13 KiB
Geschiedenis van machine learning
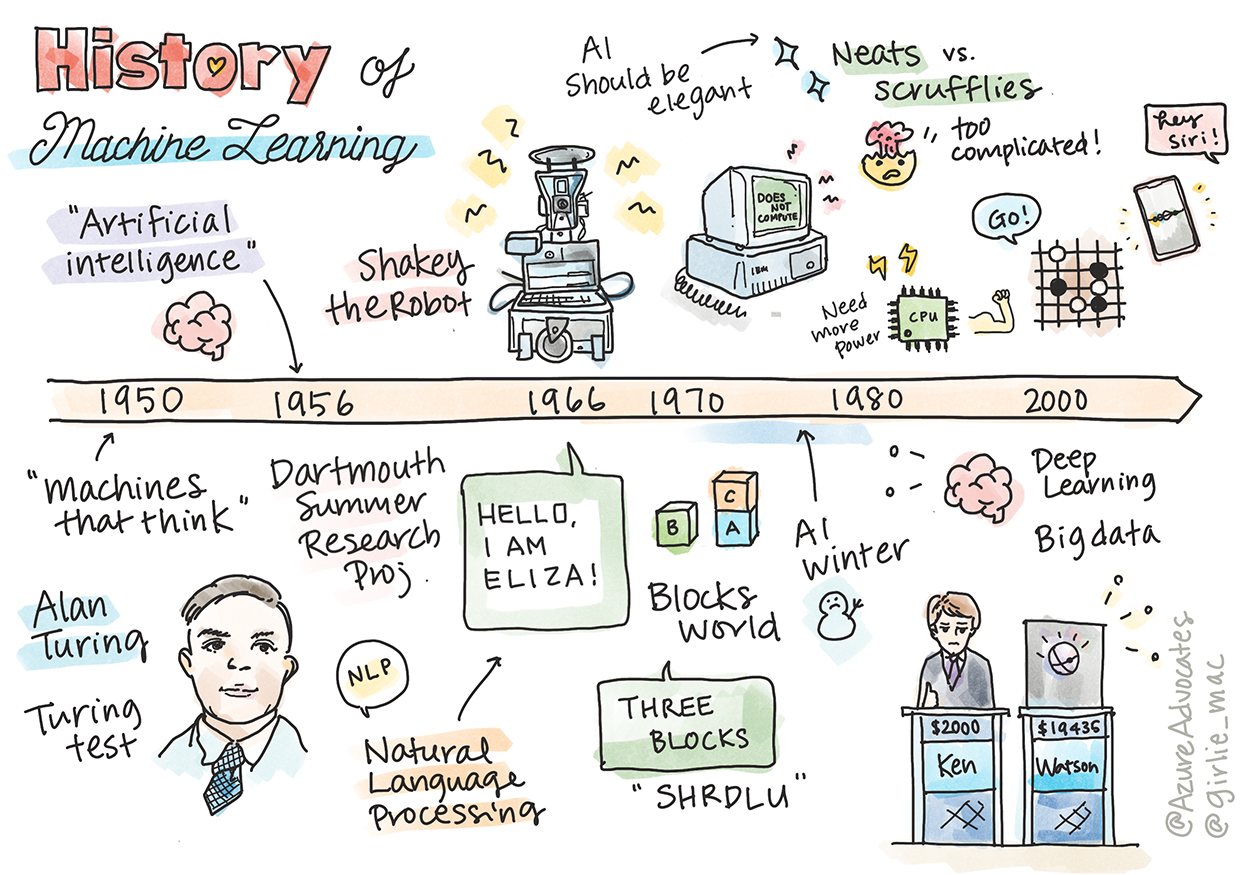
Sketchnote door Tomomi Imura
Quiz voorafgaand aan de les

🎥 Klik op de afbeelding hierboven voor een korte video over deze les.
In deze les lopen we door de belangrijkste mijlpalen in de geschiedenis van machine learning en kunstmatige intelligentie.
