16 KiB
Kom igång med Python och Scikit-learn för regressionsmodeller

Sketchnote av Tomomi Imura
Quiz före föreläsningen
Den här lektionen finns tillgänglig i R!
Introduktion
I dessa fyra lektioner kommer du att lära dig hur man bygger regressionsmodeller. Vi kommer snart att diskutera vad dessa används till. Men innan du gör något, se till att du har rätt verktyg på plats för att starta processen!
I den här lektionen kommer du att lära dig att:
- Konfigurera din dator för lokala maskininlärningsuppgifter.
- Arbeta med Jupyter-notebooks.
- Använda Scikit-learn, inklusive installation.
- Utforska linjär regression med en praktisk övning.
Installationer och konfigurationer

🎥 Klicka på bilden ovan för en kort video om att konfigurera din dator för ML.
-
Installera Python. Se till att Python är installerat på din dator. Du kommer att använda Python för många data science- och maskininlärningsuppgifter. De flesta datorsystem har redan en Python-installation. Det finns användbara Python Coding Packs som kan underlätta installationen för vissa användare.
Vissa användningsområden för Python kräver dock en viss version av programvaran, medan andra kräver en annan version. Därför är det användbart att arbeta inom en virtuell miljö.
-
Installera Visual Studio Code. Se till att du har Visual Studio Code installerat på din dator. Följ dessa instruktioner för att installera Visual Studio Code för grundläggande installation. Du kommer att använda Python i Visual Studio Code i den här kursen, så det kan vara bra att fräscha upp hur man konfigurerar Visual Studio Code för Python-utveckling.
Bli bekväm med Python genom att arbeta igenom denna samling av Learn-moduler

🎥 Klicka på bilden ovan för en video: använda Python i VS Code.
-
Installera Scikit-learn, genom att följa dessa instruktioner. Eftersom du behöver använda Python 3 rekommenderas det att du använder en virtuell miljö. Observera att om du installerar detta bibliotek på en M1 Mac finns det särskilda instruktioner på sidan som är länkad ovan.
-
Installera Jupyter Notebook. Du behöver installera Jupyter-paketet.
Din ML-utvecklingsmiljö
Du kommer att använda notebooks för att utveckla din Python-kod och skapa maskininlärningsmodeller. Denna typ av fil är ett vanligt verktyg för dataforskare och kan identifieras genom deras suffix eller filändelse .ipynb.
Notebooks är en interaktiv miljö som gör det möjligt för utvecklaren att både koda och lägga till anteckningar samt skriva dokumentation kring koden, vilket är mycket användbart för experimentella eller forskningsorienterade projekt.

🎥 Klicka på bilden ovan för en kort video som går igenom denna övning.
Övning - arbeta med en notebook
I den här mappen hittar du filen notebook.ipynb.
-
Öppna notebook.ipynb i Visual Studio Code.
En Jupyter-server kommer att starta med Python 3+. Du kommer att hitta områden i notebooken som kan
köras, kodstycken. Du kan köra en kodblock genom att välja ikonen som ser ut som en play-knapp. -
Välj
md-ikonen och lägg till lite markdown, och följande text # Välkommen till din notebook.Lägg sedan till lite Python-kod.
-
Skriv print('hello notebook') i kodblocket.
-
Välj pilen för att köra koden.
Du bör se det utskrivna meddelandet:
hello notebook

