|
|
3 weeks ago | |
|---|---|---|
| .. | ||
| solution | 3 weeks ago | |
| README.md | 3 weeks ago | |
| assignment.md | 3 weeks ago | |
| notebook.ipynb | 3 weeks ago | |
README.md
Začíname s Pythonom a Scikit-learn pre regresné modely

Sketchnote od Tomomi Imura
Kvíz pred prednáškou
Táto lekcia je dostupná aj v R!
Úvod
V týchto štyroch lekciách sa naučíte, ako vytvárať regresné modely. Čoskoro si vysvetlíme, na čo slúžia. Ale predtým, než začnete, uistite sa, že máte správne nástroje na začatie procesu!
V tejto lekcii sa naučíte:
- Ako nakonfigurovať váš počítač na lokálne úlohy strojového učenia.
- Ako pracovať s Jupyter notebookmi.
- Ako používať Scikit-learn, vrátane jeho inštalácie.
- Preskúmať lineárnu regresiu prostredníctvom praktického cvičenia.
Inštalácie a konfigurácie

🎥 Kliknite na obrázok vyššie pre krátke video o konfigurácii vášho počítača pre ML.
-
Nainštalujte Python. Uistite sa, že máte Python nainštalovaný na vašom počítači. Python budete používať na mnohé úlohy v oblasti dátovej vedy a strojového učenia. Väčšina počítačových systémov už obsahuje inštaláciu Pythonu. K dispozícii sú aj užitočné Python Coding Packs, ktoré uľahčujú nastavenie pre niektorých používateľov.
Niektoré použitia Pythonu však vyžadujú jednu verziu softvéru, zatiaľ čo iné vyžadujú inú verziu. Z tohto dôvodu je užitočné pracovať v virtuálnom prostredí.
-
Nainštalujte Visual Studio Code. Uistite sa, že máte Visual Studio Code nainštalovaný na vašom počítači. Postupujte podľa týchto pokynov na inštaláciu Visual Studio Code pre základnú inštaláciu. V tomto kurze budete používať Python vo Visual Studio Code, takže by ste si mohli osviežiť, ako konfigurovať Visual Studio Code pre vývoj v Pythone.
Získajte pohodlie s Pythonom prostredníctvom tejto kolekcie Learn modulov

🎥 Kliknite na obrázok vyššie pre video: používanie Pythonu vo VS Code.
-
Nainštalujte Scikit-learn, podľa týchto pokynov. Keďže je potrebné zabezpečiť, že používate Python 3, odporúča sa používať virtuálne prostredie. Ak inštalujete túto knižnicu na M1 Mac, na stránke vyššie sú špeciálne pokyny.
-
Nainštalujte Jupyter Notebook. Budete potrebovať nainštalovať balík Jupyter.
Vaše prostredie na tvorbu ML
Budete používať notebooky na vývoj vášho Python kódu a vytváranie modelov strojového učenia. Tento typ súboru je bežným nástrojom pre dátových vedcov a je možné ho identifikovať podľa jeho prípony .ipynb.
Notebooky sú interaktívne prostredie, ktoré umožňuje vývojárovi kódovať, pridávať poznámky a písať dokumentáciu okolo kódu, čo je veľmi užitočné pre experimentálne alebo výskumné projekty.

🎥 Kliknite na obrázok vyššie pre krátke video o tomto cvičení.
Cvičenie - práca s notebookom
V tejto zložke nájdete súbor notebook.ipynb.
-
Otvorte notebook.ipynb vo Visual Studio Code.
Spustí sa Jupyter server s Pythonom 3+. Nájdete oblasti notebooku, ktoré je možné
spustiť, kúsky kódu. Môžete spustiť blok kódu výberom ikony, ktorá vyzerá ako tlačidlo prehrávania. -
Vyberte ikonu
mda pridajte trochu markdownu, a nasledujúci text # Vitajte vo vašom notebooku.Potom pridajte nejaký Python kód.
-
Napíšte print('hello notebook') do bloku kódu.
-
Vyberte šípku na spustenie kódu.
Mali by ste vidieť vytlačené vyhlásenie:
hello notebook

