15 KiB
Anza na Python na Scikit-learn kwa mifano ya regression

Sketchnote na Tomomi Imura
Jaribio la awali la somo
Somo hili linapatikana kwa R!
Utangulizi
Katika masomo haya manne, utajifunza jinsi ya kujenga mifano ya regression. Tutajadili matumizi yake hivi karibuni. Lakini kabla ya kuanza, hakikisha una zana sahihi za kuanza mchakato!
Katika somo hili, utajifunza jinsi ya:
- Kuseti kompyuta yako kwa kazi za kujifunza mashine za ndani.
- Kufanya kazi na Jupyter notebooks.
- Kutumia Scikit-learn, ikiwa ni pamoja na usakinishaji.
- Kuchunguza regression ya mstari kupitia zoezi la vitendo.
Usakinishaji na usanidi

🎥 Bonyeza picha hapo juu kwa video fupi ya jinsi ya kusanidi kompyuta yako kwa ML.
-
Sakinisha Python. Hakikisha kuwa Python imewekwa kwenye kompyuta yako. Utatumia Python kwa kazi nyingi za sayansi ya data na kujifunza mashine. Mfumo mwingi wa kompyuta tayari una usakinishaji wa Python. Kuna Python Coding Packs zinazopatikana pia, ili kurahisisha usanidi kwa watumiaji wengine.
Baadhi ya matumizi ya Python yanahitaji toleo moja la programu, wakati mengine yanahitaji toleo tofauti. Kwa sababu hii, ni muhimu kufanya kazi ndani ya mazingira ya kawaida.
-
Sakinisha Visual Studio Code. Hakikisha kuwa Visual Studio Code imewekwa kwenye kompyuta yako. Fuata maelekezo haya ili kusakinisha Visual Studio Code kwa usakinishaji wa msingi. Utatumia Python ndani ya Visual Studio Code katika kozi hii, kwa hivyo unaweza kutaka kujifunza jinsi ya kusanidi Visual Studio Code kwa maendeleo ya Python.
Jifunze Python kwa kupitia mkusanyiko huu wa moduli za kujifunza

🎥 Bonyeza picha hapo juu kwa video: kutumia Python ndani ya VS Code.
-
Sakinisha Scikit-learn, kwa kufuata maelekezo haya. Kwa kuwa unahitaji kuhakikisha unatumia Python 3, inashauriwa utumie mazingira ya kawaida. Kumbuka, ikiwa unasakinisha maktaba hii kwenye Mac ya M1, kuna maelekezo maalum kwenye ukurasa uliohusishwa hapo juu.
-
Sakinisha Jupyter Notebook. Utahitaji kusakinisha kifurushi cha Jupyter.
Mazingira yako ya kuandika ML
Utatumia notebooks kuendeleza msimbo wako wa Python na kuunda mifano ya kujifunza mashine. Aina hii ya faili ni zana ya kawaida kwa wanasayansi wa data, na zinaweza kutambulika kwa kiambishi au kiendelezi .ipynb.
Notebooks ni mazingira ya maingiliano yanayomruhusu msanidi programu kuandika msimbo na kuongeza maelezo na kuandika nyaraka kuzunguka msimbo, jambo ambalo ni muhimu sana kwa miradi ya majaribio au utafiti.

🎥 Bonyeza picha hapo juu kwa video fupi ya kufanya zoezi hili.
Zoezi - kufanya kazi na notebook
Katika folda hii, utapata faili notebook.ipynb.
-
Fungua notebook.ipynb ndani ya Visual Studio Code.
Seva ya Jupyter itaanza na Python 3+ imeanzishwa. Utapata maeneo ya notebook ambayo yanaweza
kuendeshwa, vipande vya msimbo. Unaweza kuendesha kipande cha msimbo kwa kuchagua ikoni inayofanana na kitufe cha kucheza. -
Chagua ikoni ya
mdna ongeza kidogo cha markdown, na maandishi yafuatayo # Karibu kwenye notebook yako.Kisha, ongeza msimbo wa Python.
