23 KiB
စက်ရုပ်သင်ယူမှု၏ သမိုင်းကြောင်း
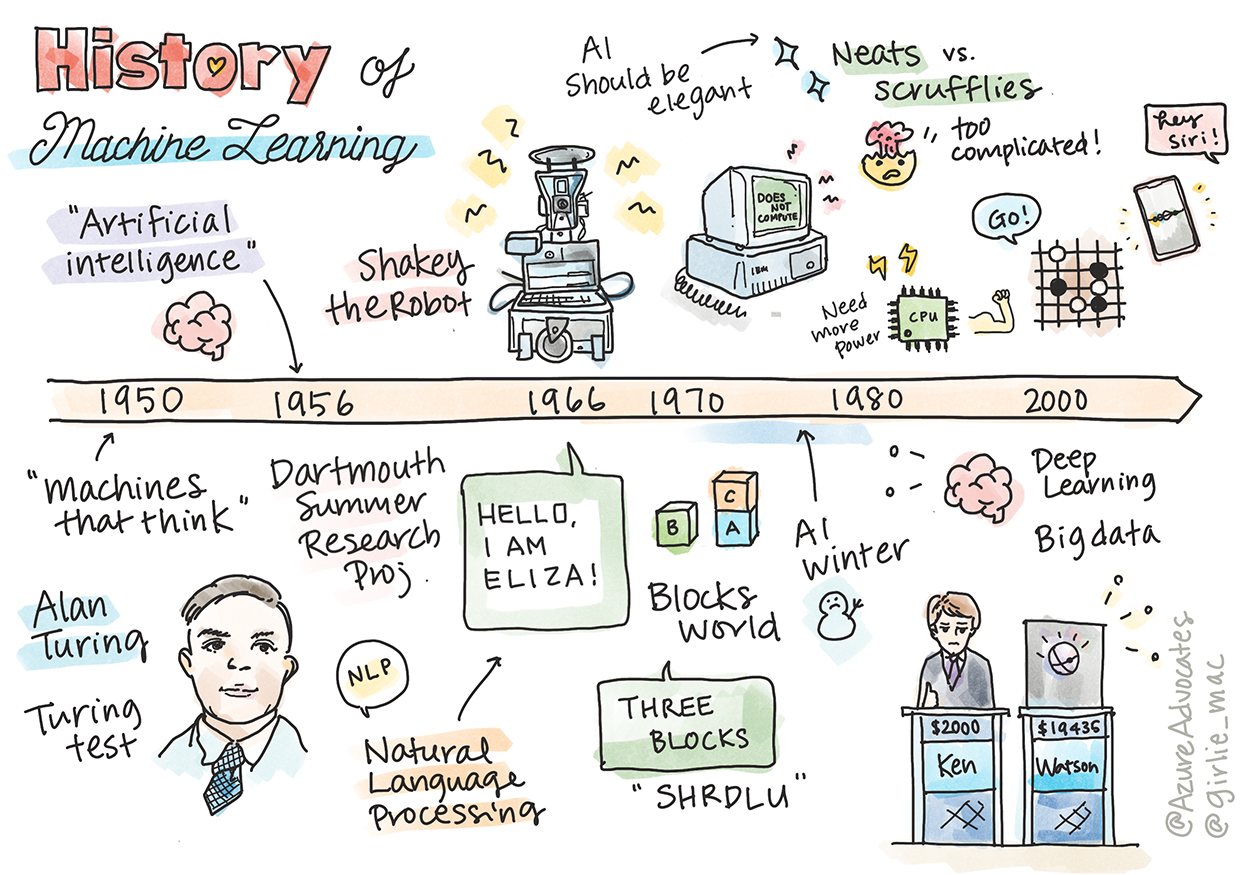
Sketchnote by Tomomi Imura
Pre-lecture quiz

🎥 အထက်ပါပုံကို နှိပ်ပြီး ဒီသင်ခန်းစာကို ရှင်းလင်းထားသော ဗီဒီယိုကို ကြည့်ပါ။
ဒီသင်ခန်းစာမှာ စက်ရုပ်သင်ယူမှုနှင့် အတုအမြင့်တုအာရုံ၏ သမိုင်းကြောင်းတွင် အရေးပါသော အခန်းကဏ္ဍများကို လေ့လာသွားပါမည်။
အတုအမြင့်တုအာရုံ (AI) ၏ သမိုင်းကြောင်းသည် စက်ရုပ်သင်ယူမှု၏ သမိုင်းကြောင်းနှင့် ဆက်စပ်နေပြီး ML ကို အခြေခံသော algorithm များနှင့် ကွန်ပျူတာတိုးတက်မှုများသည် AI ၏ ဖွံ့ဖြိုးတိုးတက်မှုကို အထောက်အကူပြုခဲ့သည်။ ဒီနယ်ပယ်များသည် 1950 ခုနှစ်များတွင် သီးခြားသော သုတေသနနယ်ပယ်များအဖြစ် ပုံသွင်းလာခဲ့သော်လည်း algorithm, statistical, mathematical, computational နှင့် technical discoveries များသည် ဒီကာလမတိုင်မီ ရှိခဲ့ပြီး အချို့ overlap ဖြစ်ခဲ့သည်။ အမှန်တကယ်တော့ လူသားများသည် ရာစုနှစ်များစွာ အတွင်း ဒီမေးခွန်းများကို စဉ်းစားခဲ့ကြသည်။ ဒီဆောင်းပါးသည် 'စဉ်းစားနိုင်သော စက်' ၏ အတွေးအမြင်၏ သမိုင်းဆိုင်ရာ အခြေခံအမြင်များကို ဆွေးနွေးထားသည်။
အရေးပါသော ရှာဖွေတွေ့ရှိမှုများ
- 1763, 1812 Bayes Theorem နှင့် ၎င်း၏ ရှေးဦးများ။ ဒီသီအိုရီသည် အကြိုသိရှိမှုအပေါ် အခြေခံပြီး ဖြစ်နိုင်ခြေကို ဖော်ပြသော inference ကို အခြေခံသည်။
- 1805 Least Square Theory ကို ပြင်သစ်ဂဏန်းသိပ္ပံပညာရှင် Adrien-Marie Legendre မှ တီထွင်ခဲ့သည်။ ဒီသီအိုရီကို Regression unit တွင် လေ့လာရမည်ဖြစ်ပြီး ဒေတာ fitting ကို အထောက်အကူပြုသည်။
- 1913 Markov Chains ကို ရုရှားဂဏန်းသိပ္ပံပညာရှင် Andrey Markov မှ တီထွင်ခဲ့ပြီး အခြေခံအခြေအနေအပေါ် အခြေခံသော ဖြစ်နိုင်သော အဖြစ်အပျက်များ၏ အစဉ်အလာကို ဖော်ပြသည်။