Môžete prekladať váš kód s komentármi na samo-dokumentovanie notebooku.
✅ Zamyslite sa na chvíľu nad tým, aké odlišné je pracovné prostredie webového vývojára oproti dátovému vedcovi.
Práca so Scikit-learn
Teraz, keď je Python nastavený vo vašom lokálnom prostredí a ste pohodlní s Jupyter notebookmi, poďme sa rovnako oboznámiť so Scikit-learn (vyslovujte sci ako v science). Scikit-learn poskytuje rozsiahle API, ktoré vám pomôže vykonávať úlohy strojového učenia.
Podľa ich webovej stránky, "Scikit-learn je open source knižnica strojového učenia, ktorá podporuje učenie pod dohľadom a bez dohľadu. Poskytuje tiež rôzne nástroje na prispôsobenie modelov, predspracovanie dát, výber modelov a hodnotenie, a mnoho ďalších užitočných funkcií."
V tomto kurze budete používať Scikit-learn a ďalšie nástroje na vytváranie modelov strojového učenia na vykonávanie toho, čo nazývame 'tradičné úlohy strojového učenia'. Úmyselne sme sa vyhli neurónovým sieťam a hlbokému učeniu, pretože sú lepšie pokryté v našom pripravovanom kurikule 'AI pre začiatočníkov'.
Scikit-learn umožňuje jednoduché vytváranie modelov a ich hodnotenie na použitie. Primárne sa zameriava na používanie numerických dát a obsahuje niekoľko pripravených datasetov na použitie ako učebné nástroje. Obsahuje tiež predpripravené modely, ktoré si študenti môžu vyskúšať. Poďme preskúmať proces načítania predpripravených dát a použitia zabudovaného odhadovača na prvý ML model so Scikit-learn s niektorými základnými dátami.
Cvičenie - váš prvý notebook so Scikit-learn
Tento tutoriál bol inšpirovaný príkladom lineárnej regresie na webovej stránke Scikit-learn.

