21 KiB
Postscript: Makine Öğreniminde Model Hata Ayıklama ve Sorumlu AI Panosu Bileşenleri Kullanımı
Ders Öncesi Test
Giriş
Makine öğrenimi günlük hayatımızı etkiliyor. Yapay zeka, sağlık, finans, eğitim ve istihdam gibi bireyler ve toplum üzerinde etkili olan en önemli sistemlere giderek daha fazla entegre oluyor. Örneğin, sağlık teşhisleri veya dolandırıcılık tespiti gibi günlük karar verme görevlerinde sistemler ve modeller kullanılıyor. Bu nedenle, yapay zekadaki ilerlemeler ve hızla artan benimseme oranı, gelişen toplumsal beklentiler ve buna yanıt olarak artan düzenlemelerle karşılaşıyor. Yapay zeka sistemlerinin beklentileri karşılamadığı, yeni zorluklar ortaya çıkardığı ve hükümetlerin yapay zeka çözümlerini düzenlemeye başladığı alanları sürekli olarak görüyoruz. Bu nedenle, bu modellerin herkes için adil, güvenilir, kapsayıcı, şeffaf ve hesap verebilir sonuçlar sağlamak amacıyla analiz edilmesi önemlidir.
Bu müfredatta, bir modelin sorumlu yapay zeka sorunlarına sahip olup olmadığını değerlendirmek için kullanılabilecek pratik araçlara bakacağız. Geleneksel makine öğrenimi hata ayıklama teknikleri genellikle toplu doğruluk veya ortalama hata kaybı gibi nicel hesaplamalara dayanır. Bu modelleri oluşturmak için kullandığınız verilerin belirli demografik özelliklerden (örneğin, ırk, cinsiyet, siyasi görüş, din) yoksun olduğunu veya bu demografik özellikleri orantısız bir şekilde temsil ettiğini hayal edin. Peki ya modelin çıktısı bazı demografik grupları kayıracak şekilde yorumlanırsa? Bu, hassas özellik gruplarının aşırı veya yetersiz temsil edilmesine yol açarak modelde adalet, kapsayıcılık veya güvenilirlik sorunlarına neden olabilir. Ayrıca, makine öğrenimi modelleri genellikle "kara kutu" olarak kabul edilir, bu da bir modelin tahminlerini neyin yönlendirdiğini anlamayı ve açıklamayı zorlaştırır. Veri bilimciler ve yapay zeka geliştiricileri, bir modelin adaletini veya güvenilirliğini değerlendirmek ve hata ayıklamak için yeterli araçlara sahip olmadıklarında bu tür zorluklarla karşılaşırlar.
Bu derste, modellerinizi aşağıdaki yöntemlerle hata ayıklamayı öğreneceksiniz:
- Hata Analizi: Modelin veri dağılımında yüksek hata oranlarına sahip olduğu yerleri belirleyin.
- Model Genel Bakışı: Modelinizin performans metriklerindeki farklılıkları keşfetmek için farklı veri grupları arasında karşılaştırmalı analiz yapın.
- Veri Analizi: Modelinizin bir veri demografisini diğerine kayırmasına neden olabilecek veri aşırı veya yetersiz temsilini araştırın.
- Özellik Önem Derecesi: Modelinizin tahminlerini küresel veya yerel düzeyde yönlendiren özellikleri anlayın.
Ön Koşul
Ön koşul olarak, Geliştiriciler için Sorumlu AI Araçları incelemesini tamamlayın.

Hata Analizi
Doğruluğu ölçmek için kullanılan geleneksel model performans metrikleri genellikle doğru ve yanlış tahminlere dayalı hesaplamalardır. Örneğin, bir modelin %89 oranında doğru olduğunu ve 0.001 hata kaybına sahip olduğunu belirlemek iyi bir performans olarak kabul edilebilir. Ancak hatalar, temel veri kümenizde eşit olarak dağılmayabilir. %89 model doğruluk puanı alabilirsiniz, ancak modelin veri gruplarının belirli bölgelerinde %42 oranında başarısız olduğunu keşfedebilirsiniz. Belirli veri gruplarındaki bu hata kalıplarının sonuçları, adalet veya güvenilirlik sorunlarına yol açabilir. Modelin iyi veya kötü performans gösterdiği alanları anlamak önemlidir. Modelinizdeki yüksek hata oranlarına sahip veri bölgeleri, önemli bir veri demografisi olabilir.

