12 KiB
ਖਾਣੇ ਦੀ ਸਿਫਾਰਸ਼ ਕਰਨ ਵਾਲਾ ਵੈੱਬ ਐਪ ਬਣਾਓ
ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ਪਿਛਲੇ ਪਾਠਾਂ ਵਿੱਚ ਸਿੱਖੀਆਂ ਕੁਝ ਤਕਨੀਕਾਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਇੱਕ ਵਰਗੀਕਰਨ ਮਾਡਲ ਬਣਾਉਗੇ ਅਤੇ ਇਸ ਸਿਰੀਜ਼ ਵਿੱਚ ਵਰਤੇ ਗਏ ਸੁਆਦਿਸ਼ਟ ਖਾਣੇ ਦੇ ਡਾਟਾਸੈਟ ਨਾਲ ਕੰਮ ਕਰੋਗੇ। ਇਸ ਤੋਂ ਇਲਾਵਾ, ਤੁਸੀਂ ਇੱਕ ਛੋਟਾ ਵੈੱਬ ਐਪ ਬਣਾਉਗੇ ਜੋ ਸੇਵ ਕੀਤੇ ਮਾਡਲ ਨੂੰ ਵਰਤਦਾ ਹੈ, Onnx ਦੇ ਵੈੱਬ ਰਨਟਾਈਮ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ।
ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਦੇ ਸਭ ਤੋਂ ਉਪਯੋਗ ਪ੍ਰਯੋਗਾਂ ਵਿੱਚੋਂ ਇੱਕ ਸਿਫਾਰਸ਼ੀ ਸਿਸਟਮ ਬਣਾਉਣਾ ਹੈ, ਅਤੇ ਤੁਸੀਂ ਅੱਜ ਇਸ ਦਿਸ਼ਾ ਵਿੱਚ ਪਹਿਲਾ ਕਦਮ ਲੈ ਸਕਦੇ ਹੋ!

🎥 ਉੱਪਰ ਦਿੱਤੀ ਤਸਵੀਰ 'ਤੇ ਕਲਿਕ ਕਰੋ ਇੱਕ ਵੀਡੀਓ ਲਈ: ਜੈਨ ਲੂਪਰ ਵਰਗੀਕ੍ਰਿਤ ਖਾਣੇ ਦੇ ਡਾਟਾ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ ਇੱਕ ਵੈੱਬ ਐਪ ਬਣਾਉਂਦੇ ਹਨ
ਪਾਠ-ਪਹਿਲਾਂ ਕਵਿਜ਼
ਇਸ ਪਾਠ ਵਿੱਚ ਤੁਸੀਂ ਸਿੱਖੋਗੇ:
- ਮਾਡਲ ਬਣਾਉਣਾ ਅਤੇ ਇਸਨੂੰ Onnx ਮਾਡਲ ਵਜੋਂ ਸੇਵ ਕਰਨਾ
- Netron ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਮਾਡਲ ਦੀ ਜਾਂਚ ਕਰਨਾ
- ਆਪਣੇ ਮਾਡਲ ਨੂੰ ਵੈੱਬ ਐਪ ਵਿੱਚ ਅਨੁਮਾਨ ਲਈ ਵਰਤਣਾ
ਆਪਣਾ ਮਾਡਲ ਬਣਾਓ
Applied ML ਸਿਸਟਮ ਬਣਾਉਣਾ ਤੁਹਾਡੇ ਕਾਰੋਬਾਰੀ ਸਿਸਟਮਾਂ ਲਈ ਇਹ ਤਕਨਾਲੋਜੀਆਂ ਦੀ ਵਰਤੋਂ ਕਰਨ ਦਾ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਹਿੱਸਾ ਹੈ। ਤੁਸੀਂ ਆਪਣੇ ਵੈੱਬ ਐਪਲੀਕੇਸ਼ਨਾਂ ਵਿੱਚ ਮਾਡਲ ਦੀ ਵਰਤੋਂ ਕਰ ਸਕਦੇ ਹੋ (ਅਤੇ ਜੇ ਲੋੜ ਹੋਵੇ ਤਾਂ ਇਸਨੂੰ ਆਫਲਾਈਨ ਸੰਦਰਭ ਵਿੱਚ ਵੀ ਵਰਤ ਸਕਦੇ ਹੋ) Onnx ਦੀ ਵਰਤੋਂ ਕਰਕੇ।
