18 KiB
Costruire soluzioni di Machine Learning con AI responsabile
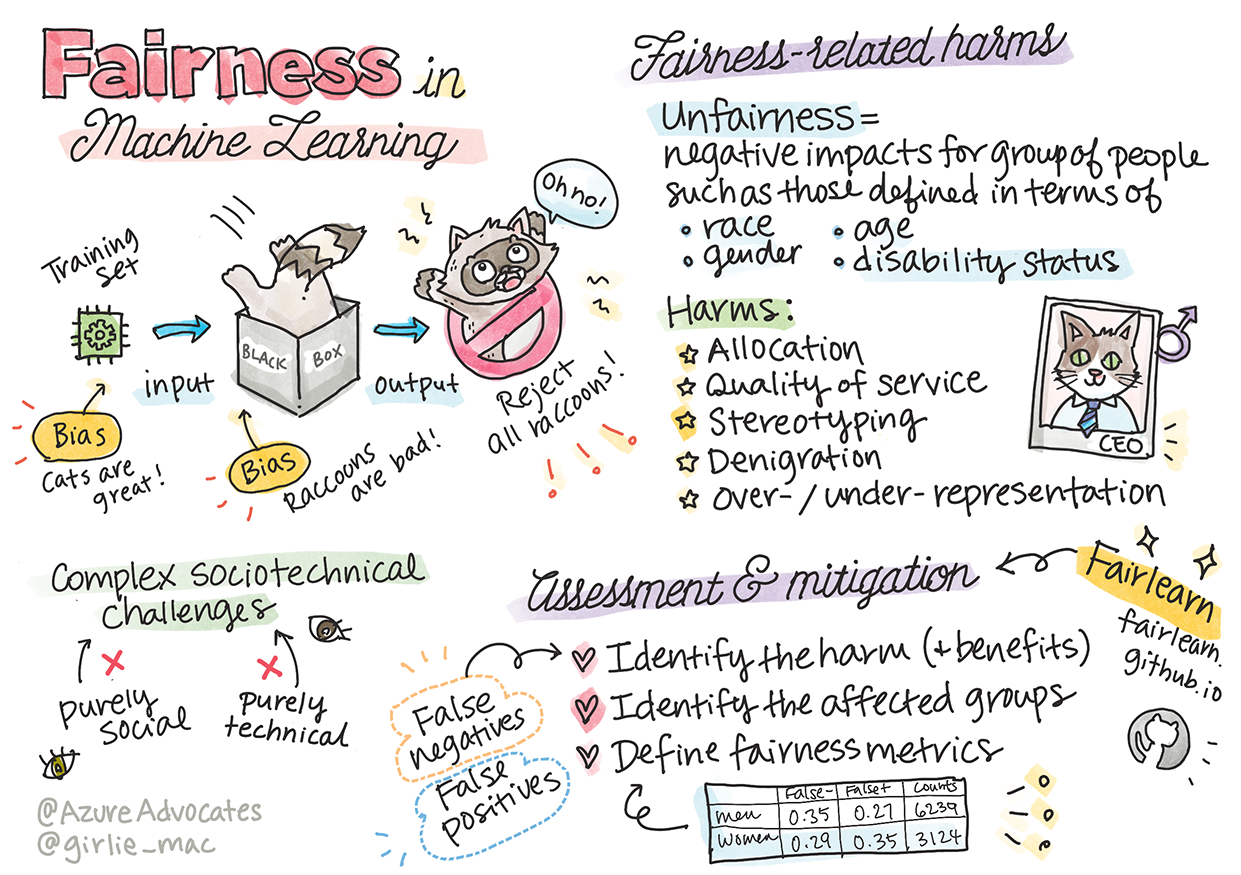
Sketchnote di Tomomi Imura
Quiz pre-lezione
Introduzione
In questo curriculum, inizierai a scoprire come il machine learning può influenzare e sta influenzando la nostra vita quotidiana. Anche ora, sistemi e modelli sono coinvolti in attività decisionali quotidiane, come diagnosi sanitarie, approvazioni di prestiti o rilevamento di frodi. È quindi importante che questi modelli funzionino bene per fornire risultati affidabili. Come qualsiasi applicazione software, i sistemi di AI possono non soddisfare le aspettative o avere risultati indesiderati. Per questo motivo, è essenziale essere in grado di comprendere e spiegare il comportamento di un modello di AI.
