17 KiB
Bygga maskininlärningslösningar med ansvarsfull AI
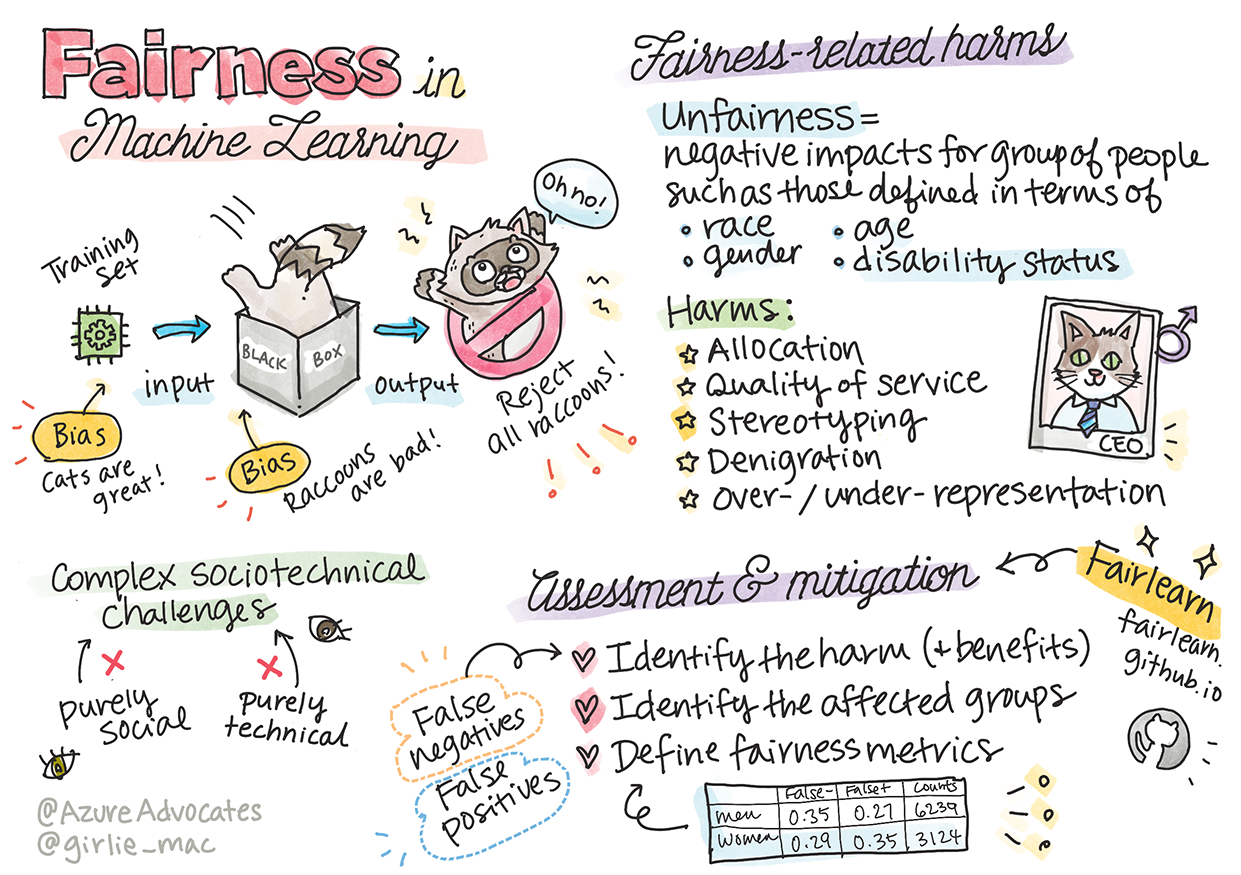
Sketchnote av Tomomi Imura
Quiz före föreläsningen
Introduktion
I denna kursplan kommer du att börja upptäcka hur maskininlärning kan och redan påverkar våra dagliga liv. Redan nu är system och modeller involverade i dagliga beslutsprocesser, som exempelvis hälsovårdsdiagnoser, låneansökningar eller att upptäcka bedrägerier. Därför är det viktigt att dessa modeller fungerar väl för att ge resultat som är pålitliga. Precis som med vilken mjukvaruapplikation som helst kommer AI-system att missa förväntningar eller ge oönskade resultat. Det är därför avgörande att kunna förstå och förklara beteendet hos en AI-modell.
