31 KiB
Python आणि Scikit-learn वापरून रिग्रेशन मॉडेल्ससाठी सुरुवात करा

स्केच नोट Tomomi Imura यांनी तयार केले आहे
पूर्व-व्याख्यान प्रश्नमंजुषा
हा धडा R मध्ये उपलब्ध आहे!
परिचय
या चार धड्यांमध्ये, तुम्ही रिग्रेशन मॉडेल्स कसे तयार करायचे ते शिकाल. आम्ही लवकरच याचा उपयोग कशासाठी होतो ते चर्चा करू. पण काहीही करण्यापूर्वी, प्रक्रिया सुरू करण्यासाठी योग्य साधने तुमच्याकडे आहेत याची खात्री करा!
या धड्यात तुम्ही शिकाल:
- स्थानिक मशीन लर्निंग कार्यांसाठी तुमचा संगणक कॉन्फिगर करणे.
- Jupyter नोटबुक्ससह काम करणे.
- Scikit-learn वापरणे, त्यात स्थापना समाविष्ट आहे.
- एक व्यावहारिक सराव करून रेखीय रिग्रेशन एक्सप्लोर करणे.
स्थापना आणि कॉन्फिगरेशन

🎥 वरील प्रतिमेवर क्लिक करा, तुमचा संगणक एमएलसाठी कॉन्फिगर करण्यासाठी एक लहान व्हिडिओ पाहण्यासाठी.
-
Python स्थापित करा. खात्री करा की Python तुमच्या संगणकावर स्थापित आहे. तुम्ही डेटा सायन्स आणि मशीन लर्निंग कार्यांसाठी Python वापराल. बहुतेक संगणक प्रणालींमध्ये आधीच Python स्थापित असते. काही वापरकर्त्यांसाठी सेटअप सुलभ करण्यासाठी उपयुक्त Python Coding Packs उपलब्ध आहेत.
Python चा काही उपयोग, तथापि, सॉफ्टवेअरच्या एका आवृत्तीची आवश्यकता असतो, तर इतरांना वेगळ्या आवृत्तीची आवश्यकता असते. यासाठी, virtual environment मध्ये काम करणे उपयुक्त ठरते.
-
Visual Studio Code स्थापित करा. खात्री करा की Visual Studio Code तुमच्या संगणकावर स्थापित आहे. Visual Studio Code स्थापित करण्यासाठी या सूचनांचे अनुसरण करा. तुम्ही या कोर्समध्ये Visual Studio Code मध्ये Python वापरणार आहात, त्यामुळे Python विकासासाठी Visual Studio Code कॉन्फिगर कसे करावे याबद्दल माहिती मिळवा.
Python मध्ये आरामदायक व्हा, या Learn modules संग्रहातून काम करून.

🎥 वरील प्रतिमेवर क्लिक करा, VS Code मध्ये Python वापरण्यासाठी व्हिडिओ पाहण्यासाठी.
-
Scikit-learn स्थापित करा, या सूचनांचे अनुसरण करून. तुम्हाला Python 3 वापरण्याची खात्री करावी लागेल, त्यामुळे virtual environment वापरण्याची शिफारस केली जाते. लक्षात ठेवा, जर तुम्ही M1 Mac वर हे लायब्ररी स्थापित करत असाल, तर वरील लिंक केलेल्या पृष्ठावर विशेष सूचना आहेत.
-
Jupyter Notebook स्थापित करा. तुम्हाला Jupyter package स्थापित करावे लागेल.
तुमचे एमएल लेखन वातावरण
तुम्ही notebooks वापरून तुमचा Python कोड विकसित कराल आणि मशीन लर्निंग मॉडेल्स तयार कराल. डेटा सायंटिस्ट्ससाठी ही फाइल प्रकार सामान्य साधन आहे आणि त्यांना त्यांच्या विस्तार .ipynb द्वारे ओळखले जाऊ शकते.
नोटबुक्स एक परस्परसंवादी वातावरण आहे जे विकसकाला कोड लिहिण्यास आणि कोडच्या आसपास टिपा आणि दस्तऐवज लिहिण्यास परवानगी देते, जे प्रायोगिक किंवा संशोधन-आधारित प्रकल्पांसाठी खूप उपयुक्त आहे.