Immagina cosa può accadere quando i dati utilizzati per costruire questi modelli mancano di determinate demografie, come razza, genere, opinioni politiche, religione, o rappresentano in modo sproporzionato tali demografie. E se l'output del modello fosse interpretato in modo da favorire alcune demografie? Quali sarebbero le conseguenze per l'applicazione? Inoltre, cosa succede quando il modello ha un risultato negativo e danneggia le persone? Chi è responsabile del comportamento dei sistemi di AI? Queste sono alcune delle domande che esploreremo in questo curriculum.
In questa lezione, imparerai a:
- Aumentare la consapevolezza sull'importanza dell'equità nel machine learning e sui danni correlati all'equità.
- Familiarizzare con la pratica di esplorare outlier e scenari insoliti per garantire affidabilità e sicurezza.
- Comprendere la necessità di progettare sistemi inclusivi per potenziare tutti.
- Esplorare quanto sia vitale proteggere la privacy e la sicurezza dei dati e delle persone.
- Riconoscere l'importanza di un approccio trasparente per spiegare il comportamento dei modelli di AI.
- Essere consapevoli di come la responsabilità sia essenziale per costruire fiducia nei sistemi di AI.
Prerequisiti
Come prerequisito, segui il percorso di apprendimento "Principi di AI responsabile" e guarda il video qui sotto sull'argomento:
Scopri di più sull'AI responsabile seguendo questo Percorso di apprendimento

🎥 Clicca sull'immagine sopra per un video: Approccio di Microsoft all'AI responsabile
Equità
I sistemi di AI dovrebbero trattare tutti equamente ed evitare di influenzare gruppi simili di persone in modi diversi. Ad esempio, quando i sistemi di AI forniscono indicazioni su trattamenti medici, richieste di prestiti o occupazione, dovrebbero fare le stesse raccomandazioni a tutti con sintomi, circostanze finanziarie o qualifiche professionali simili. Ognuno di noi, come esseri umani, porta con sé bias ereditati che influenzano le nostre decisioni e azioni. Questi bias possono essere evidenti nei dati che utilizziamo per addestrare i sistemi di AI. Tali manipolazioni possono talvolta accadere involontariamente. Spesso è difficile sapere consapevolmente quando si sta introducendo un bias nei dati.
“Ingiustizia” comprende impatti negativi, o “danni”, per un gruppo di persone, come quelli definiti in termini di razza, genere, età o stato di disabilità. I principali danni correlati all'equità possono essere classificati come:
- Allocazione, se un genere o un'etnia, ad esempio, è favorito rispetto a un altro.
- Qualità del servizio. Se i dati sono addestrati per uno scenario specifico ma la realtà è molto più complessa, si ottiene un servizio di scarsa qualità. Ad esempio, un dispenser di sapone che non riesce a rilevare persone con pelle scura. Riferimento
- Denigrazione. Criticare ingiustamente e etichettare qualcosa o qualcuno. Ad esempio, una tecnologia di etichettatura delle immagini ha etichettato erroneamente immagini di persone con pelle scura come gorilla.
- Sovra- o sotto-rappresentazione. L'idea che un certo gruppo non sia visibile in una certa professione, e qualsiasi servizio o funzione che continui a promuovere ciò contribuisce al danno.
- Stereotipizzazione. Associare un determinato gruppo a attributi preassegnati. Ad esempio, un sistema di traduzione tra inglese e turco potrebbe avere imprecisioni dovute a parole con associazioni stereotipate di genere.
