26 KiB
ประวัติศาสตร์ของการเรียนรู้ของเครื่อง
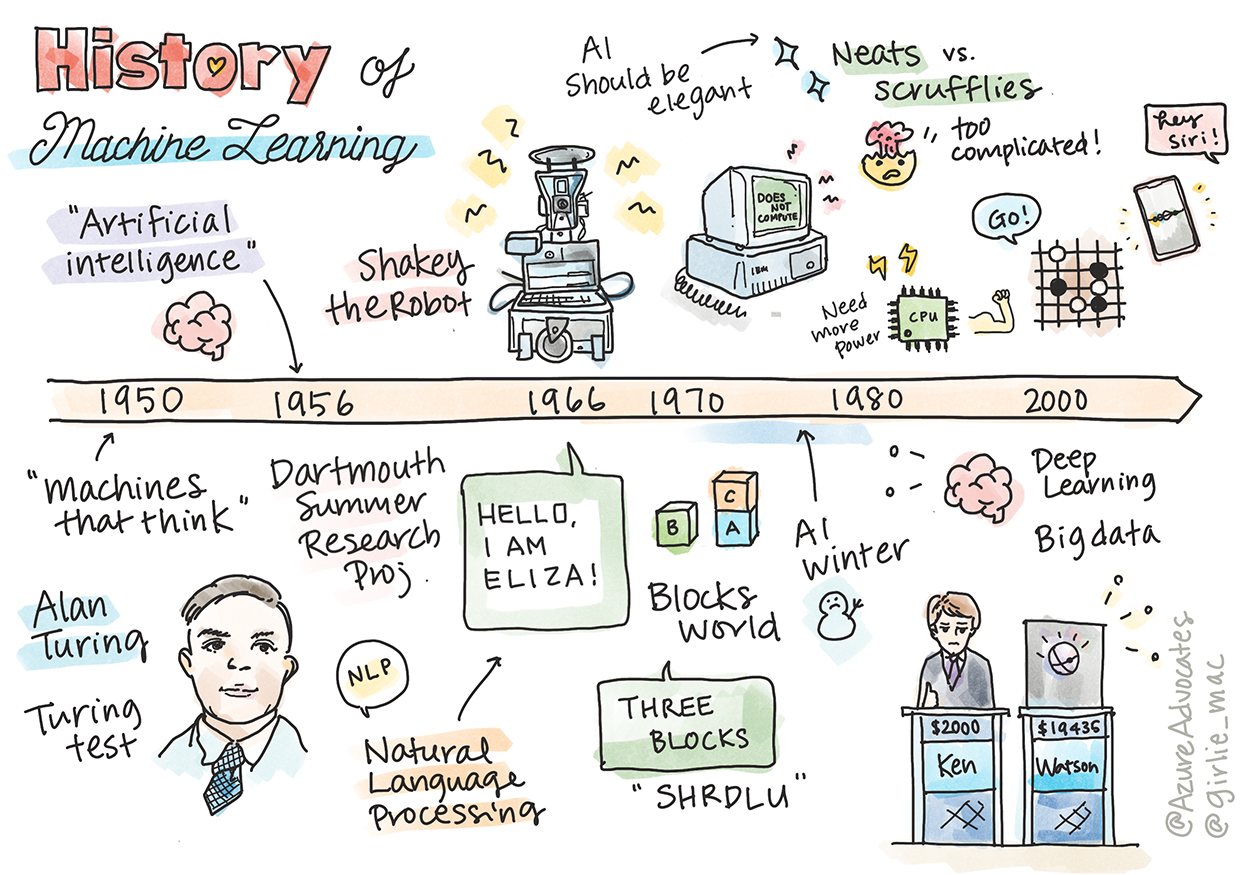
สเก็ตโน้ตโดย Tomomi Imura
แบบทดสอบก่อนเรียน

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอสั้น ๆ เกี่ยวกับบทเรียนนี้
ในบทเรียนนี้ เราจะสำรวจเหตุการณ์สำคัญในประวัติศาสตร์ของการเรียนรู้ของเครื่องและปัญญาประดิษฐ์
ประวัติศาสตร์ของปัญญาประดิษฐ์ (AI) ในฐานะสาขาวิชามีความเชื่อมโยงกับประวัติศาสตร์ของการเรียนรู้ของเครื่อง เนื่องจากอัลกอริทึมและความก้าวหน้าทางคอมพิวเตอร์ที่เป็นรากฐานของ ML ได้สนับสนุนการพัฒนา AI สิ่งสำคัญคือต้องจำไว้ว่า แม้ว่าสาขาเหล่านี้จะเริ่มเป็นรูปเป็นร่างในช่วงปี 1950 แต่ การค้นพบทางอัลกอริทึม สถิติ คณิตศาสตร์ คอมพิวเตอร์ และเทคนิคที่สำคัญ ได้เกิดขึ้นก่อนและทับซ้อนกับยุคนี้ ในความเป็นจริง มนุษย์ได้คิดเกี่ยวกับคำถามเหล่านี้มานาน หลายร้อยปี: บทความนี้กล่าวถึงรากฐานทางปัญญาในประวัติศาสตร์ของแนวคิดเกี่ยวกับ 'เครื่องจักรที่คิดได้'
การค้นพบที่สำคัญ
- 1763, 1812 ทฤษฎีของเบย์ และแนวคิดก่อนหน้า ทฤษฎีนี้และการประยุกต์ใช้เป็นพื้นฐานของการอนุมาน โดยอธิบายความน่าจะเป็นของเหตุการณ์ที่เกิดขึ้นโดยอิงจากความรู้ก่อนหน้า
- 1805 ทฤษฎีการถดถอยกำลังสองน้อยที่สุด โดยนักคณิตศาสตร์ชาวฝรั่งเศส Adrien-Marie Legendre ทฤษฎีนี้ซึ่งคุณจะได้เรียนรู้ในหน่วยการถดถอย ช่วยในการปรับข้อมูลให้เหมาะสม
- 1913 โซ่ของมาร์คอฟ ตั้งชื่อตามนักคณิตศาสตร์ชาวรัสเซีย Andrey Markov ใช้เพื่ออธิบายลำดับของเหตุการณ์ที่เป็นไปได้โดยอิงจากสถานะก่อนหน้า
- 1957 เพอร์เซปตรอน เป็นตัวจำแนกเชิงเส้นชนิดหนึ่งที่คิดค้นโดยนักจิตวิทยาชาวอเมริกัน Frank Rosenblatt ซึ่งเป็นพื้นฐานของความก้าวหน้าใน Deep Learning
- 1967 อัลกอริทึมเพื่อนบ้านที่ใกล้ที่สุด เดิมออกแบบมาเพื่อวางแผนเส้นทาง ในบริบทของ ML ใช้ในการตรวจจับรูปแบบ
- 1970 Backpropagation ใช้ในการฝึก โครงข่ายประสาทเทียมแบบฟีดฟอร์เวิร์ด
- 1982 โครงข่ายประสาทเทียมแบบวนซ้ำ เป็นโครงข่ายประสาทเทียมที่พัฒนามาจากโครงข่ายแบบฟีดฟอร์เวิร์ดที่สร้างกราฟเชิงเวลา