🎥 वरील प्रतिमेवर क्लिक करा, या सरावामध्ये काम करण्यासाठी एक लहान व्हिडिओ पाहण्यासाठी.
सराव - नोटबुकसह काम करा
या फोल्डरमध्ये, तुम्हाला notebook.ipynb नावाची फाइल सापडेल.
-
notebook.ipynb Visual Studio Code मध्ये उघडा.
Jupyter सर्व्हर Python 3+ सह सुरू होईल. तुम्हाला नोटबुकच्या भागांमध्ये
runकरता येणारे कोडचे तुकडे सापडतील. तुम्ही प्ले बटणासारखे दिसणारे चिन्ह निवडून कोड ब्लॉक चालवू शकता. -
mdचिन्ह निवडा आणि थोडेसे markdown आणि खालील मजकूर जोडा # Welcome to your notebook.नंतर, काही Python कोड जोडा.
-
कोड ब्लॉकमध्ये print('hello notebook') टाइप करा.
-
कोड चालवण्यासाठी बाण निवडा.
तुम्हाला मुद्रित विधान दिसले पाहिजे:
hello notebook

तुम्ही तुमच्या कोडसह टिप्पण्या जोडून नोटबुक स्वतः दस्तऐवजीकरण करू शकता.
✅ एका मिनिटासाठी विचार करा की वेब विकसकाचे कार्य वातावरण डेटा सायंटिस्टच्या कार्य वातावरणापेक्षा किती वेगळे आहे.
Scikit-learn सह सुरुवात
आता Python तुमच्या स्थानिक वातावरणात सेट केले आहे आणि तुम्ही Jupyter नोटबुक्समध्ये आरामदायक आहात, चला Scikit-learn मध्ये तितकेच आरामदायक होऊया (sci म्हणजे science असे उच्चारले जाते). Scikit-learn तुम्हाला एमएल कार्ये करण्यास मदत करण्यासाठी व्यापक API प्रदान करते.
त्यांच्या वेबसाइट नुसार, "Scikit-learn एक ओपन सोर्स मशीन लर्निंग लायब्ररी आहे जी supervised आणि unsupervised learning ला समर्थन देते. हे मॉडेल फिटिंग, डेटा preprocessing, मॉडेल निवड आणि मूल्यांकन, आणि इतर अनेक उपयुक्तता साधनांसाठी विविध साधने प्रदान करते."
या कोर्समध्ये, तुम्ही Scikit-learn आणि इतर साधने वापरून मशीन लर्निंग मॉडेल्स तयार कराल जे आम्ही 'पारंपरिक मशीन लर्निंग' कार्ये म्हणतो. आम्ही neural networks आणि deep learning टाळले आहे, कारण ते आमच्या आगामी 'AI for Beginners' अभ्यासक्रमात चांगले कव्हर केले जातील.
Scikit-learn मॉडेल्स तयार करणे आणि त्यांचे मूल्यांकन करणे सोपे करते. हे प्रामुख्याने संख्यात्मक डेटा वापरण्यावर लक्ष केंद्रित करते आणि शिकण्याच्या साधनांप्रमाणे वापरण्यासाठी अनेक तयार केलेले डेटासेट्स समाविष्ट करते. विद्यार्थ्यांना प्रयत्न करण्यासाठी पूर्व-निर्मित मॉडेल्स देखील समाविष्ट आहेत. चला Scikit-learn सह काही मूलभूत डेटासह पूर्व-पॅकेज केलेला डेटा लोड करण्याची प्रक्रिया आणि पहिला एमएल मॉडेल वापरणे एक्सप्लोर करूया.
सराव - तुमचा पहिला Scikit-learn नोटबुक
हा ट्यूटोरियल Scikit-learn च्या वेबसाइटवरील रेखीय रिग्रेशन उदाहरण द्वारे प्रेरित आहे.