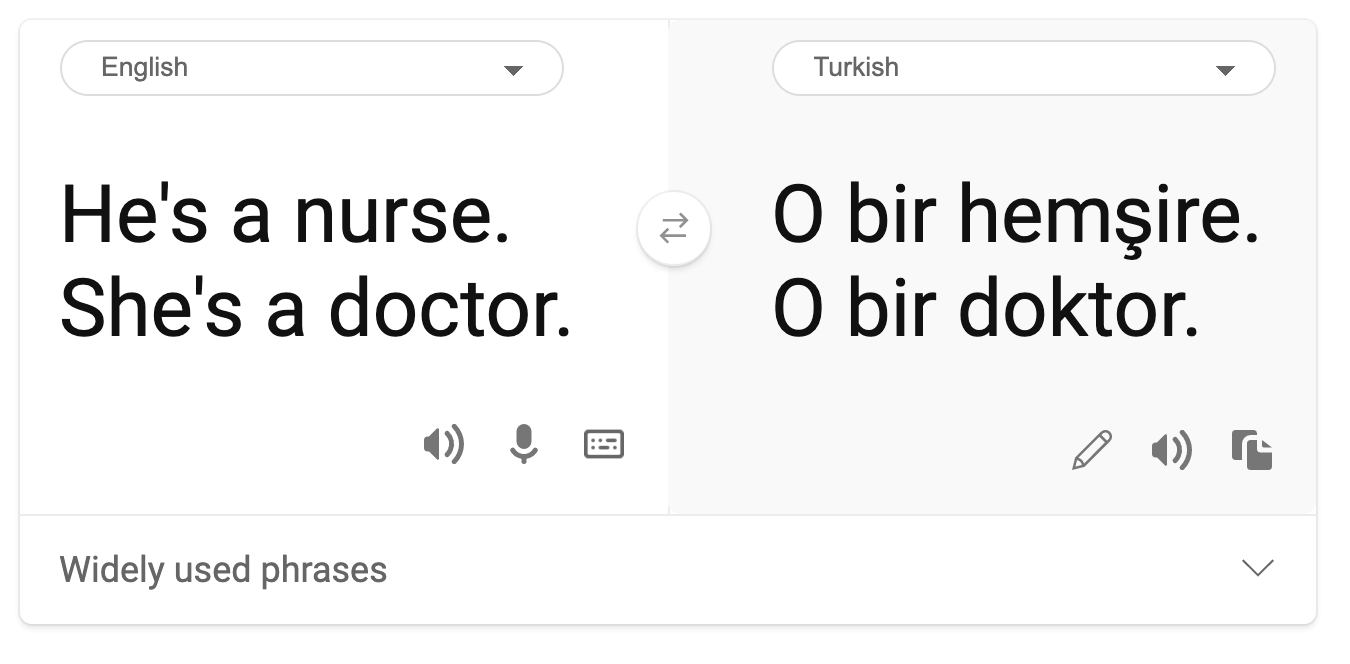
traduzione in turco

traduzione di ritorno in inglese
Quando progettiamo e testiamo sistemi di AI, dobbiamo garantire che l'AI sia equa e non programmata per prendere decisioni discriminatorie o di parte, che anche gli esseri umani sono proibiti dal prendere. Garantire l'equità nell'AI e nel machine learning rimane una sfida sociotecnica complessa.
Affidabilità e sicurezza
Per costruire fiducia, i sistemi di AI devono essere affidabili, sicuri e coerenti in condizioni normali e inattese. È importante sapere come i sistemi di AI si comporteranno in una varietà di situazioni, specialmente quando si tratta di outlier. Quando si costruiscono soluzioni di AI, è necessario concentrarsi in modo sostanziale su come gestire una vasta gamma di circostanze che le soluzioni di AI potrebbero incontrare. Ad esempio, un'auto a guida autonoma deve mettere la sicurezza delle persone come priorità assoluta. Di conseguenza, l'AI che alimenta l'auto deve considerare tutti gli scenari possibili che l'auto potrebbe incontrare, come notte, temporali o bufere di neve, bambini che attraversano la strada, animali domestici, lavori stradali, ecc. Quanto bene un sistema di AI può gestire una vasta gamma di condizioni in modo affidabile e sicuro riflette il livello di anticipazione che il data scientist o sviluppatore di AI ha considerato durante la progettazione o il test del sistema.
Inclusività
I sistemi di AI dovrebbero essere progettati per coinvolgere e potenziare tutti. Quando progettano e implementano sistemi di AI, i data scientist e gli sviluppatori di AI identificano e affrontano potenziali barriere nel sistema che potrebbero escludere involontariamente le persone. Ad esempio, ci sono 1 miliardo di persone con disabilità in tutto il mondo. Con l'avanzamento dell'AI, possono accedere a una vasta gamma di informazioni e opportunità più facilmente nella loro vita quotidiana. Affrontando le barriere, si creano opportunità per innovare e sviluppare prodotti di AI con esperienze migliori che beneficiano tutti.
