30 KiB
เริ่มต้นกับ Python และ Scikit-learn สำหรับโมเดลการถดถอย

สเก็ตโน้ตโดย Tomomi Imura
แบบทดสอบก่อนเรียน
บทเรียนนี้มีในภาษา R ด้วย!
บทนำ
ในบทเรียนทั้งสี่นี้ คุณจะได้เรียนรู้วิธีสร้างโมเดลการถดถอย เราจะพูดถึงว่ามันมีไว้เพื่ออะไรในไม่ช้า แต่ก่อนที่คุณจะเริ่มต้น อย่าลืมเตรียมเครื่องมือที่เหมาะสมให้พร้อมสำหรับการเริ่มต้นกระบวนการนี้!
ในบทเรียนนี้ คุณจะได้เรียนรู้วิธี:
- ตั้งค่าคอมพิวเตอร์ของคุณสำหรับงานการเรียนรู้ของเครื่องในเครื่อง
- ทำงานกับ Jupyter notebooks
- ใช้ Scikit-learn รวมถึงการติดตั้ง
- สำรวจการถดถอยเชิงเส้นผ่านการฝึกปฏิบัติ
การติดตั้งและการตั้งค่า

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอสั้น ๆ เกี่ยวกับการตั้งค่าคอมพิวเตอร์ของคุณสำหรับ ML
-
ติดตั้ง Python ตรวจสอบให้แน่ใจว่า Python ได้รับการติดตั้งในคอมพิวเตอร์ของคุณแล้ว คุณจะใช้ Python สำหรับงานด้านวิทยาศาสตร์ข้อมูลและการเรียนรู้ของเครื่องหลายอย่าง ระบบคอมพิวเตอร์ส่วนใหญ่มีการติดตั้ง Python อยู่แล้ว นอกจากนี้ยังมี Python Coding Packs ที่เป็นประโยชน์เพื่อช่วยให้การตั้งค่าสำหรับผู้ใช้บางคนง่ายขึ้น
อย่างไรก็ตาม การใช้งาน Python บางอย่างอาจต้องการเวอร์ชันที่แตกต่างกัน ดังนั้นจึงเป็นประโยชน์ที่จะทำงานใน virtual environment
-
ติดตั้ง Visual Studio Code ตรวจสอบให้แน่ใจว่าคุณได้ติดตั้ง Visual Studio Code ในคอมพิวเตอร์ของคุณแล้ว ทำตามคำแนะนำเหล่านี้เพื่อ ติดตั้ง Visual Studio Code สำหรับการติดตั้งพื้นฐาน คุณจะใช้ Python ใน Visual Studio Code ในคอร์สนี้ ดังนั้นคุณอาจต้องการทบทวนวิธี ตั้งค่า Visual Studio Code สำหรับการพัฒนา Python
ทำความคุ้นเคยกับ Python โดยทำตามคอลเลกชันของ Learn modules

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอ: การใช้ Python ใน VS Code
-
ติดตั้ง Scikit-learn โดยทำตาม คำแนะนำเหล่านี้ เนื่องจากคุณต้องใช้ Python 3 จึงแนะนำให้ใช้ virtual environment โปรดทราบว่าหากคุณกำลังติดตั้งไลบรารีนี้บน Mac ที่ใช้ M1 มีคำแนะนำพิเศษในหน้าที่ลิงก์ไว้ข้างต้น
-
ติดตั้ง Jupyter Notebook คุณจะต้อง ติดตั้งแพ็กเกจ Jupyter
สภาพแวดล้อมการเขียน ML ของคุณ
คุณจะใช้ notebooks เพื่อพัฒนาโค้ด Python และสร้างโมเดลการเรียนรู้ของเครื่อง ไฟล์ประเภทนี้เป็นเครื่องมือทั่วไปสำหรับนักวิทยาศาสตร์ข้อมูล และสามารถระบุได้ด้วยนามสกุล .ipynb
Notebooks เป็นสภาพแวดล้อมแบบโต้ตอบที่ช่วยให้นักพัฒนาสามารถเขียนโค้ด เพิ่มบันทึก และเขียนเอกสารประกอบรอบ ๆ โค้ด ซึ่งมีประโยชน์มากสำหรับโครงการที่เน้นการทดลองหรือการวิจัย

