17 KiB
Începeți cu Python și Scikit-learn pentru modele de regresie

Sketchnote de Tomomi Imura
Chestionar înainte de lecție
Această lecție este disponibilă și în R!
Introducere
În aceste patru lecții, veți descoperi cum să construiți modele de regresie. Vom discuta în curând la ce sunt utile acestea. Dar înainte de a începe, asigurați-vă că aveți instrumentele potrivite pentru a începe procesul!
În această lecție, veți învăța cum să:
- Configurați computerul pentru sarcini locale de învățare automată.
- Lucrați cu Jupyter notebooks.
- Utilizați Scikit-learn, inclusiv instalarea acestuia.
- Explorați regresia liniară printr-un exercițiu practic.
Instalări și configurări

🎥 Faceți clic pe imaginea de mai sus pentru un scurt videoclip despre configurarea computerului pentru ML.
-
Instalați Python. Asigurați-vă că Python este instalat pe computerul dvs. Veți utiliza Python pentru multe sarcini de știința datelor și învățare automată. Majoritatea sistemelor de operare includ deja o instalare Python. Există și Pachete de codare Python utile, pentru a ușura configurarea pentru unii utilizatori.
Totuși, unele utilizări ale Python necesită o anumită versiune a software-ului, în timp ce altele necesită o versiune diferită. Din acest motiv, este util să lucrați într-un mediu virtual.
-
Instalați Visual Studio Code. Asigurați-vă că Visual Studio Code este instalat pe computerul dvs. Urmați aceste instrucțiuni pentru a instala Visual Studio Code pentru o instalare de bază. Veți utiliza Python în Visual Studio Code în acest curs, așa că poate doriți să vă familiarizați cu modul de configurare a Visual Studio Code pentru dezvoltarea în Python.
Familiarizați-vă cu Python parcurgând această colecție de module de învățare

🎥 Faceți clic pe imaginea de mai sus pentru un videoclip: utilizarea Python în VS Code.
-
Instalați Scikit-learn, urmând aceste instrucțiuni. Deoarece trebuie să vă asigurați că utilizați Python 3, este recomandat să utilizați un mediu virtual. Notă: dacă instalați această bibliotecă pe un Mac cu M1, există instrucțiuni speciale pe pagina menționată mai sus.
-
Instalați Jupyter Notebook. Va trebui să instalați pachetul Jupyter.
Mediul dvs. de lucru pentru ML
Veți utiliza notebooks pentru a dezvolta codul Python și a crea modele de învățare automată. Acest tip de fișier este un instrument comun pentru oamenii de știință în domeniul datelor și poate fi identificat prin sufixul sau extensia .ipynb.
Notebooks oferă un mediu interactiv care permite dezvoltatorului să scrie cod și să adauge note și documentație în jurul codului, ceea ce este foarte util pentru proiecte experimentale sau orientate spre cercetare.

🎥 Faceți clic pe imaginea de mai sus pentru un scurt videoclip despre acest exercițiu.
Exercițiu - lucrați cu un notebook
În acest folder, veți găsi fișierul notebook.ipynb.
-
Deschideți notebook.ipynb în Visual Studio Code.
Un server Jupyter va porni cu Python 3+ activat. Veți găsi zone ale notebook-ului care pot fi
rulate, adică bucăți de cod. Puteți rula un bloc de cod selectând pictograma care arată ca un buton de redare. -
Selectați pictograma
mdși adăugați puțin markdown, precum și următorul text # Bine ați venit în notebook-ul dvs..Apoi, adăugați ceva cod Python.
-
Scrieți print('hello notebook') în blocul de cod.
-
Selectați săgeata pentru a rula codul.
Ar trebui să vedeți declarația afișată:
hello notebook