De geschiedenis van kunstmatige intelligentie (AI) als vakgebied is nauw verweven met de geschiedenis van machine learning, omdat de algoritmen en computationele vooruitgangen die ML ondersteunen hebben bijgedragen aan de ontwikkeling van AI. Het is nuttig om te onthouden dat, hoewel deze vakgebieden als afzonderlijke onderzoeksgebieden in de jaren 1950 begonnen te kristalliseren, belangrijke algoritmische, statistische, wiskundige, computationele en technische ontdekkingen voorafgingen aan en overlapten met deze periode. Mensen denken zelfs al honderden jaren na over deze vragen: dit artikel bespreekt de historische intellectuele basis van het idee van een 'denkende machine.'
Belangrijke ontdekkingen
- 1763, 1812 Bayesiaanse stelling en zijn voorlopers. Deze stelling en de toepassingen ervan vormen de basis van inferentie en beschrijven de kans dat een gebeurtenis plaatsvindt op basis van eerdere kennis.
- 1805 Least Square Theory door de Franse wiskundige Adrien-Marie Legendre. Deze theorie, die je zult leren in onze regressie-eenheid, helpt bij het aanpassen van data.
- 1913 Markovketens, genoemd naar de Russische wiskundige Andrey Markov, worden gebruikt om een reeks mogelijke gebeurtenissen te beschrijven op basis van een vorige toestand.
- 1957 Perceptron is een type lineaire classifier uitgevonden door de Amerikaanse psycholoog Frank Rosenblatt, die de basis vormt voor vooruitgangen in deep learning.
- 1967 Nearest Neighbor is een algoritme dat oorspronkelijk is ontworpen om routes in kaart te brengen. In een ML-context wordt het gebruikt om patronen te detecteren.
- 1970 Backpropagation wordt gebruikt om feedforward neural networks te trainen.
- 1982 Recurrent Neural Networks zijn kunstmatige neurale netwerken afgeleid van feedforward neurale netwerken die temporele grafieken creëren.
✅ Doe wat onderzoek. Welke andere data springen eruit als cruciaal in de geschiedenis van ML en AI?
1950: Machines die denken
Alan Turing, een werkelijk opmerkelijk persoon die door het publiek in 2019 werd verkozen tot de grootste wetenschapper van de 20e eeuw, wordt gecrediteerd met het helpen leggen van de basis voor het concept van een 'machine die kan denken.' Hij worstelde met sceptici en zijn eigen behoefte aan empirisch bewijs van dit concept, onder andere door het creëren van de Turingtest, die je zult verkennen in onze NLP-lessen.
1956: Dartmouth Summer Research Project
"Het Dartmouth Summer Research Project over kunstmatige intelligentie was een baanbrekende gebeurtenis voor kunstmatige intelligentie als vakgebied," en hier werd de term 'kunstmatige intelligentie' bedacht (bron).
Elk aspect van leren of een ander kenmerk van intelligentie kan in principe zo precies worden beschreven dat een machine kan worden gemaakt om het te simuleren.
De hoofdonderzoeker, wiskundeprofessor John McCarthy, hoopte "voort te gaan op basis van de veronderstelling dat elk aspect van leren of een ander kenmerk van intelligentie in principe zo precies kan worden beschreven dat een machine kan worden gemaakt om het te simuleren." De deelnemers omvatten een andere grootheid in het veld, Marvin Minsky.
De workshop wordt gecrediteerd met het initiëren en aanmoedigen van verschillende discussies, waaronder "de opkomst van symbolische methoden, systemen gericht op beperkte domeinen (vroege expertsystemen), en deductieve systemen versus inductieve systemen." (bron).
1956 - 1974: "De gouden jaren"
Van de jaren 1950 tot halverwege de jaren '70 was er veel optimisme over de hoop dat AI veel problemen kon oplossen. In 1967 verklaarde Marvin Minsky vol vertrouwen: "Binnen een generatie ... zal het probleem van het creëren van 'kunstmatige intelligentie' substantieel zijn opgelost." (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)
Onderzoek naar natuurlijke taalverwerking bloeide, zoekmethoden werden verfijnd en krachtiger gemaakt, en het concept van 'micro-werelden' werd gecreëerd, waar eenvoudige taken werden uitgevoerd met behulp van eenvoudige taalopdrachten.