RAI panosundaki Hata Analizi bileşeni, model hatalarının çeşitli gruplar arasında nasıl dağıldığını bir ağaç görselleştirmesiyle gösterir. Bu, veri kümenizde yüksek hata oranına sahip özellikleri veya alanları belirlemede faydalıdır. Modelin hatalarının çoğunun nereden geldiğini görerek, sorunun kök nedenini araştırmaya başlayabilirsiniz. Ayrıca veri grupları oluşturarak analiz yapabilirsiniz. Bu veri grupları, modelin bir grupta neden iyi performans gösterdiğini, ancak diğerinde hatalı olduğunu belirlemek için hata ayıklama sürecinde yardımcı olur.

Ağaç haritasındaki görsel göstergeler, sorunlu alanları daha hızlı bulmaya yardımcı olur. Örneğin, bir ağaç düğümünün daha koyu kırmızı tonuna sahip olması, daha yüksek hata oranını gösterir.
Isı haritası, kullanıcıların bir veya iki özelliği kullanarak hata oranını araştırması için başka bir görselleştirme işlevselliğidir. Bu, model hatalarına katkıda bulunan özellikleri tüm veri kümesi veya gruplar arasında bulmaya yardımcı olur.

Hata analizini şu durumlarda kullanın:
- Model hatalarının bir veri kümesi ve çeşitli giriş ve özellik boyutları arasında nasıl dağıldığını derinlemesine anlamak.
- Toplu performans metriklerini bölerek, hedeflenen iyileştirme adımlarınızı bilgilendirmek için hatalı grupları otomatik olarak keşfetmek.
Model Genel Bakışı
Bir makine öğrenimi modelinin performansını değerlendirmek, davranışını bütünsel bir şekilde anlamayı gerektirir. Bu, hata oranı, doğruluk, geri çağırma, hassasiyet veya MAE (Ortalama Mutlak Hata) gibi birden fazla metriği gözden geçirerek performans metrikleri arasındaki farklılıkları bulmakla sağlanabilir. Bir performans metriği harika görünebilir, ancak başka bir metrikteki yanlışlıklar ortaya çıkabilir. Ayrıca, metrikleri tüm veri kümesi veya gruplar arasında karşılaştırmak, modelin nerede iyi veya kötü performans gösterdiğini anlamaya yardımcı olur. Bu, özellikle hassas ve hassas olmayan özellikler (örneğin, hastanın ırkı, cinsiyeti veya yaşı) arasında modelin performansını görerek modelin potansiyel adaletsizliğini ortaya çıkarmak için önemlidir. Örneğin, modelin hassas özelliklere sahip bir grupta daha hatalı olduğunu keşfetmek, modelin potansiyel adaletsizliğini ortaya çıkarabilir.
RAI panosundaki Model Genel Bakışı bileşeni, yalnızca bir veri grubundaki performans metriklerini analiz etmekle kalmaz, aynı zamanda kullanıcıların modelin davranışını farklı gruplar arasında karşılaştırma yeteneği sağlar.

Bileşenin özellik tabanlı analiz işlevselliği, kullanıcıların belirli bir özellik içinde veri alt gruplarını daraltarak anormallikleri daha ayrıntılı bir düzeyde belirlemesine olanak tanır. Örneğin, pano, kullanıcı tarafından seçilen bir özellik için (örneğin, "hastanede geçirilen süre < 3" veya "hastanede geçirilen süre >= 7") otomatik olarak gruplar oluşturmak için yerleşik zekaya sahiptir. Bu, kullanıcıların daha büyük bir veri grubundan belirli bir özelliği izole ederek modelin hatalı sonuçlarının anahtar bir etkileyicisi olup olmadığını görmesini sağlar.