Puteți intercala codul cu comentarii pentru a documenta notebook-ul.
✅ Gândiți-vă un minut la cât de diferit este mediul de lucru al unui dezvoltator web față de cel al unui om de știință în domeniul datelor.
Începeți cu Scikit-learn
Acum că Python este configurat în mediul dvs. local și sunteți confortabil cu Jupyter notebooks, să devenim la fel de confortabili cu Scikit-learn (se pronunță sci ca în science). Scikit-learn oferă o API extinsă pentru a vă ajuta să efectuați sarcini de ML.
Conform site-ului lor, "Scikit-learn este o bibliotecă open source pentru învățare automată care suportă învățarea supravegheată și nesupravegheată. De asemenea, oferă diverse instrumente pentru ajustarea modelelor, preprocesarea datelor, selecția și evaluarea modelelor, precum și multe alte utilități."
În acest curs, veți utiliza Scikit-learn și alte instrumente pentru a construi modele de învățare automată pentru a efectua ceea ce numim sarcini de 'învățare automată tradițională'. Am evitat în mod deliberat rețelele neuronale și învățarea profundă, deoarece acestea sunt mai bine acoperite în viitorul nostru curriculum 'AI pentru Începători'.
Scikit-learn face ușor să construiți modele și să le evaluați pentru utilizare. Este axat în principal pe utilizarea datelor numerice și conține mai multe seturi de date gata făcute pentru utilizare ca instrumente de învățare. De asemenea, include modele pre-construite pentru studenți. Să explorăm procesul de încărcare a datelor preambalate și utilizarea unui estimator pentru primul model ML cu Scikit-learn, folosind câteva date de bază.
Exercițiu - primul dvs. notebook Scikit-learn
Acest tutorial a fost inspirat de exemplul de regresie liniară de pe site-ul Scikit-learn.

