19 KiB
Postscript: Modellfeilsøking i maskinlæring ved bruk av komponenter fra Responsible AI-dashboardet
Pre-lecture quiz
Introduksjon
Maskinlæring påvirker våre daglige liv. AI finner veien inn i noen av de viktigste systemene som berører oss som individer og samfunnet vårt, fra helsevesen, finans, utdanning og arbeidsliv. For eksempel er systemer og modeller involvert i daglige beslutningsoppgaver, som helsediagnoser eller deteksjon av svindel. Som en konsekvens blir fremskrittene innen AI og den akselererte adopsjonen møtt med stadig utviklende samfunnsforventninger og økende regulering. Vi ser stadig områder der AI-systemer ikke lever opp til forventningene; de avdekker nye utfordringer; og myndigheter begynner å regulere AI-løsninger. Derfor er det viktig at disse modellene analyseres for å sikre rettferdige, pålitelige, inkluderende, transparente og ansvarlige resultater for alle.
I dette kurset skal vi se på praktiske verktøy som kan brukes til å vurdere om en modell har problemer knyttet til ansvarlig AI. Tradisjonelle feilsøkingsmetoder for maskinlæring er ofte basert på kvantitative beregninger som aggregert nøyaktighet eller gjennomsnittlig feilrate. Tenk deg hva som kan skje når dataene du bruker til å bygge disse modellene mangler visse demografiske grupper, som rase, kjønn, politisk syn, religion, eller er uforholdsmessig representert. Hva med når modellens output tolkes til å favorisere en demografisk gruppe? Dette kan føre til over- eller underrepresentasjon av sensitive egenskaper, noe som resulterer i rettferdighets-, inkluderings- eller pålitelighetsproblemer fra modellen. En annen faktor er at maskinlæringsmodeller ofte anses som "black boxes", noe som gjør det vanskelig å forstå og forklare hva som driver modellens prediksjoner. Alle disse er utfordringer dataforskere og AI-utviklere står overfor når de ikke har tilstrekkelige verktøy for å feilsøke og vurdere rettferdigheten eller påliteligheten til en modell.
I denne leksjonen vil du lære om feilsøking av modeller ved bruk av:
- Feilanalyse: Identifisere hvor i datadistribusjonen modellen har høye feilrater.
- Modelloversikt: Utføre sammenlignende analyser på tvers av ulike datakohorter for å avdekke forskjeller i modellens ytelsesmetrikker.
- Dataanalyse: Undersøke hvor det kan være over- eller underrepresentasjon i dataene som kan skjevfordele modellen til å favorisere én demografisk gruppe fremfor en annen.
- Funksjonsviktighet: Forstå hvilke funksjoner som driver modellens prediksjoner på globalt eller lokalt nivå.
Forutsetninger
Som en forutsetning, vennligst gjennomgå Responsible AI tools for developers

Feilanalyse
Tradisjonelle ytelsesmetrikker for modeller som brukes til å måle nøyaktighet, er ofte beregninger basert på korrekte vs feilaktige prediksjoner. For eksempel kan det å fastslå at en modell er nøyaktig 89 % av tiden med en feilrate på 0,001 anses som god ytelse. Feilene er imidlertid ofte ikke jevnt fordelt i det underliggende datasettet. Du kan få en modellnøyaktighet på 89 %, men oppdage at det er ulike områder i dataene der modellen feiler 42 % av tiden. Konsekvensen av disse feilene i visse datagrupper kan føre til rettferdighets- eller pålitelighetsproblemer. Det er avgjørende å forstå områdene der modellen presterer godt eller ikke. Dataområdene med høy feilrate kan vise seg å være viktige demografiske grupper.

Feilanalysemodulen på RAI-dashboardet illustrerer hvordan modellfeil er fordelt på ulike kohorter med en trevisualisering. Dette er nyttig for å identifisere funksjoner eller områder der det er høy feilrate i datasettet ditt. Ved å se hvor de fleste av modellens feil oppstår, kan du begynne å undersøke årsaken. Du kan også opprette datakohorter for å utføre analyser. Disse datakohortene hjelper i feilsøkingsprosessen med å avgjøre hvorfor modellens ytelse er god i én kohort, men feilaktig i en annen.

De visuelle indikatorene på trevisualiseringen hjelper deg med å lokalisere problemområdene raskere. For eksempel, jo mørkere rødfargen på en tre-node, desto høyere er feilraten.