Model Genel Bakışı bileşeni iki tür farklılık metriğini destekler:
Model performansındaki farklılık: Bu metrikler, seçilen performans metriğinin değerlerindeki farklılıkları veri alt grupları arasında hesaplar. İşte birkaç örnek:
- Doğruluk oranındaki farklılık
- Hata oranındaki farklılık
- Hassasiyetteki farklılık
- Geri çağırmadaki farklılık
- Ortalama mutlak hatadaki (MAE) farklılık
Seçim oranındaki farklılık: Bu metrik, veri alt grupları arasındaki seçim oranındaki (olumlu tahmin) farkı içerir. Buna bir örnek, kredi onay oranlarındaki farklılıktır. Seçim oranı, her sınıftaki veri noktalarının 1 olarak sınıflandırılma oranını (ikili sınıflandırmada) veya tahmin değerlerinin dağılımını (regresyonda) ifade eder.
Veri Analizi
"Veriyi yeterince zorlayın, her şeyi itiraf eder" - Ronald Coase
Bu ifade aşırı görünebilir, ancak verilerin herhangi bir sonucu desteklemek için manipüle edilebileceği doğrudur. Bu tür manipülasyon bazen istemeden gerçekleşebilir. İnsanlar olarak hepimiz önyargıya sahibiz ve verilerde önyargı oluşturduğumuzda bunu bilinçli olarak fark etmek genellikle zordur. Yapay zekada ve makine öğreniminde adaleti sağlamak karmaşık bir zorluk olmaya devam ediyor.
Veri, geleneksel model performans metrikleri için büyük bir kör noktadır. Yüksek doğruluk puanlarına sahip olabilirsiniz, ancak bu her zaman veri kümenizdeki temel veri önyargısını yansıtmaz. Örneğin, bir şirketteki çalışanların %27'sinin kadın, %73'ünün erkek olduğu bir veri kümesi, bir iş ilanı yapay zeka modeli bu verilerle eğitildiğinde, üst düzey iş pozisyonları için çoğunlukla erkek bir kitleyi hedefleyebilir. Bu tür bir veri dengesizliği, modelin tahminini bir cinsiyeti kayıracak şekilde çarpıttı. Bu, yapay zeka modelinde bir adalet sorunu olduğunu ve cinsiyet önyargısı bulunduğunu gösterir.
RAI panosundaki Veri Analizi bileşeni, veri kümesinde aşırı ve yetersiz temsil edilen alanları belirlemeye yardımcı olur. Kullanıcılara veri dengesizliklerinden veya belirli bir veri grubunun temsil eksikliğinden kaynaklanan hataların ve adalet sorunlarının kök nedenini teşhis etme olanağı sağlar. Bu, kullanıcıların veri kümelerini tahmin edilen ve gerçek sonuçlara, hata gruplarına ve belirli özelliklere göre görselleştirmesine olanak tanır. Bazen yetersiz temsil edilen bir veri grubunu keşfetmek, modelin iyi öğrenmediğini ve dolayısıyla yüksek yanlışlıklar olduğunu da ortaya çıkarabilir. Veri önyargısına sahip bir model, yalnızca bir adalet sorunu değil, aynı zamanda modelin kapsayıcı veya güvenilir olmadığını gösterir.

Veri analizini şu durumlarda kullanın:
- Veri kümesi istatistiklerini farklı boyutlara (gruplara) ayırmak için farklı filtreler seçerek keşfetmek.
- Veri kümenizin farklı gruplar ve özellik grupları arasındaki dağılımını anlamak.
- Adalet, hata analizi ve nedensellik ile ilgili bulgularınızın (diğer pano bileşenlerinden türetilen) veri kümenizin dağılımından kaynaklanıp kaynaklanmadığını belirlemek.
- Temsil sorunlarından, etiket gürültüsünden, özellik gürültüsünden, etiket önyargısından ve benzeri faktörlerden kaynaklanan hataları azaltmak için daha fazla veri toplamanız gereken alanları belirlemek.
