15 KiB
後記:使用負責任的 AI 儀表板元件進行機器學習模型調試
課前測驗
簡介
機器學習已深刻影響我們的日常生活。AI 正逐漸滲透到一些對個人及社會至關重要的系統中,例如醫療保健、金融、教育和就業。舉例來說,系統和模型參與了日常決策任務,例如醫療診斷或欺詐檢測。然而,隨著 AI 的快速發展和廣泛採用,社會期望也在不斷演變,並且政府開始針對 AI 解決方案進行監管。我們經常看到 AI 系統未能達到期望的情況,並暴露出新的挑戰。因此,分析這些模型以確保其結果公平、可靠、包容、透明且負責任,對每個人都至關重要。
在本課程中,我們將探討一些實用工具,用於評估模型是否存在負責任的 AI 問題。傳統的機器學習調試技術通常基於定量計算,例如整體準確率或平均錯誤損失。然而,想像一下,如果您用來構建這些模型的數據缺乏某些人口統計特徵,例如種族、性別、政治觀點或宗教,或者這些特徵被不成比例地代表,會發生什麼?如果模型的輸出偏向某些人口統計特徵,又會如何?這可能導致敏感特徵群體的過度或不足代表性,進而引發模型的公平性、包容性或可靠性問題。此外,機器學習模型通常被視為黑箱,這使得理解和解釋模型的預測驅動因素變得困難。這些都是數據科學家和 AI 開發者在缺乏足夠工具來調試和評估模型的公平性或可信度時面臨的挑戰。
在本課程中,您將學習如何使用以下方法調試模型:
- 錯誤分析:識別模型在數據分佈中錯誤率較高的區域。
- 模型概覽:對不同數據群體進行比較分析,以發現模型性能指標中的差異。
- 數據分析:調查數據是否存在過度或不足代表性,這可能導致模型偏向某些數據群體。
- 特徵重要性:了解哪些特徵在全局或局部層面上驅動模型的預測。
前置條件
在開始之前,請先查看 開發者的負責任 AI 工具

錯誤分析
傳統的模型性能指標通常基於正確與錯誤預測的計算。例如,判斷一個模型的準確率為 89%,錯誤損失為 0.001,可以被認為是良好的性能。然而,錯誤通常並非均勻分佈於底層數據集中。您可能獲得 89% 的模型準確率,但發現模型在某些數據區域的錯誤率高達 42%。這些特定數據群體的失敗模式可能導致公平性或可靠性問題。因此,了解模型表現良好或不佳的區域至關重要。模型在某些數據區域的高錯誤率可能揭示出重要的數據人口統計特徵。

RAI 儀表板中的錯誤分析元件通過樹狀可視化展示模型失敗在不同群體中的分佈情況。這有助於識別數據集中錯誤率較高的特徵或區域。通過了解模型大部分錯誤的來源,您可以開始調查根本原因。您還可以創建數據群體進行分析,這些群體有助於調試過程,確定模型在某些群體表現良好,而在其他群體表現不佳的原因。

樹狀圖中的視覺指示器可以幫助更快地定位問題區域。例如,樹節點的紅色陰影越深,錯誤率越高。
熱圖是另一種可視化功能,用於通過一個或兩個特徵調查錯誤率,找出整個數據集或群體中導致模型錯誤的因素。

使用錯誤分析的情境:
- 深入了解模型失敗在數據集和多個輸入及特徵維度中的分佈情況。
- 分解整體性能指標,通過自動發現錯誤群體來制定有針對性的緩解措施。
模型概覽
評估機器學習模型的性能需要全面了解其行為。這可以通過查看多個指標(例如錯誤率、準確率、召回率、精確度或 MAE)來實現,以發現性能指標中的差異。一個指標可能看起來很好,但另一個指標可能暴露出不準確的地方。此外,比較整個數據集或群體中的指標差異有助於揭示模型表現良好或不佳的地方。這在查看模型在敏感特徵(例如患者的種族、性別或年齡)與非敏感特徵中的表現時尤為重要,以揭示模型可能存在的潛在不公平。例如,發現模型在包含敏感特徵的群體中錯誤率更高,可能揭示模型存在的不公平性。