Varmekart er en annen visualiseringsfunksjonalitet som brukere kan bruke til å undersøke feilraten ved hjelp av én eller to funksjoner for å finne bidragsytere til modellfeil på tvers av hele datasettet eller kohorter.

Bruk feilanalyse når du trenger å:
- Få en dyp forståelse av hvordan modellfeil er fordelt på et datasett og på flere input- og funksjonsdimensjoner.
- Bryte ned de samlede ytelsesmetrikker for automatisk å oppdage feilaktige kohorter og informere om målrettede tiltak for å redusere feil.
Modelloversikt
Evaluering av ytelsen til en maskinlæringsmodell krever en helhetlig forståelse av dens oppførsel. Dette kan oppnås ved å gjennomgå mer enn én metrikk, som feilrate, nøyaktighet, tilbakekalling, presisjon eller MAE (Mean Absolute Error), for å finne forskjeller blant ytelsesmetrikker. Én ytelsesmetrikk kan se bra ut, men unøyaktigheter kan avdekkes i en annen metrikk. I tillegg hjelper sammenligning av metrikker for forskjeller på tvers av hele datasettet eller kohorter med å belyse hvor modellen presterer godt eller ikke. Dette er spesielt viktig for å se modellens ytelse blant sensitive vs insensitive funksjoner (f.eks. pasientens rase, kjønn eller alder) for å avdekke potensiell urettferdighet modellen kan ha. For eksempel kan det å oppdage at modellen er mer feilaktig i en kohort med sensitive funksjoner avsløre potensiell urettferdighet.
Modelloversiktsmodulen på RAI-dashboardet hjelper ikke bare med å analysere ytelsesmetrikker for datarepresentasjon i en kohort, men gir brukere muligheten til å sammenligne modellens oppførsel på tvers av ulike kohorter.

Modulens funksjonsbaserte analysefunksjonalitet lar brukere snevre inn datasubgrupper innenfor en bestemt funksjon for å identifisere avvik på et detaljert nivå. For eksempel har dashboardet innebygd intelligens for automatisk å generere kohorter for en bruker-valgt funksjon (f.eks. "time_in_hospital < 3" eller "time_in_hospital >= 7"). Dette gjør det mulig for en bruker å isolere en bestemt funksjon fra en større datagruppe for å se om den er en nøkkelpåvirker for modellens feilaktige resultater.

Modelloversiktsmodulen støtter to klasser av forskjellsmetrikker:
Forskjeller i modellens ytelse: Disse metrikker beregner forskjellen i verdiene til den valgte ytelsesmetrikk på tvers av undergrupper av data. Her er noen eksempler:
- Forskjell i nøyaktighetsrate
- Forskjell i feilrate
- Forskjell i presisjon
- Forskjell i tilbakekalling
- Forskjell i gjennomsnittlig absolutt feil (MAE)
Forskjeller i utvalgsrate: Denne metrikk inneholder forskjellen i utvalgsrate (gunstig prediksjon) blant undergrupper. Et eksempel på dette er forskjellen i lånegodkjenningsrater. Utvalgsrate betyr andelen datapunkter i hver klasse klassifisert som 1 (i binær klassifisering) eller distribusjonen av prediksjonsverdier (i regresjon).
Dataanalyse
"Hvis du torturerer dataene lenge nok, vil de tilstå hva som helst" - Ronald Coase
Denne uttalelsen høres ekstrem ut, men det er sant at data kan manipuleres for å støtte enhver konklusjon. Slik manipulasjon kan noen ganger skje utilsiktet. Som mennesker har vi alle bias, og det er ofte vanskelig å bevisst vite når vi introduserer bias i dataene. Å garantere rettferdighet i AI og maskinlæring forblir en kompleks utfordring.
Data er et stort blindpunkt for tradisjonelle modellytelsesmetrikker. Du kan ha høye nøyaktighetsscorer, men dette reflekterer ikke alltid den underliggende databiasen som kan være i datasettet ditt. For eksempel, hvis et datasett med ansatte har 27 % kvinner i lederstillinger i et selskap og 73 % menn på samme nivå, kan en AI-modell for jobbannonsering som er trent på disse dataene, målrette seg mot en overvekt av mannlige kandidater for seniorstillinger. Denne ubalansen i dataene skjevfordelte modellens prediksjon til å favorisere ett kjønn. Dette avslører et rettferdighetsproblem der det er kjønnsbias i AI-modellen.
