15 KiB
Kom i gang med Python og Scikit-learn for regresjonsmodeller

Sketchnote av Tomomi Imura
Quiz før leksjonen
Denne leksjonen er også tilgjengelig i R!
Introduksjon
I disse fire leksjonene vil du lære hvordan du bygger regresjonsmodeller. Vi skal snart diskutere hva disse brukes til. Men før du gjør noe som helst, sørg for at du har de riktige verktøyene på plass for å starte prosessen!
I denne leksjonen vil du lære å:
- Konfigurere datamaskinen din for lokale maskinlæringsoppgaver.
- Jobbe med Jupyter-notatbøker.
- Bruke Scikit-learn, inkludert installasjon.
- Utforske lineær regresjon gjennom en praktisk øvelse.
Installasjoner og konfigurasjoner

🎥 Klikk på bildet over for en kort video som viser hvordan du konfigurerer datamaskinen din for maskinlæring.
-
Installer Python. Sørg for at Python er installert på datamaskinen din. Du vil bruke Python til mange oppgaver innen datavitenskap og maskinlæring. De fleste datamaskiner har allerede en Python-installasjon. Det finnes også nyttige Python Coding Packs som kan gjøre oppsettet enklere for noen brukere.
Noen bruksområder for Python krever én versjon av programvaren, mens andre krever en annen versjon. Derfor er det nyttig å jobbe i et virtuelt miljø.
-
Installer Visual Studio Code. Sørg for at Visual Studio Code er installert på datamaskinen din. Følg disse instruksjonene for å installere Visual Studio Code for grunnleggende installasjon. Du skal bruke Python i Visual Studio Code i dette kurset, så det kan være lurt å friske opp hvordan du konfigurerer Visual Studio Code for Python-utvikling.
Bli komfortabel med Python ved å jobbe gjennom denne samlingen av Learn-moduler

🎥 Klikk på bildet over for en video: bruk Python i VS Code.
-
Installer Scikit-learn ved å følge disse instruksjonene. Siden du må sørge for at du bruker Python 3, anbefales det at du bruker et virtuelt miljø. Merk at hvis du installerer dette biblioteket på en M1 Mac, finnes det spesielle instruksjoner på siden som er lenket over.
-
Installer Jupyter Notebook. Du må installere Jupyter-pakken.
Ditt ML-utviklingsmiljø
Du skal bruke notatbøker for å utvikle Python-koden din og lage maskinlæringsmodeller. Denne typen filer er et vanlig verktøy for dataforskere, og de kan identifiseres ved suffikset eller filtypen .ipynb.
Notatbøker er et interaktivt miljø som lar utvikleren både kode og legge til notater og skrive dokumentasjon rundt koden, noe som er ganske nyttig for eksperimentelle eller forskningsorienterte prosjekter.

🎥 Klikk på bildet over for en kort video som viser denne øvelsen.
Øvelse - jobb med en notatbok
I denne mappen finner du filen notebook.ipynb.
-
Åpne notebook.ipynb i Visual Studio Code.
En Jupyter-server vil starte med Python 3+. Du vil finne områder i notatboken som kan
kjøres, altså kodeblokker. Du kan kjøre en kodeblokk ved å velge ikonet som ser ut som en avspillingsknapp. -
Velg
md-ikonet og legg til litt markdown, og følgende tekst: # Velkommen til din notatbok.Deretter legger du til litt Python-kode.
-
Skriv print('hello notebook') i kodeblokken.
-
Velg pilen for å kjøre koden.
Du bør se den utskrevne meldingen:
hello notebook