✅ ลองค้นคว้าเพิ่มเติม มีวันที่อื่นใดที่โดดเด่นในประวัติศาสตร์ของ ML และ AI หรือไม่?
1950: เครื่องจักรที่คิดได้
Alan Turing บุคคลที่น่าทึ่งซึ่งได้รับการโหวต จากสาธารณชนในปี 2019 ให้เป็นนักวิทยาศาสตร์ที่ยิ่งใหญ่ที่สุดแห่งศตวรรษที่ 20 ได้รับเครดิตว่าเป็นผู้วางรากฐานสำหรับแนวคิดของ 'เครื่องจักรที่สามารถคิดได้' เขาเผชิญหน้ากับผู้ที่ไม่เห็นด้วยและความต้องการหลักฐานเชิงประจักษ์ของเขาเองเกี่ยวกับแนวคิดนี้ โดยการสร้าง การทดสอบของทัวริง ซึ่งคุณจะได้สำรวจในบทเรียน NLP ของเรา
1956: โครงการวิจัยฤดูร้อนที่ดาร์ตมัธ
"โครงการวิจัยฤดูร้อนที่ดาร์ตมัธเกี่ยวกับปัญญาประดิษฐ์เป็นเหตุการณ์สำคัญสำหรับปัญญาประดิษฐ์ในฐานะสาขาวิชา" และที่นี่เองที่คำว่า 'ปัญญาประดิษฐ์' ถูกบัญญัติขึ้น (แหล่งที่มา)
ทุกแง่มุมของการเรียนรู้หรือคุณลักษณะอื่นใดของปัญญาสามารถอธิบายได้อย่างแม่นยำจนเครื่องจักรสามารถจำลองมันได้
นักวิจัยหลัก ศาสตราจารย์คณิตศาสตร์ John McCarthy หวังว่า "จะดำเนินการบนพื้นฐานของสมมติฐานที่ว่าทุกแง่มุมของการเรียนรู้หรือคุณลักษณะอื่นใดของปัญญาสามารถอธิบายได้อย่างแม่นยำจนเครื่องจักรสามารถจำลองมันได้" ผู้เข้าร่วมรวมถึงบุคคลสำคัญอีกคนในสาขานี้ Marvin Minsky
การประชุมเชิงปฏิบัติการนี้ได้รับเครดิตว่าได้เริ่มต้นและสนับสนุนการอภิปรายหลายประเด็น รวมถึง "การเพิ่มขึ้นของวิธีการเชิงสัญลักษณ์ ระบบที่มุ่งเน้นไปที่โดเมนที่จำกัด (ระบบผู้เชี่ยวชาญยุคแรก) และระบบนิรนัยเทียบกับระบบอุปนัย" (แหล่งที่มา)
1956 - 1974: "ยุคทอง"
ตั้งแต่ปี 1950 ถึงกลางปี 1970 ความหวังสูงว่าปัญญาประดิษฐ์จะสามารถแก้ปัญหาต่าง ๆ ได้ ในปี 1967 Marvin Minsky กล่าวอย่างมั่นใจว่า "ภายในหนึ่งชั่วอายุคน ... ปัญหาของการสร้าง 'ปัญญาประดิษฐ์' จะได้รับการแก้ไขอย่างมีนัยสำคัญ" (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)
