15 KiB
요리 추천 웹 앱 만들기
이 강의에서는 이전 강의에서 배운 기술과 이 시리즈에서 사용된 맛있는 요리 데이터셋을 활용하여 분류 모델을 구축합니다. 또한 저장된 모델을 사용하여 Onnx의 웹 런타임을 활용한 작은 웹 앱을 만들 것입니다.
머신 러닝의 가장 실용적인 활용 중 하나는 추천 시스템을 구축하는 것입니다. 오늘 그 방향으로 첫걸음을 내딛어 보세요!

🎥 위 이미지를 클릭하면 제니 루퍼가 분류된 요리 데이터를 사용하여 웹 앱을 만드는 영상을 볼 수 있습니다.
강의 전 퀴즈
이 강의에서 배우게 될 내용:
- 모델을 구축하고 이를 Onnx 모델로 저장하는 방법
- Netron을 사용하여 모델을 검사하는 방법
- 웹 앱에서 모델을 사용하여 추론하는 방법
모델 구축하기
응용 머신 러닝 시스템을 구축하는 것은 비즈니스 시스템에서 이러한 기술을 활용하는 중요한 부분입니다. Onnx를 사용하면 웹 애플리케이션 내에서 모델을 사용할 수 있으며, 필요할 경우 오프라인 환경에서도 사용할 수 있습니다.
이전 강의에서는 UFO 목격에 대한 회귀 모델을 구축하고 이를 "피클링"하여 Flask 앱에서 사용했습니다. 이 아키텍처는 매우 유용하지만, 전체 스택 Python 앱이며 JavaScript 애플리케이션을 사용해야 할 수도 있습니다.
이번 강의에서는 추론을 위한 기본적인 JavaScript 기반 시스템을 구축할 수 있습니다. 먼저 모델을 훈련시키고 이를 Onnx에서 사용할 수 있도록 변환해야 합니다.
실습 - 분류 모델 훈련하기
먼저, 우리가 사용했던 정리된 요리 데이터셋을 사용하여 분류 모델을 훈련시킵니다.
-
유용한 라이브러리를 가져옵니다:
!pip install skl2onnx import pandas as pdScikit-learn 모델을 Onnx 형식으로 변환하는 데 도움이 되는 'skl2onnx'가 필요합니다.
-
이전 강의에서 했던 것처럼
read_csv()를 사용하여 CSV 파일을 읽습니다:data = pd.read_csv('../data/cleaned_cuisines.csv') data.head() -
첫 번째 두 개의 불필요한 열을 제거하고 나머지 데이터를 'X'로 저장합니다:
X = data.iloc[:,2:] X.head() -
레이블을 'y'로 저장합니다:
y = data[['cuisine']] y.head()
훈련 루틴 시작하기
우리는 정확도가 좋은 'SVC' 라이브러리를 사용할 것입니다.
-
Scikit-learn에서 적절한 라이브러리를 가져옵니다:
from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.model_selection import cross_val_score from sklearn.metrics import accuracy_score,precision_score,confusion_matrix,classification_report -
훈련 및 테스트 세트를 분리합니다:
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3) -
이전 강의에서 했던 것처럼 SVC 분류 모델을 구축합니다:
model = SVC(kernel='linear', C=10, probability=True,random_state=0) model.fit(X_train,y_train.values.ravel()) -
이제
predict()를 호출하여 모델을 테스트합니다:y_pred = model.predict(X_test) -
모델의 품질을 확인하기 위해 분류 보고서를 출력합니다:
print(classification_report(y_test,y_pred))이전에 본 것처럼 정확도가 좋습니다:
precision recall f1-score support chinese 0.72 0.69 0.70 257 indian 0.91 0.87 0.89 243 japanese 0.79 0.77 0.78 239 korean 0.83 0.79 0.81 236 thai 0.72 0.84 0.78 224 accuracy 0.79 1199 macro avg 0.79 0.79 0.79 1199 weighted avg 0.79 0.79 0.79 1199
모델을 Onnx로 변환하기
올바른 텐서 번호로 변환을 수행해야 합니다. 이 데이터셋에는 380개의 재료가 나열되어 있으므로 FloatTensorType에 해당 숫자를 기재해야 합니다.
