16 KiB
Bermula dengan Python dan Scikit-learn untuk model regresi

Sketchnote oleh Tomomi Imura
Kuiz sebelum kuliah
Pelajaran ini tersedia dalam R!
Pengenalan
Dalam empat pelajaran ini, anda akan belajar cara membina model regresi. Kita akan membincangkan kegunaannya sebentar lagi. Tetapi sebelum memulakan apa-apa, pastikan anda mempunyai alat yang betul untuk memulakan proses ini!
Dalam pelajaran ini, anda akan belajar cara:
- Mengkonfigurasi komputer anda untuk tugas pembelajaran mesin secara tempatan.
- Bekerja dengan Jupyter notebooks.
- Menggunakan Scikit-learn, termasuk pemasangan.
- Meneroka regresi linear melalui latihan praktikal.
Pemasangan dan konfigurasi

🎥 Klik imej di atas untuk video pendek tentang cara mengkonfigurasi komputer anda untuk ML.
-
Pasang Python. Pastikan Python dipasang pada komputer anda. Anda akan menggunakan Python untuk banyak tugas sains data dan pembelajaran mesin. Kebanyakan sistem komputer sudah mempunyai Python yang dipasang. Terdapat juga Pakej Pengkodan Python yang berguna untuk memudahkan pemasangan bagi sesetengah pengguna.
Walau bagaimanapun, beberapa penggunaan Python memerlukan satu versi perisian, manakala yang lain memerlukan versi yang berbeza. Oleh itu, adalah berguna untuk bekerja dalam persekitaran maya.
-
Pasang Visual Studio Code. Pastikan anda mempunyai Visual Studio Code yang dipasang pada komputer anda. Ikuti arahan ini untuk memasang Visual Studio Code untuk pemasangan asas. Anda akan menggunakan Python dalam Visual Studio Code dalam kursus ini, jadi anda mungkin ingin menyegarkan pengetahuan anda tentang cara mengkonfigurasi Visual Studio Code untuk pembangunan Python.
Biasakan diri dengan Python dengan melalui koleksi modul pembelajaran ini

🎥 Klik imej di atas untuk video: menggunakan Python dalam VS Code.
-
Pasang Scikit-learn, dengan mengikuti arahan ini. Oleh kerana anda perlu memastikan bahawa anda menggunakan Python 3, disarankan agar anda menggunakan persekitaran maya. Perhatikan, jika anda memasang pustaka ini pada Mac M1, terdapat arahan khas pada halaman yang dipautkan di atas.
-
Pasang Jupyter Notebook. Anda perlu memasang pakej Jupyter.
Persekitaran pengarang ML anda
Anda akan menggunakan notebooks untuk membangunkan kod Python anda dan mencipta model pembelajaran mesin. Jenis fail ini adalah alat biasa untuk saintis data, dan ia boleh dikenalpasti melalui akhiran atau sambungan .ipynb.
Notebooks adalah persekitaran interaktif yang membolehkan pembangun untuk menulis kod serta menambah nota dan dokumentasi di sekitar kod, yang sangat berguna untuk projek eksperimen atau berorientasikan penyelidikan.

🎥 Klik imej di atas untuk video pendek melalui latihan ini.
Latihan - bekerja dengan notebook
Dalam folder ini, anda akan menemui fail notebook.ipynb.
-
Buka notebook.ipynb dalam Visual Studio Code.
Pelayan Jupyter akan bermula dengan Python 3+ dimulakan. Anda akan menemui kawasan dalam notebook yang boleh
dijalankan, iaitu potongan kod. Anda boleh menjalankan blok kod dengan memilih ikon yang kelihatan seperti butang main. -
Pilih ikon
mddan tambahkan sedikit markdown, serta teks berikut # Selamat datang ke notebook anda.Seterusnya, tambahkan beberapa kod Python.
-
Taip print('hello notebook') dalam blok kod.
-
Pilih anak panah untuk menjalankan kod.
Anda sepatutnya melihat kenyataan yang dicetak:
hello notebook