ਇੱਕ ਪਿਛਲੇ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ UFO sightings ਬਾਰੇ ਇੱਕ ਰਿਗ੍ਰੈਸ਼ਨ ਮਾਡਲ ਬਣਾਇਆ ਸੀ, ਇਸਨੂੰ "pickled" ਕੀਤਾ ਸੀ, ਅਤੇ ਇਸਨੂੰ Flask ਐਪ ਵਿੱਚ ਵਰਤਿਆ ਸੀ। ਜਦੋਂ ਕਿ ਇਹ ਆਰਕੀਟੈਕਚਰ ਜਾਣਨ ਲਈ ਬਹੁਤ ਹੀ ਉਪਯੋਗ ਹੈ, ਇਹ ਇੱਕ ਫੁੱਲ-ਸਟੈਕ ਪਾਈਥਨ ਐਪ ਹੈ, ਅਤੇ ਤੁਹਾਡੇ ਜ਼ਰੂਰਤਾਂ ਵਿੱਚ ਜਾਵਾਸਕ੍ਰਿਪਟ ਐਪਲੀਕੇਸ਼ਨ ਦੀ ਵਰਤੋਂ ਸ਼ਾਮਲ ਹੋ ਸਕਦੀ ਹੈ।
ਇਸ ਪਾਠ ਵਿੱਚ, ਤੁਸੀਂ ਅਨੁਮਾਨ ਲਈ ਇੱਕ ਬੁਨਿਆਦੀ ਜਾਵਾਸਕ੍ਰਿਪਟ-ਅਧਾਰਤ ਸਿਸਟਮ ਬਣਾਉਣਗੇ। ਪਹਿਲਾਂ, ਹਾਲਾਂਕਿ, ਤੁਹਾਨੂੰ ਇੱਕ ਮਾਡਲ ਟ੍ਰੇਨ ਕਰਨਾ ਅਤੇ ਇਸਨੂੰ Onnx ਨਾਲ ਵਰਤਣ ਲਈ ਕਨਵਰਟ ਕਰਨਾ ਪਵੇਗਾ।
ਅਭਿਆਸ - ਵਰਗੀਕਰਨ ਮਾਡਲ ਟ੍ਰੇਨ ਕਰੋ
ਸਭ ਤੋਂ ਪਹਿਲਾਂ, ਸਾਫ ਕੀਤੇ ਗਏ ਖਾਣੇ ਦੇ ਡਾਟਾਸੈਟ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਇੱਕ ਵਰਗੀਕਰਨ ਮਾਡਲ ਟ੍ਰੇਨ ਕਰੋ।
-
ਉਪਯੋਗ ਲਾਇਬ੍ਰੇਰੀਆਂ ਨੂੰ ਇੰਪੋਰਟ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰੋ:
!pip install skl2onnx import pandas as pdਤੁਹਾਨੂੰ 'skl2onnx' ਦੀ ਲੋੜ ਹੈ ਜੋ ਤੁਹਾਡੇ Scikit-learn ਮਾਡਲ ਨੂੰ Onnx ਫਾਰਮੈਟ ਵਿੱਚ ਕਨਵਰਟ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰੇਗਾ।
-
ਫਿਰ, ਆਪਣੇ ਡਾਟਾ ਨਾਲ ਪਿਛਲੇ ਪਾਠਾਂ ਵਿੱਚ ਕੀਤੇ ਤਰੀਕੇ ਨਾਲ ਕੰਮ ਕਰੋ,
read_csv()ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਇੱਕ CSV ਫਾਈਲ ਪੜ੍ਹੋ:data = pd.read_csv('../data/cleaned_cuisines.csv') data.head() -
