16 KiB
Bygge maskinlæringsløsninger med ansvarlig AI
Sketchnote av Tomomi Imura
Quiz før forelesning
Introduksjon
I dette kurset vil du begynne å utforske hvordan maskinlæring påvirker våre daglige liv. Allerede nå er systemer og modeller involvert i beslutningsprosesser som helsevesendiagnoser, lånesøknader eller oppdagelse av svindel. Derfor er det viktig at disse modellene fungerer godt og gir pålitelige resultater. Akkurat som med andre programvareapplikasjoner, kan AI-systemer feile eller gi uønskede utfall. Derfor er det avgjørende å kunne forstå og forklare oppførselen til en AI-modell.
Tenk på hva som kan skje hvis dataene du bruker til å bygge disse modellene mangler visse demografiske grupper, som rase, kjønn, politisk syn eller religion, eller hvis de overrepresenterer visse grupper. Hva skjer hvis modellens resultater tolkes til å favorisere en bestemt gruppe? Hva er konsekvensene for applikasjonen? Og hva skjer hvis modellen gir et skadelig utfall? Hvem er ansvarlig for oppførselen til AI-systemet? Dette er noen av spørsmålene vi vil utforske i dette kurset.
I denne leksjonen vil du:
- Øke bevisstheten om viktigheten av rettferdighet i maskinlæring og skader relatert til urettferdighet.
- Bli kjent med praksisen med å utforske avvik og uvanlige scenarier for å sikre pålitelighet og sikkerhet.
- Forstå behovet for å styrke alle ved å designe inkluderende systemer.
- Utforske hvor viktig det er å beskytte personvern og sikkerhet for data og mennesker.
- Se viktigheten av en "glassboks"-tilnærming for å forklare oppførselen til AI-modeller.
- Være oppmerksom på hvordan ansvarlighet er essensielt for å bygge tillit til AI-systemer.
Forutsetninger
Som en forutsetning, vennligst ta "Ansvarlige AI-prinsipper" læringsstien og se videoen nedenfor om emnet:
Lær mer om ansvarlig AI ved å følge denne læringsstien

