|
|
2 weeks ago | |
|---|---|---|
| .. | ||
| solution | 2 weeks ago | |
| README.md | 2 weeks ago | |
| assignment.md | 2 weeks ago | |
| notebook.ipynb | 2 weeks ago | |
README.md
Memulai dengan Python dan Scikit-learn untuk model regresi

Sketchnote oleh Tomomi Imura
Kuis sebelum pelajaran
Pelajaran ini tersedia dalam R!
Pendahuluan
Dalam empat pelajaran ini, Anda akan mempelajari cara membangun model regresi. Kita akan membahas kegunaannya sebentar lagi. Namun sebelum memulai, pastikan Anda memiliki alat yang tepat untuk memulai proses ini!
Dalam pelajaran ini, Anda akan belajar:
- Mengonfigurasi komputer Anda untuk tugas pembelajaran mesin lokal.
- Bekerja dengan Jupyter notebook.
- Menggunakan Scikit-learn, termasuk instalasi.
- Mengeksplorasi regresi linier melalui latihan langsung.
Instalasi dan konfigurasi

🎥 Klik gambar di atas untuk video singkat tentang cara mengonfigurasi komputer Anda untuk ML.
-
Instal Python. Pastikan Python sudah terinstal di komputer Anda. Anda akan menggunakan Python untuk banyak tugas ilmu data dan pembelajaran mesin. Sebagian besar sistem komputer sudah memiliki instalasi Python. Ada juga Python Coding Packs yang berguna untuk mempermudah pengaturan bagi beberapa pengguna.
Namun, beberapa penggunaan Python memerlukan satu versi perangkat lunak, sementara yang lain memerlukan versi yang berbeda. Oleh karena itu, sangat berguna untuk bekerja dalam lingkungan virtual.
-
Instal Visual Studio Code. Pastikan Anda memiliki Visual Studio Code yang terinstal di komputer Anda. Ikuti petunjuk ini untuk menginstal Visual Studio Code untuk instalasi dasar. Anda akan menggunakan Python di Visual Studio Code dalam kursus ini, jadi Anda mungkin ingin mempelajari cara mengonfigurasi Visual Studio Code untuk pengembangan Python.
Biasakan diri dengan Python dengan mempelajari koleksi modul pembelajaran

🎥 Klik gambar di atas untuk video: menggunakan Python dalam VS Code.
-
Instal Scikit-learn, dengan mengikuti petunjuk ini. Karena Anda perlu memastikan bahwa Anda menggunakan Python 3, disarankan untuk menggunakan lingkungan virtual. Perhatikan, jika Anda menginstal pustaka ini di Mac M1, ada petunjuk khusus di halaman yang ditautkan di atas.
-
Instal Jupyter Notebook. Anda perlu menginstal paket Jupyter.
Lingkungan penulisan ML Anda
Anda akan menggunakan notebook untuk mengembangkan kode Python Anda dan membuat model pembelajaran mesin. Jenis file ini adalah alat umum bagi ilmuwan data, dan dapat diidentifikasi dengan akhiran atau ekstensi .ipynb.
Notebook adalah lingkungan interaktif yang memungkinkan pengembang untuk menulis kode sekaligus menambahkan catatan dan dokumentasi di sekitar kode, yang sangat membantu untuk proyek eksperimental atau berbasis penelitian.

🎥 Klik gambar di atas untuk video singkat tentang latihan ini.
Latihan - bekerja dengan notebook
Di folder ini, Anda akan menemukan file notebook.ipynb.
-
Buka notebook.ipynb di Visual Studio Code.
Server Jupyter akan dimulai dengan Python 3+. Anda akan menemukan area di notebook yang dapat
dijalankan, yaitu potongan kode. Anda dapat menjalankan blok kode dengan memilih ikon yang terlihat seperti tombol putar. -
Pilih ikon
mddan tambahkan sedikit markdown, serta teks berikut # Selamat datang di notebook Anda.Selanjutnya, tambahkan beberapa kode Python.