ਪਹਿਲੇ ਦੋ ਗੈਰ-ਜ਼ਰੂਰੀ ਕਾਲਮ ਹਟਾਓ ਅਤੇ ਬਾਕੀ ਡਾਟਾ ਨੂੰ 'X' ਵਜੋਂ ਸੇਵ ਕਰੋ:
X = data.iloc[:,2:] X.head() -
ਲੇਬਲ ਨੂੰ 'y' ਵਜੋਂ ਸੇਵ ਕਰੋ:
y = data[['cuisine']] y.head()
ਟ੍ਰੇਨਿੰਗ ਰੂਟੀਨ ਸ਼ੁਰੂ ਕਰੋ
ਅਸੀਂ 'SVC' ਲਾਇਬ੍ਰੇਰੀ ਦੀ ਵਰਤੋਂ ਕਰਾਂਗੇ ਜਿਸਦੀ ਸਹੀਤਾ ਚੰਗੀ ਹੈ।
-
Scikit-learn ਤੋਂ ਉਚਿਤ ਲਾਇਬ੍ਰੇਰੀਆਂ ਇੰਪੋਰਟ ਕਰੋ:
from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.model_selection import cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report -
ਟ੍ਰੇਨਿੰਗ ਅਤੇ ਟੈਸਟ ਸੈੱਟ ਨੂੰ ਵੱਖ ਕਰੋ:
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3) -
ਪਿਛਲੇ ਪਾਠ ਵਿੱਚ ਕੀਤੇ ਤਰੀਕੇ ਨਾਲ ਇੱਕ SVC ਵਰਗੀਕਰਨ ਮਾਡਲ ਬਣਾਓ:
model = SVC(kernel='linear', C=10, probability=True,random_state=0) model.fit(X_train,y_train.values.ravel()) -
ਹੁਣ, ਆਪਣੇ ਮਾਡਲ ਦੀ ਜਾਂਚ ਕਰੋ,
predict()ਨੂੰ ਕਾਲ ਕਰਕੇ:y_pred = model.predict(X_test) -
ਮਾਡਲ ਦੀ ਗੁਣਵੱਤਾ ਦੀ ਜਾਂਚ ਕਰਨ ਲਈ ਇੱਕ ਵਰਗੀਕਰਨ ਰਿਪੋਰਟ ਪ੍ਰਿੰਟ ਕਰੋ:
print(classification_report(y_test,y_pred))ਜਿਵੇਂ ਅਸੀਂ ਪਹਿਲਾਂ ਵੇਖਿਆ ਸੀ, ਸਹੀਤਾ ਚੰਗੀ ਹੈ:
precision recall f1-score support chinese 0.72 0.69 0.70 257 indian 0.91 0.87 0.89 243 japanese 0.79 0.77 0.78 239 korean 0.83 0.79 0.81 236 thai 0.72 0.84 0.78 224 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