- 1957 Perceptron ကို အမေရိကန် စိတ်ပညာရှင် Frank Rosenblatt မှ တီထွင်ခဲ့ပြီး deep learning တိုးတက်မှုများ၏ အခြေခံဖြစ်သည်။
- 1967 Nearest Neighbor ကို route များကို map ပြုလုပ်ရန် အစတင်ဖန်တီးခဲ့သည်။ ML context တွင် pattern များကို ရှာဖွေဖော်ထုတ်ရန် အသုံးပြုသည်။
- 1970 Backpropagation ကို feedforward neural networks များကို training ပြုလုပ်ရန် အသုံးပြုသည်။
- 1982 Recurrent Neural Networks ကို feedforward neural networks မှ ဆင်းသက်လာပြီး အချိန်ဇယားများကို ဖန်တီးသည်။
✅ သုတေသနအနည်းငယ် ပြုလုပ်ပါ။ ML နှင့် AI ၏ သမိုင်းကြောင်းတွင် အရေးပါသော အခြားသော ရက်စွဲများကို ရှာဖွေပါ။
1950: စဉ်းစားနိုင်သော စက်များ
Alan Turing သည် 2019 ခုနှစ်တွင် လူထုမှ 20 ရာစု၏ အကြီးမားဆုံး သိပ္ပံပညာရှင်အဖြစ် မဲပေးရွေးချယ်ခံရသော ထူးချွန်သောပုဂ္ဂိုလ်ဖြစ်ပြီး 'စဉ်းစားနိုင်သော စက်' ၏ အခြေခံအမြင်ကို တည်ဆောက်ရန် အထောက်အကူပြုခဲ့သည်။ ၎င်းသည် Turing Test ကို ဖန်တီးခြင်းဖြင့် ဒီအမြင်ကို အတည်ပြုရန် ကြိုးစားခဲ့သည်။ Turing Test ကို NLP သင်ခန်းစာများတွင် လေ့လာရမည်။
1956: Dartmouth Summer Research Project
"Dartmouth Summer Research Project on artificial intelligence သည် အတုအမြင့်တုအာရုံနယ်ပယ်အတွက် အရေးပါသော အခန်းကဏ္ဍတစ်ခုဖြစ်ပြီး ဒီနေရာတွင် 'artificial intelligence' ဆိုသော စကားလုံးကို ပထမဆုံး အသုံးပြုခဲ့သည်။" (source)
သင်ယူမှု၏ အပိုင်းအစများ သို့မဟုတ် ဉာဏ်ရည်၏ အခြားသော လက္ခဏာများကို စက်တစ်ခုမှ simulation ပြုလုပ်နိုင်ရန် အလွန်တိကျစွာ ဖော်ပြနိုင်သည်။
ဦးဆောင်သုတေသနပညာရှင်ဖြစ်သော ဂဏန်းသိပ္ပံပညာရှင် John McCarthy သည် "သင်ယူမှု၏ အပိုင်းအစများ သို့မဟုတ် ဉာဏ်ရည်၏ အခြားသော လက္ခဏာများကို စက်တစ်ခုမှ simulation ပြုလုပ်နိုင်ရန် အလွန်တိကျစွာ ဖော်ပြနိုင်သည်" ဆိုသော အယူအဆအပေါ် အခြေခံ၍ ဆက်လက်လုပ်ဆောင်ရန် မျှော်လင့်ခဲ့သည်။ ၎င်း၏ ပါဝင်သူများတွင် Marvin Minsky ကဲ့သို့သော နယ်ပယ်၏ ထူးချွန်သောပုဂ္ဂိုလ်တစ်ဦးလည်း ပါဝင်ခဲ့သည်။