Du kan blanda din kod med kommentarer för att själv dokumentera notebooken.
✅ Fundera en stund på hur annorlunda en webbutvecklares arbetsmiljö är jämfört med en dataforskares.
Kom igång med Scikit-learn
Nu när Python är inställt i din lokala miljö och du är bekväm med Jupyter-notebooks, låt oss bli lika bekväma med Scikit-learn (uttalas sci som i science). Scikit-learn erbjuder ett omfattande API för att hjälpa dig utföra ML-uppgifter.
Enligt deras webbplats, "Scikit-learn är ett open source-maskininlärningsbibliotek som stödjer övervakad och oövervakad inlärning. Det erbjuder också olika verktyg för modellanpassning, datapreprocessering, modellval och utvärdering, samt många andra verktyg."
I den här kursen kommer du att använda Scikit-learn och andra verktyg för att bygga maskininlärningsmodeller för att utföra det vi kallar 'traditionella maskininlärningsuppgifter'. Vi har medvetet undvikit neurala nätverk och djupinlärning, eftersom de täcks bättre i vår kommande 'AI för nybörjare'-kursplan.
Scikit-learn gör det enkelt att bygga modeller och utvärdera dem för användning. Det är främst fokuserat på att använda numerisk data och innehåller flera färdiga dataset för användning som inlärningsverktyg. Det inkluderar också förbyggda modeller för studenter att prova. Låt oss utforska processen att ladda förpackad data och använda en inbyggd estimator för att skapa den första ML-modellen med Scikit-learn med lite grundläggande data.
Övning - din första Scikit-learn notebook
Den här handledningen inspirerades av exemplet på linjär regression på Scikit-learns webbplats.