-
Ketik print('hello notebook') di blok kode.
-
Pilih panah untuk menjalankan kode.
Anda akan melihat pernyataan yang dicetak:
hello notebook

Anda dapat menyisipkan kode Anda dengan komentar untuk mendokumentasikan notebook secara mandiri.
✅ Pikirkan sejenak tentang betapa berbedanya lingkungan kerja pengembang web dibandingkan dengan ilmuwan data.
Memulai dengan Scikit-learn
Sekarang Python telah diatur di lingkungan lokal Anda, dan Anda merasa nyaman dengan Jupyter notebook, mari kita sama-sama merasa nyaman dengan Scikit-learn (diucapkan sci seperti dalam science). Scikit-learn menyediakan API yang luas untuk membantu Anda melakukan tugas ML.
Menurut situs web mereka, "Scikit-learn adalah pustaka pembelajaran mesin sumber terbuka yang mendukung pembelajaran terawasi dan tidak terawasi. Pustaka ini juga menyediakan berbagai alat untuk fitting model, praproses data, pemilihan model, evaluasi, dan banyak utilitas lainnya."
Dalam kursus ini, Anda akan menggunakan Scikit-learn dan alat lainnya untuk membangun model pembelajaran mesin untuk melakukan apa yang kita sebut tugas 'pembelajaran mesin tradisional'. Kami sengaja menghindari jaringan saraf dan pembelajaran mendalam, karena topik tersebut lebih baik dibahas dalam kurikulum 'AI untuk Pemula' kami yang akan datang.
Scikit-learn membuatnya mudah untuk membangun model dan mengevaluasinya untuk digunakan. Pustaka ini terutama berfokus pada penggunaan data numerik dan berisi beberapa dataset siap pakai untuk digunakan sebagai alat pembelajaran. Pustaka ini juga mencakup model yang sudah dibuat sebelumnya untuk dicoba oleh siswa. Mari kita eksplorasi proses memuat data yang sudah dikemas dan menggunakan estimator bawaan untuk model ML pertama dengan Scikit-learn menggunakan data dasar.
Latihan - notebook Scikit-learn pertama Anda
Tutorial ini terinspirasi oleh contoh regresi linier di situs web Scikit-learn.

🎥 Klik gambar di atas untuk video singkat tentang latihan ini.
Di file notebook.ipynb yang terkait dengan pelajaran ini, hapus semua sel dengan menekan ikon 'tempat sampah'.
Di bagian ini, Anda akan bekerja dengan dataset kecil tentang diabetes yang sudah ada di Scikit-learn untuk tujuan pembelajaran. Bayangkan Anda ingin menguji pengobatan untuk pasien diabetes. Model Pembelajaran Mesin mungkin membantu Anda menentukan pasien mana yang akan merespons pengobatan dengan lebih baik, berdasarkan kombinasi variabel. Bahkan model regresi yang sangat dasar, ketika divisualisasikan, mungkin menunjukkan informasi tentang variabel yang dapat membantu Anda mengatur uji klinis teoritis Anda.
✅ Ada banyak jenis metode regresi, dan pilihan metode tergantung pada jawaban yang Anda cari. Jika Anda ingin memprediksi tinggi badan yang mungkin untuk seseorang berdasarkan usia tertentu, Anda akan menggunakan regresi linier, karena Anda mencari nilai numerik. Jika Anda tertarik untuk mengetahui apakah jenis masakan tertentu harus dianggap vegan atau tidak, Anda mencari penugasan kategori, sehingga Anda akan menggunakan regresi logistik. Anda akan mempelajari lebih lanjut tentang regresi logistik nanti. Pikirkan sejenak tentang beberapa pertanyaan yang dapat Anda ajukan dari data, dan metode mana yang lebih sesuai.
Mari kita mulai tugas ini.
Impor pustaka
Untuk tugas ini, kita akan mengimpor beberapa pustaka:
- matplotlib. Ini adalah alat grafik yang berguna dan akan kita gunakan untuk membuat plot garis.
