16 KiB
Introduzione a Python e Scikit-learn per modelli di regressione

Sketchnote di Tomomi Imura
Quiz pre-lezione
Questa lezione è disponibile in R!
Introduzione
In queste quattro lezioni, scoprirai come costruire modelli di regressione. Discuteremo a breve a cosa servono. Ma prima di fare qualsiasi cosa, assicurati di avere gli strumenti giusti per iniziare il processo!
In questa lezione imparerai a:
- Configurare il tuo computer per attività di machine learning locale.
- Lavorare con i notebook Jupyter.
- Utilizzare Scikit-learn, inclusa l'installazione.
- Esplorare la regressione lineare con un esercizio pratico.
Installazioni e configurazioni

🎥 Clicca sull'immagine sopra per un breve video su come configurare il tuo computer per il ML.
-
Installa Python. Assicurati che Python sia installato sul tuo computer. Utilizzerai Python per molte attività di data science e machine learning. La maggior parte dei sistemi informatici include già un'installazione di Python. Sono disponibili utili Python Coding Packs per semplificare la configurazione per alcuni utenti.
Alcuni utilizzi di Python richiedono una versione specifica del software, mentre altri ne richiedono una diversa. Per questo motivo, è utile lavorare all'interno di un ambiente virtuale.
-
Installa Visual Studio Code. Assicurati di avere Visual Studio Code installato sul tuo computer. Segui queste istruzioni per installare Visual Studio Code per l'installazione di base. Utilizzerai Python in Visual Studio Code in questo corso, quindi potrebbe essere utile ripassare come configurare Visual Studio Code per lo sviluppo in Python.
Familiarizza con Python lavorando attraverso questa raccolta di moduli Learn

🎥 Clicca sull'immagine sopra per un video: utilizzo di Python all'interno di VS Code.
-
Installa Scikit-learn, seguendo queste istruzioni. Poiché è necessario utilizzare Python 3, si consiglia di utilizzare un ambiente virtuale. Nota che, se stai installando questa libreria su un Mac M1, ci sono istruzioni speciali nella pagina collegata sopra.
-
Installa Jupyter Notebook. Dovrai installare il pacchetto Jupyter.
Il tuo ambiente di sviluppo ML
Utilizzerai notebook per sviluppare il tuo codice Python e creare modelli di machine learning. Questo tipo di file è uno strumento comune per i data scientist e può essere identificato dal suffisso o estensione .ipynb.
I notebook sono un ambiente interattivo che consente al programmatore di scrivere codice e aggiungere note e documentazione intorno al codice, il che è molto utile per progetti sperimentali o orientati alla ricerca.

🎥 Clicca sull'immagine sopra per un breve video su questo esercizio.
Esercizio - lavora con un notebook
In questa cartella troverai il file notebook.ipynb.
-
Apri notebook.ipynb in Visual Studio Code.
Un server Jupyter si avvierà con Python 3+. Troverai aree del notebook che possono essere
eseguite, ovvero blocchi di codice. Puoi eseguire un blocco di codice selezionando l'icona che sembra un pulsante di riproduzione. -
Seleziona l'icona
mde aggiungi un po' di markdown, con il seguente testo # Benvenuto nel tuo notebook.Successivamente, aggiungi del codice Python.
-
Scrivi print('hello notebook') nel blocco di codice.
-
Seleziona la freccia per eseguire il codice.
Dovresti vedere la dichiarazione stampata:
hello notebook

