18 KiB
Paggawa ng Solusyon sa Machine Learning gamit ang Responsible AI
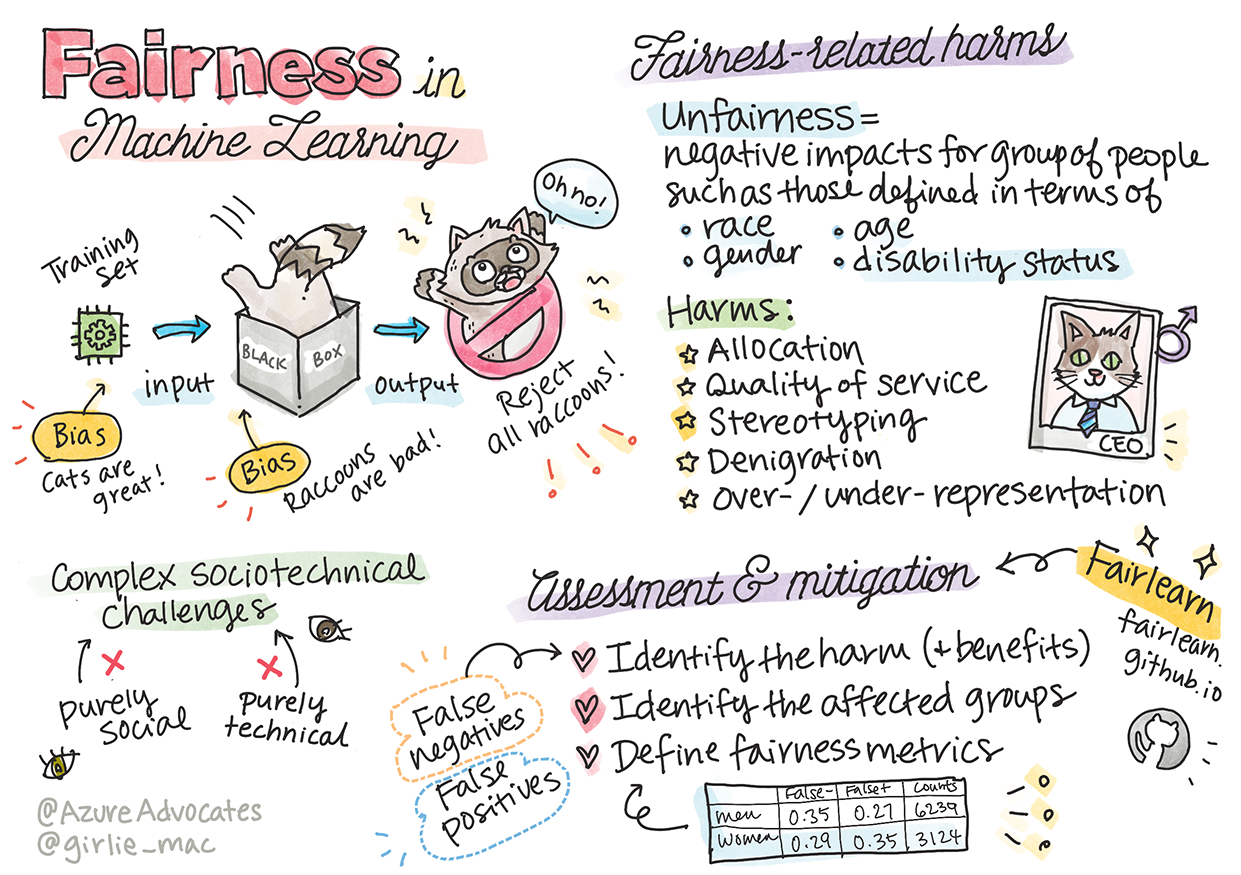
Sketchnote ni Tomomi Imura
Pre-lecture quiz
Panimula
Sa kurikulum na ito, sisimulan mong tuklasin kung paano nakakaapekto ang machine learning sa ating pang-araw-araw na buhay. Sa kasalukuyan, ang mga sistema at modelo ay ginagamit sa mga desisyon sa araw-araw tulad ng mga diagnosis sa pangangalaga ng kalusugan, pag-apruba ng pautang, o pagtuklas ng pandaraya. Kaya mahalaga na ang mga modelong ito ay gumana nang maayos upang magbigay ng mga resulta na mapagkakatiwalaan. Tulad ng anumang software application, ang mga sistema ng AI ay maaaring hindi umabot sa inaasahan o magdulot ng hindi kanais-nais na resulta. Kaya mahalaga na maunawaan at maipaliwanag ang pag-uugali ng isang AI model.
