12 KiB
Historien om maskinlæring
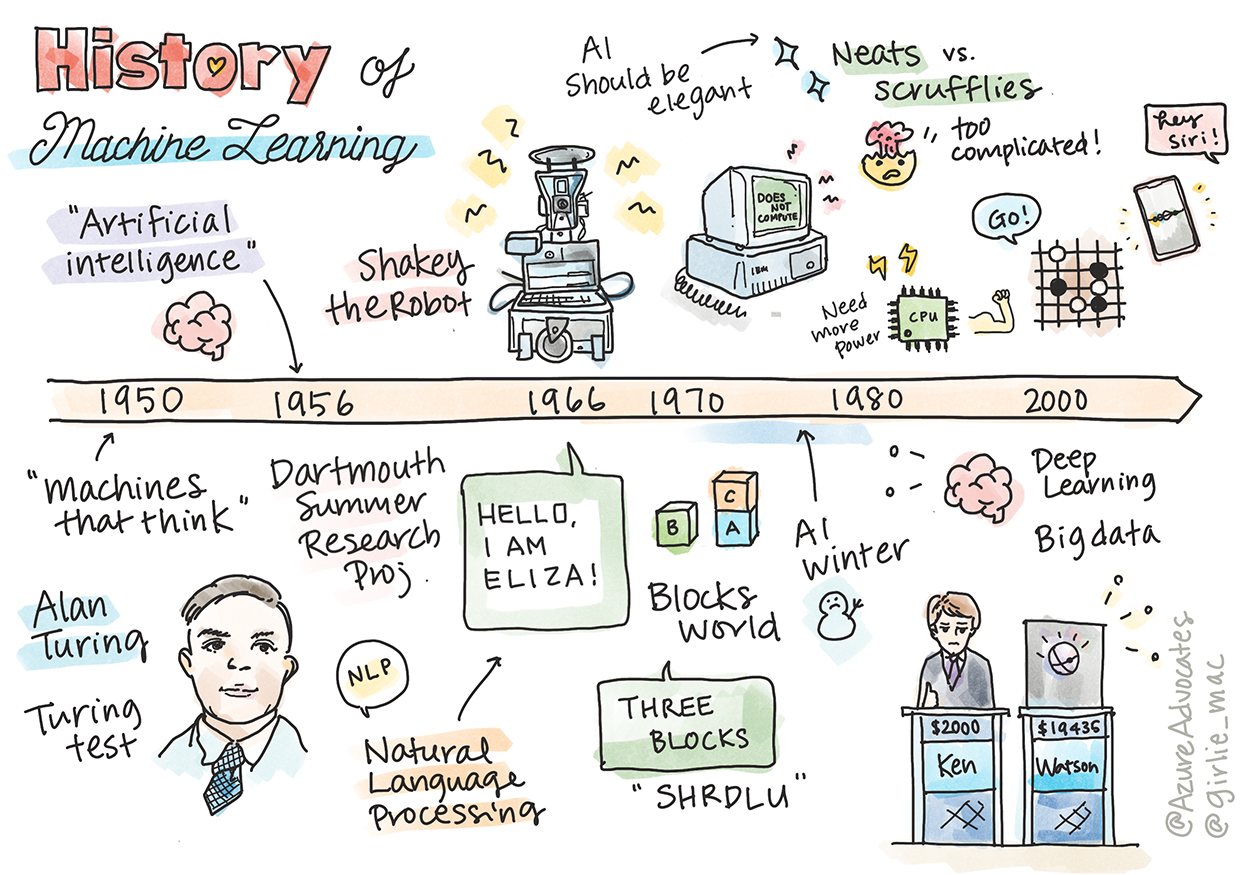
Sketchnote av Tomomi Imura
Quiz før forelesning