ਆਪਣੇ ਮਾਡਲ ਨੂੰ Onnx ਵਿੱਚ ਕਨਵਰਟ ਕਰੋ
ਸਹੀ Tensor ਨੰਬਰ ਨਾਲ ਕਨਵਰਸ਼ਨ ਯਕੀਨੀ ਬਣਾਓ। ਇਸ ਡਾਟਾਸੈਟ ਵਿੱਚ 380 ਸਮੱਗਰੀਆਂ ਦੀ ਸੂਚੀ ਹੈ, ਇਸ ਲਈ ਤੁਹਾਨੂੰ FloatTensorType ਵਿੱਚ ਉਸ ਨੰਬਰ ਨੂੰ ਦਰਸਾਉਣਾ ਪਵੇਗਾ:
-
380 ਦੇ Tensor ਨੰਬਰ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਕਨਵਰਟ ਕਰੋ।
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 380]))] options = {id(model): {'nocl': True, 'zipmap': False}} -
Onnx ਬਣਾਓ ਅਤੇ ਇਸਨੂੰ model.onnx ਫਾਈਲ ਵਜੋਂ ਸਟੋਰ ਕਰੋ:
onx = convert_sklearn(model, initial_types=initial_type, options=options) with open("./model.onnx", "wb") as f: f.write(onx.SerializeToString())ਨੋਟ ਕਰੋ, ਤੁਸੀਂ ਆਪਣੇ ਕਨਵਰਸ਼ਨ ਸਕ੍ਰਿਪਟ ਵਿੱਚ ਵਿਕਲਪ ਪਾਸ ਕਰ ਸਕਦੇ ਹੋ। ਇਸ ਮਾਮਲੇ ਵਿੱਚ, ਅਸੀਂ 'nocl' ਨੂੰ True ਅਤੇ 'zipmap' ਨੂੰ False ਪਾਸ ਕੀਤਾ। ਕਿਉਂਕਿ ਇਹ ਇੱਕ ਵਰਗੀਕਰਨ ਮਾਡਲ ਹੈ, ਤੁਹਾਡੇ ਕੋਲ ZipMap ਨੂੰ ਹਟਾਉਣ ਦਾ ਵਿਕਲਪ ਹੈ ਜੋ ਡਿਕਸ਼ਨਰੀਆਂ ਦੀ ਸੂਚੀ ਪੈਦਾ ਕਰਦਾ ਹੈ (ਜ਼ਰੂਰੀ ਨਹੀਂ)।
noclਮਾਡਲ ਵਿੱਚ ਸ਼ਾਮਲ ਕਲਾਸ ਜਾਣਕਾਰੀ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ।noclਨੂੰ 'True' ਸੈਟ ਕਰਕੇ ਆਪਣੇ ਮਾਡਲ ਦਾ ਆਕਾਰ ਘਟਾਓ।
ਸਾਰਾ ਨੋਟਬੁੱਕ ਚਲਾਉਣਾ ਹੁਣ ਇੱਕ Onnx ਮਾਡਲ ਬਣਾਏਗਾ ਅਤੇ ਇਸਨੂੰ ਇਸ ਫੋਲਡਰ ਵਿੱਚ ਸੇਵ ਕਰੇਗਾ।
ਆਪਣੇ ਮਾਡਲ ਨੂੰ ਵੇਖੋ