Isipin kung ano ang maaaring mangyari kapag ang data na ginagamit mo upang bumuo ng mga modelong ito ay kulang sa ilang demograpiko tulad ng lahi, kasarian, pananaw sa politika, relihiyon, o hindi pantay na kinakatawan ang mga demograpikong ito. Paano kung ang output ng modelo ay pabor sa isang demograpiko? Ano ang magiging epekto nito sa aplikasyon? Bukod dito, ano ang mangyayari kapag ang modelo ay nagkaroon ng masamang resulta at nakapinsala sa mga tao? Sino ang may pananagutan sa pag-uugali ng mga sistema ng AI? Ito ang ilan sa mga tanong na ating susuriin sa kurikulum na ito.
Sa araling ito, ikaw ay:
- Magkakaroon ng kamalayan sa kahalagahan ng pagiging patas sa machine learning at mga pinsalang kaugnay nito.
- Malalaman ang kahalagahan ng pagsusuri sa mga outliers at hindi pangkaraniwang sitwasyon upang matiyak ang pagiging maaasahan at kaligtasan.
- Mauunawaan ang pangangailangan na bigyang kapangyarihan ang lahat sa pamamagitan ng pagdidisenyo ng mga inklusibong sistema.
- Susuriin ang kahalagahan ng pagprotekta sa privacy at seguridad ng data at mga tao.
- Makikita ang kahalagahan ng "glass box" na diskarte upang maipaliwanag ang pag-uugali ng mga modelo ng AI.
- Magiging maingat sa kung paano mahalaga ang pananagutan upang makabuo ng tiwala sa mga sistema ng AI.
Paunang Kaalaman
Bilang paunang kaalaman, mangyaring kunin ang "Responsible AI Principles" Learn Path at panoorin ang video sa ibaba tungkol sa paksa:
Matuto pa tungkol sa Responsible AI sa pamamagitan ng pagsunod sa Learning Path

🎥 I-click ang imahe sa itaas para sa video: Microsoft's Approach to Responsible AI
Pagiging Patas
Ang mga sistema ng AI ay dapat tratuhin ang lahat nang patas at iwasan ang pag-apekto sa mga katulad na grupo ng tao sa iba't ibang paraan. Halimbawa, kapag ang mga sistema ng AI ay nagbibigay ng gabay sa paggamot sa medikal, aplikasyon ng pautang, o trabaho, dapat silang magbigay ng parehong rekomendasyon sa lahat ng may magkatulad na sintomas, kalagayan sa pananalapi, o kwalipikasyon sa propesyon. Bawat isa sa atin bilang tao ay may dalang likas na bias na nakakaapekto sa ating mga desisyon at aksyon. Ang mga bias na ito ay maaaring makita sa data na ginagamit natin upang sanayin ang mga sistema ng AI. Ang ganitong manipulasyon ay minsan nangyayari nang hindi sinasadya. Madalas mahirap malaman nang may kamalayan kung kailan ka nagdadala ng bias sa data.
Ang “Kawalan ng Pagiging Patas” ay sumasaklaw sa mga negatibong epekto, o “pinsala”, para sa isang grupo ng tao, tulad ng mga tinukoy batay sa lahi, kasarian, edad, o kalagayan ng kapansanan. Ang mga pangunahing pinsalang kaugnay ng pagiging patas ay maaaring uriin bilang:
- Paglalaan, kung ang isang kasarian o etnisidad ay pinapaboran kaysa sa iba.
- Kalidad ng serbisyo. Kung sinanay mo ang data para sa isang partikular na sitwasyon ngunit mas kumplikado ang realidad, nagdudulot ito ng mahinang serbisyo. Halimbawa, isang dispenser ng sabon na hindi makadetect ng mga taong may maitim na balat. Sanggunian
- Pagkakalait. Hindi patas na pagbatikos o pag-label sa isang bagay o tao. Halimbawa, isang teknolohiya sa pag-label ng imahe na maling tinukoy ang mga imahe ng mga taong may maitim na balat bilang gorilya.