Föreställ dig vad som kan hända när data som används för att bygga dessa modeller saknar vissa demografiska grupper, som exempelvis ras, kön, politiska åsikter eller religion, eller när dessa grupper är oproportionerligt representerade. Vad händer om modellens resultat tolkas som att gynna vissa grupper? Vilka blir konsekvenserna för applikationen? Dessutom, vad händer när modellen ger ett negativt resultat som skadar människor? Vem är ansvarig för AI-systemets beteende? Dessa är några av de frågor vi kommer att utforska i denna kursplan.
I denna lektion kommer du att:
- Öka din medvetenhet om vikten av rättvisa i maskininlärning och skador relaterade till orättvisa.
- Bli bekant med att utforska avvikelser och ovanliga scenarier för att säkerställa tillförlitlighet och säkerhet.
- Få förståelse för behovet av att stärka alla genom att designa inkluderande system.
- Utforska hur viktigt det är att skydda integritet och säkerhet för data och människor.
- Se vikten av att ha en "glaslåda"-metod för att förklara AI-modellers beteende.
- Vara medveten om hur ansvarstagande är avgörande för att bygga förtroende för AI-system.
Förkunskaper
Som förkunskap, vänligen ta "Principer för ansvarsfull AI" på Learn Path och titta på videon nedan om ämnet:
Lär dig mer om ansvarsfull AI genom att följa denna Learning Path

🎥 Klicka på bilden ovan för en video: Microsofts syn på ansvarsfull AI
Rättvisa
AI-system bör behandla alla rättvist och undvika att påverka liknande grupper av människor på olika sätt. Till exempel, när AI-system ger vägledning om medicinsk behandling, låneansökningar eller anställning, bör de ge samma rekommendationer till alla med liknande symptom, ekonomiska förhållanden eller yrkeskvalifikationer. Vi människor bär alla på ärvda fördomar som påverkar våra beslut och handlingar. Dessa fördomar kan också återspeglas i data som används för att träna AI-system. Sådan manipulation kan ibland ske oavsiktligt. Det är ofta svårt att medvetet veta när man introducerar fördomar i data.
"Orättvisa" omfattar negativa effekter, eller "skador", för en grupp människor, såsom de definierade utifrån ras, kön, ålder eller funktionsnedsättning. De huvudsakliga skadorna relaterade till rättvisa kan klassificeras som:
- Allokering, om exempelvis ett kön eller en etnicitet gynnas över en annan.
- Kvalitet på tjänsten. Om du tränar data för ett specifikt scenario men verkligheten är mycket mer komplex, leder det till en dåligt fungerande tjänst. Till exempel en tvålautomat som inte kunde känna av personer med mörk hud. Referens
- Nedvärdering. Att orättvist kritisera och märka något eller någon. Till exempel, en bildmärkningsteknik som ökändes för att felaktigt märka bilder av mörkhyade personer som gorillor.
- Över- eller underrepresentation. Idén att en viss grupp inte syns i ett visst yrke, och att alla tjänster eller funktioner som fortsätter att främja detta bidrar till skada.
- Stereotyper. Att associera en viss grupp med förutbestämda attribut. Till exempel kan ett språköversättningssystem mellan engelska och turkiska ha felaktigheter på grund av ord med stereotypa kopplingar till kön.