Sicurezza e privacy
I sistemi di AI dovrebbero essere sicuri e rispettare la privacy delle persone. Le persone hanno meno fiducia nei sistemi che mettono a rischio la loro privacy, informazioni o vite. Quando si addestrano modelli di machine learning, ci affidiamo ai dati per ottenere i migliori risultati. Facendo ciò, l'origine dei dati e la loro integrità devono essere considerate. Ad esempio, i dati sono stati forniti dagli utenti o sono pubblicamente disponibili? Inoltre, mentre si lavora con i dati, è cruciale sviluppare sistemi di AI che possano proteggere informazioni riservate e resistere agli attacchi. Con l'aumento dell'uso dell'AI, proteggere la privacy e garantire la sicurezza delle informazioni personali e aziendali sta diventando sempre più critico e complesso. Le questioni di privacy e sicurezza dei dati richiedono particolare attenzione per l'AI, poiché l'accesso ai dati è essenziale affinché i sistemi di AI possano fare previsioni e decisioni accurate e informate sulle persone.
- Come industria, abbiamo fatto significativi progressi nella privacy e sicurezza, alimentati in modo significativo da regolamenti come il GDPR (Regolamento Generale sulla Protezione dei Dati).
- Tuttavia, con i sistemi di AI dobbiamo riconoscere la tensione tra la necessità di più dati personali per rendere i sistemi più personali ed efficaci – e la privacy.
- Proprio come con la nascita dei computer connessi a Internet, stiamo anche assistendo a un enorme aumento del numero di problemi di sicurezza legati all'AI.
- Allo stesso tempo, abbiamo visto l'AI essere utilizzata per migliorare la sicurezza. Ad esempio, la maggior parte degli scanner antivirus moderni è guidata da euristiche di AI.
- Dobbiamo garantire che i nostri processi di Data Science si armonizzino con le ultime pratiche di privacy e sicurezza.
Trasparenza
I sistemi di AI dovrebbero essere comprensibili. Una parte cruciale della trasparenza è spiegare il comportamento dei sistemi di AI e dei loro componenti. Migliorare la comprensione dei sistemi di AI richiede che gli stakeholder comprendano come e perché funzionano, in modo che possano identificare potenziali problemi di prestazioni, preoccupazioni sulla sicurezza e privacy, bias, pratiche esclusive o risultati non intenzionali. Crediamo anche che coloro che utilizzano sistemi di AI dovrebbero essere onesti e trasparenti su quando, perché e come scelgono di implementarli, così come sui limiti dei sistemi che utilizzano. Ad esempio, se una banca utilizza un sistema di AI per supportare le sue decisioni di prestito ai consumatori, è importante esaminare i risultati e comprendere quali dati influenzano le raccomandazioni del sistema. I governi stanno iniziando a regolamentare l'AI in vari settori, quindi i data scientist e le organizzazioni devono spiegare se un sistema di AI soddisfa i requisiti normativi, specialmente quando c'è un risultato indesiderato.
- Poiché i sistemi di AI sono così complessi, è difficile capire come funzionano e interpretare i risultati.
- Questa mancanza di comprensione influisce sul modo in cui questi sistemi vengono gestiti, operativizzati e documentati.
- Ancora più importante, questa mancanza di comprensione influisce sulle decisioni prese utilizzando i risultati prodotti da questi sistemi.
Responsabilità
Le persone che progettano e implementano sistemi di AI devono essere responsabili del modo in cui i loro sistemi operano. La necessità di responsabilità è particolarmente cruciale con tecnologie sensibili come il riconoscimento facciale. Recentemente, c'è stata una crescente domanda di tecnologia di riconoscimento facciale, soprattutto da parte delle organizzazioni di polizia che vedono il potenziale della tecnologia in usi come trovare bambini scomparsi. Tuttavia, queste tecnologie potrebbero essere utilizzate da un governo per mettere a rischio le libertà fondamentali dei cittadini, ad esempio, consentendo la sorveglianza continua di individui specifici. Pertanto, i data scientist e le organizzazioni devono essere responsabili dell'impatto dei loro sistemi di AI sugli individui o sulla società.
🎥 Clicca sull'immagine sopra per un video: Avvertimenti sulla sorveglianza di massa attraverso il riconoscimento facciale
Alla fine, una delle domande più grandi per la nostra generazione, come la prima generazione che sta portando l'AI nella società, è come garantire che i computer rimangano responsabili verso le persone e come garantire che le persone che progettano i computer rimangano responsabili verso tutti gli altri.
Valutazione dell'impatto
Prima di addestrare un modello di machine learning, è importante condurre una valutazione dell'impatto per comprendere lo scopo del sistema di AI; quale sarà l'uso previsto; dove sarà implementato; e chi interagirà con il sistema. Questi aspetti sono utili per i revisori o i tester che valutano il sistema per sapere quali fattori considerare quando si identificano potenziali rischi e conseguenze attese.