Onderzoek werd goed gefinancierd door overheidsinstanties, vooruitgangen werden geboekt in computation en algoritmen, en prototypes van intelligente machines werden gebouwd. Enkele van deze machines zijn:
-
Shakey de robot, die kon manoeuvreren en beslissen hoe taken 'intelligent' moesten worden uitgevoerd.

Shakey in 1972
-
Eliza, een vroege 'chatterbot', kon met mensen praten en fungeren als een primitieve 'therapeut'. Je leert meer over Eliza in de NLP-lessen.
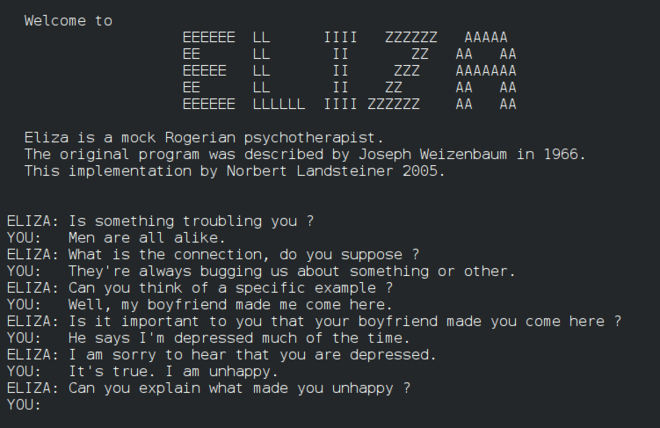
Een versie van Eliza, een chatbot
-
"Blocks world" was een voorbeeld van een micro-wereld waar blokken konden worden gestapeld en gesorteerd, en experimenten in het leren van machines om beslissingen te nemen konden worden getest. Vooruitgangen gebouwd met bibliotheken zoals SHRDLU hielpen de taalverwerking vooruit te stuwen.

🎥 Klik op de afbeelding hierboven voor een video: Blocks world met SHRDLU
1974 - 1980: "AI Winter"
Halverwege de jaren '70 werd duidelijk dat de complexiteit van het maken van 'intelligente machines' was onderschat en dat de belofte ervan, gezien de beschikbare rekenkracht, was overdreven. Financiering droogde op en het vertrouwen in het veld nam af. Enkele problemen die het vertrouwen beïnvloedden waren:
- Beperkingen. De rekenkracht was te beperkt.
- Combinatorische explosie. Het aantal parameters dat moest worden getraind groeide exponentieel naarmate er meer van computers werd gevraagd, zonder een parallelle evolutie van rekenkracht en capaciteit.
- Gebrek aan data. Er was een gebrek aan data dat het proces van testen, ontwikkelen en verfijnen van algoritmen hinderde.
- Stellen we de juiste vragen?. De vragen die werden gesteld begonnen zelf ter discussie te staan. Onderzoekers kregen kritiek op hun benaderingen:
- Turingtests werden in twijfel getrokken door middel van onder andere de 'Chinese kamer theorie', die stelde dat "het programmeren van een digitale computer het misschien kan laten lijken alsof het taal begrijpt, maar geen echte begrip kan produceren." (bron)
- De ethiek van het introduceren van kunstmatige intelligenties zoals de "therapeut" ELIZA in de samenleving werd uitgedaagd.
Tegelijkertijd begonnen verschillende AI-denkrichtingen te ontstaan. Er werd een dichotomie vastgesteld tussen "scruffy" vs. "neat AI" praktijken. Scruffy labs pasten programma's urenlang aan totdat ze het gewenste resultaat hadden. Neat labs "richtten zich op logica en formele probleemoplossing". ELIZA en SHRDLU waren bekende scruffy systemen. In de jaren '80, toen de vraag ontstond om ML-systemen reproduceerbaar te maken, nam de neat benadering geleidelijk de voorgrond omdat de resultaten ervan beter uitlegbaar zijn.