🎥 Klikk på bildet over for en video: Microsofts tilnærming til ansvarlig AI
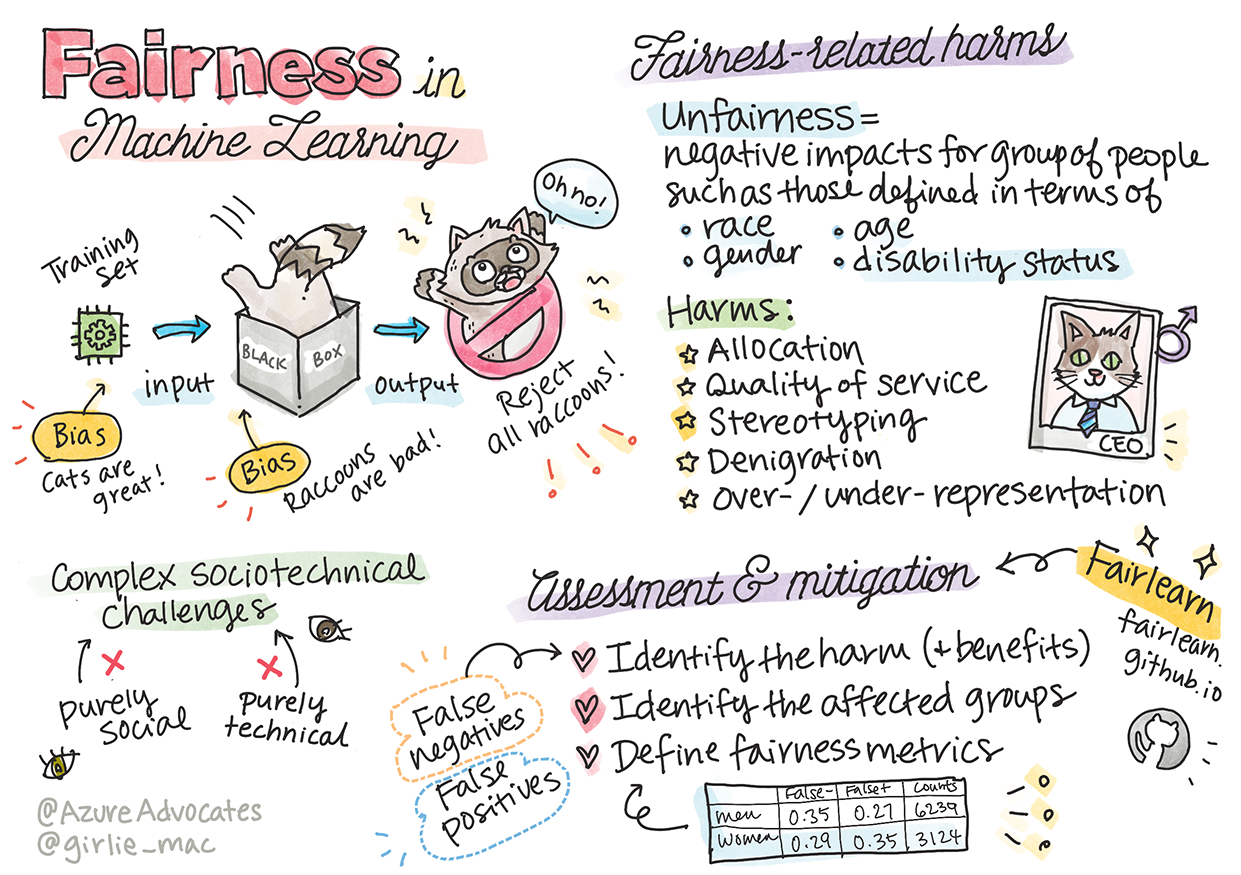
Rettferdighet
AI-systemer bør behandle alle rettferdig og unngå å påvirke lignende grupper på ulike måter. For eksempel, når AI-systemer gir veiledning om medisinsk behandling, lånesøknader eller ansettelser, bør de gi samme anbefalinger til alle med lignende symptomer, økonomiske forhold eller kvalifikasjoner. Vi mennesker bærer med oss arvede skjevheter som påvirker våre beslutninger og handlinger. Disse skjevhetene kan også være til stede i dataene vi bruker til å trene AI-systemer. Slike skjevheter kan noen ganger oppstå utilsiktet. Det er ofte vanskelig å være bevisst på når man introduserer skjevheter i data.
"Urettferdighet" omfatter negative konsekvenser, eller "skader", for en gruppe mennesker, som definert av rase, kjønn, alder eller funksjonshemming. De viktigste skadene relatert til rettferdighet kan klassifiseres som:
- Allokering, hvis for eksempel et kjønn eller en etnisitet favoriseres over en annen.
- Kvalitet på tjenesten. Hvis du trener data for ett spesifikt scenario, men virkeligheten er mye mer kompleks, kan det føre til dårlig ytelse. For eksempel en såpedispenser som ikke klarte å registrere personer med mørk hud. Referanse
- Nedvurdering. Å urettferdig kritisere eller merke noe eller noen. For eksempel ble en bildemerkingsteknologi beryktet for å feilmerke bilder av mørkhudede mennesker som gorillaer.
- Over- eller underrepresentasjon. Ideen om at en bestemt gruppe ikke er synlig i et bestemt yrke, og enhver tjeneste eller funksjon som fortsetter å fremme dette, bidrar til skade.
- Stereotypisering. Å assosiere en gitt gruppe med forhåndsbestemte egenskaper. For eksempel kan et språkoversettingssystem mellom engelsk og tyrkisk ha unøyaktigheter på grunn av ord med stereotypiske kjønnsassosiasjoner.