RAI 儀表板中的模型概覽元件不僅有助於分析數據群體中的性能指標,還使用戶能夠比較模型在不同群體中的行為。

該元件的基於特徵的分析功能允許用戶縮小特定特徵的數據子群體,以更細緻地識別異常。例如,儀表板具有內置智能,可以自動為用戶選擇的特徵生成群體(例如 "time_in_hospital < 3" 或 "time_in_hospital >= 7")。這使用戶能夠從更大的數據群體中隔離特定特徵,以查看它是否是模型錯誤結果的關鍵影響因素。

模型概覽元件支持兩類差異指標:
模型性能差異:這些指標計算所選性能指標在數據子群體之間的差異。例如:
- 準確率差異
- 錯誤率差異
- 精確度差異
- 召回率差異
- 平均絕對誤差(MAE)差異
選擇率差異:此指標包含子群體之間選擇率(有利預測)的差異。例如,貸款批准率的差異。選擇率指的是每個類別中被分類為 1 的數據點比例(在二元分類中)或預測值的分佈(在回歸中)。
數據分析
「如果你對數據施加足夠的壓力,它會承認任何事情。」—— Ronald Coase
這句話聽起來極端,但事實上數據確實可以被操縱以支持任何結論。有時這種操縱可能是無意的。作為人類,我們都有偏見,並且往往難以有意識地察覺自己何時在數據中引入了偏見。保證 AI 和機器學習的公平性仍然是一個複雜的挑戰。
數據是傳統模型性能指標的一個巨大盲點。您可能擁有高準確率,但這並不總是反映底層數據集中可能存在的偏見。例如,如果一家公司高層職位的員工數據集中女性佔 27%,男性佔 73%,那麼基於此數據訓練的招聘 AI 模型可能會主要針對男性群體進行高層職位的招聘。這種數據不平衡使模型的預測偏向某一性別,揭示了模型存在性別偏見的公平性問題。
RAI 儀表板中的數據分析元件有助於識別數據集中過度或不足代表的區域。它幫助用戶診斷由數據不平衡或缺乏特定數據群體代表性引入的錯誤和公平性問題的根本原因。這使用戶能夠根據預測和實際結果、錯誤群體以及特定特徵來可視化數據集。有時發現一個代表性不足的數據群體也可能揭示模型未能很好地學習,從而導致高錯誤率。具有數據偏見的模型不僅是一個公平性問題,還表明模型不具包容性或可靠性。

使用數據分析的情境:
- 通過選擇不同的篩選器探索數據集統計,將數據切片為不同維度(也稱為群體)。
- 了解數據集在不同群體和特徵群體中的分佈。
- 確定與公平性、錯誤分析和因果關係相關的發現(來自其他儀表板元件)是否源於數據集的分佈。
- 決定在哪些區域收集更多數據,以減少由代表性問題、標籤噪音、特徵噪音、標籤偏見等因素引起的錯誤。
模型可解釋性
機器學習模型往往是黑箱。理解哪些關鍵數據特徵驅動模型的預測可能具有挑戰性。提供模型做出某種預測的透明性至關重要。例如,如果 AI 系統預測某位糖尿病患者有可能在 30 天內再次入院,它應該能夠提供支持其預測的數據。提供支持數據指標可以幫助臨床醫生或醫院做出明智的決策。此外,能夠解釋模型對個別患者的預測原因,有助於符合健康法規的問責要求。當您使用機器學習模型影響人們的生活時,了解和解釋模型行為的驅動因素至關重要。模型的可解釋性和可解釋性有助於回答以下場景中的問題:
- 模型調試:為什麼我的模型會犯這個錯誤?如何改進我的模型?
- 人機協作:如何理解並信任模型的決策?
- 法規合規:我的模型是否符合法律要求?