-
텐서 번호를 380으로 설정하여 변환합니다.
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType initial_type = [('float_input', FloatTensorType([None, 380]))] options = {id(model): {'nocl': True, 'zipmap': False}} -
onx를 생성하고 model.onnx 파일로 저장합니다:
onx = convert_sklearn(model, initial_types=initial_type, options=options) with open("./model.onnx", "wb") as f: f.write(onx.SerializeToString())참고로, 변환 스크립트에서 옵션을 전달할 수 있습니다. 이 경우 'nocl'을 True로 설정하고 'zipmap'을 False로 설정했습니다. 이는 분류 모델이므로 ZipMap을 제거하여 딕셔너리 목록을 생성하지 않도록 할 수 있습니다(필요하지 않음).
nocl은 모델에 클래스 정보를 포함시키는 옵션을 나타냅니다.nocl을 'True'로 설정하여 모델 크기를 줄일 수 있습니다.
전체 노트북을 실행하면 Onnx 모델이 생성되어 이 폴더에 저장됩니다.
모델 보기
Onnx 모델은 Visual Studio Code에서 잘 보이지 않지만, 많은 연구자들이 모델이 제대로 구축되었는지 확인하기 위해 사용하는 매우 좋은 무료 소프트웨어가 있습니다. Netron을 다운로드하여 model.onnx 파일을 열어보세요. 380개의 입력과 분류기가 나열된 간단한 모델을 시각화할 수 있습니다:
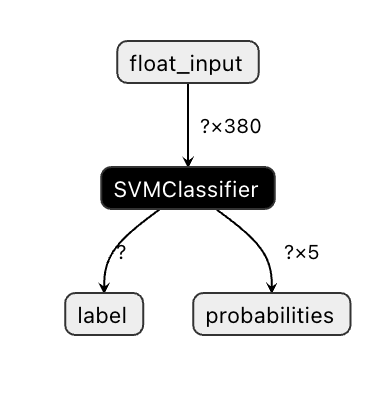
Netron은 모델을 보는 데 유용한 도구입니다.
이제 이 멋진 모델을 웹 앱에서 사용할 준비가 되었습니다. 냉장고를 열어 남은 재료를 조합하여 모델이 결정한 요리를 만들 수 있는 앱을 만들어 봅시다.
추천 웹 애플리케이션 만들기
모델을 웹 앱에서 직접 사용할 수 있습니다. 이 아키텍처를 사용하면 로컬에서 실행하거나 필요할 경우 오프라인에서도 실행할 수 있습니다. model.onnx 파일이 저장된 동일한 폴더에 index.html 파일을 생성하세요.
-
이 파일 _index.html_에 다음 마크업을 추가합니다:
<!DOCTYPE html> <html> <header> <title>Cuisine Matcher</title> </header> <body> ... </body> </html> -
이제
body태그 내에서 몇 가지 재료를 반영하는 체크박스 목록을 표시하는 마크업을 추가합니다:<h1>Check your refrigerator. What can you create?</h1> <div id="wrapper"> <div class="boxCont"> <input type="checkbox" value="4" class="checkbox"> <label>apple</label> </div> <div class="boxCont"> <input type="checkbox" value="247" class="checkbox"> <label>pear</label> </div> <div class="boxCont"> <input type="checkbox" value="77" class="checkbox"> <label>cherry</label> </div> <div class="boxCont"> <input type="checkbox" value="126" class="checkbox"> <label>fenugreek</label> </div> <div class="boxCont"> <input type="checkbox" value="302" class="checkbox"> <label>sake</label> </div> <div class="boxCont"> <input type="checkbox" value="327" class="checkbox"> <label>soy sauce</label> </div> <div class="boxCont"> <input type="checkbox" value="112" class="checkbox"> <label>cumin</label> </div> </div> <div style="padding-top:10px"> <button onClick="startInference()">What kind of cuisine can you make?</button> </div>각 체크박스에 값이 부여된 것을 확인하세요. 이는 데이터셋에 따라 재료가 발견되는 인덱스를 반영합니다. 예를 들어, 사과는 이 알파벳 목록에서 다섯 번째 열을 차지하므로 값이 '4'입니다(0부터 시작). 재료 스프레드시트를 참조하여 특정 재료의 인덱스를 확인할 수 있습니다.
index.html 파일 작업을 계속하면서 마지막 닫는
</div>뒤에 스크립트 블록을 추가하여 모델을 호출합니다. -
먼저 Onnx Runtime을 가져옵니다:
<script src="https://cdn.jsdelivr.net/npm/onnxruntime-web@1.9.0/dist/ort.min.js"></script>Onnx Runtime은 다양한 하드웨어 플랫폼에서 Onnx 모델을 실행할 수 있도록 최적화와 API를 제공합니다.