Du kan blande koden din med kommentarer for å selv-dokumentere notatboken.
✅ Tenk et øyeblikk på hvor forskjellig arbeidsmiljøet til en webutvikler er sammenlignet med en dataforsker.
Kom i gang med Scikit-learn
Nå som Python er satt opp i ditt lokale miljø, og du er komfortabel med Jupyter-notatbøker, la oss bli like komfortable med Scikit-learn (uttales sci som i science). Scikit-learn tilbyr en omfattende API for å hjelpe deg med å utføre ML-oppgaver.
Ifølge deres nettsted, "Scikit-learn er et åpen kildekode-bibliotek for maskinlæring som støtter både overvåket og ikke-overvåket læring. Det tilbyr også ulike verktøy for modelltilpasning, dataprosessering, modellvalg og evaluering, samt mange andre nyttige funksjoner."
I dette kurset vil du bruke Scikit-learn og andre verktøy for å bygge maskinlæringsmodeller for å utføre det vi kaller 'tradisjonelle maskinlæringsoppgaver'. Vi har bevisst unngått nevrale nettverk og dyp læring, da disse dekkes bedre i vårt kommende 'AI for nybegynnere'-pensum.
Scikit-learn gjør det enkelt å bygge modeller og evaluere dem for bruk. Det fokuserer primært på bruk av numeriske data og inneholder flere ferdiglagde datasett som kan brukes som læringsverktøy. Det inkluderer også forhåndsbygde modeller som studenter kan prøve. La oss utforske prosessen med å laste inn forhåndspakkede data og bruke en innebygd estimator for å lage vår første ML-modell med Scikit-learn ved hjelp av noen grunnleggende data.
Øvelse - din første Scikit-learn-notatbok
Denne opplæringen er inspirert av eksempelet på lineær regresjon på Scikit-learns nettsted.