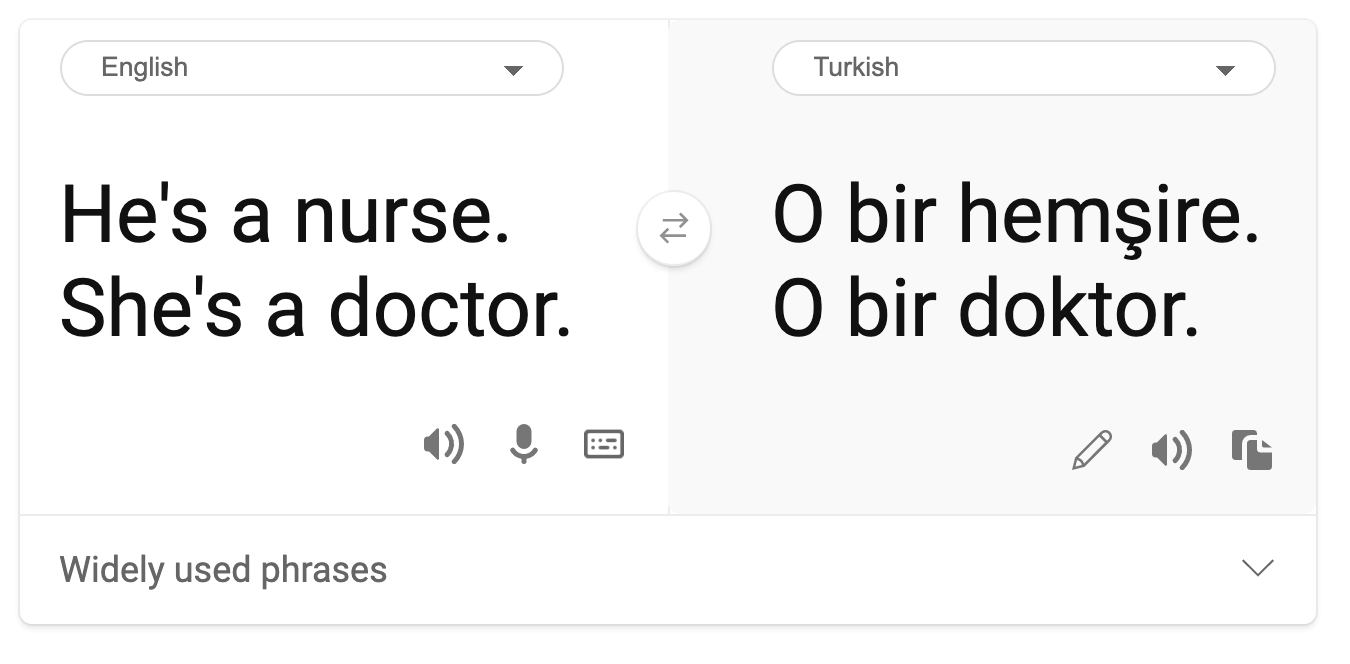
oversettelse til tyrkisk

oversettelse tilbake til engelsk
Når vi designer og tester AI-systemer, må vi sørge for at AI er rettferdig og ikke programmert til å ta skjeve eller diskriminerende beslutninger, noe som også er forbudt for mennesker. Å garantere rettferdighet i AI og maskinlæring forblir en kompleks sosioteknisk utfordring.
Pålitelighet og sikkerhet
For å bygge tillit må AI-systemer være pålitelige, sikre og konsistente under normale og uventede forhold. Det er viktig å vite hvordan AI-systemer vil oppføre seg i ulike situasjoner, spesielt når det gjelder avvik. Når vi bygger AI-løsninger, må vi fokusere mye på hvordan vi håndterer et bredt spekter av omstendigheter som AI-løsningene kan møte. For eksempel må en selvkjørende bil prioritere menneskers sikkerhet. Derfor må AI som driver bilen, ta hensyn til alle mulige scenarier bilen kan møte, som natt, tordenvær eller snøstormer, barn som løper over gaten, kjæledyr, veiarbeid osv. Hvor godt et AI-system kan håndtere et bredt spekter av forhold pålitelig og sikkert, reflekterer nivået av forberedelse dataforskeren eller AI-utvikleren har vurdert under design eller testing av systemet.
Inkludering
AI-systemer bør designes for å engasjere og styrke alle. Når dataforskere og AI-utviklere designer og implementerer AI-systemer, identifiserer og adresserer de potensielle barrierer i systemet som utilsiktet kan ekskludere mennesker. For eksempel finnes det 1 milliard mennesker med funksjonshemminger over hele verden. Med fremskritt innen AI kan de lettere få tilgang til et bredt spekter av informasjon og muligheter i hverdagen. Ved å adressere barrierene skapes det muligheter for å innovere og utvikle AI-produkter med bedre opplevelser som gagner alle.
Sikkerhet og personvern
AI-systemer bør være trygge og respektere folks personvern. Folk har mindre tillit til systemer som setter deres personvern, informasjon eller liv i fare. Når vi trener maskinlæringsmodeller, er vi avhengige av data for å oppnå de beste resultatene. I denne prosessen må vi vurdere opprinnelsen til dataene og deres integritet. For eksempel, ble dataene sendt inn av brukere eller var de offentlig tilgjengelige? Videre, mens vi arbeider med dataene, er det avgjørende å utvikle AI-systemer som kan beskytte konfidensiell informasjon og motstå angrep. Etter hvert som AI blir mer utbredt, blir det stadig viktigere og mer komplekst å beskytte personvern og sikre viktig personlig og forretningsmessig informasjon. Personvern og datasikkerhet krever spesielt nøye oppmerksomhet for AI, fordi tilgang til data er essensielt for at AI-systemer skal kunne gi nøyaktige og informerte prediksjoner og beslutninger om mennesker.