- numpy. numpy adalah pustaka yang berguna untuk menangani data numerik dalam Python.
- sklearn. Ini adalah pustaka Scikit-learn.
Impor beberapa pustaka untuk membantu tugas Anda.
-
Tambahkan impor dengan mengetik kode berikut:
import matplotlib.pyplot as plt import numpy as np from sklearn import datasets, linear_model, model_selectionDi atas, Anda mengimpor
matplotlib,numpy, dan Anda mengimpordatasets,linear_model, danmodel_selectiondarisklearn.model_selectiondigunakan untuk membagi data menjadi set pelatihan dan pengujian.
Dataset diabetes
Dataset diabetes bawaan mencakup 442 sampel data tentang diabetes, dengan 10 variabel fitur, beberapa di antaranya meliputi:
- age: usia dalam tahun
- bmi: indeks massa tubuh
- bp: tekanan darah rata-rata
- s1 tc: T-Cells (jenis sel darah putih)
✅ Dataset ini mencakup konsep 'jenis kelamin' sebagai variabel fitur yang penting untuk penelitian tentang diabetes. Banyak dataset medis mencakup jenis klasifikasi biner seperti ini. Pikirkan sejenak tentang bagaimana kategorisasi seperti ini mungkin mengecualikan bagian tertentu dari populasi dari pengobatan.
Sekarang, muat data X dan y.
🎓 Ingat, ini adalah pembelajaran terawasi, dan kita membutuhkan target 'y' yang bernama.
Di sel kode baru, muat dataset diabetes dengan memanggil load_diabetes(). Input return_X_y=True menandakan bahwa X akan menjadi matriks data, dan y akan menjadi target regresi.
-
Tambahkan beberapa perintah print untuk menunjukkan bentuk matriks data dan elemen pertamanya:
X, y = datasets.load_diabetes(return_X_y=True) print(X.shape) print(X[0])Apa yang Anda dapatkan sebagai respons adalah tuple. Anda menetapkan dua nilai pertama dari tuple ke
Xdanymasing-masing. Pelajari lebih lanjut tentang tuple.Anda dapat melihat bahwa data ini memiliki 442 item yang berbentuk array dengan 10 elemen:
(442, 10) [ 0.03807591 0.05068012 0.06169621 0.02187235 -0.0442235 -0.03482076 -0.04340085 -0.00259226 0.01990842 -0.01764613]✅ Pikirkan sejenak tentang hubungan antara data dan target regresi. Regresi linier memprediksi hubungan antara fitur X dan variabel target y. Bisakah Anda menemukan target untuk dataset diabetes dalam dokumentasi? Apa yang ditunjukkan oleh dataset ini, mengingat targetnya?
-
Selanjutnya, pilih bagian dari dataset ini untuk dipetakan dengan memilih kolom ke-3 dari dataset. Anda dapat melakukannya dengan menggunakan operator
:untuk memilih semua baris, lalu memilih kolom ke-3 menggunakan indeks (2). Anda juga dapat mengubah bentuk data menjadi array 2D - seperti yang diperlukan untuk pemetaan - dengan menggunakanreshape(n_rows, n_columns). Jika salah satu parameter adalah -1, dimensi yang sesuai dihitung secara otomatis.X = X[:, 2] X = X.reshape((-1,1))✅ Kapan saja, cetak data untuk memeriksa bentuknya.
-
Sekarang setelah Anda memiliki data yang siap untuk dipetakan, Anda dapat melihat apakah mesin dapat membantu menentukan pembagian logis antara angka-angka dalam dataset ini. Untuk melakukan ini, Anda perlu membagi data (X) dan target (y) menjadi set pengujian dan pelatihan. Scikit-learn memiliki cara yang sederhana untuk melakukan ini; Anda dapat membagi data pengujian Anda pada titik tertentu.