🎥 वरील प्रतिमेवर क्लिक करा, या सरावामध्ये काम करण्यासाठी एक लहान व्हिडिओ पाहण्यासाठी.
नोटबुक.ipynb फाइलमधील सर्व सेल्स 'trash can' चिन्हावर क्लिक करून साफ करा.
या विभागात, तुम्ही Scikit-learn मध्ये शिकण्यासाठी तयार केलेल्या मधुमेहाबद्दलच्या लहान डेटासेटसह काम कराल. कल्पना करा की तुम्हाला मधुमेहाच्या रुग्णांसाठी उपचाराची चाचणी करायची आहे. मशीन लर्निंग मॉडेल्स तुम्हाला व्हेरिएबल्सच्या संयोजनांवर आधारित कोणते रुग्ण उपचाराला चांगला प्रतिसाद देतील हे ठरविण्यात मदत करू शकतात. अगदी मूलभूत रिग्रेशन मॉडेल, जेव्हा व्हिज्युअलाइज केले जाते, तेव्हा व्हेरिएबल्सबद्दल माहिती दर्शवू शकते जी तुम्हाला तुमच्या सैद्धांतिक क्लिनिकल चाचण्या आयोजित करण्यात मदत करू शकते.
✅ रिग्रेशन पद्धतींच्या अनेक प्रकार आहेत, आणि तुम्ही कोणती निवडता ते तुम्हाला शोधायचे उत्तर कोणते आहे यावर अवलंबून असते. जर तुम्हाला दिलेल्या वयाच्या व्यक्तीसाठी संभाव्य उंचीचा अंदाज घ्यायचा असेल, तर तुम्ही रेखीय रिग्रेशन वापराल, कारण तुम्ही संख्यात्मक मूल्य शोधत आहात. जर तुम्हाला एखाद्या प्रकारच्या खाद्यपदार्थाला शाकाहारी मानावे की नाही हे शोधायचे असेल, तर तुम्ही श्रेणी असाइनमेंट शोधत आहात, त्यामुळे तुम्ही लॉजिस्टिक रिग्रेशन वापराल. तुम्ही नंतर लॉजिस्टिक रिग्रेशनबद्दल अधिक शिकाल. डेटामधून काही प्रश्न विचारण्याचा विचार करा आणि या पद्धतींपैकी कोणती अधिक योग्य असेल.
चला या कार्यावर सुरुवात करूया.
लायब्ररी आयात करा
या कार्यासाठी आम्ही काही लायब्ररी आयात करू:
- matplotlib. हे एक उपयुक्त ग्राफिंग साधन आहे आणि आम्ही याचा वापर लाइन प्लॉट तयार करण्यासाठी करू.
- numpy. numpy ही Python मध्ये संख्यात्मक डेटा हाताळण्यासाठी उपयुक्त लायब्ररी आहे.
- sklearn. ही Scikit-learn लायब्ररी आहे.
तुमच्या कार्यांसाठी मदत करण्यासाठी काही लायब्ररी आयात करा.
-
खालील कोड टाइप करून आयात जोडा:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionवरील कोडमध्ये तुम्ही
matplotlib,numpyआयात करत आहात आणि तुम्हीsklearnमधूनdatasets,linear_modelआणिmodel_selectionआयात करत आहात.model_selectionडेटा प्रशिक्षण आणि चाचणी संचांमध्ये विभाजित करण्यासाठी वापरले जाते.
मधुमेह डेटासेट
Scikit-learn मध्ये तयार केलेला मधुमेह डेटासेट मधुमेहाबद्दल 442 नमुन्यांचा डेटा समाविष्ट करतो, ज्यामध्ये 10 वैशिष्ट्य व्हेरिएबल्स आहेत, त्यापैकी काही:
- age: वय वर्षांमध्ये
- bmi: बॉडी मास इंडेक्स
- bp: सरासरी रक्तदाब
- s1 tc: टी-सेल्स (पांढऱ्या रक्त पेशींचा एक प्रकार)
✅ या डेटासेटमध्ये मधुमेहाच्या संशोधनासाठी महत्त्वाचे वैशिष्ट्य व्हेरिएबल म्हणून 'sex' चा समावेश आहे. अनेक वैद्यकीय डेटासेट्समध्ये अशा प्रकारचे binary वर्गीकरण समाविष्ट असते. अशा वर्गीकरणांमुळे लोकसंख्येच्या काही भागांना उपचारांपासून वगळले जाऊ शकते याचा विचार करा.