🎥 Klikk på bildet over for en kort video som går gjennom denne leksjonen.
I denne leksjonen skal vi gå gjennom de viktigste milepælene i historien om maskinlæring og kunstig intelligens.
Historien om kunstig intelligens (AI) som et fagfelt er nært knyttet til historien om maskinlæring, ettersom algoritmene og de teknologiske fremskrittene som ligger til grunn for ML har bidratt til utviklingen av AI. Det er nyttig å huske at selv om disse feltene som separate forskningsområder begynte å ta form på 1950-tallet, så fantes det viktige algoritmiske, statistiske, matematiske, teknologiske og tekniske oppdagelser som både gikk forut for og overlappet denne perioden. Faktisk har mennesker tenkt på disse spørsmålene i hundrevis av år: denne artikkelen diskuterer de historiske intellektuelle grunnlagene for ideen om en 'tenkende maskin.'
Viktige oppdagelser
- 1763, 1812 Bayes' teorem og dets forgjengere. Dette teoremet og dets anvendelser ligger til grunn for inferens og beskriver sannsynligheten for at en hendelse inntreffer basert på tidligere kunnskap.
- 1805 Minste kvadraters metode av den franske matematikeren Adrien-Marie Legendre. Denne teorien, som du vil lære om i vår enhet om regresjon, hjelper med datafitting.
- 1913 Markov-kjeder, oppkalt etter den russiske matematikeren Andrey Markov, brukes til å beskrive en sekvens av mulige hendelser basert på en tidligere tilstand.
- 1957 Perceptron er en type lineær klassifikator oppfunnet av den amerikanske psykologen Frank Rosenblatt som ligger til grunn for fremskritt innen dyp læring.
- 1967 Nærmeste nabo er en algoritme opprinnelig designet for å kartlegge ruter. I en ML-kontekst brukes den til å oppdage mønstre.
- 1970 Backpropagation brukes til å trene feedforward-nevrale nettverk.
- 1982 Rekurrente nevrale nettverk er kunstige nevrale nettverk avledet fra feedforward-nevrale nettverk som skaper temporale grafer.
✅ Gjør litt research. Hvilke andre datoer skiller seg ut som avgjørende i historien om ML og AI?
1950: Maskiner som tenker
Alan Turing, en virkelig bemerkelsesverdig person som ble kåret av publikum i 2019 til den største vitenskapsmannen i det 20. århundre, er kreditert for å ha bidratt til å legge grunnlaget for konseptet om en 'maskin som kan tenke.' Han tok opp kampen med skeptikere og sitt eget behov for empirisk bevis for dette konseptet, blant annet ved å skape Turing-testen, som du vil utforske i våre NLP-leksjoner.
1956: Dartmouth Summer Research Project
"Dartmouth Summer Research Project on artificial intelligence var en banebrytende begivenhet for kunstig intelligens som et fagfelt," og det var her begrepet 'kunstig intelligens' ble introdusert (kilde).
Hvert aspekt av læring eller enhver annen egenskap ved intelligens kan i prinsippet beskrives så presist at en maskin kan lages for å simulere det.
Lederforskeren, matematikkprofessor John McCarthy, håpet "å gå videre basert på antagelsen om at hvert aspekt av læring eller enhver annen egenskap ved intelligens kan i prinsippet beskrives så presist at en maskin kan lages for å simulere det." Deltakerne inkluderte en annen pioner innen feltet, Marvin Minsky.
Workshoppen er kreditert for å ha initiert og oppmuntret til flere diskusjoner, inkludert "fremveksten av symbolske metoder, systemer fokusert på begrensede domener (tidlige ekspert-systemer), og deduktive systemer versus induktive systemer." (kilde).
1956 - 1974: "De gylne årene"
Fra 1950-tallet til midten av 70-tallet var optimismen høy med håp om at AI kunne løse mange problemer. I 1967 uttalte Marvin Minsky selvsikkert at "Innen en generasjon ... vil problemet med å skape 'kunstig intelligens' i stor grad være løst." (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)
Forskning på naturlig språkprosessering blomstret, søk ble raffinert og gjort mer kraftfullt, og konseptet med 'mikroverdener' ble skapt, hvor enkle oppgaver ble utført ved hjelp av instruksjoner i vanlig språk.
Forskning ble godt finansiert av statlige organer, fremskritt ble gjort innen beregning og algoritmer, og prototyper av intelligente maskiner ble bygget. Noen av disse maskinene inkluderer:
-
Shakey-roboten, som kunne manøvrere og bestemme hvordan oppgaver skulle utføres 'intelligent'.

Shakey i 1972
-
Eliza, en tidlig 'chatterbot', kunne samtale med mennesker og fungere som en primitiv 'terapeut'. Du vil lære mer om Eliza i NLP-leksjonene.
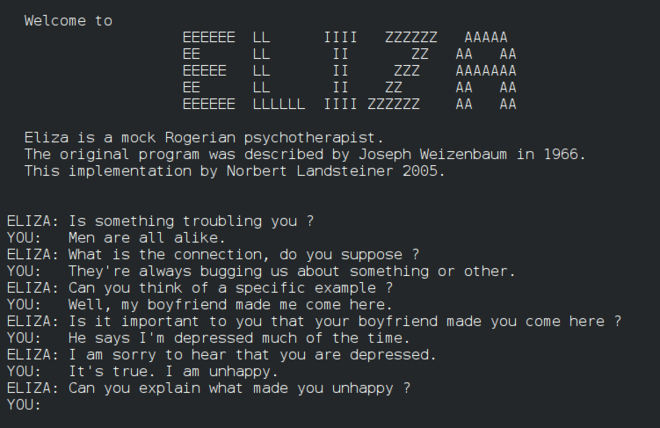
En versjon av Eliza, en chatbot
-
"Blocks world" var et eksempel på en mikroverden hvor blokker kunne stables og sorteres, og eksperimenter med å lære maskiner å ta beslutninger kunne testes. Fremskritt bygget med biblioteker som SHRDLU hjalp til med å drive språkprosessering fremover.