Anda boleh menyelitkan kod anda dengan komen untuk mendokumentasikan notebook secara sendiri.
✅ Fikirkan sebentar tentang betapa berbezanya persekitaran kerja pembangun web berbanding dengan saintis data.
Memulakan dengan Scikit-learn
Sekarang Python telah disediakan dalam persekitaran tempatan anda, dan anda sudah selesa dengan Jupyter notebooks, mari kita menjadi sama selesa dengan Scikit-learn (disebut sci seperti dalam science). Scikit-learn menyediakan API yang luas untuk membantu anda melaksanakan tugas ML.
Menurut laman web mereka, "Scikit-learn adalah pustaka pembelajaran mesin sumber terbuka yang menyokong pembelajaran terarah dan tidak terarah. Ia juga menyediakan pelbagai alat untuk pemasangan model, prapemprosesan data, pemilihan model dan penilaian, serta banyak utiliti lain."
Dalam kursus ini, anda akan menggunakan Scikit-learn dan alat lain untuk membina model pembelajaran mesin untuk melaksanakan apa yang kita panggil tugas 'pembelajaran mesin tradisional'. Kami sengaja mengelakkan rangkaian neural dan pembelajaran mendalam, kerana ia lebih sesuai diliputi dalam kurikulum 'AI untuk Pemula' kami yang akan datang.
Scikit-learn memudahkan untuk membina model dan menilai mereka untuk digunakan. Ia terutamanya memberi tumpuan kepada penggunaan data berangka dan mengandungi beberapa dataset siap sedia untuk digunakan sebagai alat pembelajaran. Ia juga termasuk model pra-bina untuk pelajar mencuba. Mari kita terokai proses memuatkan data yang telah dipakejkan dan menggunakan estimator terbina untuk model ML pertama dengan Scikit-learn menggunakan data asas.
Latihan - notebook Scikit-learn pertama anda
Tutorial ini diilhamkan oleh contoh regresi linear di laman web Scikit-learn.