การวิจัยเกี่ยวกับการประมวลผลภาษาธรรมชาติเติบโตขึ้น การค้นหาถูกปรับปรุงให้ทรงพลังยิ่งขึ้น และแนวคิดของ 'โลกจุลภาค' ถูกสร้างขึ้น ซึ่งงานง่าย ๆ ถูกทำให้สำเร็จโดยใช้คำสั่งภาษาธรรมดา
การวิจัยได้รับการสนับสนุนอย่างดีจากหน่วยงานรัฐบาล มีความก้าวหน้าในด้านการคำนวณและอัลกอริทึม และมีการสร้างต้นแบบของเครื่องจักรอัจฉริยะ เครื่องจักรบางส่วนเหล่านี้รวมถึง:
-
Shakey the robot ซึ่งสามารถเคลื่อนที่และตัดสินใจว่าจะทำงานอย่าง 'ชาญฉลาด' ได้

Shakey ในปี 1972
-
Eliza บอทสนทนาในยุคแรก ๆ สามารถพูดคุยกับผู้คนและทำหน้าที่เป็น 'นักบำบัด' แบบพื้นฐาน คุณจะได้เรียนรู้เพิ่มเติมเกี่ยวกับ Eliza ในบทเรียน NLP
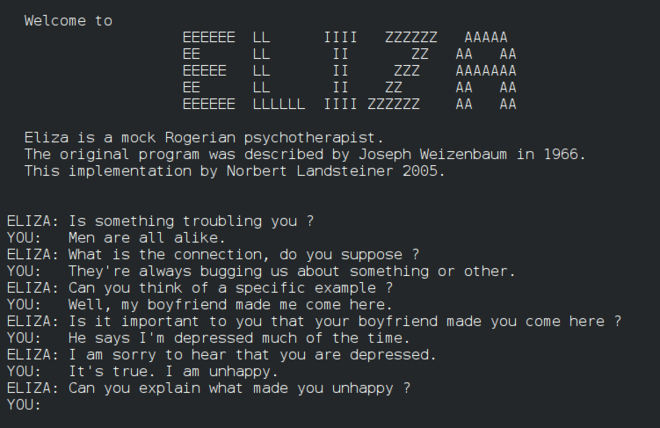
เวอร์ชันหนึ่งของ Eliza, บอทสนทนา
-
"Blocks world" เป็นตัวอย่างของโลกจุลภาคที่บล็อกสามารถซ้อนและจัดเรียงได้ และการทดลองในการสอนเครื่องจักรให้ตัดสินใจสามารถทดสอบได้ ความก้าวหน้าที่สร้างขึ้นด้วยไลบรารี เช่น SHRDLU ช่วยผลักดันการประมวลผลภาษาก้าวไปข้างหน้า

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอ: Blocks world with SHRDLU
1974 - 1980: "ฤดูหนาวของ AI"
ในช่วงกลางปี 1970 ได้ปรากฏชัดว่าความซับซ้อนของการสร้าง 'เครื่องจักรอัจฉริยะ' ถูกประเมินต่ำเกินไป และคำมั่นสัญญาของมันเมื่อเทียบกับพลังการคำนวณที่มีอยู่ถูกพูดเกินจริง การสนับสนุนทางการเงินลดลงและความมั่นใจในสาขานี้ชะลอตัว ปัญหาบางประการที่ส่งผลต่อความมั่นใจ ได้แก่:
- ข้อจำกัด พลังการคำนวณมีจำกัดเกินไป
- การระเบิดเชิงผสมผสาน จำนวนพารามิเตอร์ที่ต้องฝึกเพิ่มขึ้นแบบทวีคูณเมื่อมีการร้องขอให้คอมพิวเตอร์ทำงานมากขึ้น โดยไม่มีการพัฒนาคู่ขนานของพลังและความสามารถในการคำนวณ
- การขาดแคลนข้อมูล การขาดแคลนข้อมูลขัดขวางกระบวนการทดสอบ พัฒนา และปรับปรุงอัลกอริทึม
- เรากำลังถามคำถามที่ถูกต้องหรือไม่? คำถามที่ถูกถามเริ่มถูกตั้งคำถาม นักวิจัยเริ่มเผชิญกับคำวิจารณ์เกี่ยวกับแนวทางของพวกเขา:
- การทดสอบของทัวริงถูกตั้งคำถามผ่านแนวคิดต่าง ๆ เช่น 'ทฤษฎีห้องจีน' ซึ่งเสนอว่า "การเขียนโปรแกรมคอมพิวเตอร์ดิจิทัลอาจทำให้ดูเหมือนเข้าใจภาษา แต่ไม่สามารถสร้างความเข้าใจที่แท้จริงได้" (แหล่งที่มา)