🎥 Klikk på bildet over for en kort video som viser denne øvelsen.
I notebook.ipynb-filen som er tilknyttet denne leksjonen, tøm alle cellene ved å trykke på 'søppelbøtte'-ikonet.
I denne delen skal du jobbe med et lite datasett om diabetes som er innebygd i Scikit-learn for læringsformål. Tenk deg at du ønsket å teste en behandling for diabetikere. Maskinlæringsmodeller kan hjelpe deg med å avgjøre hvilke pasienter som vil respondere bedre på behandlingen, basert på kombinasjoner av variabler. Selv en veldig grunnleggende regresjonsmodell, når den visualiseres, kan vise informasjon om variabler som kan hjelpe deg med å organisere dine teoretiske kliniske studier.
✅ Det finnes mange typer regresjonsmetoder, og hvilken du velger avhenger av spørsmålet du ønsker å besvare. Hvis du vil forutsi sannsynlig høyde for en person med en gitt alder, vil du bruke lineær regresjon, siden du søker en numerisk verdi. Hvis du er interessert i å finne ut om en type mat skal anses som vegansk eller ikke, ser du etter en kategoriinndeling, og da vil du bruke logistisk regresjon. Du vil lære mer om logistisk regresjon senere. Tenk litt på noen spørsmål du kan stille til data, og hvilken av disse metodene som ville være mest passende.
La oss komme i gang med denne oppgaven.
Importer biblioteker
For denne oppgaven skal vi importere noen biblioteker:
- matplotlib. Et nyttig verktøy for grafer som vi skal bruke til å lage en linjediagram.
- numpy. numpy er et nyttig bibliotek for håndtering av numeriske data i Python.
- sklearn. Dette er Scikit-learn-biblioteket.
Importer noen biblioteker for å hjelpe med oppgavene dine.
-
Legg til imports ved å skrive følgende kode:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionOver importerer du
matplotlib,numpy, og du importererdatasets,linear_modelogmodel_selectionfrasklearn.model_selectionbrukes til å dele data i trenings- og testsett.
Diabetes-datasettet
Det innebygde diabetes-datasettet inkluderer 442 datasettprøver om diabetes, med 10 funksjonsvariabler, inkludert:
- age: alder i år
- bmi: kroppsmasseindeks
- bp: gjennomsnittlig blodtrykk
- s1 tc: T-celler (en type hvite blodceller)
✅ Dette datasettet inkluderer konseptet 'kjønn' som en funksjonsvariabel viktig for forskning på diabetes. Mange medisinske datasett inkluderer denne typen binær klassifisering. Tenk litt på hvordan slike kategoriseringer kan ekskludere visse deler av befolkningen fra behandlinger.
Nå, last inn X- og y-dataene.
🎓 Husk, dette er overvåket læring, og vi trenger et navngitt 'y'-mål.
I en ny kodecelle, last inn diabetes-datasettet ved å kalle load_diabetes(). Inputen return_X_y=True signaliserer at X vil være en datamatrise, og y vil være regresjonsmålet.
-
Legg til noen print-kommandoer for å vise formen på datamatrisen og dens første element:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Det du får tilbake som svar, er en tuple. Det du gjør, er å tilordne de to første verdiene i tuplen til henholdsvis
Xogy. Lær mer om tupler.Du kan se at disse dataene har 442 elementer formet i matriser med 10 elementer:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Tenk litt på forholdet mellom dataene og regresjonsmålet. Lineær regresjon forutsier forholdet mellom funksjonen X og målvariabelen y. Kan du finne målet for diabetes-datasettet i dokumentasjonen? Hva demonstrerer dette datasettet, gitt målet?
-
Velg deretter en del av dette datasettet for å plotte ved å velge den tredje kolonnen i datasettet. Du kan gjøre dette ved å bruke
:-operatoren for å velge alle rader, og deretter velge den tredje kolonnen ved hjelp av indeksen (2). Du kan også omforme dataene til å være en 2D-matrise - som kreves for plotting - ved å brukereshape(n_rows, n_columns). Hvis en av parameterne er -1, beregnes den tilsvarende dimensjonen automatisk.X = X[:, 2] X = X.reshape((-1,1))✅ Når som helst, skriv ut dataene for å sjekke formen.
-
Nå som du har data klare til å bli plottet, kan du se om en maskin kan hjelpe med å bestemme en logisk inndeling mellom tallene i dette datasettet. For å gjøre dette, må du dele både dataene (X) og målet (y) i test- og treningssett. Scikit-learn har en enkel måte å gjøre dette på; du kan dele testdataene dine på et gitt punkt.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Nå er du klar til å trene modellen din! Last inn den lineære regresjonsmodellen og tren den med X- og y-treningssettene dine ved å bruke
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()er en funksjon du vil se i mange ML-biblioteker som TensorFlow. -
Deretter lager du en prediksjon ved hjelp av testdataene, ved å bruke funksjonen
predict(). Dette vil brukes til å tegne linjen mellom datagruppene.y_pred = model.predict(X_test) -
Nå er det på tide å vise dataene i et diagram. Matplotlib er et veldig nyttig verktøy for denne oppgaven. Lag et spredningsdiagram av alle X- og y-testdataene, og bruk prediksjonen til å tegne en linje på det mest passende stedet mellom modellens datagrupper.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()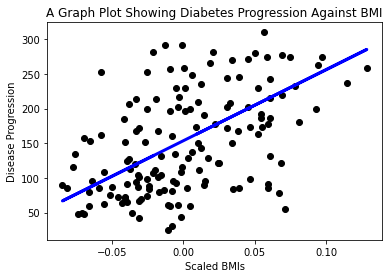 ✅ Tenk litt over hva som skjer her. En rett linje går gjennom mange små datapunkter, men hva gjør den egentlig? Kan du se hvordan du bør kunne bruke denne linjen til å forutsi hvor et nytt, ukjent datapunkt bør passe i forhold til y-aksen i plottet? Prøv å sette ord på den praktiske bruken av denne modellen.
✅ Tenk litt over hva som skjer her. En rett linje går gjennom mange små datapunkter, men hva gjør den egentlig? Kan du se hvordan du bør kunne bruke denne linjen til å forutsi hvor et nytt, ukjent datapunkt bør passe i forhold til y-aksen i plottet? Prøv å sette ord på den praktiske bruken av denne modellen.
Gratulerer, du har bygget din første lineære regresjonsmodell, laget en prediksjon med den, og vist den i et plott!
🚀Utfordring
Plott en annen variabel fra dette datasettet. Hint: rediger denne linjen: X = X[:,2]. Gitt målet for dette datasettet, hva kan du oppdage om utviklingen av diabetes som sykdom?
Quiz etter forelesning
Gjennomgang & Selvstudium
I denne opplæringen jobbet du med enkel lineær regresjon, i stedet for univariat eller multippel lineær regresjon. Les litt om forskjellene mellom disse metodene, eller ta en titt på denne videoen.
Les mer om konseptet regresjon og tenk over hvilke typer spørsmål som kan besvares med denne teknikken. Ta denne opplæringen for å utdype forståelsen din.
Oppgave
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi tilstreber nøyaktighet, vennligst vær oppmerksom på at automatiske oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for eventuelle misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.