ဒီ workshop ကို "symbolic methods, limited domains (early expert systems), deductive systems နှင့် inductive systems" တိုးတက်မှုများကို စတင်ပြီး အားပေးခဲ့သည်ဟု သတ်မှတ်ထားသည်။ (source)
1956 - 1974: "ရွှေခေတ်"
1950 ခုနှစ်များမှ 1970 ခုနှစ်ဝန်းကျင်အထိ AI သည် အများပြည်သူ၏ ပြဿနာများကို ဖြေရှင်းနိုင်မည်ဟု မျှော်လင့်မှုများ အလွန်မြင့်မားခဲ့သည်။ 1967 ခုနှစ်တွင် Marvin Minsky သည် "တစ်မျိုးဆက်အတွင်း ... 'artificial intelligence' ဖန်တီးခြင်း၏ ပြဿနာကို အများအားဖြင့် ဖြေရှင်းနိုင်မည်" ဟု ယုံကြည်စွာ ပြောကြားခဲ့သည်။ (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)
natural language processing သုတေသနများ တိုးတက်မှုရှိခဲ့ပြီး ရှာဖွေမှုများကို ပိုမိုစွမ်းဆောင်နိုင်စေခဲ့သည်။ 'micro-worlds' ဆိုသော အတွေးအမြင်ကို ဖန်တီးခဲ့ပြီး ရိုးရှင်းသော လုပ်ငန်းများကို ရိုးရှင်းသော စကားလုံးများဖြင့် ပြုလုပ်နိုင်ခဲ့သည်။
သုတေသနများကို အစိုးရအေဂျင်စီများမှ ရန်ပုံငွေထောက်ပံ့ခဲ့ပြီး ကွန်ပျူတာနှင့် algorithm များတွင် တိုးတက်မှုများ ရှိခဲ့သည်။ ဉာဏ်ရည်ရှိသော စက်များ၏ prototype များကို ဖန်တီးခဲ့သည်။ ၎င်းတို့ထဲတွင် ပါဝင်သော စက်များမှာ -
-
Shakey the robot သည် လှုပ်ရှားနိုင်ပြီး 'ဉာဏ်ရည်ရှိ' လုပ်ငန်းများကို ဆုံးဖြတ်နိုင်သည်။

Shakey in 1972
-
Eliza သည် စောစောပိုင်း 'chatterbot' တစ်ခုဖြစ်ပြီး လူများနှင့် စကားပြောနိုင်သည်။ ၎င်းသည် primitive 'therapist' အဖြစ် လုပ်ဆောင်နိုင်သည်။ Eliza ကို NLP သင်ခန်းစာများတွင် ပိုမိုလေ့လာရမည်။
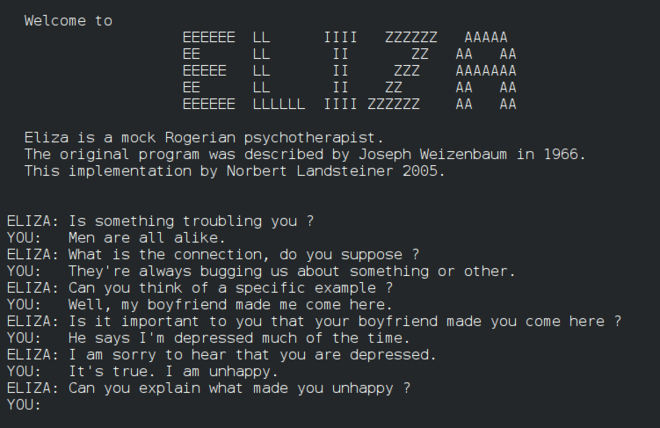