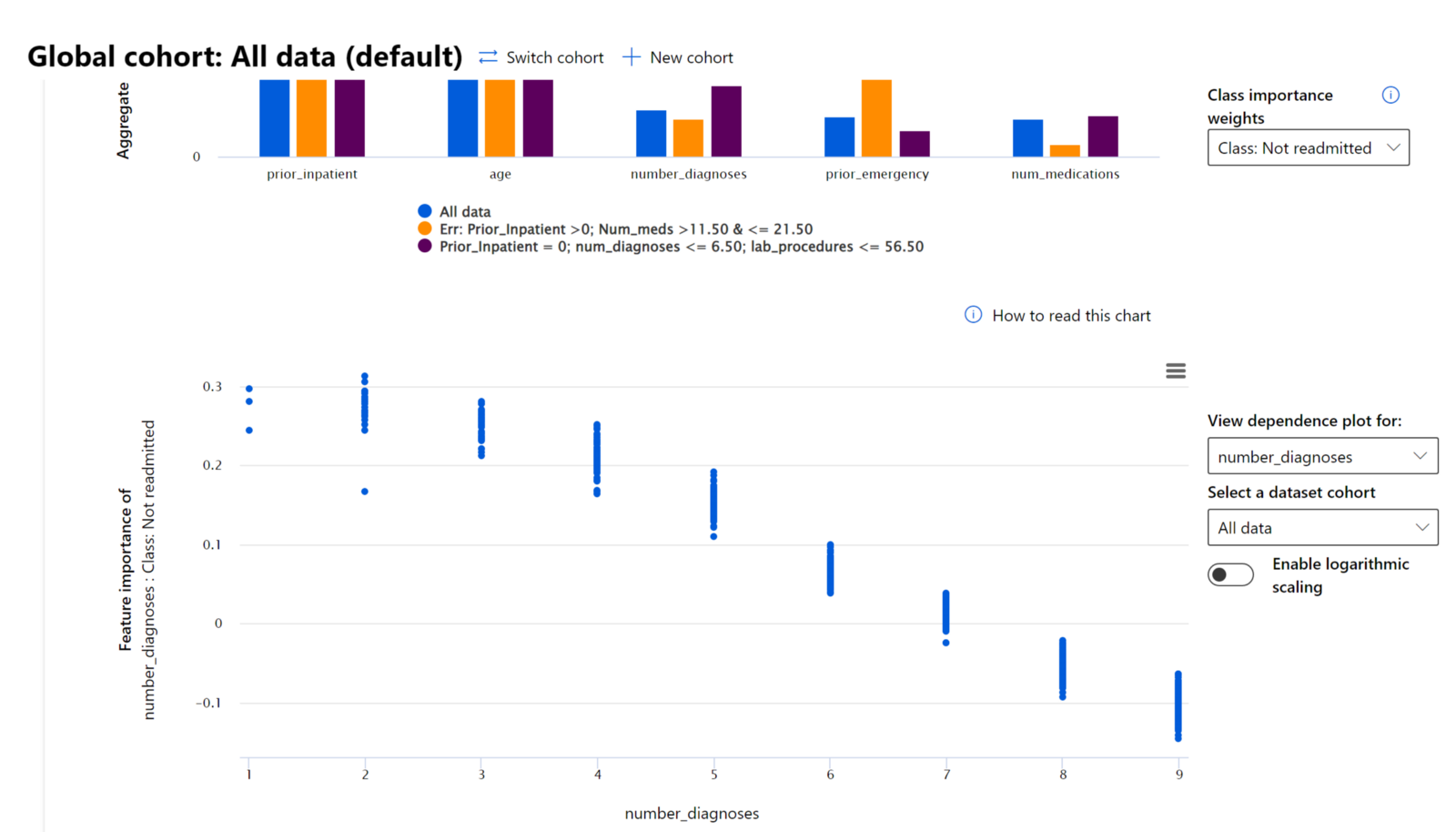
RAI 儀表板中的特徵重要性元件幫助您調試並全面了解模型如何進行預測。它也是機器學習專業人士和決策者解釋模型行為並提供證據以符合法規要求的有用工具。接下來,用戶可以探索全局和局部解釋,驗證哪些特徵驅動模型的預測。全局解釋列出影響模型整體預測的主要特徵。局部解釋顯示哪些特徵導致模型對個別案例的預測。