🎥 Faceți clic pe imaginea de mai sus pentru un scurt videoclip despre acest exercițiu.
În fișierul notebook.ipynb asociat acestei lecții, ștergeți toate celulele apăsând pe pictograma 'coș de gunoi'.
În această secțiune, veți lucra cu un set mic de date despre diabet, care este inclus în Scikit-learn pentru scopuri de învățare. Imaginați-vă că doriți să testați un tratament pentru pacienții diabetici. Modelele de învățare automată ar putea să vă ajute să determinați care pacienți ar răspunde mai bine la tratament, pe baza combinațiilor de variabile. Chiar și un model de regresie foarte simplu, atunci când este vizualizat, ar putea arăta informații despre variabilele care v-ar ajuta să organizați studiile clinice teoretice.
✅ Există multe tipuri de metode de regresie, iar alegerea uneia depinde de răspunsul pe care îl căutați. Dacă doriți să preziceți înălțimea probabilă a unei persoane de o anumită vârstă, ați utiliza regresia liniară, deoarece căutați o valoare numerică. Dacă sunteți interesat să descoperiți dacă un tip de bucătărie ar trebui considerat vegan sau nu, căutați o încadrare în categorie, așa că ați utiliza regresia logistică. Veți învăța mai multe despre regresia logistică mai târziu. Gândiți-vă puțin la întrebările pe care le puteți pune datelor și care dintre aceste metode ar fi mai potrivită.
Să începem această sarcină.
Importați biblioteci
Pentru această sarcină, vom importa câteva biblioteci:
- matplotlib. Este un instrument util pentru graficare și îl vom folosi pentru a crea un grafic liniar.
- numpy. numpy este o bibliotecă utilă pentru manipularea datelor numerice în Python.
- sklearn. Aceasta este biblioteca Scikit-learn.
Importați câteva biblioteci pentru a vă ajuta cu sarcinile.
-
Adăugați importurile tastând următorul cod:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionMai sus importați
matplotlib,numpyși importațidatasets,linear_modelșimodel_selectiondinsklearn.model_selectioneste utilizat pentru a împărți datele în seturi de antrenament și testare.
Setul de date despre diabet
Setul de date diabet inclus conține 442 de mostre de date despre diabet, cu 10 variabile caracteristice, dintre care unele includ:
- age: vârsta în ani
- bmi: indicele de masă corporală
- bp: tensiunea arterială medie
- s1 tc: T-Cells (un tip de globule albe)
✅ Acest set de date include conceptul de 'sex' ca variabilă caracteristică importantă pentru cercetarea despre diabet. Multe seturi de date medicale includ acest tip de clasificare binară. Gândiți-vă puțin la modul în care astfel de clasificări ar putea exclude anumite părți ale populației de la tratamente.
Acum, încărcați datele X și y.
🎓 Amintiți-vă, aceasta este învățare supravegheată, iar noi avem nevoie de o țintă 'y' denumită.
Într-o nouă celulă de cod, încărcați setul de date despre diabet apelând load_diabetes(). Parametrul return_X_y=True semnalează că X va fi o matrice de date, iar y va fi ținta regresiei.
-
Adăugați câteva comenzi print pentru a afișa forma matricei de date și primul său element:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Ceea ce primiți ca răspuns este un tuplu. Ceea ce faceți este să atribuiți cele două prime valori ale tuplului lui
Xșiy, respectiv. Aflați mai multe despre tupluri.Puteți vedea că aceste date au 442 de elemente organizate în matrici de 10 elemente:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Gândiți-vă puțin la relația dintre date și ținta regresiei. Regresia liniară prezice relațiile dintre caracteristica X și variabila țintă y. Puteți găsi ținta pentru setul de date despre diabet în documentație? Ce demonstrează acest set de date, având în vedere ținta?
-
Apoi, selectați o parte din acest set de date pentru a o reprezenta grafic, selectând a treia coloană a setului de date. Puteți face acest lucru utilizând operatorul
:pentru a selecta toate rândurile, apoi selectând a treia coloană utilizând indexul (2). De asemenea, puteți rearanja datele pentru a fi o matrice 2D - așa cum este necesar pentru reprezentarea grafică - utilizândreshape(n_rows, n_columns). Dacă unul dintre parametri este -1, dimensiunea corespunzătoare este calculată automat.X = X[:, 2] X = X.reshape((-1,1))✅ În orice moment, afișați datele pentru a verifica forma lor.
-
Acum că aveți datele pregătite pentru a fi reprezentate grafic, puteți vedea dacă o mașină poate determina o separare logică între numerele din acest set de date. Pentru a face acest lucru, trebuie să împărțiți atât datele (X), cât și ținta (y) în seturi de testare și antrenament. Scikit-learn are o metodă simplă pentru aceasta; puteți împărți datele de testare la un anumit punct.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Acum sunteți gata să antrenați modelul! Încărcați modelul de regresie liniară și antrenați-l cu seturile de antrenament X și y utilizând
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()este o funcție pe care o veți întâlni în multe biblioteci ML, cum ar fi TensorFlow. -
Apoi, creați o predicție utilizând datele de testare, folosind funcția
predict(). Aceasta va fi utilizată pentru a trasa linia între grupurile de date.y_pred = model.predict(X_test) -
Acum este momentul să afișați datele într-un grafic. Matplotlib este un instrument foarte util pentru această sarcină. Creați un grafic scatter cu toate datele de testare X și y și utilizați predicția pentru a trasa o linie în locul cel mai potrivit, între grupările de date ale modelului.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()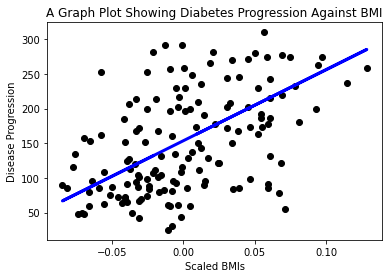 ✅ Gândește-te puțin la ce se întâmplă aici. O linie dreaptă trece prin multe puncte mici de date, dar ce face exact? Poți vedea cum ar trebui să poți folosi această linie pentru a prezice unde ar trebui să se încadreze un punct de date nou, nevăzut, în raport cu axa y a graficului? Încearcă să exprimi în cuvinte utilitatea practică a acestui model.
✅ Gândește-te puțin la ce se întâmplă aici. O linie dreaptă trece prin multe puncte mici de date, dar ce face exact? Poți vedea cum ar trebui să poți folosi această linie pentru a prezice unde ar trebui să se încadreze un punct de date nou, nevăzut, în raport cu axa y a graficului? Încearcă să exprimi în cuvinte utilitatea practică a acestui model.
Felicitări, ai construit primul tău model de regresie liniară, ai creat o predicție cu el și ai afișat-o într-un grafic!
🚀Provocare
Reprezintă grafic o variabilă diferită din acest set de date. Sugestie: editează această linie: X = X[:,2]. Având în vedere ținta acestui set de date, ce poți descoperi despre progresia diabetului ca boală?
Test de verificare după lecție
Recapitulare & Studiu individual
În acest tutorial, ai lucrat cu regresia liniară simplă, mai degrabă decât cu regresia univariată sau regresia multiplă. Citește puțin despre diferențele dintre aceste metode sau aruncă o privire la acest videoclip.
Citește mai multe despre conceptul de regresie și gândește-te la ce tipuri de întrebări pot fi răspunse prin această tehnică. Urmează acest tutorial pentru a-ți aprofunda înțelegerea.
Temă
Declinare de responsabilitate:
Acest document a fost tradus folosind serviciul de traducere AI Co-op Translator. Deși ne străduim să asigurăm acuratețea, vă rugăm să fiți conștienți că traducerile automate pot conține erori sau inexactități. Documentul original în limba sa natală ar trebui considerat sursa autoritară. Pentru informații critice, se recomandă traducerea profesională realizată de un specialist uman. Nu ne asumăm responsabilitatea pentru eventualele neînțelegeri sau interpretări greșite care pot apărea din utilizarea acestei traduceri.