неправильні тлумачення, що виникли внаслідок використання цього перекладу.