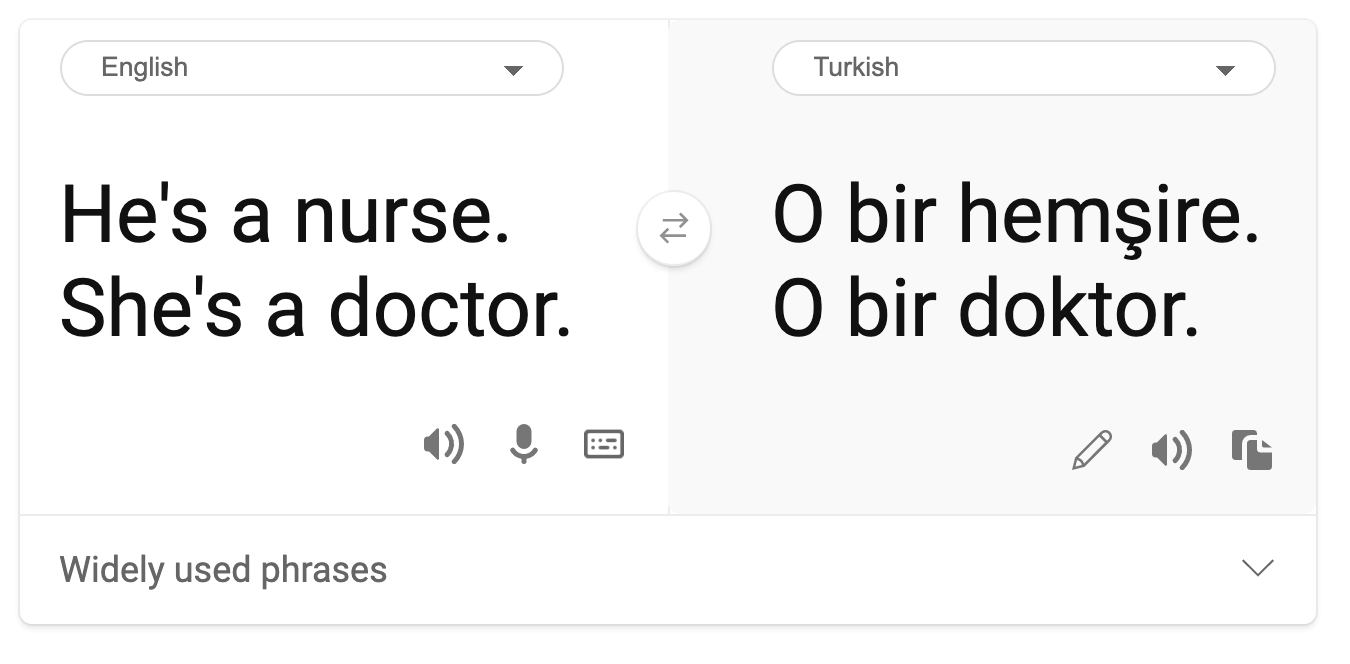
översättning till turkiska

översättning tillbaka till engelska
När vi designar och testar AI-system måste vi säkerställa att AI är rättvis och inte programmerad att fatta partiska eller diskriminerande beslut, vilket även människor är förbjudna att göra. Att garantera rättvisa i AI och maskininlärning förblir en komplex socio-teknisk utmaning.
Tillförlitlighet och säkerhet
För att bygga förtroende måste AI-system vara tillförlitliga, säkra och konsekventa under normala och oväntade förhållanden. Det är viktigt att veta hur AI-system beter sig i olika situationer, särskilt när de är avvikande. När vi bygger AI-lösningar måste vi lägga stor vikt vid hur vi hanterar en mängd olika omständigheter som AI-lösningarna kan stöta på. Till exempel måste en självkörande bil prioritera människors säkerhet. Därför måste AI som driver bilen ta hänsyn till alla möjliga scenarier som bilen kan stöta på, såsom natt, åskväder eller snöstormar, barn som springer över gatan, husdjur, vägarbeten etc. Hur väl ett AI-system kan hantera en mängd olika förhållanden på ett tillförlitligt och säkert sätt återspeglar graden av förutseende som dataforskaren eller AI-utvecklaren hade under systemets design eller testning.
Inkludering
AI-system bör designas för att engagera och stärka alla. När dataforskare och AI-utvecklare designar och implementerar AI-system identifierar och adresserar de potentiella hinder i systemet som oavsiktligt kan exkludera människor. Till exempel finns det 1 miljard människor med funktionsnedsättningar världen över. Med AI:s framsteg kan de få tillgång till en mängd information och möjligheter enklare i sina dagliga liv. Genom att adressera dessa hinder skapas möjligheter att innovera och utveckla AI-produkter med bättre upplevelser som gynnar alla.