🎥 Klikk på bildet over for en video: Blocks world med SHRDLU
1974 - 1980: "AI-vinter"
På midten av 1970-tallet ble det klart at kompleksiteten ved å lage 'intelligente maskiner' hadde blitt undervurdert og at løftene, gitt den tilgjengelige beregningskraften, hadde blitt overdrevet. Finansiering tørket opp, og tilliten til feltet avtok. Noen problemer som påvirket tilliten inkluderte:
- Begrensninger. Beregningskraften var for begrenset.
- Kombinatorisk eksplosjon. Antallet parametere som måtte trenes vokste eksponentielt etter hvert som mer ble forventet av datamaskiner, uten en parallell utvikling av beregningskraft og kapasitet.
- Mangel på data. Det var mangel på data som hindret prosessen med å teste, utvikle og forbedre algoritmer.
- Spør vi de riktige spørsmålene?. Selve spørsmålene som ble stilt begynte å bli stilt spørsmål ved. Forskere begynte å møte kritikk for sine tilnærminger:
- Turing-tester ble utfordret, blant annet gjennom 'kinesisk rom-teorien' som hevdet at "programmering av en digital datamaskin kan få den til å fremstå som om den forstår språk, men kunne ikke produsere ekte forståelse." (kilde)
- Etikken ved å introdusere kunstige intelligenser som "terapeuten" ELIZA i samfunnet ble utfordret.
Samtidig begynte ulike AI-skoler å dannes. En dikotomi ble etablert mellom "scruffy" vs. "neat AI"-praksiser. Scruffy-laboratorier justerte programmer i timevis til de oppnådde ønskede resultater. Neat-laboratorier "fokuserte på logikk og formell problemløsning". ELIZA og SHRDLU var velkjente scruffy-systemer. På 1980-tallet, da etterspørselen etter å gjøre ML-systemer reproduserbare økte, tok neat-tilnærmingen gradvis ledelsen ettersom dens resultater er mer forklarbare.
1980-tallet: Ekspertsystemer
Etter hvert som feltet vokste, ble dets nytte for næringslivet tydeligere, og på 1980-tallet økte også spredningen av 'ekspertsystemer'. "Ekspertsystemer var blant de første virkelig vellykkede formene for kunstig intelligens (AI)-programvare." (kilde).
Denne typen system er faktisk hybrid, bestående delvis av en regelmotor som definerer forretningskrav, og en inferensmotor som utnyttet reglesystemet for å utlede nye fakta.
Denne perioden så også økende oppmerksomhet rettet mot nevrale nettverk.
1987 - 1993: AI 'Chill'
Spredningen av spesialisert maskinvare for ekspertsystemer hadde den uheldige effekten av å bli for spesialisert. Fremveksten av personlige datamaskiner konkurrerte også med disse store, spesialiserte, sentraliserte systemene. Demokratifiseringen av databehandling hadde begynt, og den banet til slutt vei for den moderne eksplosjonen av big data.
1993 - 2011
Denne epoken markerte en ny æra for ML og AI, hvor noen av problemene som tidligere hadde vært forårsaket av mangel på data og beregningskraft kunne løses. Mengden data begynte å øke raskt og bli mer tilgjengelig, på godt og vondt, spesielt med introduksjonen av smarttelefonen rundt 2007. Beregningskraften utvidet seg eksponentielt, og algoritmer utviklet seg parallelt. Feltet begynte å modnes etter hvert som de frie og eksperimentelle dagene fra fortiden begynte å krystallisere seg til en ekte disiplin.
Nå
I dag berører maskinlæring og AI nesten alle deler av livene våre. Denne perioden krever nøye forståelse av risikoene og de potensielle effektene av disse algoritmene på menneskeliv. Som Microsofts Brad Smith har uttalt: "Informasjonsteknologi reiser spørsmål som går til kjernen av grunnleggende menneskerettighetsbeskyttelser som personvern og ytringsfrihet. Disse spørsmålene øker ansvaret for teknologiselskaper som skaper disse produktene. Etter vår mening krever de også gjennomtenkt statlig regulering og utvikling av normer rundt akseptabel bruk" (kilde).
Det gjenstår å se hva fremtiden bringer, men det er viktig å forstå disse datasystemene og programvaren og algoritmene de kjører. Vi håper at dette pensumet vil hjelpe deg med å få en bedre forståelse slik at du kan ta dine egne beslutninger.

🎥 Klikk på bildet over for en video: Yann LeCun diskuterer historien om dyp læring i denne forelesningen
🚀Utfordring
Fordyp deg i et av disse historiske øyeblikkene og lær mer om menneskene bak dem. Det finnes fascinerende karakterer, og ingen vitenskapelig oppdagelse ble noen gang skapt i et kulturelt vakuum. Hva oppdager du?
Quiz etter forelesning
Gjennomgang og selvstudium
Her er ting du kan se og lytte til:
Denne podcasten hvor Amy Boyd diskuterer utviklingen av AI

Oppgave
Ansvarsfraskrivelse:
Dette dokumentet er oversatt ved hjelp av AI-oversettelsestjenesten Co-op Translator. Selv om vi streber etter nøyaktighet, vær oppmerksom på at automatiserte oversettelser kan inneholde feil eller unøyaktigheter. Det originale dokumentet på sitt opprinnelige språk bør anses som den autoritative kilden. For kritisk informasjon anbefales profesjonell menneskelig oversettelse. Vi er ikke ansvarlige for eventuelle misforståelser eller feiltolkninger som oppstår ved bruk av denne oversettelsen.