आता X आणि y डेटा लोड करा.
🎓 लक्षात ठेवा, हे supervised learning आहे, आणि आपल्याला नाव असलेला 'y' target आवश्यक आहे.
नवीन कोड सेलमध्ये, load_diabetes() कॉल करून मधुमेह डेटासेट लोड करा. इनपुट return_X_y=True संकेत देतो की X डेटा मॅट्रिक्स असेल, आणि y रिग्रेशन target असेल.
-
डेटा मॅट्रिक्सचा आकार आणि त्याचा पहिला घटक दर्शविण्यासाठी काही print कमांड जोडा:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])तुम्हाला प्रतिसाद म्हणून जे मिळत आहे ते tuple आहे. तुम्ही काय करत आहात ते म्हणजे tuple च्या दोन पहिल्या मूल्यांना अनुक्रमे
Xआणिyमध्ये असाइन करत आहात. tuples बद्दल अधिक जाणून घ्या.तुम्ही पाहू शकता की या डेटामध्ये 442 आयटम आहेत जे 10 घटकांच्या अॅरेमध्ये आकारलेले आहेत:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ डेटा आणि रिग्रेशन target यांच्यातील संबंधाचा विचार करा. रेखीय रिग्रेशन वैशिष्ट्य X आणि target व्हेरिएबल y यांच्यातील संबंधांचा अंदाज लावतो. तुम्ही मधुमेह डेटासेटसाठी target दस्तऐवजामध्ये शोधू शकता का? target दिल्याने हा डेटासेट काय दर्शवित आहे?
-
नंतर, या डेटासेटचा एक भाग प्लॉट करण्यासाठी निवडा, डेटासेटचा तिसरा कॉलम निवडून. तुम्ही
:ऑपरेटर वापरून सर्व रांगा निवडू शकता आणि नंतर इंडेक्स (2) वापरून तिसरा कॉलम निवडू शकता. तुम्हीreshape(n_rows, n_columns)वापरून डेटा 2D अॅरेमध्ये आकार बदलू शकता - प्लॉटिंगसाठी आवश्यक आहे. जर एका पॅरामीटरला -1 असेल, तर संबंधित परिमाण आपोआप गणना केली जाते.X = X[:, 2] X = X.reshape((-1,1))✅ कोणत्याही वेळी, डेटा त्याचा आकार तपासण्यासाठी प्रिंट करा.
-
आता तुमच्याकडे प्लॉट करण्यासाठी डेटा तयार आहे, तुम्ही पाहू शकता की मशीन या डेटासेटमधील संख्यांमध्ये तर्कसंगत विभाजन ठरवू शकते का. हे करण्यासाठी, तुम्हाला डेटा (X) आणि target (y) दोन्ही चाचणी आणि प्रशिक्षण संचांमध्ये विभाजित करणे आवश्यक आहे. Scikit-learn मध्ये हे करण्याचा सोपा मार्ग आहे; तुम्ही तुमचा चाचणी डेटा दिलेल्या बिंदूवर विभाजित करू शकता.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
आता तुम्ही तुमचे मॉडेल प्रशिक्षण देण्यासाठी तयार आहात! रेखीय रिग्रेशन मॉडेल लोड करा आणि
model.fit()वापरून तुमच्या X आणि y प्रशिक्षण संचांसह ते प्रशिक्षण द्या:model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()ही एक फंक्शन आहे जी तुम्हाला TensorFlow सारख्या अनेक एमएल लायब्ररींमध्ये दिसेल. -
नंतर, चाचणी डेटा वापरून अंदाज तयार करा,