- Sobra o kulang na representasyon. Ang ideya na ang isang grupo ay hindi nakikita sa isang partikular na propesyon, at anumang serbisyo o function na patuloy na nagpo-promote nito ay nagdudulot ng pinsala.
- Stereotyping. Pag-uugnay ng isang grupo sa mga pre-assigned na katangian. Halimbawa, isang sistema ng pagsasalin ng wika sa pagitan ng Ingles at Turkish ay maaaring magkaroon ng mga kamalian dahil sa mga salitang may stereotypical na kaugnayan sa kasarian.
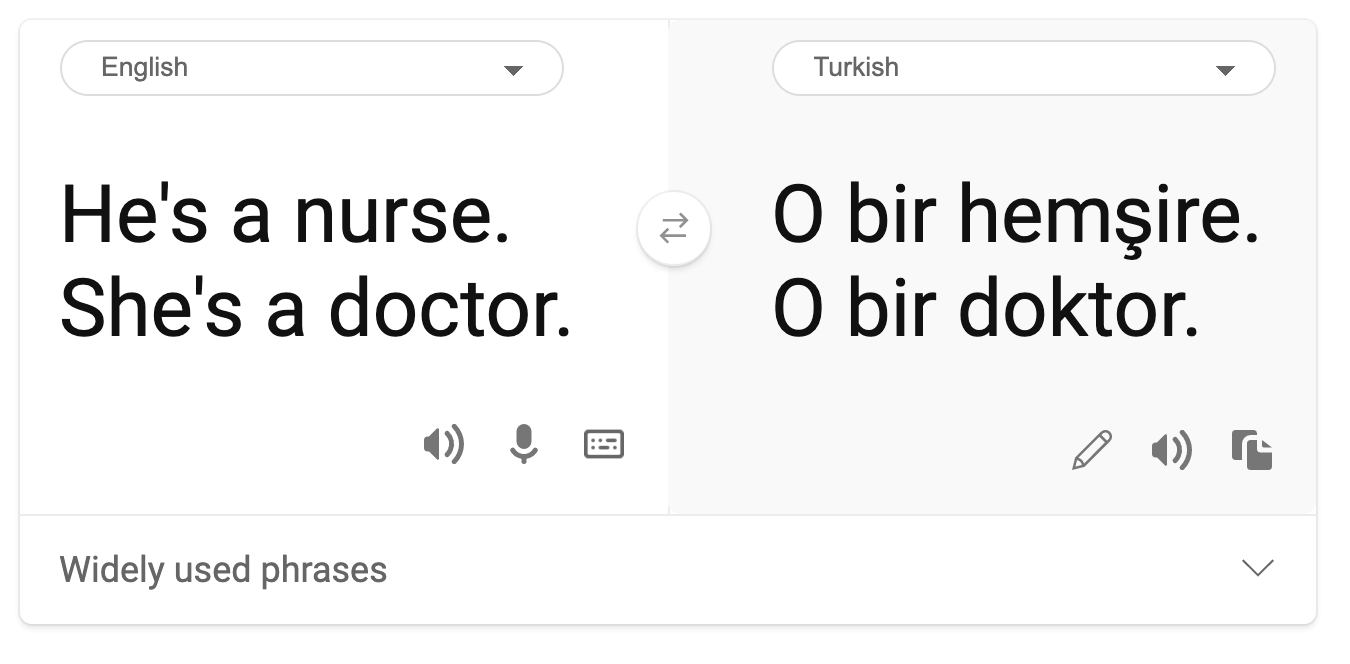
pagsasalin sa Turkish

pagsasalin pabalik sa Ingles
Kapag nagdidisenyo at sumusubok ng mga sistema ng AI, kailangan nating tiyakin na ang AI ay patas at hindi naka-program upang gumawa ng biased o diskriminatoryong desisyon, na ipinagbabawal din sa mga tao. Ang pagtiyak ng pagiging patas sa AI at machine learning ay nananatiling isang kumplikadong hamon sa teknolohiya at lipunan.
