38 KiB
जिम्मेदार AI के साथ मशीन लर्निंग समाधान बनाना
स्केच नोट: Tomomi Imura
पाठ से पहले का क्विज़
परिचय
इस पाठ्यक्रम में, आप जानेंगे कि मशीन लर्निंग हमारे दैनिक जीवन को कैसे प्रभावित कर रही है। आज भी, सिस्टम और मॉडल स्वास्थ्य देखभाल निदान, ऋण स्वीकृति, या धोखाधड़ी का पता लगाने जैसे दैनिक निर्णय लेने के कार्यों में शामिल हैं। इसलिए यह महत्वपूर्ण है कि ये मॉडल भरोसेमंद परिणाम प्रदान करने के लिए अच्छी तरह से काम करें। जैसे किसी भी सॉफ़्टवेयर एप्लिकेशन में, AI सिस्टम भी अपेक्षाओं से चूक सकते हैं या अवांछनीय परिणाम दे सकते हैं। यही कारण है कि AI मॉडल के व्यवहार को समझना और समझाना आवश्यक है।
कल्पना करें कि जब आप इन मॉडलों को बनाने के लिए उपयोग किए जा रहे डेटा में कुछ जनसांख्यिकी, जैसे जाति, लिंग, राजनीतिक दृष्टिकोण, धर्म, या असमान रूप से प्रतिनिधित्व करने वाले जनसांख्यिकी की कमी हो, तो क्या हो सकता है। अगर मॉडल का आउटपुट किसी विशेष जनसांख्यिकी को प्राथमिकता देता है, तो इसका एप्लिकेशन पर क्या प्रभाव पड़ेगा? इसके अलावा, जब मॉडल का परिणाम हानिकारक हो और लोगों को नुकसान पहुंचाए, तो क्या होगा? AI सिस्टम के व्यवहार के लिए कौन जिम्मेदार होगा? ये कुछ सवाल हैं जिनकी हम इस पाठ्यक्रम में जांच करेंगे।
इस पाठ में, आप:
- मशीन लर्निंग में निष्पक्षता और इससे संबंधित हानियों के महत्व के बारे में जागरूकता बढ़ाएंगे।
- असामान्य परिदृश्यों और बाहरी मूल्यों की जांच करने की प्रक्रिया से परिचित होंगे ताकि विश्वसनीयता और सुरक्षा सुनिश्चित की जा सके।
- समावेशी सिस्टम डिज़ाइन करके सभी को सशक्त बनाने की आवश्यकता को समझेंगे।
- डेटा और लोगों की गोपनीयता और सुरक्षा की रक्षा करने के महत्व का पता लगाएंगे।
- AI मॉडल के व्यवहार को समझाने के लिए एक पारदर्शी दृष्टिकोण अपनाने के महत्व को देखेंगे।
- यह समझेंगे कि AI सिस्टम में विश्वास बनाने के लिए जवाबदेही क्यों आवश्यक है।
पूर्वापेक्षा
इस पाठ से पहले, कृपया "जिम्मेदार AI सिद्धांत" सीखने का पथ पूरा करें और नीचे दिए गए वीडियो को देखें:
जिम्मेदार AI के बारे में अधिक जानने के लिए इस लर्निंग पाथ का अनुसरण करें।