評估局部解釋還有助於調試或審核特定案例,以更好地理解和解釋模型做出準確或不準確預測的原因。
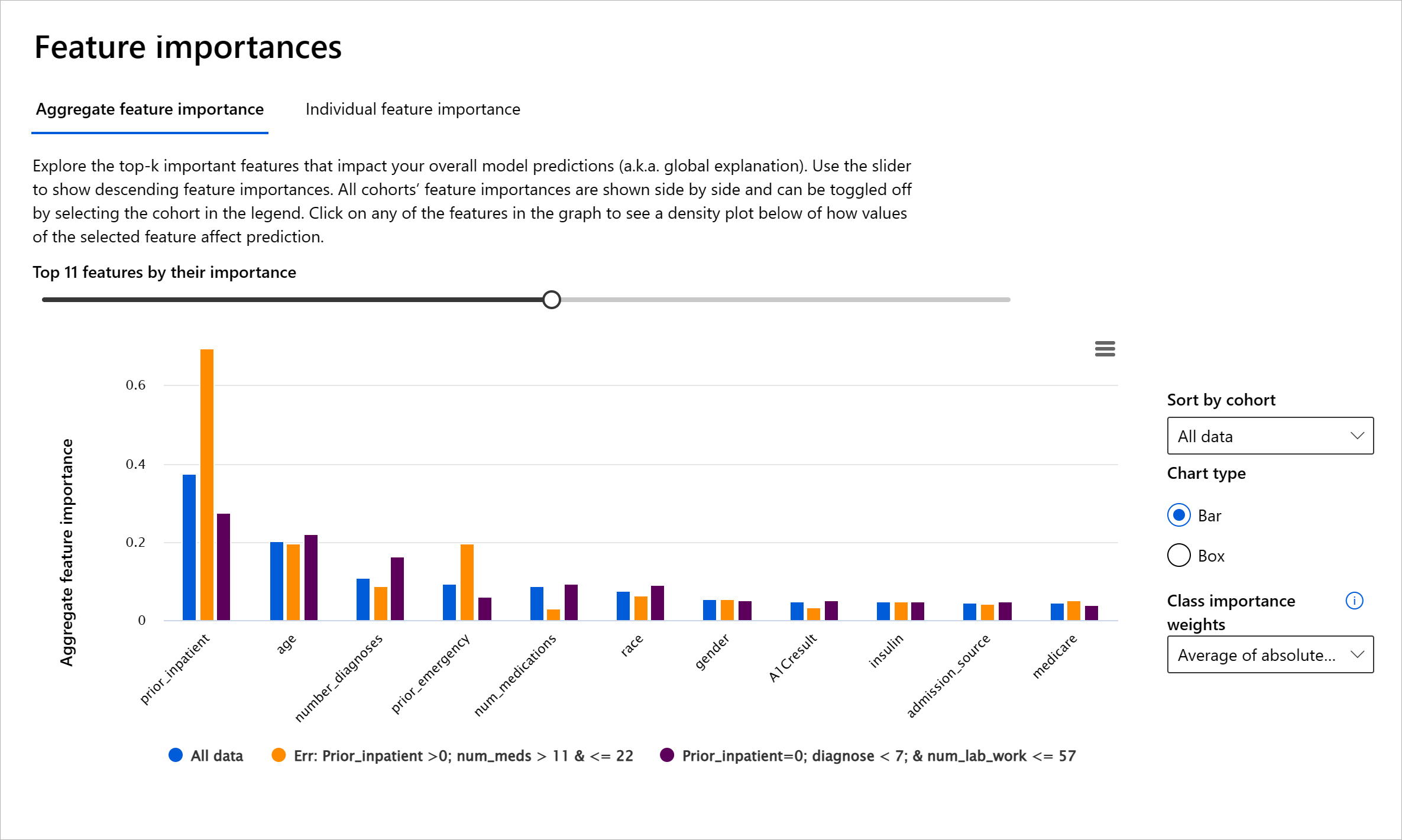
- 全局解釋:例如,哪些特徵影響糖尿病患者入院模型的整體行為?
- 局部解釋:例如,為什麼一位年齡超過 60 歲且有過住院史的糖尿病患者被預測為會或不會在 30 天內再次入院?