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอสั้น ๆ เกี่ยวกับการฝึกปฏิบัตินี้
การฝึกปฏิบัติ - ทำงานกับ notebook
ในโฟลเดอร์นี้ คุณจะพบไฟล์ notebook.ipynb
-
เปิด notebook.ipynb ใน Visual Studio Code
Jupyter server จะเริ่มต้นพร้อมกับ Python 3+ คุณจะพบพื้นที่ใน notebook ที่สามารถ
runได้ ซึ่งเป็นส่วนของโค้ด คุณสามารถรันโค้ดบล็อกได้โดยเลือกไอคอนที่มีลักษณะเหมือนปุ่มเล่น -
เลือกไอคอน
mdและเพิ่มข้อความ markdown ต่อไปนี้ # ยินดีต้อนรับสู่ notebook ของคุณจากนั้นเพิ่มโค้ด Python
-
พิมพ์ print('hello notebook') ในโค้ดบล็อก
-
เลือกลูกศรเพื่อรันโค้ด
คุณควรเห็นข้อความที่พิมพ์ออกมา:
hello notebook

คุณสามารถสลับโค้ดกับคอมเมนต์เพื่อเขียนเอกสารประกอบใน notebook ได้ด้วยตัวเอง
✅ ลองคิดดูสักนิดว่าสภาพแวดล้อมการทำงานของนักพัฒนาเว็บแตกต่างจากของนักวิทยาศาสตร์ข้อมูลอย่างไร
เริ่มต้นใช้งาน Scikit-learn
ตอนนี้ Python ได้รับการตั้งค่าในสภาพแวดล้อมของคุณแล้ว และคุณคุ้นเคยกับ Jupyter notebooks แล้ว มาทำความคุ้นเคยกับ Scikit-learn กันเถอะ (ออกเสียงว่า sci เหมือน science) Scikit-learn มี API ที่ครอบคลุม เพื่อช่วยคุณทำงาน ML
ตามที่ระบุใน เว็บไซต์ของพวกเขา "Scikit-learn เป็นไลบรารีการเรียนรู้ของเครื่องแบบโอเพ่นซอร์สที่รองรับการเรียนรู้แบบมีผู้สอนและไม่มีผู้สอน นอกจากนี้ยังมีเครื่องมือต่าง ๆ สำหรับการฟิตโมเดล การเตรียมข้อมูล การเลือกโมเดล และการประเมินผล รวมถึงเครื่องมืออื่น ๆ อีกมากมาย"
ในคอร์สนี้ คุณจะใช้ Scikit-learn และเครื่องมืออื่น ๆ เพื่อสร้างโมเดลการเรียนรู้ของเครื่องสำหรับงานที่เรียกว่า 'การเรียนรู้ของเครื่องแบบดั้งเดิม' เราได้หลีกเลี่ยงการใช้โครงข่ายประสาทเทียมและการเรียนรู้เชิงลึกโดยเจตนา เนื่องจากหัวข้อเหล่านี้จะครอบคลุมในหลักสูตร 'AI for Beginners' ที่กำลังจะมาถึง
Scikit-learn ทำให้การสร้างโมเดลและการประเมินผลใช้งานง่ายขึ้น โดยเน้นที่การใช้ข้อมูลเชิงตัวเลขเป็นหลัก และมีชุดข้อมูลที่พร้อมใช้งานหลายชุดสำหรับการเรียนรู้ นอกจากนี้ยังมีโมเดลที่สร้างไว้ล่วงหน้าให้นักเรียนได้ลองใช้งาน มาสำรวจขั้นตอนการโหลดข้อมูลที่เตรียมไว้ล่วงหน้าและการใช้ตัวประมาณค่าในโมเดล ML แรกของคุณด้วย Scikit-learn กับข้อมูลพื้นฐานกันเถอะ
การฝึกปฏิบัติ - notebook Scikit-learn แรกของคุณ
บทแนะนำนี้ได้รับแรงบันดาลใจจาก ตัวอย่างการถดถอยเชิงเส้น บนเว็บไซต์ของ Scikit-learn