Le seguenti sono aree di interesse quando si conduce una valutazione dell'impatto:
- Impatto negativo sugli individui. Essere consapevoli di eventuali restrizioni o requisiti, usi non supportati o limitazioni note che ostacolano le prestazioni del sistema è vitale per garantire che il sistema non venga utilizzato in modo da causare danni agli individui.
- Requisiti dei dati. Comprendere come e dove il sistema utilizzerà i dati consente ai revisori di esplorare eventuali requisiti di dati di cui essere consapevoli (ad esempio, regolamenti GDPR o HIPPA). Inoltre, esaminare se la fonte o la quantità di dati è sufficiente per l'addestramento.
- Riepilogo dell'impatto. Raccogliere un elenco di potenziali danni che potrebbero derivare dall'uso del sistema. Durante il ciclo di vita del ML, verificare se i problemi identificati sono mitigati o affrontati.
- Obiettivi applicabili per ciascuno dei sei principi fondamentali. Valutare se gli obiettivi di ciascun principio sono soddisfatti e se ci sono lacune.
Debugging con AI responsabile
Simile al debugging di un'applicazione software, il debugging di un sistema di AI è un processo necessario per identificare e risolvere problemi nel sistema. Ci sono molti fattori che potrebbero influenzare un modello che non funziona come previsto o in modo responsabile. La maggior parte delle metriche tradizionali di prestazione del modello sono aggregati quantitativi delle prestazioni del modello, che non sono sufficienti per analizzare come un modello viola i principi di AI responsabile. Inoltre, un modello di machine learning è una scatola nera che rende difficile capire cosa guida il suo risultato o fornire spiegazioni quando commette un errore. Più avanti in questo corso, impareremo come utilizzare il dashboard di AI responsabile per aiutare a fare debugging dei sistemi di AI. Il dashboard fornisce uno strumento olistico per i data scientist e gli sviluppatori di AI per eseguire:
- Analisi degli errori. Per identificare la distribuzione degli errori del modello che può influenzare l'equità o l'affidabilità del sistema.
- Panoramica del modello. Per scoprire dove ci sono disparità nelle prestazioni del modello tra i gruppi di dati.
- Analisi dei dati. Per comprendere la distribuzione dei dati e identificare eventuali bias nei dati che potrebbero portare a problemi di equità, inclusività e affidabilità.
- Interpretabilità del modello. Per comprendere cosa influenza o guida le previsioni del modello. Questo aiuta a spiegare il comportamento del modello, che è importante per la trasparenza e la responsabilità.
🚀 Sfida
Per prevenire l'introduzione di danni fin dall'inizio, dovremmo:
- avere una diversità di background e prospettive tra le persone che lavorano sui sistemi
- investire in dataset che riflettano la diversità della nostra società
- sviluppare metodi migliori durante il ciclo di vita del machine learning per rilevare e correggere l'AI responsabile quando si verifica
Pensa a scenari reali in cui l'inaffidabilità di un modello è evidente nella costruzione e nell'uso del modello. Cos'altro dovremmo considerare?
Quiz post-lezione
Revisione e studio autonomo
In questa lezione, hai appreso alcune basi dei concetti di equità e ingiustizia nel machine learning. Guarda questo workshop per approfondire gli argomenti:
- Alla ricerca di un'IA responsabile: Portare i principi nella pratica con Besmira Nushi, Mehrnoosh Sameki e Amit Sharma

🎥 Clicca sull'immagine sopra per un video: RAI Toolbox: Un framework open-source per costruire un'IA responsabile con Besmira Nushi, Mehrnoosh Sameki e Amit Sharma
Leggi anche:
-
Centro risorse RAI di Microsoft: Responsible AI Resources – Microsoft AI
-
Gruppo di ricerca FATE di Microsoft: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Leggi gli strumenti di Azure Machine Learning per garantire l'equità:
Compito
Disclaimer:
Questo documento è stato tradotto utilizzando il servizio di traduzione automatica Co-op Translator. Sebbene ci impegniamo per garantire l'accuratezza, si prega di notare che le traduzioni automatiche possono contenere errori o imprecisioni. Il documento originale nella sua lingua nativa dovrebbe essere considerato la fonte autorevole. Per informazioni critiche, si raccomanda una traduzione professionale effettuata da un traduttore umano. Non siamo responsabili per eventuali incomprensioni o interpretazioni errate derivanti dall'uso di questa traduzione.