|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| README.md | 2 weeks ago | |
| assignment.md | 3 weeks ago | |
README.md
Postscript: Debugowanie modeli w uczeniu maszynowym za pomocą komponentów pulpitu odpowiedzialnej AI
Quiz przed wykładem
Wprowadzenie
Uczenie maszynowe wpływa na nasze codzienne życie. Sztuczna inteligencja (AI) znajduje zastosowanie w jednych z najważniejszych systemów, które mają wpływ na nas jako jednostki i społeczeństwo, takich jak opieka zdrowotna, finanse, edukacja czy zatrudnienie. Na przykład systemy i modele są zaangażowane w codzienne procesy decyzyjne, takie jak diagnozy medyczne czy wykrywanie oszustw. W związku z tym postępy w AI oraz jej przyspieszone wdrażanie spotykają się z rosnącymi oczekiwaniami społecznymi i regulacjami. Wciąż obserwujemy obszary, w których systemy AI nie spełniają oczekiwań, ujawniają nowe wyzwania, a rządy zaczynają regulować rozwiązania AI. Dlatego ważne jest, aby analizować te modele, aby zapewnić sprawiedliwe, wiarygodne, inkluzywne, przejrzyste i odpowiedzialne wyniki dla wszystkich.
W tym kursie przyjrzymy się praktycznym narzędziom, które można wykorzystać do oceny, czy model ma problemy związane z odpowiedzialną AI. Tradycyjne techniki debugowania uczenia maszynowego opierają się głównie na obliczeniach ilościowych, takich jak zagregowana dokładność czy średnia strata błędu. Wyobraź sobie, co może się stać, gdy dane, których używasz do budowy tych modeli, nie uwzględniają pewnych grup demograficznych, takich jak rasa, płeć, poglądy polityczne, religia, lub gdy są one nadmiernie reprezentowane. Co w sytuacji, gdy wyniki modelu są interpretowane w sposób faworyzujący pewne grupy demograficzne? Może to prowadzić do nadmiernej lub niedostatecznej reprezentacji tych wrażliwych grup cech, co skutkuje problemami z uczciwością, inkluzywnością lub wiarygodnością modelu. Kolejnym wyzwaniem jest to, że modele uczenia maszynowego są często traktowane jako "czarne skrzynki", co utrudnia zrozumienie i wyjaśnienie, co napędza ich przewidywania. Wszystkie te kwestie stanowią wyzwania dla naukowców zajmujących się danymi i twórców AI, którzy nie mają odpowiednich narzędzi do debugowania i oceny uczciwości czy wiarygodności modelu.
W tej lekcji dowiesz się, jak debugować swoje modele, korzystając z:
- Analizy błędów: identyfikowanie obszarów w rozkładzie danych, w których model ma wysokie wskaźniki błędów.
- Przeglądu modelu: przeprowadzanie analizy porównawczej w różnych kohortach danych w celu wykrycia rozbieżności w metrykach wydajności modelu.
- Analizy danych: badanie, gdzie może występować nadmierna lub niedostateczna reprezentacja danych, która może wpływać na faworyzowanie jednej grupy demograficznej kosztem innej.
- Ważności cech: zrozumienie, które cechy napędzają przewidywania modelu na poziomie globalnym lub lokalnym.
Wymagania wstępne
Jako wstęp, zapoznaj się z narzędziami odpowiedzialnej AI dla programistów.

Analiza błędów
Tradycyjne metryki wydajności modeli używane do pomiaru dokładności to głównie obliczenia oparte na poprawnych i niepoprawnych przewidywaniach. Na przykład stwierdzenie, że model jest dokładny w 89% przypadków przy stracie błędu wynoszącej 0,001, może być uznane za dobrą wydajność. Jednak błędy często nie są równomiernie rozłożone w podstawowym zbiorze danych. Możesz uzyskać wynik dokładności modelu na poziomie 89%, ale odkryć, że w niektórych obszarach danych model zawodzi w 42% przypadków. Konsekwencje takich wzorców błędów w określonych grupach danych mogą prowadzić do problemów z uczciwością lub wiarygodnością. Ważne jest, aby zrozumieć, w jakich obszarach model działa dobrze, a w jakich nie. Obszary danych, w których występuje wysoka liczba nieścisłości, mogą okazać się istotnymi grupami demograficznymi.