Model Yorumlanabilirliği
Makine öğrenimi modelleri genellikle "kara kutu" olarak kabul edilir. Bir modelin tahminini yönlendiren temel veri özelliklerini anlamak zor olabilir. Bir modelin belirli bir tahmini neden yaptığını açıklamak önemlidir. Örneğin, bir yapay zeka sistemi, bir diyabet hastasının 30 gün içinde hastaneye yeniden yatma riski taşıdığını tahmin ederse, tahminine yol açan destekleyici verileri sağlamalıdır. Destekleyici veri göstergelerine sahip olmak, klinisyenlerin veya hastanelerin iyi bilgilendirilmiş kararlar almasına yardımcı olmak için şeffaflık sağlar. Ayrıca, bir modelin bireysel bir hasta için neden bir tahminde bulunduğunu açıklayabilmek, sağlık düzenlemeleriyle hesap verebilirlik sağlar. İnsanların hayatlarını etkileyen şekillerde makine öğrenimi modelleri kullanıyorsanız, bir modelin davranışını neyin etkilediğini anlamak ve açıklamak çok önemlidir. Model açıklanabilirliği ve yorumlanabilirliği, aşağıdaki senaryolarda soruları yanıtlamaya yardımcı olur:
- Model hata ayıklama: Modelim neden bu hatayı yaptı? Modelimi nasıl geliştirebilirim?
- İnsan-Yapay Zeka iş birliği: Modelin kararlarını nasıl anlayabilir ve güvenebilirim?
- Düzenleyici uyumluluk: Modelim yasal gereklilikleri karşılıyor mu?
RAI panosundaki Özellik Önem Derecesi bileşeni, bir modelin tahminlerini nasıl yaptığını anlamak ve hata ayıklamak için kapsamlı bir araçtır. Ayrıca, makine öğrenimi profesyonelleri ve karar vericiler için modelin davranışını etkileyen özelliklerin kanıtlarını açıklamak ve düzenleyici uyumluluk için göstermek adına faydalı bir araçtır. Kullanıcılar, modelin tahminlerini yönlendiren