-
런타임이 설정되면 이를 호출할 수 있습니다:
<script> const ingredients = Array(380).fill(0); const checks = [...document.querySelectorAll('.checkbox')]; checks.forEach(check => { check.addEventListener('change', function() { // toggle the state of the ingredient // based on the checkbox's value (1 or 0) ingredients[check.value] = check.checked ? 1 : 0; }); }); function testCheckboxes() { // validate if at least one checkbox is checked return checks.some(check => check.checked); } async function startInference() { let atLeastOneChecked = testCheckboxes() if (!atLeastOneChecked) { alert('Please select at least one ingredient.'); return; } try { // create a new session and load the model. const session = await ort.InferenceSession.create('./model.onnx'); const input = new ort.Tensor(new Float32Array(ingredients), [1, 380]); const feeds = { float_input: input }; // feed inputs and run const results = await session.run(feeds); // read from results alert('You can enjoy ' + results.label.data[0] + ' cuisine today!') } catch (e) { console.log(`failed to inference ONNX model`); console.error(e); } } </script>
이 코드에서는 여러 가지 작업이 이루어집니다:
- 380개의 가능한 값(1 또는 0)을 설정하고, 선택된 재료 체크박스에 따라 모델에 추론을 위해 보낼 배열을 생성합니다.
- 체크박스 배열을 생성하고 애플리케이션이 시작될 때 호출되는
init함수에서 체크박스가 선택되었는지 확인하는 방법을 만듭니다. 체크박스가 선택되면ingredients배열이 선택된 재료를 반영하도록 변경됩니다. - 체크박스가 선택되었는지 확인하는