1980s Expertsystemen
Naarmate het veld groeide, werd het voordeel ervan voor bedrijven duidelijker, en in de jaren '80 nam ook de proliferatie van 'expertsystemen' toe. "Expertsystemen waren een van de eerste echt succesvolle vormen van kunstmatige intelligentie (AI) software." (bron).
Dit type systeem is eigenlijk hybride, bestaande gedeeltelijk uit een regelsysteem dat bedrijfsvereisten definieert, en een inferentie-engine die het regelsysteem gebruikt om nieuwe feiten af te leiden.
Deze periode zag ook toenemende aandacht voor neurale netwerken.
1987 - 1993: AI 'Chill'
De proliferatie van gespecialiseerde hardware voor expertsystemen had het ongelukkige effect dat het te gespecialiseerd werd. De opkomst van personal computers concurreerde ook met deze grote, gespecialiseerde, gecentraliseerde systemen. De democratisering van computing was begonnen, en het effende uiteindelijk de weg voor de moderne explosie van big data.
1993 - 2011
Deze periode zag een nieuw tijdperk voor ML en AI om enkele van de problemen op te lossen die eerder waren veroorzaakt door het gebrek aan data en rekenkracht. De hoeveelheid data begon snel toe te nemen en breder beschikbaar te worden, zowel ten goede als ten kwade, vooral met de komst van de smartphone rond 2007. Rekenkracht breidde exponentieel uit, en algoritmen evolueerden mee. Het veld begon volwassen te worden naarmate de vrije dagen van het verleden begonnen te kristalliseren in een echte discipline.
Nu
Vandaag de dag raken machine learning en AI bijna elk aspect van ons leven. Dit tijdperk vraagt om een zorgvuldige begrip van de risico's en potentiële effecten van deze algoritmen op mensenlevens. Zoals Microsoft's Brad Smith heeft verklaard: "Informatietechnologie roept kwesties op die raken aan de kern van fundamentele mensenrechtenbescherming zoals privacy en vrijheid van meningsuiting. Deze kwesties vergroten de verantwoordelijkheid voor technologiebedrijven die deze producten creëren. Naar onze mening vragen ze ook om doordachte overheidsregulering en de ontwikkeling van normen rond acceptabel gebruik" (bron).
Het blijft afwachten wat de toekomst brengt, maar het is belangrijk om deze computersystemen en de software en algoritmen die ze draaien te begrijpen. We hopen dat dit curriculum je zal helpen om een beter begrip te krijgen zodat je zelf kunt beslissen.

🎥 Klik op de afbeelding hierboven voor een video: Yann LeCun bespreekt de geschiedenis van deep learning in deze lezing
🚀Uitdaging
Duik in een van deze historische momenten en leer meer over de mensen erachter. Er zijn fascinerende personages, en geen enkele wetenschappelijke ontdekking is ooit in een culturele vacuüm gecreëerd. Wat ontdek je?
Quiz na de les
Review & Zelfstudie
Hier zijn items om te bekijken en te beluisteren:
Deze podcast waarin Amy Boyd de evolutie van AI bespreekt

Opdracht
Disclaimer:
Dit document is vertaald met behulp van de AI-vertalingsservice Co-op Translator. Hoewel we streven naar nauwkeurigheid, dient u zich ervan bewust te zijn dat geautomatiseerde vertalingen fouten of onnauwkeurigheden kunnen bevatten. Het originele document in zijn oorspronkelijke taal moet worden beschouwd als de gezaghebbende bron. Voor cruciale informatie wordt professionele menselijke vertaling aanbevolen. Wij zijn niet aansprakelijk voor eventuele misverstanden of verkeerde interpretaties die voortvloeien uit het gebruik van deze vertaling.