Säkerhet och integritet
AI-system bör vara säkra och respektera människors integritet. Människor har mindre förtroende för system som äventyrar deras integritet, information eller liv. När vi tränar maskininlärningsmodeller förlitar vi oss på data för att producera de bästa resultaten. I detta arbete måste vi överväga datans ursprung och integritet. Till exempel, var datan användargenererad eller offentligt tillgänglig? Vidare, när vi arbetar med data, är det avgörande att utveckla AI-system som kan skydda konfidentiell information och motstå attacker. När AI blir allt vanligare blir det allt viktigare och mer komplext att skydda integritet och säkra viktig personlig och affärsmässig information. Integritets- och datasäkerhetsfrågor kräver särskilt noggrann uppmärksamhet för AI eftersom tillgång till data är avgörande för att AI-system ska kunna göra korrekta och informerade förutsägelser och beslut om människor.
- Som bransch har vi gjort betydande framsteg inom integritet och säkerhet, mycket tack vare regleringar som GDPR (General Data Protection Regulation).
- Med AI-system måste vi dock erkänna spänningen mellan behovet av mer personlig data för att göra systemen mer personliga och effektiva – och integritet.
- Precis som med internets födelse ser vi också en stor ökning av säkerhetsproblem relaterade till AI.
- Samtidigt har vi sett AI användas för att förbättra säkerheten. Till exempel drivs de flesta moderna antivirusprogram idag av AI-heuristik.
- Vi måste säkerställa att våra dataforskningsprocesser harmoniserar med de senaste integritets- och säkerhetspraxis.
Transparens
AI-system bör vara förståeliga. En viktig del av transparens är att förklara AI-systemens beteende och deras komponenter. Att förbättra förståelsen av AI-system kräver att intressenter förstår hur och varför de fungerar så att de kan identifiera potentiella prestandaproblem, säkerhets- och integritetsproblem, fördomar, exkluderande praxis eller oavsiktliga resultat. Vi tror också att de som använder AI-system bör vara ärliga och öppna om när, varför och hur de väljer att använda dem, samt om systemens begränsningar. Till exempel, om en bank använder ett AI-system för att stödja sina beslut om konsumentlån, är det viktigt att granska resultaten och förstå vilken data som påverkar systemets rekommendationer. Regeringar börjar reglera AI inom olika branscher, så dataforskare och organisationer måste förklara om ett AI-system uppfyller regulatoriska krav, särskilt när det finns ett oönskat resultat.
- Eftersom AI-system är så komplexa är det svårt att förstå hur de fungerar och tolka resultaten.
- Denna brist på förståelse påverkar hur dessa system hanteras, operationaliseras och dokumenteras.
- Denna brist på förståelse påverkar ännu viktigare de beslut som fattas baserat på resultaten dessa system producerar.
Ansvarstagande
De personer som designar och implementerar AI-system måste vara ansvariga för hur deras system fungerar. Behovet av ansvarstagande är särskilt viktigt med känsliga teknologier som ansiktsigenkänning. På senare tid har efterfrågan på ansiktsigenkänningsteknik ökat, särskilt från brottsbekämpande organisationer som ser potentialen i tekniken för användning som att hitta försvunna barn. Dessa teknologier kan dock potentiellt användas av en regering för att äventyra medborgarnas grundläggande friheter, exempelvis genom att möjliggöra kontinuerlig övervakning av specifika individer. Därför måste dataforskare och organisationer vara ansvariga för hur deras AI-system påverkar individer eller samhället.
🎥 Klicka på bilden ovan för en video: Varningar om massövervakning genom ansiktsigenkänning
Slutligen är en av de största frågorna för vår generation, som den första generationen som introducerar AI i samhället, hur vi säkerställer att datorer förblir ansvariga inför människor och hur vi säkerställer att de som designar datorer förblir ansvariga inför alla andra.
Konsekvensbedömning
Innan du tränar en maskininlärningsmodell är det viktigt att genomföra en konsekvensbedömning för att förstå syftet med AI-systemet; vad den avsedda användningen är; var det kommer att implementeras; och vem som kommer att interagera med systemet. Dessa är hjälpsamma för granskare eller testare som utvärderar systemet för att veta vilka faktorer som ska beaktas vid identifiering av potentiella risker och förväntade konsekvenser.