Dataanalysemodulen på RAI-dashboardet hjelper med å identifisere områder der det er over- og underrepresentasjon i datasettet. Den hjelper brukere med å diagnostisere årsaken til feil og rettferdighetsproblemer som introduseres fra dataubalanser eller mangel på representasjon av en bestemt datagruppe. Dette gir brukere muligheten til å visualisere datasett basert på predikerte og faktiske resultater, feilgrupper og spesifikke funksjoner. Noen ganger kan det å oppdage en underrepresentert datagruppe også avdekke at modellen ikke lærer godt, og dermed har høye unøyaktigheter. En modell med databias er ikke bare et rettferdighetsproblem, men viser også at modellen ikke er inkluderende eller pålitelig.

Bruk dataanalyse når du trenger å:
- Utforske statistikken i datasettet ditt ved å velge ulike filtre for å dele opp dataene i ulike dimensjoner (også kjent som kohorter).
- Forstå distribusjonen av datasettet ditt på tvers av ulike kohorter og funksjonsgrupper.
- Bestemme om funnene dine relatert til rettferdighet, feilanalyse og årsakssammenhenger (avledet fra andre dashboardmoduler) er et resultat av distribusjonen i datasettet ditt.
- Avgjøre hvilke områder du bør samle inn mer data for å redusere feil som kommer fra representasjonsproblemer, støy i etiketter, støy i funksjoner, etikettbias og lignende faktorer.
Modellfortolkning
Maskinlæringsmodeller har en tendens til å være "black boxes". Å forstå hvilke nøkkelfunksjoner i dataene som driver en modells prediksjon kan være utfordrende. Det er viktig å gi transparens om hvorfor en modell gjør en bestemt prediksjon. For eksempel, hvis et AI-system forutsier at en diabetiker er i fare for å bli innlagt på sykehus igjen innen 30 dager, bør det kunne gi støttende data som ledet til denne prediksjonen. Å ha støttende dataindikatorer gir transparens som hjelper klinikere eller sykehus med å ta velinformerte beslutninger. I tillegg gjør det å kunne forklare hvorfor en modell gjorde en prediksjon for en individuell pasient det mulig å oppfylle ansvarlighet med helsereguleringer. Når du bruker maskinlæringsmodeller på måter som påvirker menneskers liv, er det avgjørende å forstå og forklare hva som påvirker modellens oppførsel. Modellforklarbarhet og fortolkning hjelper med å svare på spørsmål i scenarier som:
- Modellfeilsøking: Hvorfor gjorde modellen min denne feilen? Hvordan kan jeg forbedre modellen min?
- Menneske-AI-samarbeid: Hvordan kan jeg forstå og stole på modellens beslutninger?
- Regulatorisk samsvar: Oppfyller modellen min juridiske krav?
Funksjonsviktighetsmodulen på RAI-dashboardet hjelper deg med å feilsøke og få en omfattende forståelse av hvordan en modell gjør prediksjoner. Det er også et nyttig verktøy for maskinlæringsprofesjonelle og beslutningstakere for å forklare og vise bevis på funksjoner som påvirker modellens oppførsel for regulatorisk samsvar. Videre kan brukere utforske både globale og lokale forklaringer for å validere hvilke funksjoner som driver modellens prediksjon. Globale forklaringer viser de viktigste funksjonene som påvirket modellens samlede prediksjon. Lokale forklaringer viser hvilke funksjoner som ledet til modellens prediksjon for en individuell sak. Muligheten til å evaluere lokale forklaringer er også nyttig i feilsøking eller revisjon av en spesifikk sak for bedre å forstå og tolke hvorfor en modell gjorde en korrekt eller feilaktig prediksjon.