-
Andika print('hello notebook') kwenye kipande cha msimbo.
-
Chagua mshale ili kuendesha msimbo.
Unapaswa kuona taarifa iliyochapishwa:
hello notebook

Unaweza kuchanganya msimbo wako na maoni ili kujidokumentisha notebook.
✅ Fikiria kwa dakika moja jinsi mazingira ya kazi ya msanidi programu wa wavuti yanavyotofautiana na yale ya mwanasayansi wa data.
Kuanzisha na Scikit-learn
Sasa kwa kuwa Python imewekwa katika mazingira yako ya ndani, na unajisikia vizuri na Jupyter notebooks, hebu tujifunze vizuri na Scikit-learn (tamka sci kama science). Scikit-learn inatoa API ya kina kusaidia kufanya kazi za ML.
Kulingana na tovuti yao, "Scikit-learn ni maktaba ya kujifunza mashine ya chanzo huria inayounga mkono kujifunza kwa usimamizi na bila usimamizi. Pia inatoa zana mbalimbali za kufaa mifano, usindikaji wa data, uteuzi wa mifano na tathmini, na huduma nyingine nyingi."
Katika kozi hii, utatumia Scikit-learn na zana nyingine kujenga mifano ya kujifunza mashine kufanya kile tunachokiita 'kazi za kujifunza mashine za jadi'. Tumeepuka makusudi mitandao ya neva na kujifunza kwa kina, kwani zinashughulikiwa vyema katika mtaala wetu ujao wa 'AI kwa Wanaoanza'.
Scikit-learn inafanya iwe rahisi kujenga mifano na kuipima kwa matumizi. Inalenga hasa kutumia data ya nambari na ina datasets kadhaa zilizotayarishwa tayari kwa matumizi kama zana za kujifunza. Pia inajumuisha mifano iliyojengwa tayari kwa wanafunzi kujaribu. Hebu tuchunguze mchakato wa kupakia data iliyopakiwa awali na kutumia estimator iliyojengwa kwa mfano wa kwanza wa ML na Scikit-learn na data ya msingi.
Zoezi - notebook yako ya kwanza ya Scikit-learn
Mafunzo haya yamechochewa na mfano wa regression ya mstari kwenye tovuti ya Scikit-learn.

🎥 Bonyeza picha hapo juu kwa video fupi ya kufanya zoezi hili.
Katika faili notebook.ipynb lililohusishwa na somo hili, futa seli zote kwa kubonyeza ikoni ya 'takataka'.
Katika sehemu hii, utatumia dataset ndogo kuhusu ugonjwa wa kisukari ambayo imejengwa ndani ya Scikit-learn kwa madhumuni ya kujifunza. Fikiria kwamba unataka kujaribu matibabu kwa wagonjwa wa kisukari. Mifano ya Kujifunza Mashine inaweza kusaidia kuamua ni wagonjwa gani watakaoitikia matibabu vizuri zaidi, kulingana na mchanganyiko wa vigezo. Hata mfano wa regression ya msingi, unapowekwa kwenye grafu, unaweza kuonyesha taarifa kuhusu vigezo ambavyo vinaweza kusaidia kupanga majaribio yako ya kliniki ya kinadharia.
✅ Kuna aina nyingi za mbinu za regression, na ni ipi unayochagua inategemea jibu unalotafuta. Ikiwa unataka kutabiri urefu unaowezekana wa mtu wa umri fulani, ungetumia regression ya mstari, kwani unatafuta thamani ya nambari. Ikiwa unavutiwa na kugundua kama aina ya chakula inapaswa kuzingatiwa kuwa ya mboga au la, unatafuta ugawaji wa kategoria kwa hivyo ungetumia regression ya logistic. Utajifunza zaidi kuhusu regression ya logistic baadaye. Fikiria kidogo kuhusu maswali unayoweza kuuliza data, na ni mbinu ipi kati ya hizi itakuwa sahihi zaidi.