Eliza ၏ version တစ်ခု
-
"Blocks world" သည် blocks များကို စုစည်းခြင်းနှင့် စီမံခြင်းကို ပြုလုပ်နိုင်သော micro-world တစ်ခုဖြစ်ပြီး စက်များကို ဆုံးဖြတ်ချက်ချရန် သင်ကြားမှုများကို စမ်းသပ်နိုင်သည်။ SHRDLU ကဲ့သို့သော library များဖြင့် language processing ကို တိုးတက်စေခဲ့သည်။

🎥 အထက်ပါပုံကို နှိပ်ပြီး ဗီဒီယိုကြည့်ပါ: Blocks world with SHRDLU
1974 - 1980: "AI Winter"
1970 ခုနှစ်ဝန်းကျင်တွင် 'ဉာဏ်ရည်ရှိသော စက်' ဖန်တီးခြင်း၏ အခက်အခဲများကို အလွန်နည်းနည်းသာ သတ်မှတ်ထားသည်ဟု သိရှိလာခဲ့ပြီး compute power ရှိမှုအပေါ် အလွန်မြှင့်တင်ထားသည်ဟု သိရှိလာခဲ့သည်။ ရန်ပုံငွေများ လျော့နည်းလာခဲ့ပြီး နယ်ပယ်အပေါ် ယုံကြည်မှုများ လျော့နည်းလာခဲ့သည်။ ယုံကြည်မှုကို ထိခိုက်စေသော အချက်များမှာ -
- ကန့်သတ်ချက်များ။ Compute power သည် အလွန်နည်းပါးနေသည်။
- Combinatorial explosion။ စက်များကို ပိုမိုတိုးတက်စွမ်းဆောင်စေရန် training လိုအပ်သော parameters များသည် exponential အတိုင်း တိုးလာခဲ့သည်။
- ဒေတာနည်းပါးမှု။ ဒေတာနည်းပါးမှုသည် algorithm များကို စမ်းသပ်ခြင်း၊ ဖွံ့ဖြိုးတိုးတက်ခြင်းနှင့် ပြုပြင်ခြင်းကို အတားအဆီးဖြစ်စေခဲ့သည်။
- ကျွန်ုပ်တို့မှန်ကန်သောမေးခွန်းများကို မေးနေပါသလား?။ မေးခွန်းများကို မေးနေသော နည်းလမ်းများကို ပြန်လည်စဉ်းစားခဲ့သည်။
- Turing tests ကို 'chinese room theory' ကဲ့သို့သော အယူအဆများဖြင့် ပြန်လည်စဉ်းစားခဲ့သည်။ "digital computer ကို programming ပြုလုပ်ခြင်းသည် ဘာသာစကားကို နားလည်သည့်အတိုင်း ထင်ရစေသော်လည်း အမှန်တကယ် နားလည်မှုကို ဖန်တီးနိုင်မည်မဟုတ်ပါ။" (source)
- "therapist" ELIZA ကဲ့သို့သော artificial intelligences များကို လူ့အဖွဲ့အစည်းထဲသို့ ထည့်သွင်းခြင်း၏ ethics ကို စိစစ်ခဲ့သည်။