- Som bransje har vi gjort betydelige fremskritt innen personvern og sikkerhet, drevet i stor grad av reguleringer som GDPR (General Data Protection Regulation).
- Likevel må vi med AI-systemer erkjenne spenningen mellom behovet for mer personlige data for å gjøre systemer mer personlige og effektive – og personvern.
- Akkurat som med fremveksten av tilkoblede datamaskiner via internett, ser vi også en stor økning i antall sikkerhetsproblemer relatert til AI.
- Samtidig har vi sett AI bli brukt til å forbedre sikkerhet. For eksempel drives de fleste moderne antivirusprogrammer i dag av AI-heuristikk.
- Vi må sørge for at våre dataforskningsprosesser harmonerer med de nyeste praksisene for personvern og sikkerhet.
Åpenhet
AI-systemer bør være forståelige. En viktig del av åpenhet er å forklare oppførselen til AI-systemer og deres komponenter. Forbedring av forståelsen av AI-systemer krever at interessenter forstår hvordan og hvorfor de fungerer, slik at de kan identifisere potensielle ytelsesproblemer, sikkerhets- og personvernhensyn, skjevheter, ekskluderende praksis eller utilsiktede utfall. Vi mener også at de som bruker AI-systemer, bør være ærlige og åpne om når, hvorfor og hvordan de velger å bruke dem, samt begrensningene til systemene de bruker. For eksempel, hvis en bank bruker et AI-system for å støtte sine utlånsbeslutninger, er det viktig å undersøke resultatene og forstå hvilke data som påvirker systemets anbefalinger. Regjeringer begynner å regulere AI på tvers av bransjer, så dataforskere og organisasjoner må forklare om et AI-system oppfyller regulatoriske krav, spesielt når det oppstår et uønsket utfall.
- Fordi AI-systemer er så komplekse, er det vanskelig å forstå hvordan de fungerer og tolke resultatene.
- Denne mangelen på forståelse påvirker hvordan disse systemene administreres, operasjonaliseres og dokumenteres.
- Enda viktigere påvirker denne mangelen på forståelse beslutningene som tas basert på resultatene disse systemene produserer.
Ansvarlighet
De som designer og implementerer AI-systemer, må være ansvarlige for hvordan systemene deres fungerer. Behovet for ansvarlighet er spesielt viktig for sensitive teknologier som ansiktsgjenkjenning. Nylig har det vært en økende etterspørsel etter ansiktsgjenkjenningsteknologi, spesielt fra rettshåndhevelsesorganisasjoner som ser potensialet i teknologien for bruk som å finne savnede barn. Imidlertid kan disse teknologiene potensielt brukes av en regjering til å sette borgernes grunnleggende friheter i fare, for eksempel ved å muliggjøre kontinuerlig overvåking av spesifikke individer. Derfor må dataforskere og organisasjoner være ansvarlige for hvordan deres AI-system påvirker enkeltpersoner eller samfunnet.
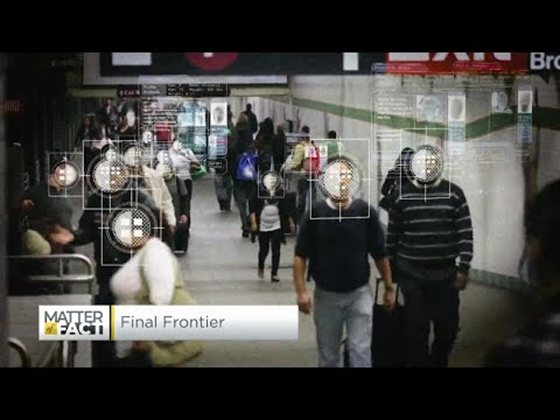
🎥 Klikk på bildet over for en video: Advarsler om masseovervåking gjennom ansiktsgjenkjenning
Til syvende og sist er et av de største spørsmålene for vår generasjon, som den første generasjonen som bringer AI til samfunnet, hvordan vi kan sikre at datamaskiner forblir ansvarlige overfor mennesker, og hvordan vi kan sikre at de som designer datamaskiner, forblir ansvarlige overfor alle andre.