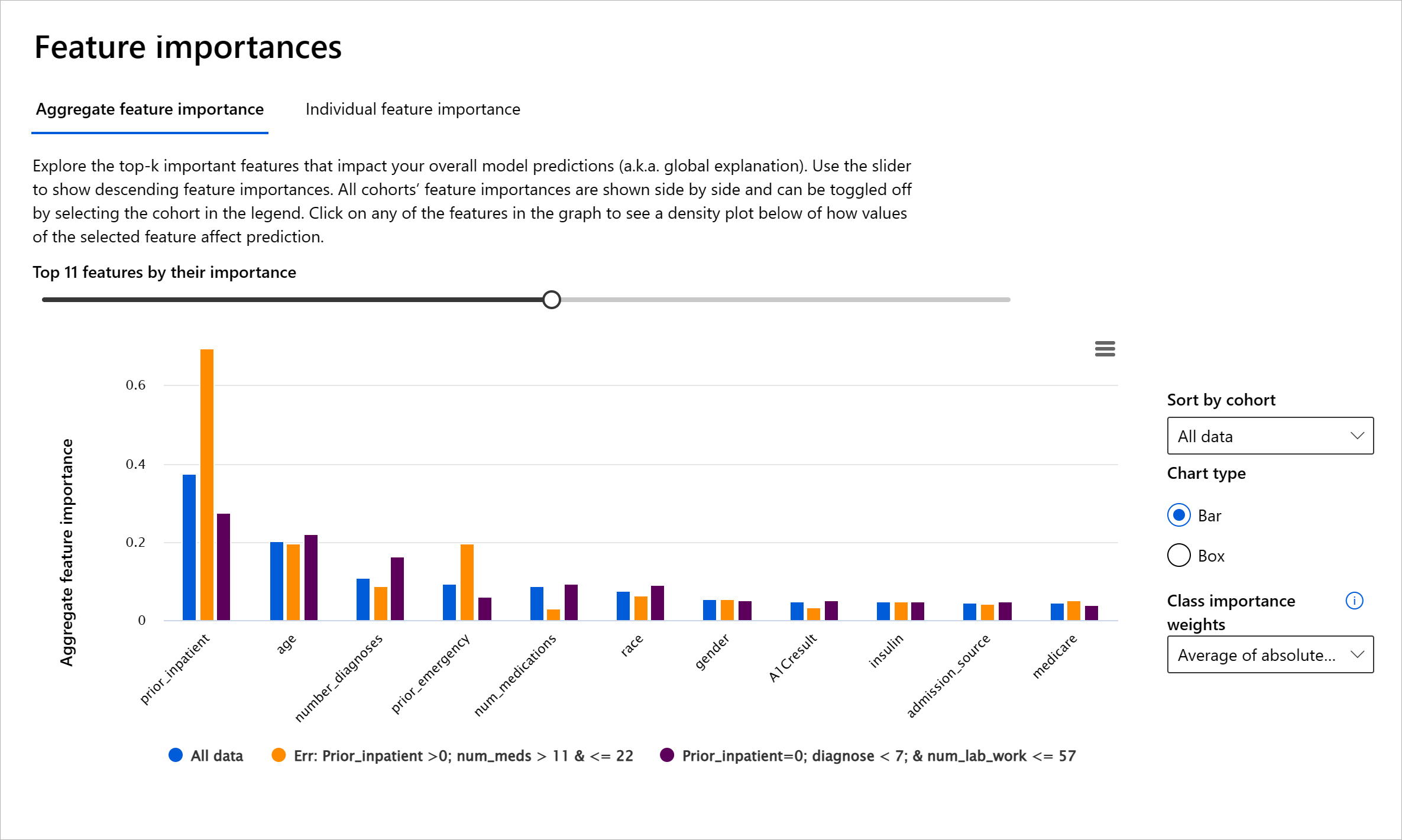
- Globale forklaringer: For eksempel, hvilke funksjoner påvirker den generelle oppførselen til en diabetesmodell for sykehusinnleggelse?
- Lokale forklaringer: For eksempel, hvorfor ble en diabetiker over 60 år med tidligere sykehusinnleggelser forutsagt å bli innlagt eller ikke innlagt igjen innen 30 dager?
I feilsøkingsprosessen med å undersøke modellens ytelse på tvers av ulike kohorter, viser Funksjonsviktighet hvilken grad av påvirkning en funksjon har på tvers av kohorter. Det hjelper med å avdekke avvik når man sammenligner nivået av innflytelse funksjonen har på å drive modellens feilaktige prediksjoner. Funksjonsviktighetsmodulen kan vise hvilke verdier i en funksjon som positivt eller negativt påvirket modellens resultat. For eksempel, hvis en modell gjorde en feilaktig prediksjon, gir modulen deg muligheten til å bore ned og identifisere hvilke funksjoner eller funksjonsverdier som drev prediksjonen. Dette detaljnivået hjelper ikke bare med feilsøking, men gir transparens og ansvarlighet i revisjonssituasjoner. Til slutt kan modulen hjelpe deg med å identifisere rettferdighetsproblemer. For å illustrere, hvis en sensitiv funksjon som etnisitet eller kjønn har stor innflytelse på modellens prediksjon, kan dette være et tegn på rase- eller kjønnsbias i modellen.