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอสั้น ๆ เกี่ยวกับการฝึกปฏิบัตินี้
ในไฟล์ notebook.ipynb ที่เกี่ยวข้องกับบทเรียนนี้ ให้ล้างเซลล์ทั้งหมดโดยกดไอคอน 'ถังขยะ'
ในส่วนนี้ คุณจะทำงานกับชุดข้อมูลขนาดเล็กเกี่ยวกับโรคเบาหวานที่มีอยู่ใน Scikit-learn เพื่อการเรียนรู้ ลองจินตนาการว่าคุณต้องการทดสอบการรักษาสำหรับผู้ป่วยเบาหวาน โมเดลการเรียนรู้ของเครื่องอาจช่วยคุณกำหนดว่าผู้ป่วยรายใดจะตอบสนองต่อการรักษาได้ดีกว่า โดยพิจารณาจากการรวมกันของตัวแปรต่าง ๆ แม้แต่โมเดลการถดถอยพื้นฐาน เมื่อแสดงผลในรูปแบบภาพ อาจแสดงข้อมูลเกี่ยวกับตัวแปรที่ช่วยให้คุณจัดระเบียบการทดลองทางคลินิกเชิงทฤษฎีของคุณได้
✅ มีวิธีการถดถอยหลายประเภท และการเลือกใช้วิธีใดขึ้นอยู่กับคำตอบที่คุณกำลังมองหา หากคุณต้องการทำนายความสูงที่เป็นไปได้ของบุคคลในช่วงอายุหนึ่ง คุณจะใช้การถดถอยเชิงเส้น เนื่องจากคุณกำลังมองหาค่าเชิงตัวเลข หากคุณสนใจที่จะค้นหาว่าประเภทของอาหารควรจัดเป็นมังสวิรัติหรือไม่ คุณกำลังมองหาการกำหนดหมวดหมู่ ดังนั้นคุณจะใช้การถดถอยโลจิสติก คุณจะได้เรียนรู้เพิ่มเติมเกี่ยวกับการถดถอยโลจิสติกในภายหลัง ลองคิดดูสักนิดเกี่ยวกับคำถามที่คุณสามารถถามข้อมูล และวิธีการใดที่เหมาะสมกว่า
มาเริ่มต้นงานนี้กันเถอะ
นำเข้าไลบรารี
สำหรับงานนี้ เราจะนำเข้าไลบรารีบางตัว:
- matplotlib เป็น เครื่องมือสร้างกราฟ ที่มีประโยชน์ และเราจะใช้มันเพื่อสร้างกราฟเส้น
- numpy numpy เป็นไลบรารีที่มีประโยชน์สำหรับการจัดการข้อมูลเชิงตัวเลขใน Python
- sklearn นี่คือไลบรารี Scikit-learn
นำเข้าไลบรารีบางตัวเพื่อช่วยในงานของคุณ
-
เพิ่มการนำเข้าโดยพิมพ์โค้ดต่อไปนี้:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionด้านบนคุณกำลังนำเข้า
matplotlib,numpyและคุณกำลังนำเข้าdatasets,linear_modelและmodel_selectionจากsklearnโดยmodel_selectionใช้สำหรับการแบ่งข้อมูลเป็นชุดฝึกอบรมและชุดทดสอบ
ชุดข้อมูลเบาหวาน
ชุดข้อมูล เบาหวาน ที่มีอยู่ในตัวประกอบด้วยตัวอย่างข้อมูล 442 ชุดเกี่ยวกับเบาหวาน โดยมีตัวแปรคุณลักษณะ 10 ตัว ซึ่งบางตัวได้แก่:
- age: อายุในปี
- bmi: ดัชนีมวลกาย
- bp: ความดันโลหิตเฉลี่ย
- s1 tc: T-Cells (ชนิดของเซลล์เม็ดเลือดขาว)
✅ ชุดข้อมูลนี้รวมถึงแนวคิดของ 'เพศ' เป็นตัวแปรคุณลักษณะที่สำคัญต่อการวิจัยเกี่ยวกับเบาหวาน ชุดข้อมูลทางการแพทย์หลายชุดรวมการจัดประเภทแบบไบนารีประเภทนี้ ลองคิดดูว่าการจัดประเภทดังกล่าวอาจกีดกันบางส่วนของประชากรจากการรักษาได้อย่างไร