Puoi alternare il tuo codice con commenti per auto-documentare il notebook.
✅ Pensa per un momento a quanto sia diverso l'ambiente di lavoro di uno sviluppatore web rispetto a quello di un data scientist.
Iniziare con Scikit-learn
Ora che Python è configurato nel tuo ambiente locale e ti senti a tuo agio con i notebook Jupyter, familiarizziamo con Scikit-learn (si pronuncia sci come in science). Scikit-learn fornisce un'API estesa per aiutarti a svolgere attività di ML.
Secondo il loro sito web, "Scikit-learn è una libreria open source di machine learning che supporta l'apprendimento supervisionato e non supervisionato. Fornisce anche vari strumenti per il fitting dei modelli, la pre-elaborazione dei dati, la selezione e la valutazione dei modelli, e molte altre utilità."
In questo corso utilizzerai Scikit-learn e altri strumenti per costruire modelli di machine learning per svolgere quelle che chiamiamo attività di 'machine learning tradizionale'. Abbiamo deliberatamente evitato reti neurali e deep learning, poiché sono meglio trattati nel nostro prossimo curriculum 'AI per principianti'.
Scikit-learn rende semplice costruire modelli e valutarli per l'uso. Si concentra principalmente sull'utilizzo di dati numerici e contiene diversi dataset pronti per l'uso come strumenti di apprendimento. Include anche modelli pre-costruiti per gli studenti da provare. Esploriamo il processo di caricamento di dati preconfezionati e utilizziamo un estimatore per il primo modello di ML con Scikit-learn con alcuni dati di base.
Esercizio - il tuo primo notebook con Scikit-learn
Questo tutorial è stato ispirato dall'esempio di regressione lineare sul sito web di Scikit-learn.