predict()फंक्शन वापरून. हे डेटा गटांमधील रेषा काढण्यासाठी वापरले जाईल.y_pred = model.predict(X_test) -
आता डेटा प्लॉटमध्ये दर्शविण्याची वेळ आली आहे. Matplotlib हे या कार्यासाठी खूप उपयुक्त साधन आहे. सर्व X आणि y चाचणी डेटाचा scatterplot तयार करा आणि मॉडेलच्या डेटा गटांमधील सर्वात योग्य ठिकाणी रेषा काढण्यासाठी अंदाज वापरा.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()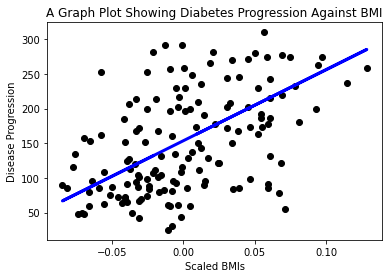 ✅ विचार करा की येथे नेमके काय चालले आहे. अनेक छोटे डेटा बिंदूंच्या माध्यमातून एक सरळ रेषा जात आहे, पण ती नेमके काय करत आहे? तुम्हाला दिसते का की तुम्ही ही रेषा वापरून नवीन, न पाहिलेला डेटा बिंदू प्लॉटच्या y अक्षाशी कसा संबंधित आहे हे अंदाज करू शकता? या मॉडेलचा व्यावहारिक उपयोग शब्दांत मांडण्याचा प्रयत्न करा.
✅ विचार करा की येथे नेमके काय चालले आहे. अनेक छोटे डेटा बिंदूंच्या माध्यमातून एक सरळ रेषा जात आहे, पण ती नेमके काय करत आहे? तुम्हाला दिसते का की तुम्ही ही रेषा वापरून नवीन, न पाहिलेला डेटा बिंदू प्लॉटच्या y अक्षाशी कसा संबंधित आहे हे अंदाज करू शकता? या मॉडेलचा व्यावहारिक उपयोग शब्दांत मांडण्याचा प्रयत्न करा.
अभिनंदन, तुम्ही तुमचे पहिले रेषीय प्रतिगमन मॉडेल तयार केले, त्याचा वापर करून अंदाज तयार केला आणि ते प्लॉटमध्ये प्रदर्शित केले!
🚀चॅलेंज
या डेटासेटमधून वेगळा व्हेरिएबल प्लॉट करा. सूचना: ही ओळ संपादित करा: X = X[:,2]. या डेटासेटच्या लक्ष्यानुसार, तुम्ही मधुमेह या आजाराच्या प्रगतीबद्दल काय शोधू शकता?
पाठानंतरचा क्विझ
पुनरावलोकन आणि स्व-अभ्यास
या ट्युटोरियलमध्ये, तुम्ही साध्या रेषीय प्रतिगमनासोबत काम केले, न की एकच व्हेरिएबल असलेले किंवा अनेक व्हेरिएबल्स असलेले प्रतिगमन. या पद्धतींमधील फरकांबद्दल थोडे वाचा किंवा या व्हिडिओ कडे लक्ष द्या.
प्रतिगमनाच्या संकल्पनेबद्दल अधिक वाचा आणि कोणत्या प्रकारचे प्रश्न या तंत्राद्वारे उत्तर दिले जाऊ शकतात याचा विचार करा. तुमचे ज्ञान वाढवण्यासाठी हा ट्युटोरियल घ्या.
असाइनमेंट
अस्वीकरण:
हा दस्तऐवज AI भाषांतर सेवा Co-op Translator चा वापर करून भाषांतरित करण्यात आला आहे. आम्ही अचूकतेसाठी प्रयत्नशील असलो तरी, कृपया लक्षात घ्या की स्वयंचलित भाषांतरांमध्ये त्रुटी किंवा अचूकतेचा अभाव असू शकतो. मूळ भाषेतील मूळ दस्तऐवज हा अधिकृत स्रोत मानला जावा. महत्त्वाच्या माहितीसाठी व्यावसायिक मानवी भाषांतराची शिफारस केली जाते. या भाषांतराचा वापर केल्यामुळे उद्भवणाऱ्या कोणत्याही गैरसमज किंवा चुकीच्या अर्थासाठी आम्ही जबाबदार राहणार नाही.