Pagiging Maaasahan at Kaligtasan
Upang makabuo ng tiwala, ang mga sistema ng AI ay kailangang maging maaasahan, ligtas, at pare-pareho sa normal at hindi inaasahang mga kondisyon. Mahalagang malaman kung paano mag-uugali ang mga sistema ng AI sa iba't ibang sitwasyon, lalo na kapag may mga outliers. Kapag gumagawa ng mga solusyon sa AI, kailangang magbigay ng malaking pansin sa kung paano haharapin ang iba't ibang sitwasyon na maaaring maranasan ng mga solusyon sa AI. Halimbawa, ang isang self-driving car ay kailangang unahin ang kaligtasan ng mga tao. Bilang resulta, ang AI na nagpapatakbo ng kotse ay kailangang isaalang-alang ang lahat ng posibleng senaryo na maaaring maranasan ng kotse tulad ng gabi, bagyo, o snowstorm, mga bata na tumatakbo sa kalsada, mga alagang hayop, mga konstruksyon sa kalsada, at iba pa. Ang kakayahan ng isang sistema ng AI na maayos na makayanan ang malawak na hanay ng mga kondisyon ay sumasalamin sa antas ng anticipation na isinasaalang-alang ng data scientist o AI developer sa disenyo o pagsubok ng sistema.
Inklusibidad
Ang mga sistema ng AI ay dapat idisenyo upang makisali at magbigay kapangyarihan sa lahat. Kapag nagdidisenyo at nagpapatupad ng mga sistema ng AI, ang mga data scientist at AI developer ay tumutukoy at tinutugunan ang mga potensyal na hadlang sa sistema na maaaring hindi sinasadyang mag-exclude ng mga tao. Halimbawa, mayroong 1 bilyong tao na may kapansanan sa buong mundo. Sa pag-unlad ng AI, mas madali nilang ma-access ang malawak na hanay ng impormasyon at mga oportunidad sa kanilang pang-araw-araw na buhay. Sa pamamagitan ng pagtugon sa mga hadlang, nagkakaroon ng pagkakataon na mag-innovate at bumuo ng mga produkto ng AI na may mas mahusay na karanasan na kapaki-pakinabang para sa lahat.
Seguridad at Privacy
Ang mga sistema ng AI ay dapat maging ligtas at igalang ang privacy ng mga tao. Ang mga tao ay mas kaunti ang tiwala sa mga sistema na naglalagay sa kanilang privacy, impormasyon, o buhay sa panganib. Kapag nagsasanay ng mga modelo ng machine learning, umaasa tayo sa data upang makabuo ng pinakamahusay na resulta. Sa paggawa nito, ang pinagmulan ng data at integridad nito ay dapat isaalang-alang. Halimbawa, ang data ba ay isinumite ng user o pampublikong magagamit? Susunod, habang nagtatrabaho sa data, mahalagang bumuo ng mga sistema ng AI na maaaring protektahan ang kumpidensyal na impormasyon at labanan ang mga pag-atake. Habang nagiging mas laganap ang AI, ang pagprotekta sa privacy at pag-secure ng mahalagang personal at impormasyon ng negosyo ay nagiging mas kritikal at kumplikado. Ang mga isyu sa privacy at seguridad ng data ay nangangailangan ng espesyal na pansin para sa AI dahil ang access sa data ay mahalaga para sa mga sistema ng AI upang makagawa ng tumpak at may kaalamang mga hula at desisyon tungkol sa mga tao.
- Bilang isang industriya, nakagawa tayo ng makabuluhang pag-unlad sa Privacy & Security, na pinasigla ng mga regulasyon tulad ng GDPR (General Data Protection Regulation).
- Gayunpaman, sa mga sistema ng AI, kailangan nating kilalanin ang tensyon sa pagitan ng pangangailangan para sa mas personal na data upang gawing mas personal at epektibo ang mga sistema – at privacy.
- Tulad ng sa pagsilang ng mga konektadong computer sa internet, nakikita rin natin ang malaking pagtaas sa bilang ng mga isyu sa seguridad na nauugnay sa AI.
- Kasabay nito, nakikita natin ang AI na ginagamit upang mapabuti ang seguridad. Halimbawa, karamihan sa mga modernong anti-virus scanner ay pinapagana ng AI heuristics ngayon.
- Kailangan nating tiyakin na ang ating mga proseso sa Data Science ay maayos na nakikiayon sa pinakabagong mga kasanayan sa privacy at seguridad.