Komponent Analizy Błędów na pulpicie RAI ilustruje, jak rozkładają się błędy modelu w różnych kohortach za pomocą wizualizacji drzewa. Jest to przydatne w identyfikowaniu cech lub obszarów, w których wskaźnik błędów w zbiorze danych jest wysoki. Dzięki temu, że widzisz, skąd pochodzą największe nieścisłości modelu, możesz zacząć badać ich przyczyny. Możesz również tworzyć kohorty danych do analizy. Te kohorty danych pomagają w procesie debugowania, aby określić, dlaczego wydajność modelu jest dobra w jednej kohorcie, a błędna w innej.

Wskaźniki wizualne na mapie drzewa pomagają szybciej zlokalizować problematyczne obszary. Na przykład im ciemniejszy odcień czerwieni ma węzeł drzewa, tym wyższy wskaźnik błędów.
Mapa cieplna to kolejna funkcjonalność wizualizacji, którą użytkownicy mogą wykorzystać do badania wskaźnika błędów przy użyciu jednej lub dwóch cech, aby znaleźć przyczynę błędów modelu w całym zbiorze danych lub kohortach.

Używaj analizy błędów, gdy potrzebujesz:
- Dogłębnie zrozumieć, jak rozkładają się błędy modelu w zbiorze danych oraz w różnych wymiarach wejściowych i cech.
- Rozłożyć zagregowane metryki wydajności, aby automatycznie odkryć błędne kohorty i zaplanować ukierunkowane kroki naprawcze.
Przegląd modelu
Ocena wydajności modelu uczenia maszynowego wymaga holistycznego zrozumienia jego zachowania. Można to osiągnąć, analizując więcej niż jedną metrykę, taką jak wskaźnik błędów, dokładność, czułość, precyzja czy MAE (średni błąd bezwzględny), aby znaleźć rozbieżności między metrykami wydajności. Jedna metryka wydajności może wyglądać świetnie, ale niedokładności mogą ujawnić się w innej metryce. Ponadto porównanie metryk pod kątem rozbieżności w całym zbiorze danych lub kohortach pomaga rzucić światło na to, gdzie model działa dobrze, a gdzie nie. Jest to szczególnie ważne w analizie wydajności modelu wśród cech wrażliwych i niewrażliwych (np. rasa pacjenta, płeć czy wiek), aby odkryć potencjalną niesprawiedliwość modelu. Na przykład odkrycie, że model jest bardziej błędny w kohorcie zawierającej cechy wrażliwe, może ujawnić potencjalną niesprawiedliwość modelu.
Komponent Przeglądu Modelu na pulpicie RAI pomaga nie tylko w analizie metryk wydajności reprezentacji danych w kohorcie, ale także daje użytkownikom możliwość porównania zachowania modelu w różnych kohortach.

Funkcjonalność analizy opartej na cechach w tym komponencie pozwala użytkownikom zawęzić podgrupy danych w ramach konkretnej cechy, aby zidentyfikować anomalie na poziomie szczegółowym. Na przykład pulpit ma wbudowaną inteligencję, która automatycznie generuje kohorty dla wybranej przez użytkownika cechy (np. "time_in_hospital < 3" lub "time_in_hospital >= 7"). Umożliwia to użytkownikowi izolowanie konkretnej cechy z większej grupy danych, aby sprawdzić, czy jest ona kluczowym czynnikiem wpływającym na błędne wyniki modelu.

Komponent Przeglądu Modelu obsługuje dwie klasy metryk rozbieżności:
Rozbieżność w wydajności modelu: Te zestawy metryk obliczają różnicę w wartościach wybranej metryki wydajności w różnych podgrupach danych. Oto kilka przykładów:
- Rozbieżność w wskaźniku dokładności
- Rozbieżność w wskaźniku błędów
- Rozbieżność w precyzji
- Rozbieżność w czułości
- Rozbieżność w średnim błędzie bezwzględnym (MAE)
Rozbieżność w wskaźniku selekcji: Ta metryka zawiera różnicę w wskaźniku selekcji (korzystne przewidywanie) w różnych podgrupach. Przykładem może być rozbieżność w wskaźnikach zatwierdzania kredytów. Wskaźnik selekcji oznacza odsetek punktów danych w każdej klasie sklasyfikowanych jako 1 (w klasyfikacji binarnej) lub rozkład wartości przewidywań (w regresji).
Analiza danych
"Jeśli wystarczająco długo torturujesz dane, przyznają się do wszystkiego" - Ronald Coase
To stwierdzenie brzmi ekstremalnie, ale prawdą jest, że dane można manipulować, aby wspierały dowolny wniosek. Taka manipulacja może czasem zdarzyć się nieumyślnie. Jako ludzie wszyscy mamy uprzedzenia i często trudno jest świadomie zauważyć, kiedy wprowadzamy uprzedzenia do danych. Zapewnienie uczciwości w AI i uczeniu maszynowym pozostaje złożonym wyzwaniem.