özellikleri doğrulamak için hem küresel hem de yerel açıklamaları keşfedebilir. Küresel açıklamalar, bir modelin genel tahminini etkileyen en önemli özellikleri listeler. Yerel açıklamalar, bir modelin bireysel bir vaka için tahminine yol açan özellikleri gösterir. Yerel açıklamaları değerlendirme yeteneği, bir modelin doğru veya yanlış bir tahminde bulunmasının nedenini daha iyi anlamak ve yorumlamak için belirli bir vakayı hata ayıklama veya denetleme açısından da faydalıdır.
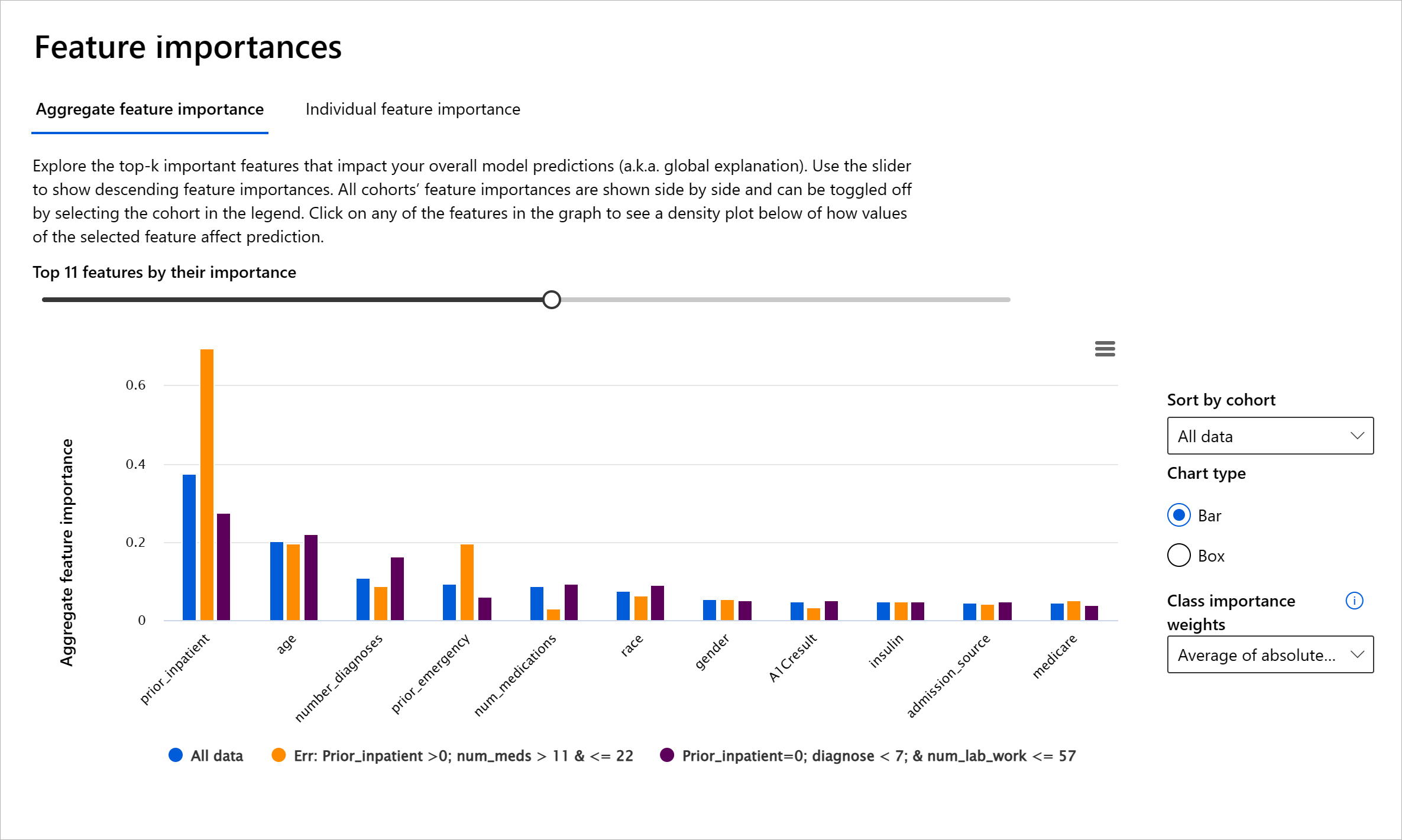
- Küresel açıklamalar: Örneğin, diyabet hastaneye yeniden yatış modelinin genel davranışını hangi özellikler etkiliyor?
- Yerel açıklamalar: Örneğin, neden 60 yaşından büyük, önceki hastane yatışları olan bir diyabet hastası 30 gün içinde hastaneye yeniden yatacak veya yatmayacak şekilde tahmin edildi?
Modelin performansını farklı gruplar arasında inceleme sürecinde, Özellik Önem Derecesi bir özelliğin gruplar arasında modelin hatalı tahminlerini yönlendirmedeki etkisini gösterir. Özelliklerin modelin sonuçlarını olumlu veya olumsuz etkilediği değerleri gösterebilir. Örneğin, bir model yanlış bir tahminde bulunduysa, bileşen, tahmini yönlendiren özellikleri veya özellik değerlerini belirlemenize olanak tanır. Bu ayrıntı düzeyi, yalnızca hata ayıklamada değil, aynı zamanda denetim durumlarında şeffaflık ve hesap verebilirlik sağlamada da yardımcı olur. Son olarak, bileşen adalet sorunlarını belirlemenize yardımcı olabilir. Örneğin, etnik köken veya cinsiyet gibi hassas bir özellik modelin tahminini yönlendirmede çok etkiliyse, bu modelde ırk veya cinsiyet önyargısının bir işareti olabilir.