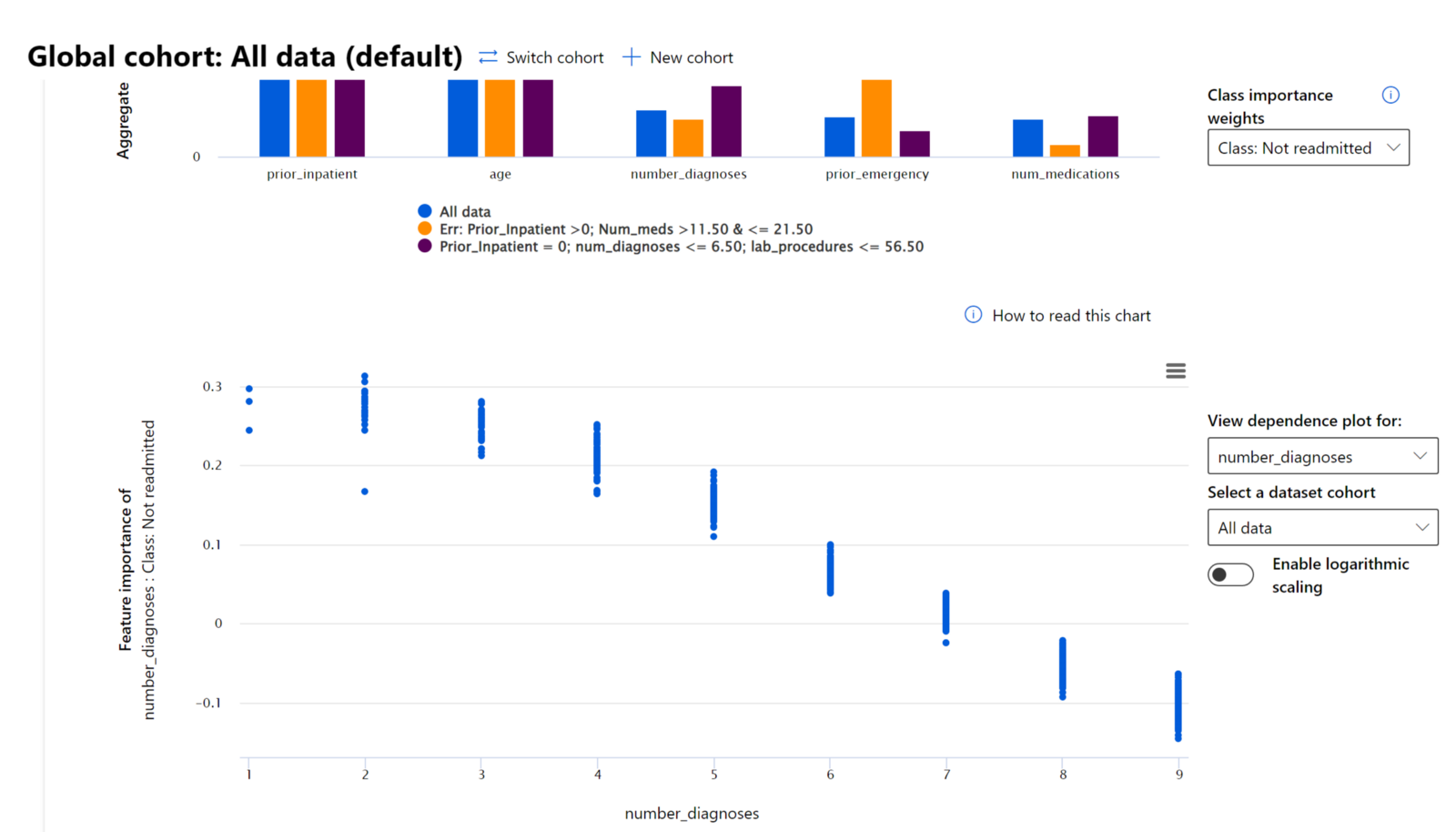
Bruk fortolkning når du trenger å:
- Bestemme hvor pålitelige prediksjonene til AI-systemet ditt er ved å forstå hvilke funksjoner som er viktigst for prediksjonene.