ตอนนี้ โหลดข้อมูล X และ y
🎓 จำไว้ว่า นี่คือการเรียนรู้แบบมีผู้สอน และเราต้องการเป้าหมาย 'y' ที่มีชื่อกำกับ
ในเซลล์โค้ดใหม่ ให้โหลดชุดข้อมูลเบาหวานโดยเรียกใช้ load_diabetes() อินพุต return_X_y=True บ่งชี้ว่า X จะเป็นเมทริกซ์ข้อมูล และ y จะเป็นเป้าหมายการถดถอย
-
เพิ่มคำสั่ง print บางคำสั่งเพื่อแสดงรูปร่างของเมทริกซ์ข้อมูลและองค์ประกอบแรก:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])สิ่งที่คุณได้รับกลับมาเป็นผลลัพธ์คือ tuple สิ่งที่คุณทำคือกำหนดค่าสองค่
แรกของ tuple ให้กับ X และ y ตามลำดับ เรียนรู้เพิ่มเติมเกี่ยวกับ tuple
คุณสามารถเห็นว่าข้อมูลนี้มี 442 รายการที่จัดอยู่ในอาร์เรย์ที่มี 10 องค์ประกอบ:
```text
(442, 10)
[ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076
-0.04340085 -0.00259226 0.01990842 -0.01764613]
```
✅ ลองคิดดูสักนิดเกี่ยวกับความสัมพันธ์ระหว่างข้อมูลและเป้าหมายการถดถอย การถดถอยเชิงเส้นทำนายความสัมพันธ์ระหว่างคุณลักษณะ X และตัวแปรเป้าหมาย y คุณสามารถค้นหา [เป้าหมาย](https://scikit-learn.org/stable/datasets/toy_dataset.html#diabetes-dataset) สำหรับชุดข้อมูลเบาหวานในเอกสารประกอบได้หรือไม่? ชุดข้อมูลนี้แสดงอะไรให้เห็นเมื่อพิจารณาเป้าหมาย?
-
ต่อไป เลือกส่วนหนึ่งของชุดข้อมูลนี้เพื่อพล็อตโดยเลือกคอลัมน์ที่ 3 ของชุดข้อมูล คุณสามารถทำได้โดยใช้ตัวดำเนินการ
:เพื่อเลือกทุกแถว จากนั้นเลือกคอลัมน์ที่ 3 โดยใช้ดัชนี (2) คุณยังสามารถปรับรูปร่างข้อมูลให้เป็นอาร์เรย์ 2D ตามที่ต้องการสำหรับการพล็อต โดยใช้reshape(n_rows, n_columns)หากพารามิเตอร์ตัวใดตัวหนึ่งเป็น -1 มิติที่สอดคล้องกันจะถูกคำนวณโดยอัตโนมัติX = X[:, 2] X = X.reshape((-1,1))✅ คุณสามารถพิมพ์ข้อมูลออกมาเพื่อตรวจสอบรูปร่างได้ตลอดเวลา
-
ตอนนี้คุณมีข้อมูลพร้อมสำหรับการพล็อตแล้ว คุณสามารถดูได้ว่าคอมพิวเตอร์สามารถช่วยกำหนดการแบ่งที่เหมาะสมระหว่างตัวเลขในชุดข้อมูลนี้ได้หรือไม่ ในการทำเช่นนี้ คุณต้องแบ่งข้อมูล (X) และเป้าหมาย (y) ออกเป็นชุดทดสอบและชุดฝึกอบรม Scikit-learn มีวิธีที่ตรงไปตรงมาสำหรับการทำเช่นนี้ คุณสามารถแบ่งข้อมูลทดสอบของคุณที่จุดที่กำหนด
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
ตอนนี้คุณพร้อมที่จะฝึกโมเดลของคุณแล้ว! โหลดโมเดลการถดถอยเชิงเส้นและฝึกด้วยชุดฝึกอบรม X และ y ของคุณโดยใช้
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()เป็นฟังก์ชันที่คุณจะเห็นในไลบรารี ML หลายตัว เช่น TensorFlow -