Onnx ਮਾਡਲ Visual Studio ਕੋਡ ਵਿੱਚ ਬਹੁਤ ਜ਼ਿਆਦਾ ਦਿਖਾਈ ਨਹੀਂ ਦਿੰਦੇ, ਪਰ ਇੱਕ ਬਹੁਤ ਵਧੀਆ ਮੁਫ਼ਤ ਸੌਫਟਵੇਅਰ ਹੈ ਜੋ ਬਹੁਤ ਸਾਰੇ ਖੋਜਕਰਤਾ ਮਾਡਲ ਨੂੰ ਵੇਖਣ ਲਈ ਵਰਤਦੇ ਹਨ ਤਾਂ ਜੋ ਇਹ ਯਕੀਨੀ ਬਣਾਇਆ ਜਾ ਸਕੇ ਕਿ ਇਹ ਠੀਕ ਤਰੀਕੇ ਨਾਲ ਬਣਾਇਆ ਗਿਆ ਹੈ। Netron ਡਾਊਨਲੋਡ ਕਰੋ ਅਤੇ ਆਪਣੀ model.onnx ਫਾਈਲ ਖੋਲ੍ਹੋ। ਤੁਸੀਂ ਆਪਣਾ ਸਧਾਰਨ ਮਾਡਲ ਵੇਖ ਸਕਦੇ ਹੋ, ਜਿਸ ਵਿੱਚ 380 ਇਨਪੁਟ ਅਤੇ ਵਰਗੀਕਰਨ ਦਰਸਾਇਆ ਗਿਆ ਹੈ:
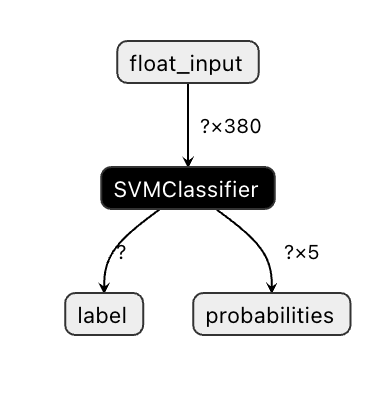
Netron ਤੁਹਾਡੇ ਮਾਡਲਾਂ ਨੂੰ ਵੇਖਣ ਲਈ ਇੱਕ ਮਦਦਗਾਰ ਸੰਦ ਹੈ।
ਹੁਣ ਤੁਸੀਂ ਇਸ ਸ਼ਾਨਦਾਰ ਮਾਡਲ ਨੂੰ ਇੱਕ ਵੈੱਬ ਐਪ ਵਿੱਚ ਵਰਤਣ ਲਈ ਤਿਆਰ ਹੋ। ਆਓ ਇੱਕ ਐਪ ਬਣਾਈਏ ਜੋ ਤੁਹਾਡੇ ਫ੍ਰਿਜ ਵਿੱਚ ਦੇਖਣ ਅਤੇ ਇਹ ਪਤਾ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰੇ ਕਿ ਤੁਹਾਡੇ ਬਚੇ ਹੋਏ ਸਮੱਗਰੀ ਦੇ ਕੌਣ-ਕੌਣ ਦੇ組
ਅਸਵੀਕਾਰਨਾ:
ਇਹ ਦਸਤਾਵੇਜ਼ AI ਅਨੁਵਾਦ ਸੇਵਾ Co-op Translator ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਅਨੁਵਾਦ ਕੀਤਾ ਗਿਆ ਹੈ। ਜਦੋਂ ਕਿ ਅਸੀਂ ਸਹੀ ਹੋਣ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦੇ ਹਾਂ, ਕਿਰਪਾ ਕਰਕੇ ਧਿਆਨ ਦਿਓ ਕਿ ਸਵੈਚਾਲਿਤ ਅਨੁਵਾਦਾਂ ਵਿੱਚ ਗਲਤੀਆਂ ਜਾਂ ਅਸੁਚੱਜੇਪਣ ਹੋ ਸਕਦੇ ਹਨ। ਮੂਲ ਦਸਤਾਵੇਜ਼, ਜੋ ਇਸਦੀ ਮੂਲ ਭਾਸ਼ਾ ਵਿੱਚ ਹੈ, ਨੂੰ ਅਧਿਕਾਰਤ ਸਰੋਤ ਮੰਨਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਮਹੱਤਵਪੂਰਨ ਜਾਣਕਾਰੀ ਲਈ, ਪੇਸ਼ੇਵਰ ਮਨੁੱਖੀ ਅਨੁਵਾਦ ਦੀ ਸਿਫਾਰਸ਼ ਕੀਤੀ ਜਾਂਦੀ ਹੈ। ਇਸ ਅਨੁਵਾਦ ਦੀ ਵਰਤੋਂ ਤੋਂ ਪੈਦਾ ਹੋਣ ਵਾਲੇ ਕਿਸੇ ਵੀ ਗਲਤ ਫਹਿਮੀ ਜਾਂ ਗਲਤ ਵਿਆਖਿਆ ਲਈ ਅਸੀਂ ਜ਼ਿੰਮੇਵਾਰ ਨਹੀਂ ਹਾਂ।