Transparency
Ang mga sistema ng AI ay dapat na naiintindihan. Isang mahalagang bahagi ng transparency ay ang pagpapaliwanag sa pag-uugali ng mga sistema ng AI at kanilang mga bahagi. Ang pagpapabuti ng pag-unawa sa mga sistema ng AI ay nangangailangan na maunawaan ng mga stakeholder kung paano at bakit gumagana ang mga ito upang matukoy ang mga potensyal na isyu sa pagganap, mga alalahanin sa kaligtasan at privacy, bias, mga eksklusibong kasanayan, o hindi inaasahang resulta. Naniniwala rin kami na ang mga gumagamit ng mga sistema ng AI ay dapat maging tapat at bukas tungkol sa kung kailan, bakit, at paano nila pinipili na i-deploy ang mga ito, pati na rin ang mga limitasyon ng mga sistemang ginagamit nila. Halimbawa, kung ang isang bangko ay gumagamit ng isang sistema ng AI upang suportahan ang mga desisyon sa pagpapautang sa consumer, mahalagang suriin ang mga resulta at maunawaan kung aling data ang nakakaimpluwensya sa mga rekomendasyon ng sistema. Ang mga gobyerno ay nagsisimulang mag-regulate ng AI sa iba't ibang industriya, kaya ang mga data scientist at organisasyon ay dapat ipaliwanag kung ang isang sistema ng AI ay nakakatugon sa mga kinakailangan sa regulasyon, lalo na kapag may hindi kanais-nais na resulta.
- Dahil ang mga sistema ng AI ay napakakomplikado, mahirap maunawaan kung paano gumagana ang mga ito at ma-interpret ang mga resulta.
- Ang kakulangan ng pag-unawa na ito ay nakakaapekto sa paraan ng pamamahala, pagpapatakbo, at dokumentasyon ng mga sistemang ito.
- Ang kakulangan ng pag-unawa na ito ay mas mahalaga dahil nakakaapekto ito sa mga desisyon na ginawa gamit ang mga resulta na ginawa ng mga sistemang ito.
Pananagutan
Ang mga tao na nagdidisenyo at nag-deploy ng mga sistema ng AI ay dapat managot sa kung paano gumagana ang kanilang mga sistema. Ang pangangailangan para sa pananagutan ay partikular na mahalaga sa mga sensitibong teknolohiya tulad ng facial recognition. Kamakailan, nagkaroon ng lumalaking demand para sa facial recognition technology, lalo na mula sa mga organisasyon ng pagpapatupad ng batas na nakikita ang potensyal ng teknolohiya sa mga gamit tulad ng paghahanap ng mga nawawalang bata. Gayunpaman, ang mga teknolohiyang ito ay maaaring potensyal na gamitin ng isang gobyerno upang ilagay sa panganib ang mga pangunahing kalayaan ng kanilang mga mamamayan, halimbawa, sa pamamagitan ng pagpapagana ng tuloy-tuloy na surveillance ng mga partikular na indibidwal. Kaya, ang mga data scientist at organisasyon ay kailangang maging responsable sa kung paano nakakaapekto ang kanilang sistema ng AI sa mga indibidwal o lipunan.
🎥 I-click ang imahe sa itaas para sa video: Warnings of Mass Surveillance Through Facial Recognition
Sa huli, isa sa pinakamalaking tanong para sa ating henerasyon, bilang unang henerasyon na nagdadala ng AI sa lipunan, ay kung paano masisiguro na ang mga computer ay mananatiling accountable sa mga tao at kung paano masisiguro na ang mga tao na nagdidisenyo ng mga computer ay mananatiling accountable sa lahat.
Pagtatasa ng Epekto
Bago sanayin ang isang modelo ng machine learning, mahalagang magsagawa ng impact assessment upang maunawaan ang layunin ng sistema ng AI; kung ano ang nilalayong paggamit nito; kung saan ito ide-deploy; at sino ang makikipag-ugnayan sa sistema. Ang mga ito ay kapaki-pakinabang para sa reviewer(s) o tester na nag-evaluate sa sistema upang malaman kung anong mga salik ang dapat isaalang-alang kapag tinutukoy ang mga potensyal na panganib at inaasahang kahihinatnan.
Ang mga sumusunod ay mga lugar ng pokus kapag nagsasagawa ng impact assessment:
- Masamang epekto sa mga indibidwal. Ang pagiging maalam sa anumang limitasyon o kinakailangan, hindi suportadong paggamit, o anumang kilalang limitasyon na humahadlang sa pagganap ng sistema ay mahalaga upang matiyak na ang sistema ay hindi ginagamit sa paraang maaaring magdulot ng pinsala sa mga indibidwal.