🎥 Clicca sull'immagine sopra per un breve video su questo esercizio.
Nel file notebook.ipynb associato a questa lezione, svuota tutte le celle premendo l'icona del 'cestino'.
In questa sezione lavorerai con un piccolo dataset sul diabete integrato in Scikit-learn per scopi di apprendimento. Immagina di voler testare un trattamento per pazienti diabetici. I modelli di Machine Learning potrebbero aiutarti a determinare quali pazienti risponderebbero meglio al trattamento, basandosi su combinazioni di variabili. Anche un modello di regressione molto semplice, quando visualizzato, potrebbe mostrare informazioni sulle variabili che ti aiuterebbero a organizzare i tuoi ipotetici studi clinici.
✅ Esistono molti tipi di metodi di regressione, e quale scegliere dipende dalla risposta che stai cercando. Se vuoi prevedere l'altezza probabile di una persona di una certa età, utilizzeresti la regressione lineare, poiché stai cercando un valore numerico. Se sei interessato a scoprire se un tipo di cucina dovrebbe essere considerato vegano o meno, stai cercando un assegnamento di categoria, quindi utilizzeresti la regressione logistica. Immagina alcune domande che puoi porre ai dati e quale di questi metodi sarebbe più appropriato.
Iniziamo con questo compito.
Importa librerie
Per questo compito importeremo alcune librerie:
- matplotlib. È uno strumento utile per grafici e lo utilizzeremo per creare un grafico a linee.
- numpy. numpy è una libreria utile per gestire dati numerici in Python.
- sklearn. Questa è la libreria Scikit-learn.
Importa alcune librerie per aiutarti nei tuoi compiti.
-
Aggiungi le importazioni scrivendo il seguente codice:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionSopra stai importando
matplotlib,numpye stai importandodatasets,linear_modelemodel_selectiondasklearn.model_selectionviene utilizzato per suddividere i dati in set di addestramento e test.
Il dataset sul diabete
Il dataset sul diabete integrato include 442 campioni di dati sul diabete, con 10 variabili caratteristiche, alcune delle quali includono:
- age: età in anni
- bmi: indice di massa corporea
- bp: pressione sanguigna media
- s1 tc: T-Cells (un tipo di globuli bianchi)
✅ Questo dataset include il concetto di 'sesso' come variabile caratteristica importante per la ricerca sul diabete. Molti dataset medici includono questo tipo di classificazione binaria. Pensa un po' a come categorizzazioni come questa potrebbero escludere alcune parti della popolazione dai trattamenti.
Ora, carica i dati X e y.
🎓 Ricorda, questo è apprendimento supervisionato, e abbiamo bisogno di un target 'y' nominato.
In una nuova cella di codice, carica il dataset sul diabete chiamando load_diabetes(). L'input return_X_y=True indica che X sarà una matrice di dati e y sarà il target di regressione.
-
Aggiungi alcuni comandi di stampa per mostrare la forma della matrice di dati e il suo primo elemento:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Quello che ottieni come risposta è una tupla. Quello che stai facendo è assegnare i primi due valori della tupla rispettivamente a
Xey. Scopri di più sulle tuple.Puoi vedere che questi dati hanno 442 elementi organizzati in array di 10 elementi:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Pensa un po' alla relazione tra i dati e il target di regressione. La regressione lineare prevede relazioni tra la caratteristica X e la variabile target y. Riesci a trovare il target per il dataset sul diabete nella documentazione? Cosa sta dimostrando questo dataset, dato il target?
-
Successivamente, seleziona una parte di questo dataset da tracciare selezionando la terza colonna del dataset. Puoi farlo utilizzando l'operatore
:per selezionare tutte le righe e poi selezionando la terza colonna utilizzando l'indice (2). Puoi anche rimodellare i dati per essere un array 2D - come richiesto per il tracciamento - utilizzandoreshape(n_rows, n_columns). Se uno dei parametri è -1, la dimensione corrispondente viene calcolata automaticamente.X = X[:, 2] X = X.reshape((-1,1))✅ In qualsiasi momento, stampa i dati per verificarne la forma.
-
Ora che hai i dati pronti per essere tracciati, puoi vedere se una macchina può aiutarti a determinare una divisione logica tra i numeri in questo dataset. Per fare ciò, devi dividere sia i dati (X) che il target (y) in set di test e di addestramento. Scikit-learn ha un modo semplice per farlo; puoi dividere i tuoi dati di test in un punto specifico.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Ora sei pronto per addestrare il tuo modello! Carica il modello di regressione lineare e addestralo con i tuoi set di addestramento X e y utilizzando
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()è una funzione che vedrai in molte librerie di ML come TensorFlow. -
Successivamente, crea una previsione utilizzando i dati di test, utilizzando la funzione
predict(). Questo sarà utilizzato per tracciare la linea tra i gruppi di dati.y_pred = model.predict(X_test) -
Ora è il momento di mostrare i dati in un grafico. Matplotlib è uno strumento molto utile per questo compito. Crea un grafico a dispersione di tutti i dati di test X e y e utilizza la previsione per tracciare una linea nel punto più appropriato, tra i gruppi di dati del modello.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()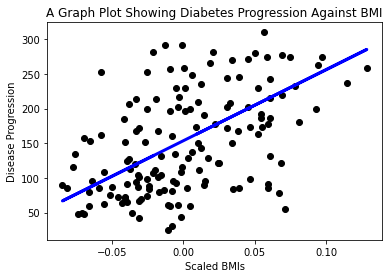 ✅ Pensa un po' a cosa sta succedendo qui. Una linea retta attraversa molti piccoli punti di dati, ma cosa sta facendo esattamente? Riesci a vedere come questa linea dovrebbe permetterti di prevedere dove un nuovo punto dati, mai visto prima, dovrebbe posizionarsi in relazione all'asse y del grafico? Prova a mettere in parole l'utilità pratica di questo modello.
✅ Pensa un po' a cosa sta succedendo qui. Una linea retta attraversa molti piccoli punti di dati, ma cosa sta facendo esattamente? Riesci a vedere come questa linea dovrebbe permetterti di prevedere dove un nuovo punto dati, mai visto prima, dovrebbe posizionarsi in relazione all'asse y del grafico? Prova a mettere in parole l'utilità pratica di questo modello.
Congratulazioni, hai costruito il tuo primo modello di regressione lineare, creato una previsione con esso e l'hai visualizzata in un grafico!
🚀Sfida
Traccia un'altra variabile da questo dataset. Suggerimento: modifica questa riga: X = X[:,2]. Considerando il target di questo dataset, cosa riesci a scoprire sulla progressione del diabete come malattia?
Quiz post-lezione
Revisione & Studio Autonomo
In questo tutorial, hai lavorato con la regressione lineare semplice, piuttosto che con la regressione univariata o multipla. Leggi un po' sulle differenze tra questi metodi, oppure dai un'occhiata a questo video.
Leggi di più sul concetto di regressione e pensa a quali tipi di domande possono essere risposte con questa tecnica. Segui questo tutorial per approfondire la tua comprensione.
Compito
Disclaimer:
Questo documento è stato tradotto utilizzando il servizio di traduzione automatica Co-op Translator. Sebbene ci impegniamo per garantire l'accuratezza, si prega di notare che le traduzioni automatiche possono contenere errori o imprecisioni. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale effettuata da un traduttore umano. Non siamo responsabili per eventuali incomprensioni o interpretazioni errate derivanti dall'uso di questa traduzione.