🎥 Kliknite na obrázok vyššie pre krátke video o tomto cvičení.
V súbore notebook.ipynb priradenom k tejto lekcii vymažte všetky bunky stlačením ikony 'odpadkového koša'.
V tejto sekcii budete pracovať s malým datasetom o cukrovke, ktorý je zabudovaný do Scikit-learn na učebné účely. Predstavte si, že chcete testovať liečbu pre diabetických pacientov. Modely strojového učenia vám môžu pomôcť určiť, ktorí pacienti by na liečbu reagovali lepšie, na základe kombinácií premenných. Dokonca aj veľmi základný regresný model, keď je vizualizovaný, môže ukázať informácie o premenných, ktoré by vám pomohli organizovať vaše teoretické klinické skúšky.
✅ Existuje mnoho typov regresných metód a výber závisí od odpovede, ktorú hľadáte. Ak chcete predpovedať pravdepodobnú výšku osoby určitého veku, použili by ste lineárnu regresiu, pretože hľadáte numerickú hodnotu. Ak vás zaujíma, či by sa určitý typ kuchyne mal považovať za vegánsky alebo nie, hľadáte kategóriu, takže by ste použili logistickú regresiu. Neskôr sa dozviete viac o logistickej regresii. Zamyslite sa nad niektorými otázkami, ktoré môžete klásť dátam, a ktorá z týchto metód by bola vhodnejšia.
Poďme začať s touto úlohou.
Import knižníc
Pre túto úlohu importujeme niektoré knižnice:
- matplotlib. Je to užitočný nástroj na grafy a použijeme ho na vytvorenie čiarového grafu.
- numpy. numpy je užitočná knižnica na prácu s numerickými dátami v Pythone.
- sklearn. Toto je knižnica Scikit-learn.
Importujte niektoré knižnice na pomoc s vašimi úlohami.
-
Pridajte importy napísaním nasledujúceho kódu:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionVyššie importujete
matplotlib,numpya importujetedatasets,linear_modelamodel_selectionzosklearn.model_selectionsa používa na rozdelenie dát na tréningové a testovacie sady.
Dataset o cukrovke
Zabudovaný dataset o cukrovke obsahuje 442 vzoriek dát o cukrovke s 10 premennými, z ktorých niektoré zahŕňajú:
- vek: vek v rokoch
- bmi: index telesnej hmotnosti
- bp: priemerný krvný tlak
- s1 tc: T-bunky (typ bielych krviniek)
✅ Tento dataset zahŕňa koncept 'pohlavia' ako premennú dôležitú pre výskum cukrovky. Mnohé medicínske datasety zahŕňajú tento typ binárnej klasifikácie. Zamyslite sa nad tým, ako takéto kategorizácie môžu vylúčiť určité časti populácie z liečby.
Teraz načítajte dáta X a y.
🎓 Pamätajte, že ide o učenie pod dohľadom, a potrebujeme pomenovaný cieľ 'y'.
V novej bunke kódu načítajte dataset o cukrovke volaním load_diabetes(). Vstup return_X_y=True signalizuje, že X bude dátová matica a y bude cieľ regresie.
-
Pridajte niekoľko príkazov na výpis, aby ste zobrazili tvar dátovej matice a jej prvý prvok:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])To, čo dostávate ako odpoveď, je tuple. Priraďujete prvé dve hodnoty tuple do
Xay. Viac sa dozviete o tuple.Môžete vidieť, že tieto dáta majú 442 položiek usporiadaných v poliach s 10 prvkami:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Zamyslite sa nad vzťahom medzi dátami a cieľovou premennou regresie. Lineárna regresia predpovedá vzťahy medzi premennou X a cieľovou premennou y. Nájdete cieľ pre dataset o cukrovke v dokumentácii? Čo tento dataset demonštruje, vzhľadom na cieľ?
-
Ďalej vyberte časť tohto datasetu na vykreslenie výberom 3. stĺpca datasetu. Môžete to urobiť pomocou operátora
:na výber všetkých riadkov a potom výberom 3. stĺpca pomocou indexu (2). Dáta môžete tiež preformátovať na 2D pole - ako je požadované na vykreslenie - pomocoureshape(n_rows, n_columns). Ak je jeden z parametrov -1, zodpovedajúci rozmer sa vypočíta automaticky.X = X[:, 2] X = X.reshape((-1,1))✅ Kedykoľvek si vypíšte dáta, aby ste skontrolovali ich tvar.
-
Teraz, keď máte dáta pripravené na vykreslenie, môžete zistiť, či stroj môže pomôcť určiť logické rozdelenie medzi číslami v tomto datasete. Na to potrebujete rozdeliť dáta (X) a cieľ (y) na testovacie a tréningové sady. Scikit-learn má jednoduchý spôsob, ako to urobiť; môžete rozdeliť vaše testovacie dáta na danom bode.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Teraz ste pripravení trénovať váš model! Načítajte model lineárnej regresie a trénujte ho s vašimi tréningovými sadami X a y pomocou
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()je funkcia, ktorú uvidíte v mnohých knižniciach ML, ako je TensorFlow. -
Potom vytvorte predpoveď pomocou testovacích dát, pomocou funkcie
predict(). Táto funkcia bude použitá na nakreslenie čiary medzi skupinami dát.y_pred = model.predict(X_test) -
Teraz je čas zobraziť dáta v grafe. Matplotlib je veľmi užitočný nástroj na túto úlohu. Vytvorte scatterplot všetkých testovacích dát X a y a použite predpoveď na nakreslenie čiary na najvhodnejšom mieste medzi skupinami dát modelu.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()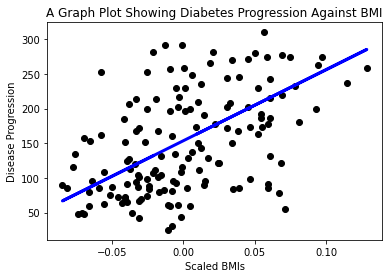 ✅ Zamyslite sa nad tým, čo sa tu deje. Priama čiara prechádza cez množstvo malých bodov údajov, ale čo presne robí? Vidíte, ako by ste mali byť schopní použiť túto čiaru na predpovedanie, kde by mal nový, nevidený bod údajov zapadnúť vo vzťahu k osi y grafu? Skúste slovami vyjadriť praktické využitie tohto modelu.
✅ Zamyslite sa nad tým, čo sa tu deje. Priama čiara prechádza cez množstvo malých bodov údajov, ale čo presne robí? Vidíte, ako by ste mali byť schopní použiť túto čiaru na predpovedanie, kde by mal nový, nevidený bod údajov zapadnúť vo vzťahu k osi y grafu? Skúste slovami vyjadriť praktické využitie tohto modelu.
Gratulujeme, vytvorili ste svoj prvý model lineárnej regresie, urobili ste predpoveď pomocou neho a zobrazili ste ju v grafe!
🚀Výzva
Vykreslite iný premennú z tejto dátovej sady. Tip: upravte tento riadok: X = X[:,2]. Na základe cieľa tejto dátovej sady, čo dokážete zistiť o progresii cukrovky ako ochorenia?
Kvíz po prednáške
Prehľad a samostatné štúdium
V tomto tutoriáli ste pracovali s jednoduchou lineárnou regresiou, namiesto univariátnej alebo viacnásobnej lineárnej regresie. Prečítajte si niečo o rozdieloch medzi týmito metódami alebo si pozrite toto video.
Prečítajte si viac o koncepte regresie a zamyslite sa nad tým, aké typy otázok je možné zodpovedať pomocou tejto techniky. Absolvujte tento tutoriál, aby ste si prehĺbili svoje porozumenie.
Zadanie
Upozornenie:
Tento dokument bol preložený pomocou služby AI prekladu Co-op Translator. Aj keď sa snažíme o presnosť, prosím, berte na vedomie, že automatizované preklady môžu obsahovať chyby alebo nepresnosti. Pôvodný dokument v jeho pôvodnom jazyku by mal byť považovaný za autoritatívny zdroj. Pre kritické informácie sa odporúča profesionálny ľudský preklad. Nie sme zodpovední za akékoľvek nedorozumenia alebo nesprávne interpretácie vyplývajúce z použitia tohto prekladu.