AI သုတေသနနယ်ပယ်များတွင် အမျိုးအစားများ ပေါ်ပေါက်လာခဲ့သည်။ "scruffy" vs. "neat AI" အယူအဆများကို ဖွဲ့စည်းခဲ့သည်။ Scruffy labs များသည် ရလဒ်လိုက်ဖို့အတွက် program များကို အချိန်ကြာကြာ tweak ပြုလုပ်ခဲ့သည်။ Neat labs များသည် "logic နှင့် formal problem solving" ကို အဓိကထားခဲ့သည်။ ELIZA နှင့် SHRDLU သည် scruffy systems များဖြစ်သည်။ 1980 ခုနှစ်များတွင် ML systems များကို reproducible ဖြစ်စေရန် demand ပေါ်လာသည်နှင့်အမျှ neat approach သည် gradually အရေးပါလာခဲ့သည်။
1980s Expert systems
နယ်ပယ်သည် တိုးတက်လာသည်နှင့် ၎င်း၏ စီးပွားရေးအကျိုးကျေးဇူးများ ပိုမိုရှင်းလင်းလာခဲ့ပြီး 1980 ခုနှစ်များတွင် 'expert systems' များ ပေါ်ပေါက်လာခဲ့သည်။ "Expert systems သည် အတုအမြင့်တုအာရုံ (AI) software ၏ ပထမဆုံးအောင်မြင်သော အမျိုးအစားများအနက် တစ်ခုဖြစ်သည်။" (source)
ဒီအမျိုးအစားသည် hybrid system တစ်ခုဖြစ်ပြီး rules engine တစ်ခုနှင့် inference engine တစ်ခုကို ပေါင်းစပ်ထားသည်။
ဒီကာလတွင် neural networks အပေါ် အာရုံစိုက်မှုများလည်း တိုးလာခဲ့သည်။
1987 - 1993: AI 'Chill'
specialized expert systems hardware များ၏ ပေါ်ပေါက်မှုသည် အလွန် specialized ဖြစ်လာခဲ့သည်။ Personal computers များ၏ တိုးတက်မှုသည် ဒီအကြီးမားသော specialized systems များနှင့် ယှဉ်ပြိုင်ခဲ့သည်။ Computing ၏ democratization သည် စတင်ခဲ့ပြီး big data ၏ explosion ကို pave လုပ်ပေးခဲ့သည်။
1993 - 2011
ဒီကာလတွင် ML နှင့် AI သည် data နှင့် compute power နည်းပါးမှုကြောင့် ဖြစ်ပေါ်ခဲ့သော ပြဿနာများကို ဖြေရှင်းနိုင်စွမ်းရှိလာခဲ့သည်။ ဒေတာပမာဏသည် အလွန်မြန်ဆန်စွာ တိုးလာခဲ့ပြီး smartphone ၏ ပေါ်ပေါက်မှု (2007) ကြောင့် ပိုမိုရရှိနိုင်လာခဲ့သည်။ Compute power သည် exponential အတိုင်း တိုးလာခဲ့ပြီး algorithm များလည်း တိုးတက်လာခဲ့သည်။ နယ်ပယ်သည် အတိတ်ကာလ၏ freewheeling days များမှ အတည်ပြု discipline တစ်ခုအဖြစ် crystallize ဖြစ်လာခဲ့သည်။