🎥 Klicka på bilden ovan för en kort video som går igenom denna övning.
I filen notebook.ipynb som är kopplad till denna lektion, rensa alla celler genom att trycka på 'papperskorgsikonen'.
I detta avsnitt kommer du att arbeta med ett litet dataset om diabetes som är inbyggt i Scikit-learn för inlärningsändamål. Föreställ dig att du ville testa en behandling för diabetiker. Maskininlärningsmodeller kan hjälpa dig att avgöra vilka patienter som skulle svara bättre på behandlingen, baserat på kombinationer av variabler. Även en mycket grundläggande regressionsmodell, när den visualiseras, kan visa information om variabler som skulle hjälpa dig att organisera dina teoretiska kliniska prövningar.
✅ Det finns många typer av regressionsmetoder, och vilken du väljer beror på svaret du söker. Om du vill förutsäga den sannolika längden för en person i en viss ålder skulle du använda linjär regression, eftersom du söker ett numeriskt värde. Om du är intresserad av att avgöra om en typ av mat ska betraktas som vegansk eller inte, söker du en kategoriindelning, så du skulle använda logistisk regression. Du kommer att lära dig mer om logistisk regression senare. Fundera lite på några frågor du kan ställa till data och vilken av dessa metoder som skulle vara mer lämplig.
Låt oss komma igång med denna uppgift.
Importera bibliotek
För denna uppgift kommer vi att importera några bibliotek:
- matplotlib. Det är ett användbart grafverktyg och vi kommer att använda det för att skapa ett linjediagram.
- numpy. numpy är ett användbart bibliotek för att hantera numerisk data i Python.
- sklearn. Detta är Scikit-learn-biblioteket.
Importera några bibliotek för att hjälpa till med dina uppgifter.
-
Lägg till imports genom att skriva följande kod:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionOvan importerar du
matplotlib,numpyoch du importerardatasets,linear_modelochmodel_selectionfrånsklearn.model_selectionanvänds för att dela upp data i tränings- och testuppsättningar.
Diabetes-datasetet
Det inbyggda diabetes-datasetet innehåller 442 dataprover om diabetes, med 10 funktionsvariabler, några av dessa inkluderar:
- age: ålder i år
- bmi: kroppsmassaindex
- bp: genomsnittligt blodtryck
- s1 tc: T-celler (en typ av vita blodkroppar)
✅ Detta dataset inkluderar konceptet 'kön' som en funktionsvariabel som är viktig för forskning kring diabetes. Många medicinska dataset inkluderar denna typ av binär klassificering. Fundera lite på hur kategoriseringar som denna kan utesluta vissa delar av befolkningen från behandlingar.
Nu, ladda upp X- och y-datan.
🎓 Kom ihåg, detta är övervakad inlärning, och vi behöver ett namngivet 'y'-mål.
I en ny kodcell, ladda diabetes-datasetet genom att kalla load_diabetes(). Inputen return_X_y=True signalerar att X kommer att vara en datamatriser, och y kommer att vara regressionsmålet.
-
Lägg till några print-kommandon för att visa formen på datamatriserna och dess första element:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Det du får tillbaka som svar är en tuple. Det du gör är att tilldela de två första värdena i tuplen till
Xochyrespektive. Läs mer om tuples.Du kan se att denna data har 442 objekt formade i arrayer med 10 element:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Fundera lite på relationen mellan datan och regressionsmålet. Linjär regression förutsäger relationer mellan funktion X och målvariabel y. Kan du hitta målet för diabetes-datasetet i dokumentationen? Vad demonstrerar detta dataset, givet målet?
-
Välj sedan en del av detta dataset att plotta genom att välja den tredje kolumnen i datasetet. Du kan göra detta genom att använda
:-operatorn för att välja alla rader och sedan välja den tredje kolumnen med hjälp av index (2). Du kan också omforma datan till att vara en 2D-array - som krävs för att plotta - genom att användareshape(n_rows, n_columns). Om en av parametrarna är -1 beräknas motsvarande dimension automatiskt.X = X[:, 2] X = X.reshape((-1,1))✅ När som helst, skriv ut datan för att kontrollera dess form.
-
Nu när du har data redo att plottas kan du se om en maskin kan hjälpa till att bestämma en logisk uppdelning mellan siffrorna i detta dataset. För att göra detta behöver du dela både datan (X) och målet (y) i test- och träningsuppsättningar. Scikit-learn har ett enkelt sätt att göra detta; du kan dela din testdata vid en given punkt.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Nu är du redo att träna din modell! Ladda upp den linjära regressionsmodellen och träna den med dina X- och y-träningsuppsättningar med hjälp av
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()är en funktion du kommer att se i många ML-bibliotek som TensorFlow. -
Skapa sedan en förutsägelse med testdata, med hjälp av funktionen
predict(). Detta kommer att användas för att dra linjen mellan datagrupperna.y_pred = model.predict(X_test) -
Nu är det dags att visa datan i ett diagram. Matplotlib är ett mycket användbart verktyg för denna uppgift. Skapa ett spridningsdiagram av all X- och y-testdata och använd förutsägelsen för att dra en linje på den mest lämpliga platsen mellan modellens datagrupperingar.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()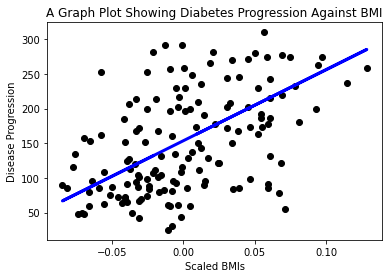 ✅ Fundera lite på vad som händer här. En rak linje går genom många små datapunkter, men vad gör den egentligen? Kan du se hur du borde kunna använda denna linje för att förutsäga var en ny, osedd datapunkt borde passa in i förhållande till diagrammets y-axel? Försök att formulera den praktiska användningen av denna modell.
✅ Fundera lite på vad som händer här. En rak linje går genom många små datapunkter, men vad gör den egentligen? Kan du se hur du borde kunna använda denna linje för att förutsäga var en ny, osedd datapunkt borde passa in i förhållande till diagrammets y-axel? Försök att formulera den praktiska användningen av denna modell.
Grattis, du har byggt din första linjära regressionsmodell, skapat en förutsägelse med den och visat den i ett diagram!
🚀Utmaning
Plotta en annan variabel från denna dataset. Tips: redigera denna rad: X = X[:,2]. Givet målet för denna dataset, vad kan du upptäcka om utvecklingen av diabetes som sjukdom?
Quiz efter föreläsningen
Granskning & Självstudier
I denna handledning arbetade du med enkel linjär regression, snarare än univariat eller multipel linjär regression. Läs lite om skillnaderna mellan dessa metoder, eller titta på denna video.
Läs mer om konceptet regression och fundera på vilka typer av frågor som kan besvaras med denna teknik. Ta denna handledning för att fördjupa din förståelse.
Uppgift
Ansvarsfriskrivning:
Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet, vänligen notera att automatiska översättningar kan innehålla fel eller felaktigheter. Det ursprungliga dokumentet på dess originalspråk bör betraktas som den auktoritativa källan. För kritisk information rekommenderas professionell mänsklig översättning. Vi ansvarar inte för eventuella missförstånd eller feltolkningar som uppstår vid användning av denna översättning.