- Mga kinakailangan sa data. Ang pag-unawa kung paano at saan gagamitin ng sistema ang data ay nagbibigay-daan sa mga reviewer na tuklasin ang anumang mga kinakailangan sa data na dapat mong tandaan (hal., GDPR o HIPPA data regulations). Bukod dito, suriin kung ang pinagmulan o dami ng data ay sapat para sa pagsasanay.
- Buod ng epekto. Magtipon ng listahan ng mga potensyal na pinsala na maaaring lumitaw mula sa paggamit ng sistema. Sa buong lifecycle ng ML, suriin kung ang mga isyung natukoy ay naibsan o natugunan.
- Mga naaangkop na layunin para sa bawat isa sa anim na pangunahing prinsipyo. Suriin kung ang mga layunin mula sa bawat prinsipyo ay natutugunan at kung mayroong anumang mga puwang.
Pag-debug gamit ang Responsible AI
Katulad ng pag-debug ng isang software application, ang pag-debug ng isang sistema ng AI ay isang kinakailangang proseso ng pagtukoy at paglutas ng mga isyu sa sistema. Maraming mga salik ang maaaring makaapekto sa isang modelo na hindi gumagana ayon sa inaasahan o responsable. Karamihan sa mga tradisyunal na sukatan ng pagganap ng modelo ay mga dami ng aggregate ng pagganap ng modelo, na hindi sapat upang suriin kung paano nilalabag ng isang modelo ang mga prinsipyo ng Responsible AI. Bukod dito, ang isang modelo ng machine learning ay isang black box na nagpapahirap na maunawaan kung ano ang nagdudulot ng resulta nito o magbigay ng paliwanag kapag nagkamali ito. Sa susunod na bahagi ng kursong ito, matutunan natin kung paano gamitin ang Responsible AI dashboard upang makatulong sa pag-debug ng mga sistema ng AI. Ang dashboard ay nagbibigay ng holistic na tool para sa mga data scientist at AI developer upang magsagawa ng:
- Error analysis. Upang matukoy ang pamamahagi ng error ng modelo na maaaring makaapekto sa pagiging patas o pagiging maaasahan ng sistema.
- Model overview. Upang matuklasan kung saan may mga pagkakaiba sa pagganap ng modelo sa iba't ibang data cohorts.
- Data analysis. Upang maunawaan ang pamamahagi ng data at matukoy ang anumang potensyal na bias sa data na maaaring magdulot ng mga isyu sa pagiging patas, inklusibidad, at pagiging maaasahan.
- Model interpretability. Upang maunawaan kung ano ang nakakaapekto o nakakaimpluwensya sa mga hula ng modelo. Nakakatulong ito sa pagpapaliwanag ng pag-uugali ng modelo, na mahalaga para sa transparency at pananagutan.
🚀 Hamon
Upang maiwasan ang mga pinsala na maipakilala sa Panoorin ang workshop na ito para mas maintindihan ang mga paksa:
- Sa paghahangad ng responsableng AI: Paglalapat ng mga prinsipyo sa praktika nina Besmira Nushi, Mehrnoosh Sameki, at Amit Sharma

🎥 I-click ang imahe sa itaas para sa video: RAI Toolbox: Isang open-source framework para sa paggawa ng responsableng AI nina Besmira Nushi, Mehrnoosh Sameki, at Amit Sharma
Basahin din:
-
Resource center ng Microsoft para sa RAI: Responsible AI Resources – Microsoft AI
-
FATE research group ng Microsoft: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Basahin ang tungkol sa mga tools ng Azure Machine Learning para masiguro ang pagiging patas:
Gawain
Paunawa:
Ang dokumentong ito ay isinalin gamit ang AI translation service na Co-op Translator. Bagama't sinisikap naming maging tumpak, tandaan na ang mga awtomatikong pagsasalin ay maaaring maglaman ng mga pagkakamali o hindi pagkakatugma. Ang orihinal na dokumento sa kanyang katutubong wika ang dapat ituring na opisyal na sanggunian. Para sa mahalagang impormasyon, inirerekomenda ang propesyonal na pagsasalin ng tao. Hindi kami mananagot sa anumang hindi pagkakaunawaan o maling interpretasyon na maaaring magmula sa paggamit ng pagsasaling ito.