ယနေ့
ယနေ့တွင် စက်ရုပ်သင်ယူမှုနှင့် AI သည် လူသားများ၏ ဘဝ၏ အစိတ်အပိုင်းများအားလုံးကို ထိခိုက်စေသည်။ ဒီကာလသည် algorithm များ၏ လူသားဘဝများအပေါ် ရှုထောင့်များနှင့် အကျိုးသက်ရောက်မှုများကို သေချာနားလည်ရန် လိုအပ်သည်။ Microsoft's Brad Smith က "သတင်းအချက်အလက်နည်းပညာသည် privacy နှင့် freedom of expression ကဲ့သို့သော အခြေခံလူ့အခွင့်အရေးများကို ထိခိုက်စေသော ပြဿနာများကို ရှုထောင့်ပေးသည်။ ဒီပြဿနာများသည် ဒီထုတ်ကုန်များကို ဖန်တီးသော နည်းပညာကုမ္ပဏီများအတွက် တာဝန်ရှိမှုကို မြှင့်တင်စေသည်။ ကျွန်ုပ်တို့၏အမြင်အရ၊ ၎င်းတို့သည် thoughtful government regulation နှင့် acceptable uses အပေါ် norms ဖွံ့ဖြိုးတိုးတက်မှုကို လိုအပ်သည်။" (source) ဟု ပြောကြားခဲ့သည်။
အနာဂတ်တွင် ဘာဖြစ်မည်ဆိုသည်ကို မသိရသေးပါသော်လည်း ဒီ computer systems များနှင့် ၎င်းတို့ run လုပ်သော software နှင့် algorithm
ဝက်ဘ်ဆိုက်မှတ်ချက်:
ဤစာရွက်စာတမ်းကို AI ဘာသာပြန်ဝန်ဆောင်မှု Co-op Translator ကို အသုံးပြု၍ ဘာသာပြန်ထားပါသည်။ ကျွန်ုပ်တို့သည် တိကျမှန်ကန်မှုအတွက် ကြိုးစားနေပါသော်လည်း၊ အလိုအလျောက်ဘာသာပြန်မှုများတွင် အမှားများ သို့မဟုတ် မမှန်ကန်မှုများ ပါဝင်နိုင်သည်ကို ကျေးဇူးပြု၍ သတိပြုပါ။ မူရင်းစာရွက်စာတမ်းကို ၎င်း၏ မူလဘာသာစကားဖြင့် အာဏာတည်သောရင်းမြစ်အဖြစ် သတ်မှတ်ရန် လိုအပ်ပါသည်။ အရေးကြီးသော အချက်အလက်များအတွက် လူ့ဘာသာပြန်ပညာရှင်များ၏ ပရော်ဖက်ရှင်နယ်ဘာသာပြန်မှုကို အကြံပြုပါသည်။ ဤဘာသာပြန်မှုကို အသုံးပြုခြင်းမှ ဖြစ်ပေါ်လာသော နားလည်မှုမှားများ သို့မဟုတ် အဓိပ္ပာယ်မှားများအတွက် ကျွန်ုပ်တို့သည် တာဝန်မယူပါ။