- Tilnærme deg feilsøkingen av modellen din ved først å forstå den og identifisere om modellen bruker sunne funksjoner eller bare falske korrelasjoner.
- Avdekke potensielle kilder til urettferdighet ved å forstå om modellen baserer prediksjoner på sensitive funksjoner eller på funksjoner som er sterkt korrelert med dem.
- Bygge brukertillit til modellens beslutninger ved å generere lokale forklaringer for å illustrere resultatene.
- Fullføre en regulatorisk revisjon av et AI-system for å validere modeller og overvåke effekten av modellens beslutninger på mennesker.
Konklusjon
Alle komponentene i RAI-dashboardet er praktiske verktøy som hjelper deg med å bygge maskinlæringsmodeller som er mindre skadelige og mer pålitelige for samfunnet. Det forbedrer forebyggingen av trusler mot menneskerettigheter; diskriminering eller ekskludering av visse grupper fra livsmuligheter; og risikoen for fysisk eller psykisk skade. Det hjelper også med å bygge tillit til modellens beslutninger ved å generere lokale forklaringer for å illustrere resultatene. Noen av de potensielle skadene kan klassifiseres som:
- Allokering, hvis for eksempel ett kjønn eller en etnisitet favoriseres over en annen.
- Tjenestekvalitet. Hvis du trener dataene for ett spesifikt scenario, men virkeligheten er mye mer kompleks, fører det til en dårlig fungerende tjeneste.
- Stereotypisering. Å assosiere en gitt gruppe med forhåndsbestemte attributter.
- Nedvurdering. Å urettferdig kritisere og merke noe eller noen.
- Over- eller underrepresentasjon. Tanken er at en bestemt gruppe ikke er synlig i en viss yrke, og enhver tjeneste eller funksjon som fortsetter å fremme dette bidrar til skade.
Azure RAI-dashboard
Azure RAI-dashboard er bygget på åpen kildekodeverktøy utviklet av ledende akademiske institusjoner og organisasjoner, inkludert Microsoft, som er avgjørende for datasientister og AI-utviklere for bedre å forstå modellatferd, oppdage og redusere uønskede problemer fra AI-modeller.
-
Lær hvordan du bruker de forskjellige komponentene ved å sjekke ut RAI-dashboard dokumentasjonen.
-
Sjekk ut noen RAI-dashboard eksempelskript for å feilsøke mer ansvarlige AI-scenarier i Azure Machine Learning.
🚀 Utfordring
For å forhindre at statistiske eller datamessige skjevheter introduseres i utgangspunktet, bør vi:
- ha en mangfoldig bakgrunn og ulike perspektiver blant de som jobber med systemene
- investere i datasett som reflekterer mangfoldet i samfunnet vårt
- utvikle bedre metoder for å oppdage og korrigere skjevheter når de oppstår
Tenk på virkelige situasjoner der urettferdighet er tydelig i modellbygging og bruk. Hva annet bør vi ta hensyn til?
Quiz etter forelesning
Gjennomgang og selvstudium
I denne leksjonen har du lært noen av de praktiske verktøyene for å integrere ansvarlig AI i maskinlæring.
Se denne workshoppen for å dykke dypere inn i temaene:
- Responsible AI Dashboard: En helhetlig løsning for å operationalisere RAI i praksis av Besmira Nushi og Mehrnoosh Sameki

🎥 Klikk på bildet over for en video: Responsible AI Dashboard: En helhetlig løsning for å operationalisere RAI i praksis av Besmira Nushi og Mehrnoosh Sameki
Referer til følgende materialer for å lære mer om ansvarlig AI og hvordan man bygger mer pålitelige modeller:
-
Microsofts RAI-dashboardverktøy for feilsøking av ML-modeller: Ressurser for ansvarlige AI-verktøy
-
Utforsk Responsible AI-verktøysettet: Github
-
Microsofts RAI-ressurssenter: Ressurser for ansvarlig AI – Microsoft AI
-
Microsofts FATE-forskningsgruppe: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
Oppgave
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi streber etter nøyaktighet, vær oppmerksom på at automatiserte oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.