Hebu tuanze kazi hii.
Ingiza maktaba
Kwa kazi hii tutaleta maktaba kadhaa:
- matplotlib. Ni chombo cha kuchora grafu na tutakitumia kuunda grafu ya mstari.
- numpy. numpy ni maktaba muhimu kwa kushughulikia data ya nambari katika Python.
- sklearn. Hii ni maktaba ya Scikit-learn.
Ingiza maktaba kadhaa kusaidia kazi zako.
-
Ongeza imports kwa kuandika msimbo ufuatao:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionHapo juu unaleta
matplotlib,numpyna unaletadatasets,linear_modelnamodel_selectionkutokasklearn.model_selectionhutumika kugawanya data katika seti za mafunzo na majaribio.
Dataset ya kisukari
Dataset ya kisukari iliyojengwa ndani ina sampuli 442 za data kuhusu kisukari, na vigezo 10 vya sifa, baadhi ya ambazo ni pamoja na:
- umri: umri kwa miaka
- bmi: index ya uzito wa mwili
- bp: shinikizo la damu la wastani
- s1 tc: T-Cells (aina ya seli nyeupe za damu)
✅ Dataset hii inajumuisha dhana ya 'jinsia' kama kigezo cha sifa muhimu kwa utafiti kuhusu kisukari. Dataset nyingi za matibabu zinajumuisha aina hii ya uainishaji wa binary. Fikiria kidogo kuhusu jinsi uainishaji kama huu unaweza kuwatenga sehemu fulani za idadi ya watu kutoka kwa matibabu.
Sasa, pakia data ya X na y.
🎓 Kumbuka, hii ni kujifunza kwa usimamizi, na tunahitaji lengo lililopewa jina 'y'.
Katika seli mpya ya msimbo, pakia dataset ya kisukari kwa kuita load_diabetes(). Ingizo return_X_y=True linaashiria kwamba X itakuwa matrix ya data, na y itakuwa lengo la regression.
-
Ongeza amri za kuchapisha ili kuonyesha umbo la matrix ya data na kipengele chake cha kwanza:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Unachopata kama jibu ni tuple. Unachofanya ni kugawa thamani mbili za kwanza za tuple kwa
Xnaymtawalia. Jifunze zaidi kuhusu tuples.Unaweza kuona kwamba data hii ina vitu 442 vilivyopangwa katika arrays za vipengele 10:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Fikiria kidogo kuhusu uhusiano kati ya data na lengo la regression. Regression ya mstari inatabiri uhusiano kati ya kipengele X na kigezo cha lengo y. Je, unaweza kupata lengo kwa dataset ya kisukari katika nyaraka? Dataset hii inaonyesha nini, ikizingatiwa lengo?
-
Kisha, chagua sehemu ya dataset hii ili kuweka grafu kwa kuchagua safu ya 3 ya dataset. Unaweza kufanya hivi kwa kutumia operator
:kuchagua safu zote, na kisha kuchagua safu ya 3 kwa kutumia index (2). Unaweza pia kupanga upya data kuwa array ya 2D - kama inavyohitajika kwa kuweka grafu - kwa kutumiareshape(n_rows, n_columns). Ikiwa moja ya parameter ni -1, kipimo kinacholingana kinahesabiwa kiotomatiki.X = X[:, 2] X = X.reshape((-1,1))✅ Wakati wowote, chapisha data ili kuangalia umbo lake.