- จริยธรรมของการแนะนำปัญญาประดิษฐ์ เช่น "นักบำบัด" ELIZA เข้าสู่สังคมถูกท้าทาย
ในเวลาเดียวกัน โรงเรียนความคิดเกี่ยวกับ AI ต่าง ๆ เริ่มก่อตัวขึ้น ความแตกต่างระหว่างแนวทาง "scruffy" กับ "neat AI" ถูกกำหนดขึ้น ห้องปฏิบัติการ scruffy ปรับแต่งโปรแกรมจนกว่าจะได้ผลลัพธ์ที่ต้องการ ในขณะที่ห้องปฏิบัติการ neat "มุ่งเน้นไปที่ตรรกะและการแก้ปัญหาอย่างเป็นทางการ" ระบบ ELIZA และ SHRDLU เป็นที่รู้จักในฐานะระบบ scruffy ในช่วงปี 1980 เมื่อความต้องการที่จะทำให้ระบบ ML สามารถทำซ้ำได้เพิ่มขึ้น แนวทาง neat ค่อย ๆ ก้าวขึ้นมาเป็นแนวหน้าเนื่องจากผลลัพธ์ของมันสามารถอธิบายได้มากกว่า
ระบบผู้เชี่ยวชาญในยุค 1980
เมื่อสาขานี้เติบโตขึ้น ประโยชน์ต่อธุรกิจก็ชัดเจนขึ้น และในยุค 1980 ระบบ 'ผู้เชี่ยวชาญ' ก็เริ่มแพร่หลาย "ระบบผู้เชี่ยวชาญเป็นหนึ่งในรูปแบบซอฟต์แวร์ปัญญาประดิษฐ์ (AI) ที่ประสบความสำเร็จอย่างแท้จริงในยุคแรก ๆ" (แหล่งที่มา)
ระบบประเภทนี้เป็นระบบ ไฮบริด ซึ่งประกอบด้วยเครื่องมือกฎที่กำหนดข้อกำหนดทางธุรกิจ และเครื่องมืออนุมานที่ใช้ระบบกฎเพื่อสรุปข้อเท็จจริงใหม่
ยุคนี้ยังเห็นความสนใจที่เพิ่มขึ้นในโครงข่ายประสาทเทียม
1987 - 1993: AI 'Chill'
การแพร่หลายของฮาร์ดแวร์ระบบผู้เชี่ยวชาญเฉพาะทางมีผลกระทบที่โชคร้ายคือการกลายเป็นเฉพาะทางเกินไป การเพิ่มขึ้นของคอมพิวเตอร์ส่วนบุคคลยังแข่งขันกับระบบขนาดใหญ่ที่มีความเชี่ยวชาญและรวมศูนย์เหล่านี้ การทำให้การคำนวณเป็นประชาธิปไตยได้เริ่มต้นขึ้น และในที่สุดก็ปูทางไปสู่การระเบิดของข้อมูลขนาดใหญ่ในยุคปัจจุบัน
1993 - 2011
ยุคนี้เป็นยุคใหม่สำหรับ ML และ AI ในการแก้ปัญหาบางประการที่เกิดขึ้นก่อนหน้านี้จากการขาดข้อมูลและพลังการคำนวณ ปริมาณข้อมูลเริ่มเพิ่มขึ้นอย่างรวดเร็วและเข้าถึงได้มากขึ้น ทั้งในด้านดีและด้านเสีย โดยเฉพาะอย่างยิ่งกับการมาของสมาร์ทโฟนในปี 2007 พลังการคำนวณขยายตัวอย่างทวีคูณ และอัลกอริทึมก็พัฒนาควบคู่กันไป สาขานี้เริ่มมีความเป็นผู้ใหญ่มากขึ้นเมื่อวันเวลาแห่งการทดลองในอดีตเริ่มตกผลึกเป็นวินัยที่แท้จริง