Konsekvensvurdering
Før du trener en maskinlæringsmodell, er det viktig å gjennomføre en konsekvensvurdering for å forstå formålet med AI-systemet; hva den tiltenkte bruken er; hvor det vil bli implementert; og hvem som vil samhandle med systemet. Dette er nyttig for vurderere eller testere som evaluerer systemet for å vite hvilke faktorer de skal ta hensyn til når de identifiserer potensielle risikoer og forventede konsekvenser.
Følgende er fokusområder når du gjennomfører en konsekvensvurdering:
- Negative konsekvenser for enkeltpersoner. Å være klar over eventuelle begrensninger eller krav, ikke-støttet bruk eller kjente begrensninger som hindrer systemets ytelse, er avgjørende for å sikre at systemet ikke brukes på en måte som kan skade enkeltpersoner.
- Datakrav. Å forstå hvordan og hvor systemet vil bruke data, gjør det mulig for vurderere å utforske eventuelle datakrav du må være oppmerksom på (f.eks. GDPR eller HIPAA-reguleringer). I tillegg bør du undersøke om kilden eller mengden av data er tilstrekkelig for trening.
- Oppsummering av konsekvenser. Samle en liste over potensielle skader som kan oppstå ved bruk av systemet. Gjennom hele ML-livssyklusen bør du vurdere om de identifiserte problemene er adressert eller redusert.
- Gjeldende mål for hver av de seks kjerneprinsippene. Vurder om målene fra hvert prinsipp er oppfylt, og om det er noen mangler.
Feilsøking med ansvarlig AI
Akkurat som med feilsøking av en programvareapplikasjon, er feilsøking av et AI-system en nødvendig prosess for å identifisere og løse problemer i systemet. Det er mange faktorer som kan påvirke at en modell ikke presterer som forventet eller ansvarlig. De fleste tradisjonelle modellytelsesmålinger er kvantitative aggregater av en modells ytelse, som ikke er tilstrekkelige for å analysere hvordan en modell bryter med prinsippene for ansvarlig AI. Videre er en maskinlæringsmodell en "svart boks" som gjør det vanskelig å forstå hva som driver dens utfall eller forklare hvorfor den gjør feil. Senere i dette kurset vil vi lære hvordan vi bruker Responsible AI-dashbordet for å hjelpe med feilsøking av AI-systemer. Dashbordet gir et helhetlig verktøy for dataforskere og AI-utviklere til å utføre:
- Feilanalyse. For å identifisere feilfordelingen i modellen som kan påvirke systemets rettferdighet eller pålitelighet.
- Modelloversikt. For å oppdage hvor det er ulikheter i modellens ytelse på tvers av datakohorter.
- Dataanalyse. For å forstå datadistribusjonen og identifisere potensielle skjevheter i dataene som kan føre til problemer med rettferdighet, inkludering og pålitelighet.
- Modellfortolkning. For å forstå hva som påvirker eller driver modellens prediksjoner. Dette hjelper med å forklare modellens oppførsel, som er viktig for åpenhet og ansvarlighet.
🚀 Utfordring
For å forhindre at skader introduseres i utgangspunktet, bør vi:
- ha et mangfold av bakgrunner og perspektiver blant de som jobber med systemer
- investere i datasett som reflekterer mangfoldet i samfunnet vårt
- utvikle bedre metoder gjennom hele maskinlæringslivssyklusen for å oppdage og korrigere ansvarlig AI når det oppstår
Tenk på virkelige scenarier der en modells upålitelighet er tydelig i modellbygging og bruk. Hva annet bør vi vurdere?
Quiz etter forelesning
Gjennomgang og selvstudium
I denne leksjonen har du lært noen grunnleggende konsepter om rettferdighet og urettferdighet i maskinlæring. Se denne workshopen for å fordype deg i temaene:
- På jakt etter ansvarlig AI: Fra prinsipper til praksis av Besmira Nushi, Mehrnoosh Sameki og Amit Sharma

🎥 Klikk på bildet over for en video: RAI Toolbox: En åpen kildekode-rammeverk for å bygge ansvarlig AI av Besmira Nushi, Mehrnoosh Sameki og Amit Sharma
Les også:
-
Microsofts RAI ressursenter: Responsible AI Resources – Microsoft AI
-
Microsofts FATE forskningsgruppe: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Les om Azure Machine Learning sine verktøy for å sikre rettferdighet:
Oppgave
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi tilstreber nøyaktighet, vennligst vær oppmerksom på at automatiske oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for eventuelle misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.