在調試模型性能的過程中,特徵重要性顯示特徵在不同群體中的影響程度。它有助於揭示異常情況,例如比較特徵在驅動模型錯誤預測中的影響程度。特徵重要性元件可以顯示特徵中的哪些值對模型結果產生正面或負面影響。例如,如果模型做出了不準確的預測,該元件使您能夠深入分析並確定哪些特徵或特徵值驅動了預測。這種細節不僅有助於調試,還在審計情境中提供透明性和問責性。最後,該元件可以幫助您識別公平性問題。例如,如果某些敏感特徵(如種族或性別)在驅動模型預測中具有高度影響力,這可能表明模型存在種族或性別偏見。
使用可解釋性的情境:
- 通過了解哪些特徵對預測最重要,判斷 AI 系統的預測是否值得信任。
- 通過先理解模型並識別模型是否使用健康特徵或僅僅是錯誤相關性,進行模型調試。
- 通過了解模型是否基於敏感特徵或與敏感特徵高度相關的特徵進行預測,揭示潛在的不公平性來源。
- 通過生成局部解釋來展示模型結果,建立用戶對模型決策的信任。
- 完成 AI 系統的法規審計,以驗證模型並監控模型決策對人類的影響。
結論
RAI 儀表板的所有元件都是幫助您構建對社會更少傷害、更值得信賴的機器學習模型的實用工具。它有助於防止對人權的威脅;避免歧視或排除某些群體的生活機會;以及減少身體或心理傷害的風險。它還通過生成局部解釋來展示模型結果,幫助建立對模型決策的信任。一些潛在的傷害可以分類為:
- 分配:例如,某一性別或種族被偏袒。
- 服務質量:如果您僅針對特定場景訓練數據,但現實情況更為複雜,可能導致服務性能不佳。
- 刻板印象:將某一群體與預先分配的屬性聯繫起來。
- 貶低:不公平地批評或標籤某事或某人。
- 過度或不足的代表性。這個概念指的是某些群體在某些職業中未被看見,而任何持續推動這種情況的服務或功能都可能造成傷害。
Azure RAI 儀表板
Azure RAI 儀表板 是基於由領先的學術機構和組織(包括 Microsoft)開發的開源工具所構建,這些工具對於資料科學家和 AI 開發者理解模型行為、發現並減輕 AI 模型中的不良問題至關重要。
🚀 挑戰
為了防止統計或資料偏差從一開始就被引入,我們應該:
- 確保系統開發者擁有多元的背景和觀點
- 投資於反映社會多樣性的資料集
- 開發更好的方法來檢測和修正偏差
思考在模型構建和使用中,現實生活中不公平的情境。還有什麼是我們應該考慮的?
課後測驗
回顧與自學
在這節課中,你學到了如何在機器學習中融入負責任 AI 的一些實用工具。
觀看這場工作坊以更深入了解相關主題:
- 負責任 AI 儀表板:實踐中操作化 RAI 的一站式平台,由 Besmira Nushi 和 Mehrnoosh Sameki 主講

🎥 點擊上方圖片觀看影片:負責任 AI 儀表板:實踐中操作化 RAI 的一站式平台,由 Besmira Nushi 和 Mehrnoosh Sameki 主講
參考以下材料以了解更多關於負責任 AI 的資訊,以及如何構建更值得信賴的模型:
-
Microsoft 的 RAI 儀表板工具,用於調試 ML 模型:負責任 AI 工具資源
-
探索負責任 AI 工具包:Github
-
Microsoft 的 RAI 資源中心:負責任 AI 資源 – Microsoft AI
-
Microsoft 的 FATE 研究小組:FATE:AI 中的公平性、問責性、透明性和倫理 - Microsoft Research
作業
免責聲明:
本文件使用 AI 翻譯服務 Co-op Translator 進行翻譯。我們致力於提供準確的翻譯,但請注意,自動翻譯可能包含錯誤或不準確之處。應以原始語言的文件作為權威來源。對於關鍵資訊,建議尋求專業人工翻譯。我們對於因使用此翻譯而產生的任何誤解或錯誤解讀概不負責。