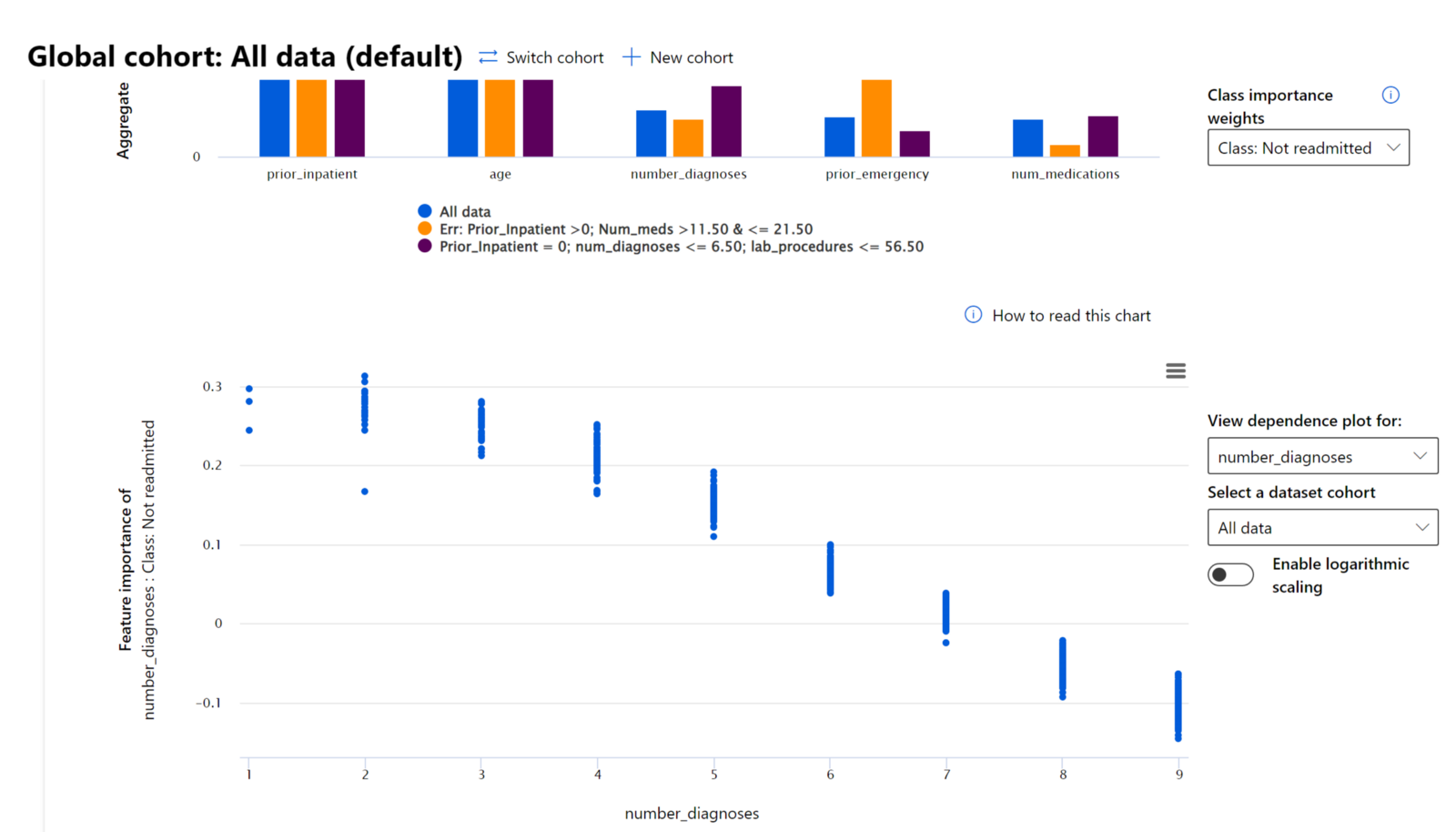
Yorumlanabilirliği şu durumlarda kullanın:
- Modelinizin tahminlerinin ne kadar güvenilir olduğunu belirlemek için tahminler için en önemli özelliklerin neler olduğunu anlamak.
- Modelinizi önce anlayarak ve modelin sağlıklı özellikler mi yoksa yalnızca yanlış korelasyonlar mı kullandığını belirleyerek hata ayıklama sürecine yaklaşmak.
- Modelin tahminlerini hassas özelliklere veya onlarla yüksek korelasyona sahip özelliklere dayandırıp dayandırmadığını anlayarak adaletsizlik kaynaklarını ortaya çıkarmak.
- Yerel açıklamalar oluşturarak modelinizin kararlarına kullanıcı güveni oluşturmak.
- İnsanlar üzerindeki model kararlarının etkisini izlemek ve modelleri doğrulamak için bir yapay zeka sisteminin düzenleyici denetimini tamamlamak.
Sonuç
RAI panosundaki tüm bileşenler, topluma daha az zarar veren ve daha güvenilir makine öğrenimi modelleri oluşturmanıza yardımcı olacak pratik araçlardır. İnsan haklarına yönelik tehditlerin önlenmesini, belirli grupların yaşam fırsatlarından dışlanmasını veya ayrımcılığa uğramasını ve fiziksel veya psikolojik zarar riskini azaltır. Ayrıca, modelinizin kararlarına güven oluşturmak için yerel açıklamalar oluşturarak sonuçlarını göstermenize yardımcı olur. Potansiyel zararlar şu şekilde sınıflandırılabilir:
- Tahsis: Örneğin, bir cinsiyet veya etnik kökenin diğerine kayırılması.