ปัจจุบัน
ทุกวันนี้ การเรียนรู้ของเครื่องและ AI มีบทบาทในเกือบทุกส่วนของชีวิตเรา ยุคนี้เรียกร้องให้มีความเข้าใจอย่างรอบคอบเกี่ยวกับความเสี่ยงและผลกระทบที่อาจเกิดขึ้นจากอัลกอริทึมเหล่านี้ต่อชีวิตมนุษย์ Brad Smith จาก Microsoft ได้กล่าวไว้ว่า "เทคโนโลยีสารสนเทศสร้างประเด็นที่เกี่ยวข้องกับการคุ้มครองสิทธิมนุษยชนขั้นพื้นฐาน เช่น ความเป็นส่วนตัวและเสรีภาพในการแสดงออก ประเด็นเหล่านี้เพิ่มความรับผิดชอบให้กับบริษัทเทคโนโลยีที่สร้างผลิตภัณฑ์เหล่านี้ ในมุมมองของเรา พวกเขายังเรียกร้องให้มีการกำกับดูแลของรัฐบาลที่รอบคอบและการพัฒนาบรรทัดฐานเกี่ยวกับการใช้งานที่ยอมรับได้" (แหล่งที่มา)
ยังคงต้องรอดูว่าอนาคตจะเป็นอย่างไร แต่สิ่งสำคัญคือต้องเข้าใจระบบคอมพิวเตอร์เหล่านี้ รวมถึงซอฟต์แวร์และอัลกอริทึมที่พวกมันใช้งาน เราหวังว่าหลักสูตรนี้จะช่วยให้คุณเข้าใจได้ดีขึ้น เพื่อที่คุณจะได้ตัดสินใจด้วยตัวเอง

🎥 คลิกที่ภาพด้านบนเพื่อดูวิดีโอ: Yann LeCun กล่าวถึงประวัติศาสตร์ของ Deep Learning ในการบรรยายนี้
🚀ความท้าทาย
เจาะลึกหนึ่งในช่วงเวลาประวัติศาสตร์เหล่านี้และเรียนรู้เพิ่มเติมเกี่ยวกับบุคคลที่อยู่เบื้องหลัง มีตัวละครที่น่าสนใจ และไม่มีการค้นพบทางวิทยาศาสตร์ใดที่เกิดขึ้นในสุญญากาศทางวัฒนธรรม คุณค้นพบอะไรบ้าง?
แบบทดสอบหลังเรียน
ทบทวนและศึกษาด้วยตนเอง
นี่คือรายการที่ควรดูและฟัง:
พอดแคสต์นี้ที่ Amy Boyd กล่าวถึงวิวัฒนาการของ AI

การบ้าน
ข้อจำกัดความรับผิดชอบ:
เอกสารนี้ได้รับการแปลโดยใช้บริการแปลภาษา AI Co-op Translator แม้ว่าเราจะพยายามให้การแปลมีความถูกต้อง แต่โปรดทราบว่าการแปลโดยอัตโนมัติอาจมีข้อผิดพลาดหรือความไม่ถูกต้อง เอกสารต้นฉบับในภาษาดั้งเดิมควรถือเป็นแหล่งข้อมูลที่เชื่อถือได้ สำหรับข้อมูลที่สำคัญ ขอแนะนำให้ใช้บริการแปลภาษาจากผู้เชี่ยวชาญ เราไม่รับผิดชอบต่อความเข้าใจผิดหรือการตีความที่ผิดพลาดซึ่งเกิดจากการใช้การแปลนี้