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.33) -
Sekarang Anda siap untuk melatih model Anda! Muat model regresi linier dan latih dengan set pelatihan X dan y Anda menggunakan
model.fit():model = linear_model.LinearRegression() model.fit(X_train, y_train)✅
model.fit()adalah fungsi yang akan sering Anda lihat di banyak pustaka ML seperti TensorFlow. -
Kemudian, buat prediksi menggunakan data pengujian, dengan menggunakan fungsi
predict(). Ini akan digunakan untuk menggambar garis antara kelompok data.y_pred = model.predict(X_test) -
Sekarang saatnya untuk menunjukkan data dalam plot. Matplotlib adalah alat yang sangat berguna untuk tugas ini. Buat scatterplot dari semua data pengujian X dan y, dan gunakan prediksi untuk menggambar garis di tempat yang paling sesuai, di antara pengelompokan data model.
plt.scatter(X_test, y_test, color='black') plt.plot(X_test, y_pred, color='blue', linewidth=3) plt.xlabel('Scaled BMIs') plt.ylabel('Disease Progression') plt.title('A Graph Plot Showing Diabetes Progression Against BMI') plt.show()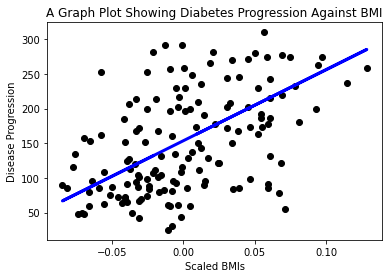 ✅ Pikirkan sebentar tentang apa yang sedang terjadi di sini. Sebuah garis lurus melewati banyak titik data kecil, tetapi apa sebenarnya yang sedang dilakukan? Bisakah Anda melihat bagaimana Anda seharusnya dapat menggunakan garis ini untuk memprediksi di mana titik data baru yang belum terlihat seharusnya berada dalam hubungannya dengan sumbu y pada plot? Cobalah untuk menjelaskan penggunaan praktis dari model ini.
✅ Pikirkan sebentar tentang apa yang sedang terjadi di sini. Sebuah garis lurus melewati banyak titik data kecil, tetapi apa sebenarnya yang sedang dilakukan? Bisakah Anda melihat bagaimana Anda seharusnya dapat menggunakan garis ini untuk memprediksi di mana titik data baru yang belum terlihat seharusnya berada dalam hubungannya dengan sumbu y pada plot? Cobalah untuk menjelaskan penggunaan praktis dari model ini.
Selamat, Anda telah membangun model regresi linear pertama Anda, membuat prediksi dengannya, dan menampilkannya dalam sebuah plot!
🚀Tantangan
Plot variabel yang berbeda dari dataset ini. Petunjuk: edit baris ini: X = X[:,2]. Berdasarkan target dataset ini, apa yang dapat Anda temukan tentang perkembangan diabetes sebagai penyakit?
Kuis setelah kuliah
Tinjauan & Studi Mandiri
Dalam tutorial ini, Anda bekerja dengan regresi linear sederhana, bukan regresi univariat atau regresi multivariat. Bacalah sedikit tentang perbedaan antara metode-metode ini, atau lihat video ini.
Pelajari lebih lanjut tentang konsep regresi dan pikirkan tentang jenis pertanyaan apa yang dapat dijawab dengan teknik ini. Ikuti tutorial ini untuk memperdalam pemahaman Anda.
Tugas
Penafian:
Dokumen ini telah diterjemahkan menggunakan layanan penerjemahan AI Co-op Translator. Meskipun kami berusaha untuk memberikan hasil yang akurat, harap diingat bahwa terjemahan otomatis mungkin mengandung kesalahan atau ketidakakuratan. Dokumen asli dalam bahasa aslinya harus dianggap sebagai sumber yang otoritatif. Untuk informasi yang bersifat kritis, disarankan menggunakan jasa penerjemahan profesional oleh manusia. Kami tidak bertanggung jawab atas kesalahpahaman atau penafsiran yang keliru yang timbul dari penggunaan terjemahan ini.