Dane są ogromnym punktem ślepym dla tradycyjnych metryk wydajności modeli. Możesz mieć wysokie wskaźniki dokładności, ale nie zawsze odzwierciedlają one ukryte uprzedzenia w danych. Na przykład, jeśli zbiór danych pracowników zawiera 27% kobiet na stanowiskach kierowniczych w firmie i 73% mężczyzn na tym samym poziomie, model AI do ogłaszania ofert pracy przeszkolony na tych danych może kierować swoje ogłoszenia głównie do mężczyzn na stanowiska wyższego szczebla. Taka nierównowaga w danych wpłynęła na przewidywania modelu, faworyzując jedną płeć. To ujawnia problem z uczciwością, gdzie model AI wykazuje uprzedzenia płciowe.
Komponent Analizy Danych na pulpicie RAI pomaga zidentyfikować obszary, w których występuje nadmierna lub niedostateczna reprezentacja w zbiorze danych. Pomaga użytkownikom diagnozować przyczyny błędów i problemów z uczciwością wynikających z nierównowagi danych lub braku reprezentacji określonej grupy danych. Daje użytkownikom możliwość wizualizacji zbiorów danych na podstawie przewidywanych i rzeczywistych wyników, grup błędów i konkretnych cech. Czasami odkrycie niedostatecznie reprezentowanej grupy danych może również ujawnić, że model nie uczy się dobrze, co skutkuje wysokimi niedokładnościami. Model, który ma uprzedzenia w danych, nie tylko ma problem z uczciwością, ale także pokazuje, że nie jest inkluzywny ani wiarygodny.

Używaj analizy danych, gdy potrzebujesz:
- Eksplorować statystyki swojego zbioru danych, wybierając różne filtry, aby podzielić dane na różne wymiary (znane również jako kohorty).
- Zrozumieć rozkład swojego zbioru danych w różnych kohortach i grupach cech.
- Określić, czy Twoje ustalenia dotyczące uczciwości, analizy błędów i przyczynowości (pochodzące z innych komponentów pulpitu) wynikają z rozkładu Twojego zbioru danych.
- Zdecydować, w których obszarach należy zebrać więcej danych, aby zminimalizować błędy wynikające z problemów z reprezentacją, szumem etykiet, szumem cech, uprzedzeniami etykiet i podobnymi czynnikami.
Interpretowalność modelu
Modele uczenia maszynowego często są traktowane jako "czarne skrzynki". Zrozumienie, które kluczowe cechy danych napędzają przewidywania modelu, może być wyzwaniem. Ważne jest, aby zapewnić przejrzystość, dlaczego model dokonuje określonego przewidywania. Na przykład, jeśli system AI przewiduje, że pacjent z cukrzycą jest zagrożony ponownym przyjęciem do szpitala w ciągu mniej niż 30 dni, powinien być w stanie dostarczyć dane wspierające, które doprowadziły do tego przewidywania. Posiadanie takich wskaźników danych wprowadza przejrzystość, która pomaga klinikom lub szpitalom podejmować świadome decyzje. Ponadto możliwość wyjaśnienia, dlaczego model dokonał przewidywania dla konkretnego pacjenta, umożliwia zgodność z regulacjami zdrowotnymi. Kiedy używasz modeli uczenia maszynowego w sposób wpływający na życie ludzi, kluczowe jest zrozumienie i wyjaśnienie, co wpływa na zachowanie modelu. Interpretowalność i wyjaśnialność modelu pomagają odpowiedzieć na pytania w takich scenariuszach jak:
- Debugowanie modelu: Dlaczego mój model popełnił ten błąd? Jak mogę go poprawić?
- Współpraca człowiek-AI: Jak mogę zrozumieć i zaufać decyzjom modelu?
- Zgodność z regulacjami: Czy mój model spełnia wymagania prawne?