🎥 Klik imej di atas untuk video pendek melalui latihan ini.
Dalam fail notebook.ipynb yang berkaitan dengan pelajaran ini, kosongkan semua sel dengan menekan ikon 'tong sampah'.
Dalam bahagian ini, anda akan bekerja dengan dataset kecil tentang diabetes yang dibina dalam Scikit-learn untuk tujuan pembelajaran. Bayangkan anda ingin menguji rawatan untuk pesakit diabetes. Model Pembelajaran Mesin mungkin membantu anda menentukan pesakit mana yang akan memberi tindak balas lebih baik terhadap rawatan, berdasarkan gabungan pembolehubah. Malah model regresi yang sangat asas, apabila divisualisasikan, mungkin menunjukkan maklumat tentang pembolehubah yang akan membantu anda mengatur ujian klinikal teori anda.
✅ Terdapat banyak jenis kaedah regresi, dan yang mana anda pilih bergantung pada jawapan yang anda cari. Jika anda ingin meramalkan ketinggian yang mungkin untuk seseorang berdasarkan umur tertentu, anda akan menggunakan regresi linear, kerana anda mencari nilai berangka. Jika anda berminat untuk mengetahui sama ada jenis masakan harus dianggap vegan atau tidak, anda mencari penugasan kategori, jadi anda akan menggunakan regresi logistik. Anda akan belajar lebih lanjut tentang regresi logistik kemudian. Fikirkan sedikit tentang beberapa soalan yang boleh anda tanyakan kepada data, dan kaedah mana yang lebih sesuai.
Mari kita mulakan tugas ini.
Import pustaka
Untuk tugas ini, kita akan mengimport beberapa pustaka:
- matplotlib. Ia adalah alat grafik yang berguna dan kita akan menggunakannya untuk mencipta plot garis.
- numpy. numpy adalah pustaka berguna untuk mengendalikan data berangka dalam Python.
- sklearn. Ini adalah pustaka Scikit-learn.
Import beberapa pustaka untuk membantu tugas anda.
-
Tambahkan import dengan menaip kod berikut:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionDi atas, anda mengimport
matplotlib,numpydan anda mengimportdatasets,linear_modeldanmodel_selectiondarisklearn.model_selectiondigunakan untuk membahagikan data kepada set latihan dan ujian.
Dataset diabetes
Dataset diabetes yang dibina dalam Scikit-learn termasuk 442 sampel data tentang diabetes, dengan 10 pembolehubah ciri, beberapa daripadanya termasuk:
- age: umur dalam tahun
- bmi: indeks jisim badan
- bp: tekanan darah purata
- s1 tc: T-Cells (sejenis sel darah putih)
✅ Dataset ini termasuk konsep 'sex' sebagai pembolehubah ciri yang penting untuk penyelidikan tentang diabetes. Banyak dataset perubatan termasuk jenis klasifikasi binari ini. Fikirkan sedikit tentang bagaimana pengkategorian seperti ini mungkin mengecualikan bahagian tertentu populasi daripada rawatan.
Sekarang, muatkan data X dan y.
🎓 Ingat, ini adalah pembelajaran terarah, dan kita memerlukan sasaran 'y' yang bernama.
Dalam sel kod baru, muatkan dataset diabetes dengan memanggil load_diabetes(). Input return_X_y=True menandakan bahawa X akan menjadi matriks data, dan y akan menjadi sasaran regresi.
-
Tambahkan beberapa arahan cetak untuk menunjukkan bentuk matriks data dan elemen pertamanya:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Apa yang anda dapat sebagai respons adalah tuple. Apa yang anda lakukan adalah menetapkan dua nilai pertama tuple kepada
Xdanymasing-masing. Ketahui lebih lanjut tentang tuple.Anda boleh melihat bahawa data ini mempunyai 442 item yang dibentuk dalam array 10 elemen:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Fikirkan sedikit tentang hubungan antara data dan sasaran regresi. Regresi linear meramalkan hubungan antara ciri X dan pembolehubah sasaran y. Bolehkah anda mencari sasaran untuk dataset diabetes dalam dokumentasi? Apa yang dataset ini tunjukkan, memandangkan sasaran?
-
Seterusnya, pilih sebahagian dataset ini untuk diplot dengan memilih lajur ke-3 dataset. Anda boleh melakukannya dengan menggunakan operator
:untuk memilih semua baris, dan kemudian memilih lajur ke-3 menggunakan indeks (2). Anda juga boleh membentuk semula data menjadi array 2D - seperti yang diperlukan untuk plot - dengan menggunakanreshape(n_rows, n_columns). Jika salah satu parameter adalah -1, dimensi yang sepadan dikira secara automatik.X = X[:, 2] X = X.reshape((-1,1))✅ Pada bila-bila masa, cetak data untuk memeriksa bentuknya.
-
Sekarang setelah anda mempunyai data yang siap untuk diplot, anda boleh melihat sama ada mesin dapat membantu menentukan pemisahan logik antara nombor dalam dataset ini. Untuk melakukan ini, anda perlu membahagikan kedua-dua data (X) dan sasaran (y) kepada set ujian dan latihan. Scikit-learn mempunyai cara yang mudah untuk melakukan ini; anda boleh membahagikan data ujian anda pada titik tertentu.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Sekarang anda bersedia untuk melatih model anda! Muatkan model regresi linear dan latih dengan set latihan X dan y anda menggunakan
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()adalah fungsi yang akan anda lihat dalam banyak pustaka ML seperti TensorFlow. -
Kemudian, buat ramalan menggunakan data ujian, dengan menggunakan fungsi
predict(). Ini akan digunakan untuk melukis garis antara kumpulan data model.y_pred = model.predict(X_test) -
Sekarang tiba masanya untuk menunjukkan data dalam plot. Matplotlib adalah alat yang sangat berguna untuk tugas ini. Buat scatterplot semua data ujian X dan y, dan gunakan ramalan untuk melukis garis di tempat yang paling sesuai, antara kumpulan data model.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()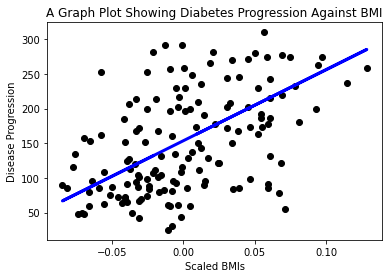 ✅ Fikirkan sedikit tentang apa yang sedang berlaku di sini. Garis lurus sedang melalui banyak titik kecil data, tetapi apa sebenarnya yang sedang dilakukan? Bolehkah anda melihat bagaimana anda sepatutnya dapat menggunakan garis ini untuk meramalkan di mana titik data baru yang belum dilihat sepatutnya sesuai dalam hubungan dengan paksi y plot? Cuba nyatakan dalam kata-kata kegunaan praktikal model ini.
✅ Fikirkan sedikit tentang apa yang sedang berlaku di sini. Garis lurus sedang melalui banyak titik kecil data, tetapi apa sebenarnya yang sedang dilakukan? Bolehkah anda melihat bagaimana anda sepatutnya dapat menggunakan garis ini untuk meramalkan di mana titik data baru yang belum dilihat sepatutnya sesuai dalam hubungan dengan paksi y plot? Cuba nyatakan dalam kata-kata kegunaan praktikal model ini.
Tahniah, anda telah membina model regresi linear pertama anda, mencipta ramalan dengannya, dan memaparkannya dalam plot!
🚀Cabaran
Plotkan pemboleh ubah yang berbeza daripada dataset ini. Petunjuk: edit baris ini: X = X[:,2]. Berdasarkan sasaran dataset ini, apakah yang anda dapat temui tentang perkembangan diabetes sebagai penyakit?
Kuiz selepas kuliah
Ulasan & Kajian Kendiri
Dalam tutorial ini, anda bekerja dengan regresi linear mudah, bukannya regresi univariat atau regresi berganda. Baca sedikit tentang perbezaan antara kaedah-kaedah ini, atau lihat video ini.
Baca lebih lanjut tentang konsep regresi dan fikirkan tentang jenis soalan yang boleh dijawab oleh teknik ini. Ambil tutorial ini untuk mendalami pemahaman anda.
Tugasan
Penafian:
Dokumen ini telah diterjemahkan menggunakan perkhidmatan terjemahan AI Co-op Translator. Walaupun kami berusaha untuk memastikan ketepatan, sila ambil perhatian bahawa terjemahan automatik mungkin mengandungi kesilapan atau ketidaktepatan. Dokumen asal dalam bahasa asalnya harus dianggap sebagai sumber yang berwibawa. Untuk maklumat yang kritikal, terjemahan manusia profesional adalah disyorkan. Kami tidak bertanggungjawab atas sebarang salah faham atau salah tafsir yang timbul daripada penggunaan terjemahan ini.