-
Sasa kwa kuwa una data tayari kuwekwa kwenye grafu, unaweza kuona kama mashine inaweza kusaidia kuamua mgawanyiko wa kimantiki kati ya nambari katika dataset hii. Ili kufanya hivyo, unahitaji kugawanya data (X) na lengo (y) katika seti za majaribio na mafunzo. Scikit-learn ina njia rahisi ya kufanya hivi; unaweza kugawanya data yako ya majaribio katika sehemu fulani.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Sasa uko tayari kufundisha mfano wako! Pakia mfano wa regression ya mstari na uufundishe na seti zako za mafunzo za X na y kwa kutumia
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()ni kazi utakayoiona katika maktaba nyingi za ML kama TensorFlow. -
Kisha, tengeneza utabiri kwa kutumia data ya majaribio, kwa kutumia kazi
predict(). Hii itatumika kuchora mstari kati ya vikundi vya data.y_pred = model.predict(X_test) -
Sasa ni wakati wa kuonyesha data kwenye grafu. Matplotlib ni chombo muhimu sana kwa kazi hii. Tengeneza grafu ya alama za X na y za majaribio, na tumia utabiri kuchora mstari mahali panapofaa zaidi, kati ya vikundi vya data vya mfano.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()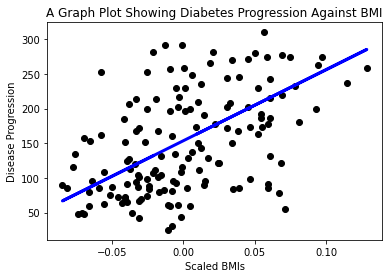 ✅ Fikiria kidogo kuhusu kinachoendelea hapa. Mstari wa moja kwa moja unapita katikati ya nukta nyingi ndogo za data, lakini unafanya nini hasa? Je, unaweza kuona jinsi unavyoweza kutumia mstari huu kutabiri mahali ambapo data mpya, ambayo haijawahi kuonekana, inapaswa kutoshea kuhusiana na mhimili wa y wa mchoro? Jaribu kuelezea kwa maneno matumizi ya vitendo ya mfano huu.
✅ Fikiria kidogo kuhusu kinachoendelea hapa. Mstari wa moja kwa moja unapita katikati ya nukta nyingi ndogo za data, lakini unafanya nini hasa? Je, unaweza kuona jinsi unavyoweza kutumia mstari huu kutabiri mahali ambapo data mpya, ambayo haijawahi kuonekana, inapaswa kutoshea kuhusiana na mhimili wa y wa mchoro? Jaribu kuelezea kwa maneno matumizi ya vitendo ya mfano huu.
Hongera, umeunda mfano wako wa kwanza wa regression ya mstari, umetengeneza utabiri kwa kutumia, na kuonyesha katika mchoro!
🚀Changamoto
Chora variable tofauti kutoka kwa dataset hii. Kidokezo: hariri mstari huu: X = X[:,2]. Ukiangalia lengo la dataset hii, unaweza kugundua nini kuhusu maendeleo ya ugonjwa wa kisukari?
Jaribio baada ya somo
Mapitio na Kujisomea
Katika mafunzo haya, ulifanya kazi na regression rahisi ya mstari, badala ya regression ya univariate au multiple. Soma kidogo kuhusu tofauti kati ya mbinu hizi, au angalia video hii.
Soma zaidi kuhusu dhana ya regression na fikiria ni aina gani za maswali yanayoweza kujibiwa kwa mbinu hii. Chukua mafunzo haya ili kuongeza uelewa wako.
Kazi
Kanusho:
Hati hii imetafsiriwa kwa kutumia huduma ya kutafsiri ya AI Co-op Translator. Ingawa tunajitahidi kuhakikisha usahihi, tafadhali fahamu kuwa tafsiri za kiotomatiki zinaweza kuwa na makosa au kutokuwa sahihi. Hati ya asili katika lugha yake ya awali inapaswa kuzingatiwa kama chanzo cha mamlaka. Kwa taarifa muhimu, tafsiri ya kitaalamu ya binadamu inapendekezwa. Hatutawajibika kwa kutoelewana au tafsiri zisizo sahihi zinazotokana na matumizi ya tafsiri hii.