Komponent Ważności Cech na pulpicie RAI pomaga debugować i uzyskać kompleksowe zrozumienie, jak model dokonuje przewidywań. Jest to również przydatne narzędzie dla specjalistów od uczenia maszynowego i decydentów, aby wyjaśniać i przedstawiać dowody na cechy wpływające na zachowanie modelu w celu zgodności z regulacjami. Użytkownicy mogą następnie eksplorować zarówno globalne, jak i lokalne wyjaśnienia, aby zweryfikować, które cechy napędzają przewidywania modelu. Globalne wyjaśnienia wymieniają najważniejsze cechy, które wpłynęły na ogólne przewidywania modelu. Lokalne wyjaśnienia pokazują, które cechy doprowadziły do przewidywania modelu w indywidualnym przypadku. Możliwość oceny lokalnych wyjaśnień jest również pomocna w debugowaniu lub audycie konkretnego przypadku, aby lepiej zrozumieć i zinterpretować, dlaczego model dokonał poprawnego lub błędnego przewidywania.
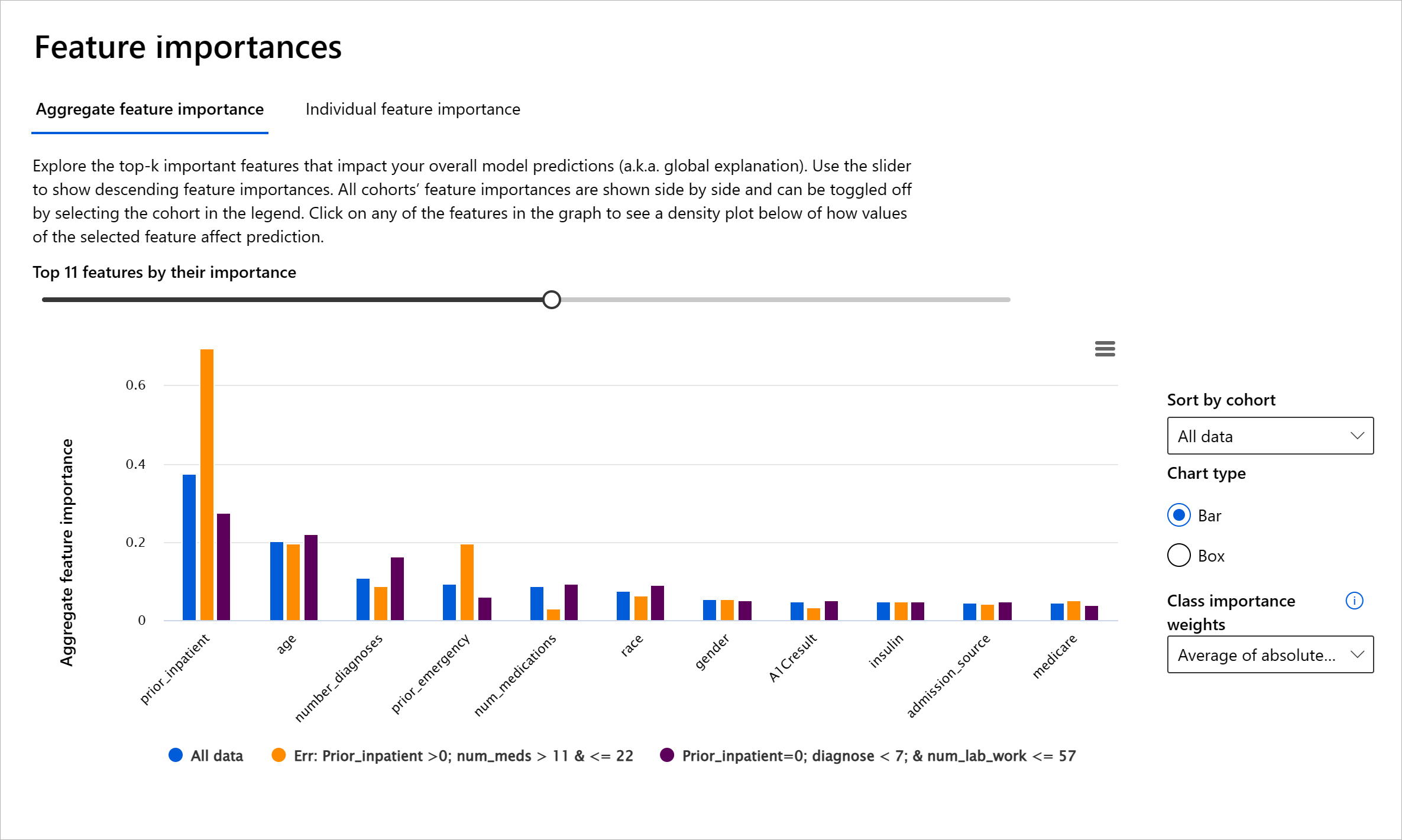
- Globalne wyjaśnienia: Na przykład, jakie cechy wpływają na ogólne zachowanie modelu przewidującego ponowne przyjęcie do szpitala pacjentów z cukrzycą?