จากนั้น สร้างการพยากรณ์โดยใช้ข้อมูลทดสอบ โดยใช้ฟังก์ชัน
predict()สิ่งนี้จะใช้เพื่อวาดเส้นระหว่างกลุ่มข้อมูลy_pred = model.predict(X_test) -
ตอนนี้ถึงเวลาที่จะแสดงข้อมูลในกราฟแล้ว Matplotlib เป็นเครื่องมือที่มีประโยชน์มากสำหรับงานนี้ สร้าง scatterplot ของข้อมูลทดสอบ X และ y ทั้งหมด และใช้การพยากรณ์เพื่อวาดเส้นในตำแหน่งที่เหมาะสมที่สุด ระหว่างกลุ่มข้อมูลของโมเดล
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()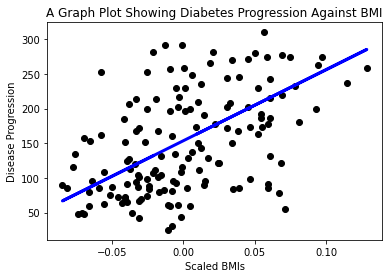 ✅ ลองคิดดูว่าเกิดอะไรขึ้นที่นี่ เส้นตรงกำลังวิ่งผ่านจุดข้อมูลเล็กๆ หลายจุด แต่จริงๆ แล้วมันกำลังทำอะไรอยู่? คุณสามารถมองเห็นได้ไหมว่าคุณควรจะใช้เส้นนี้เพื่อทำนายตำแหน่งของจุดข้อมูลใหม่ที่ยังไม่เคยเห็นมาก่อนในความสัมพันธ์กับแกน y ของกราฟได้อย่างไร? ลองอธิบายการใช้งานจริงของโมเดลนี้ออกมาเป็นคำพูด
✅ ลองคิดดูว่าเกิดอะไรขึ้นที่นี่ เส้นตรงกำลังวิ่งผ่านจุดข้อมูลเล็กๆ หลายจุด แต่จริงๆ แล้วมันกำลังทำอะไรอยู่? คุณสามารถมองเห็นได้ไหมว่าคุณควรจะใช้เส้นนี้เพื่อทำนายตำแหน่งของจุดข้อมูลใหม่ที่ยังไม่เคยเห็นมาก่อนในความสัมพันธ์กับแกน y ของกราฟได้อย่างไร? ลองอธิบายการใช้งานจริงของโมเดลนี้ออกมาเป็นคำพูด
ยินดีด้วย! คุณสร้างโมเดลการถดถอยเชิงเส้นตัวแรกของคุณ สร้างการทำนายด้วยมัน และแสดงผลในกราฟ!
🚀ความท้าทาย
ลองพล็อตตัวแปรอื่นจากชุดข้อมูลนี้ คำใบ้: แก้ไขบรรทัดนี้: X = X[:,2] จากเป้าหมายของชุดข้อมูลนี้ คุณสามารถค้นพบอะไรเกี่ยวกับการพัฒนาของโรคเบาหวานในฐานะโรค?
แบบทดสอบหลังการบรรยาย
ทบทวนและศึกษาด้วยตัวเอง
ในบทเรียนนี้ คุณได้ทำงานกับการถดถอยเชิงเส้นแบบง่าย แทนที่จะเป็นการถดถอยเชิงเส้นแบบตัวแปรเดียวหรือแบบหลายตัวแปร ลองอ่านเพิ่มเติมเกี่ยวกับความแตกต่างระหว่างวิธีการเหล่านี้ หรือดู วิดีโอนี้
อ่านเพิ่มเติมเกี่ยวกับแนวคิดของการถดถอย และลองคิดดูว่าคำถามประเภทใดที่สามารถตอบได้ด้วยเทคนิคนี้ ลองทำ บทเรียนนี้ เพื่อเพิ่มความเข้าใจของคุณ
งานที่ได้รับมอบหมาย
ข้อจำกัดความรับผิดชอบ:
เอกสารนี้ได้รับการแปลโดยใช้บริการแปลภาษา AI Co-op Translator แม้ว่าเราจะพยายามให้การแปลมีความถูกต้องมากที่สุด แต่โปรดทราบว่าการแปลโดยอัตโนมัติอาจมีข้อผิดพลาดหรือความไม่ถูกต้อง เอกสารต้นฉบับในภาษาดั้งเดิมควรถือเป็นแหล่งข้อมูลที่เชื่อถือได้ สำหรับข้อมูลที่สำคัญ ขอแนะนำให้ใช้บริการแปลภาษามืออาชีพ เราไม่รับผิดชอบต่อความเข้าใจผิดหรือการตีความผิดที่เกิดจากการใช้การแปลนี้