testCheckboxes함수를 생성합니다. - 버튼이 눌리면
startInference함수를 사용하여 추론을 시작합니다. 체크박스가 선택된 경우 추론을 시작합니다. - 추론 루틴에는 다음이 포함됩니다:
- 모델을 비동기로 로드 설정
- 모델에 보낼 텐서 구조 생성
- 훈련 시 생성한 모델의
float_input입력을 반영하는 'feeds' 생성(Netron을 사용하여 이름을 확인할 수 있음) - 이 'feeds'를 모델에 보내고 응답을 기다림
애플리케이션 테스트하기
Visual Studio Code에서 index.html 파일이 있는 폴더에서 터미널 세션을 엽니다. http-server가 전역적으로 설치되어 있는지 확인하고 프롬프트에서 http-server를 입력하세요. 로컬호스트가 열리며 웹 앱을 볼 수 있습니다. 다양한 재료를 기반으로 추천된 요리를 확인하세요:
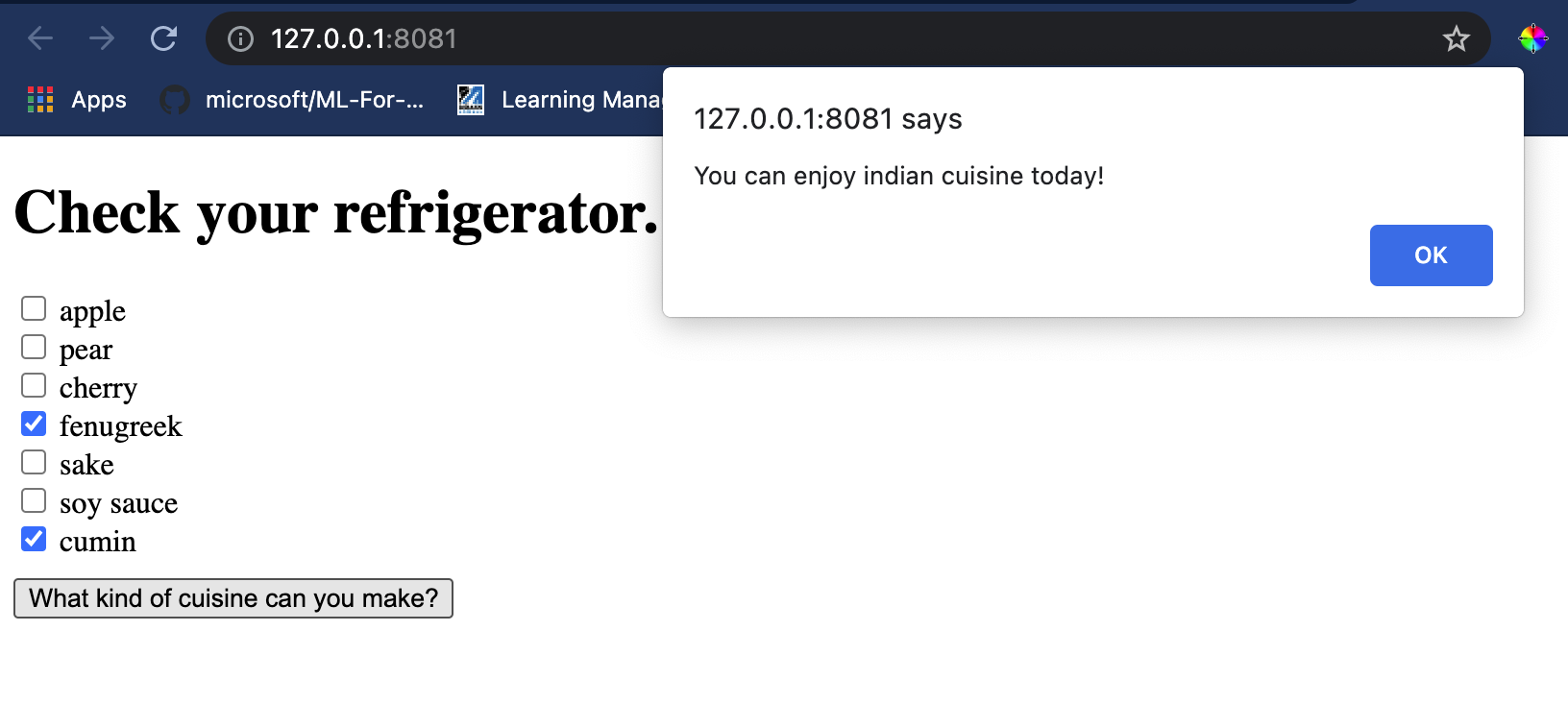
축하합니다! 몇 가지 필드가 있는 '추천' 웹 앱을 만들었습니다. 이 시스템을 구축하는 데 시간을 더 투자해 보세요!
🚀도전 과제
웹 앱이 매우 간단하므로 ingredient_indexes 데이터의 재료와 인덱스를 사용하여 계속 확장해 보세요. 어떤 맛 조합이 특정 국가 요리를 만드는 데 적합한지 알아보세요.
강의 후 퀴즈
복습 및 자기 학습
이 강의에서는 음식 재료를 위한 추천 시스템을 만드는 유용성에 대해 간단히 다뤘지만, 이 분야의 머신 러닝 응용 프로그램은 예제가 매우 풍부합니다. 이러한 시스템이 어떻게 구축되는지에 대해 더 읽어보세요:
- https://www.sciencedirect.com/topics/computer-science/recommendation-engine
- https://www.technologyreview.com/2014/08/25/171547/the-ultimate-challenge-for-recommendation-engines/
- https://www.technologyreview.com/2015/03/23/168831/everything-is-a-recommendation/
과제
면책 조항:
이 문서는 AI 번역 서비스 Co-op Translator를 사용하여 번역되었습니다. 정확성을 위해 최선을 다하고 있으나, 자동 번역에는 오류나 부정확성이 포함될 수 있습니다. 원본 문서를 해당 언어로 작성된 상태에서 권위 있는 자료로 간주해야 합니다. 중요한 정보의 경우, 전문적인 인간 번역을 권장합니다. 이 번역 사용으로 인해 발생하는 오해나 잘못된 해석에 대해 당사는 책임을 지지 않습니다.