- Lokalne wyjaśnienia: Na przykład, dlaczego pacjent z cukrzycą powyżej 60 roku życia z wcześniejszymi hospitalizacjami został przewidziany jako ponownie przyjęty lub nieprzyjęty do szpitala w ciągu 30 dni?
W procesie debugowania wydajności modelu w różnych kohortach, Ważność Cech pokazuje, jaki wpływ ma cecha w różnych kohortach. Pomaga ujawnić anomalie podczas porównywania poziomu wpływu cechy na błędne przewidywania modelu. Komponent Ważności Cech może pokazać, które wartości w cechach pozytywnie lub negatywnie wpłynęły na wynik modelu. Na przykład, jeśli model dokonał błędnego przewidywania, komponent daje możliwość szczegółowego zbadania i wskazania, które cechy lub wartości cech wpłynęły na przewidywanie. Ten poziom szczegółowości pomaga nie tylko w debugowaniu, ale także zapewnia przejrzystość i odpowiedzialność w sytuacjach audytowych. Wreszcie, komponent może pomóc w identyfikacji
- Nad- lub niedoreprezentowanie. Chodzi o sytuację, w której określona grupa nie jest widoczna w danym zawodzie, a każda usługa lub funkcja, która to utrwala, przyczynia się do szkody.
Azure RAI dashboard
Azure RAI dashboard opiera się na narzędziach open-source opracowanych przez czołowe instytucje akademickie i organizacje, w tym Microsoft. Są one kluczowe dla naukowców zajmujących się danymi i twórców AI, aby lepiej zrozumieć zachowanie modeli, odkrywać i łagodzić niepożądane problemy związane z modelami AI.
-
Dowiedz się, jak korzystać z różnych komponentów, zapoznając się z dokumentacją RAI dashboard docs.
-
Sprawdź przykładowe notatniki RAI dashboard sample notebooks do debugowania bardziej odpowiedzialnych scenariuszy AI w Azure Machine Learning.
🚀 Wyzwanie
Aby zapobiec wprowadzaniu statystycznych lub danych uprzedzeń, powinniśmy:
- zapewnić różnorodność środowisk i perspektyw wśród osób pracujących nad systemami
- inwestować w zestawy danych odzwierciedlające różnorodność naszego społeczeństwa
- opracowywać lepsze metody wykrywania i korygowania uprzedzeń, gdy się pojawią
Pomyśl o rzeczywistych scenariuszach, w których niesprawiedliwość jest widoczna w budowaniu i użytkowaniu modeli. Co jeszcze powinniśmy wziąć pod uwagę?
Quiz po wykładzie
Przegląd i samodzielna nauka
W tej lekcji nauczyłeś się praktycznych narzędzi do włączania odpowiedzialnej AI w uczeniu maszynowym.
Obejrzyj ten warsztat, aby zgłębić temat:
- Responsible AI Dashboard: Kompleksowe narzędzie do wdrażania RAI w praktyce, prowadzone przez Besmirę Nushi i Mehrnoosh Sameki

🎥 Kliknij obrazek powyżej, aby obejrzeć wideo: Responsible AI Dashboard: Kompleksowe narzędzie do wdrażania RAI w praktyce, prowadzone przez Besmirę Nushi i Mehrnoosh Sameki
Zapoznaj się z poniższymi materiałami, aby dowiedzieć się więcej o odpowiedzialnej AI i jak budować bardziej godne zaufania modele:
-
Narzędzia Microsoft RAI dashboard do debugowania modeli ML: Responsible AI tools resources
-
Odkryj zestaw narzędzi Responsible AI: Github
-
Centrum zasobów Microsoft RAI: Responsible AI Resources – Microsoft AI
-
Grupa badawcza Microsoft FATE: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Zadanie
Zastrzeżenie:
Ten dokument został przetłumaczony za pomocą usługi tłumaczeniowej AI Co-op Translator. Chociaż dokładamy wszelkich starań, aby tłumaczenie było precyzyjne, prosimy pamiętać, że automatyczne tłumaczenia mogą zawierać błędy lub nieścisłości. Oryginalny dokument w jego rodzimym języku powinien być uznawany za wiarygodne źródło. W przypadku informacji krytycznych zaleca się skorzystanie z profesjonalnego tłumaczenia wykonanego przez człowieka. Nie ponosimy odpowiedzialności za jakiekolwiek nieporozumienia lub błędne interpretacje wynikające z korzystania z tego tłumaczenia.