- Hizmet kalitesi: Verileri belirli bir senaryo için eğitmek, ancak gerçekliğin çok daha karmaşık olması, kötü performans gösteren bir hizmete yol açar.
- Stereotipleme: Belirli bir grubu önceden atanmış özelliklerle ilişkilendirme.
- Küçümseme: Bir şey veya birini haksız yere eleştirme ve etiketleme.
- Aşırı veya yetersiz temsil. Belirli bir grubun belirli bir meslek alanında görülmemesi fikri, ve bu durumu teşvik eden herhangi bir hizmet veya işlev zarara katkıda bulunuyor demektir.
Azure RAI panosu
Azure RAI panosu, Microsoft dahil olmak üzere önde gelen akademik kurumlar ve organizasyonlar tarafından geliştirilen açık kaynaklı araçlar üzerine inşa edilmiştir. Bu araçlar, veri bilimciler ve yapay zeka geliştiricilerinin model davranışını daha iyi anlamalarına, yapay zeka modellerindeki istenmeyen sorunları keşfetmelerine ve hafifletmelerine yardımcı olur.
-
RAI panosunun farklı bileşenlerini nasıl kullanacağınızı öğrenmek için dokümanlara göz atın.
-
Azure Machine Learning'de daha sorumlu yapay zeka senaryolarını hata ayıklamak için bazı RAI panosu örnek not defterlerini inceleyin.
🚀 Zorluk
İstatistiksel veya veri önyargılarının en baştan ortaya çıkmasını önlemek için şunları yapmalıyız:
- sistemler üzerinde çalışan kişiler arasında farklı geçmişlere ve bakış açılarına sahip olmak
- toplumumuzun çeşitliliğini yansıtan veri setlerine yatırım yapmak
- önyargıyı tespit etmek ve düzeltmek için daha iyi yöntemler geliştirmek
Model oluşturma ve kullanımı sırasında adaletsizliğin açıkça görüldüğü gerçek yaşam senaryolarını düşünün. Başka neleri dikkate almalıyız?
Ders sonrası test
Gözden Geçirme ve Kendi Kendine Çalışma
Bu derste, makine öğreniminde sorumlu yapay zekayı dahil etmenin bazı pratik araçlarını öğrendiniz.
Konulara daha derinlemesine dalmak için bu atölye çalışmasını izleyin:
- Sorumlu Yapay Zeka Panosu: Besmira Nushi ve Mehrnoosh Sameki tarafından pratikte RAI'yi operasyonelleştirmek için tek durak noktası

🎥 Yukarıdaki görüntüye tıklayarak video izleyin: Besmira Nushi ve Mehrnoosh Sameki tarafından Sorumlu Yapay Zeka Panosu: Pratikte RAI'yi operasyonelleştirmek için tek durak noktası
Sorumlu yapay zeka hakkında daha fazla bilgi edinmek ve daha güvenilir modeller oluşturmak için aşağıdaki materyallere başvurun:
-
ML modellerini hata ayıklamak için Microsoft’un RAI panosu araçları: Sorumlu Yapay Zeka araçları kaynakları
-
Sorumlu Yapay Zeka araç setini keşfedin: Github
-
Microsoft’un RAI kaynak merkezi: Sorumlu Yapay Zeka Kaynakları – Microsoft AI
-
Microsoft’un FATE araştırma grubu: FATE: Yapay Zekada Adalet, Hesap Verebilirlik, Şeffaflık ve Etik - Microsoft Research
Ödev
Feragatname:
Bu belge, AI çeviri hizmeti Co-op Translator kullanılarak çevrilmiştir. Doğruluk için çaba göstersek de, otomatik çevirilerin hata veya yanlışlık içerebileceğini lütfen unutmayın. Belgenin orijinal dili, yetkili kaynak olarak kabul edilmelidir. Kritik bilgiler için profesyonel insan çevirisi önerilir. Bu çevirinin kullanımından kaynaklanan yanlış anlamalar veya yanlış yorumlamalardan sorumlu değiliz.