Följande är fokusområden vid genomförande av en konsekvensbedömning:
- Negativ påverkan på individer. Att vara medveten om eventuella restriktioner eller krav, otillåten användning eller kända begränsningar som hindrar systemets prestanda är avgörande för att säkerställa att systemet inte används på ett sätt som kan skada individer.
- Datakrav. Att förstå hur och var systemet kommer att använda data gör det möjligt för granskare att utforska eventuella datakrav som du måste vara medveten om (t.ex. GDPR eller HIPPA-regler). Dessutom, undersök om datakällan eller mängden data är tillräcklig för träning.
- Sammanfattning av påverkan. Samla en lista över potentiella skador som kan uppstå vid användning av systemet. Under hela ML-livscykeln, granska om de identifierade problemen har åtgärdats eller hanterats.
- Tillämpliga mål för var och en av de sex kärnprinciperna. Bedöm om målen från varje princip uppfylls och om det finns några luckor.
Felsökning med ansvarsfull AI
Precis som att felsöka en mjukvaruapplikation är felsökning av ett AI-system en nödvändig process för att identifiera och lösa problem i systemet. Det finns många faktorer som kan påverka att en modell inte presterar som förväntat eller ansvarsfullt. De flesta traditionella modellprestandamått är kvantitativa sammanställningar av en modells prestanda, vilket inte är tillräckligt för att analysera hur en modell bryter mot principerna för ansvarsfull AI. Dessutom är en maskininlärningsmodell en "svart låda" som gör det svårt att förstå vad som driver dess resultat eller att ge en förklaring när den gör ett misstag. Senare i denna kurs kommer vi att lära oss hur man använder Responsible AI-dashboarden för att hjälpa till att felsöka AI-system. Dashboarden erbjuder ett holistiskt verktyg för dataforskare och AI-utvecklare att utföra:
- Felsökningsanalys. För att identifiera felens fördelning i modellen som kan påverka systemets rättvisa eller tillförlitlighet.
- Modellöversikt. För att upptäcka var det finns skillnader i modellens prestanda över olika datakohorter.
- Dataanalys. För att förstå datadistributionen och identifiera eventuella fördomar i data som kan leda till problem med rättvisa, inkludering och tillförlitlighet.
- Modelltolkning. För att förstå vad som påverkar eller styr modellens förutsägelser. Detta hjälper till att förklara modellens beteende, vilket är viktigt för transparens och ansvarstagande.
🚀 Utmaning
För att förhindra att skador introduceras från början bör vi:
- ha en mångfald av bakgrunder och perspektiv bland de personer som arbetar med systemen
- investera i dataset som speglar mångfalden i vårt samhälle
- utveckla bättre metoder under hela maskininlärningslivscykeln för att upptäcka och korrigera ansvarsfull AI när det inträffar
Tänk på verkliga scenarier där en modells opålitlighet är uppenbar i modellbyggande och användning. Vad mer bör vi överväga?
Quiz efter föreläsningen
Granskning och självstudier
I denna lektion har du lärt dig några grunder om begreppen rättvisa och orättvisa i maskininlärning. Titta på denna workshop för att fördjupa dig i ämnena:
- I jakten på ansvarsfull AI: Att omsätta principer i praktiken av Besmira Nushi, Mehrnoosh Sameki och Amit Sharma

🎥 Klicka på bilden ovan för en video: RAI Toolbox: En öppen källkodsram för att bygga ansvarsfull AI av Besmira Nushi, Mehrnoosh Sameki och Amit Sharma
Läs också:
-
Microsofts RAI-resurscenter: Responsible AI Resources – Microsoft AI
-
Microsofts FATE-forskningsgrupp: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Läs om Azure Machine Learnings verktyg för att säkerställa rättvisa:
Uppgift
Ansvarsfriskrivning:
Detta dokument har översatts med hjälp av AI-översättningstjänsten Co-op Translator. Även om vi strävar efter noggrannhet, vänligen notera att automatiska översättningar kan innehålla fel eller felaktigheter. Det ursprungliga dokumentet på dess originalspråk bör betraktas som den auktoritativa källan. För kritisk information rekommenderas professionell mänsklig översättning. Vi ansvarar inte för eventuella missförstånd eller feltolkningar som uppstår vid användning av denna översättning.