🎥 ऊपर दी गई छवि पर क्लिक करें: Microsoft का जिम्मेदार AI के प्रति दृष्टिकोण
निष्पक्षता
AI सिस्टम को सभी के साथ निष्पक्ष व्यवहार करना चाहिए और समान समूहों के लोगों को अलग-अलग तरीके से प्रभावित करने से बचना चाहिए। उदाहरण के लिए, जब AI सिस्टम चिकित्सा उपचार, ऋण आवेदन, या रोजगार पर मार्गदर्शन प्रदान करते हैं, तो उन्हें समान लक्षण, वित्तीय परिस्थितियों, या पेशेवर योग्यताओं वाले सभी लोगों को समान सिफारिशें देनी चाहिए। हम सभी मनुष्य अपनी निर्णय लेने की प्रक्रिया में अंतर्निहित पूर्वाग्रह रखते हैं। ये पूर्वाग्रह उस डेटा में भी दिखाई दे सकते हैं जिसका उपयोग हम AI सिस्टम को प्रशिक्षित करने के लिए करते हैं। कभी-कभी यह हेरफेर अनजाने में हो सकता है। यह जानबूझकर पहचानना कठिन हो सकता है कि आप डेटा में पूर्वाग्रह कब पेश कर रहे हैं।
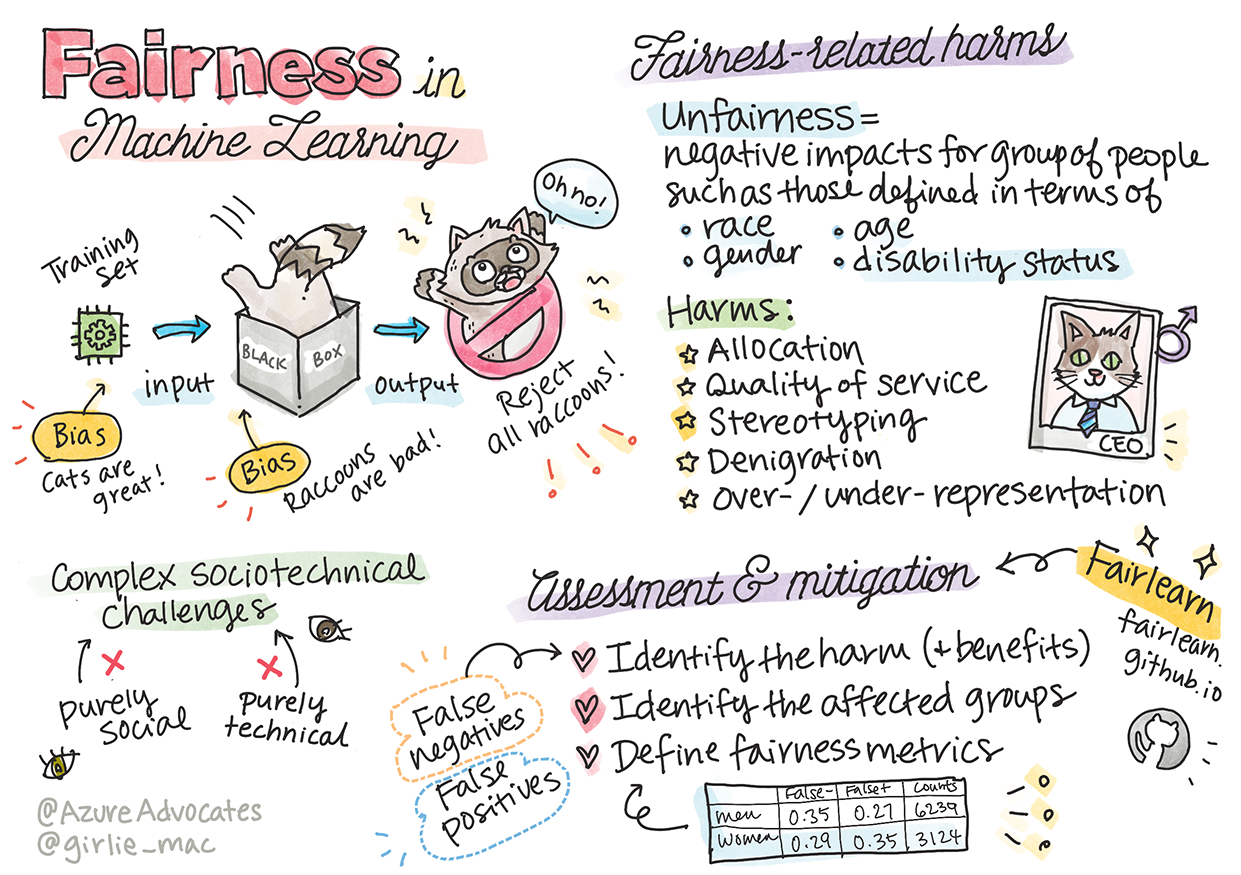
"असमानता" का मतलब है किसी समूह के लिए नकारात्मक प्रभाव या "हानियां", जैसे कि जाति, लिंग, आयु, या विकलांगता की स्थिति के संदर्भ में परिभाषित समूह। मुख्य निष्पक्षता-संबंधी हानियों को निम्नलिखित श्रेणियों में वर्गीकृत किया जा सकता है:
- आवंटन: यदि किसी लिंग या जातीयता को दूसरे पर प्राथमिकता दी जाती है।
- सेवा की गुणवत्ता: यदि आप डेटा को केवल एक विशिष्ट परिदृश्य के लिए प्रशिक्षित करते हैं, लेकिन वास्तविकता अधिक जटिल होती है, तो यह खराब प्रदर्शन वाली सेवा की ओर ले जाता है। उदाहरण के लिए, एक साबुन डिस्पेंसर जो गहरे रंग की त्वचा वाले लोगों को पहचानने में असमर्थ था। संदर्भ
- अपमान: किसी चीज़ या व्यक्ति की अनुचित आलोचना और लेबलिंग। उदाहरण के लिए, एक छवि लेबलिंग तकनीक ने काले रंग की त्वचा वाले लोगों की छवियों को गोरिल्ला के रूप में गलत लेबल किया।
- अधिक या कम प्रतिनिधित्व: यह विचार कि एक निश्चित समूह को किसी पेशे में नहीं देखा जाता है, और कोई भी सेवा या कार्य जो इसे बढ़ावा देता है, वह नुकसान में योगदान देता है।
- रूढ़िबद्धता: किसी दिए गए समूह को पूर्व-निर्धारित विशेषताओं के साथ जोड़ना। उदाहरण के लिए, अंग्रेजी और तुर्की के बीच एक भाषा अनुवाद प्रणाली में लिंग से संबंधित रूढ़ियों के कारण गलतियां हो सकती हैं।
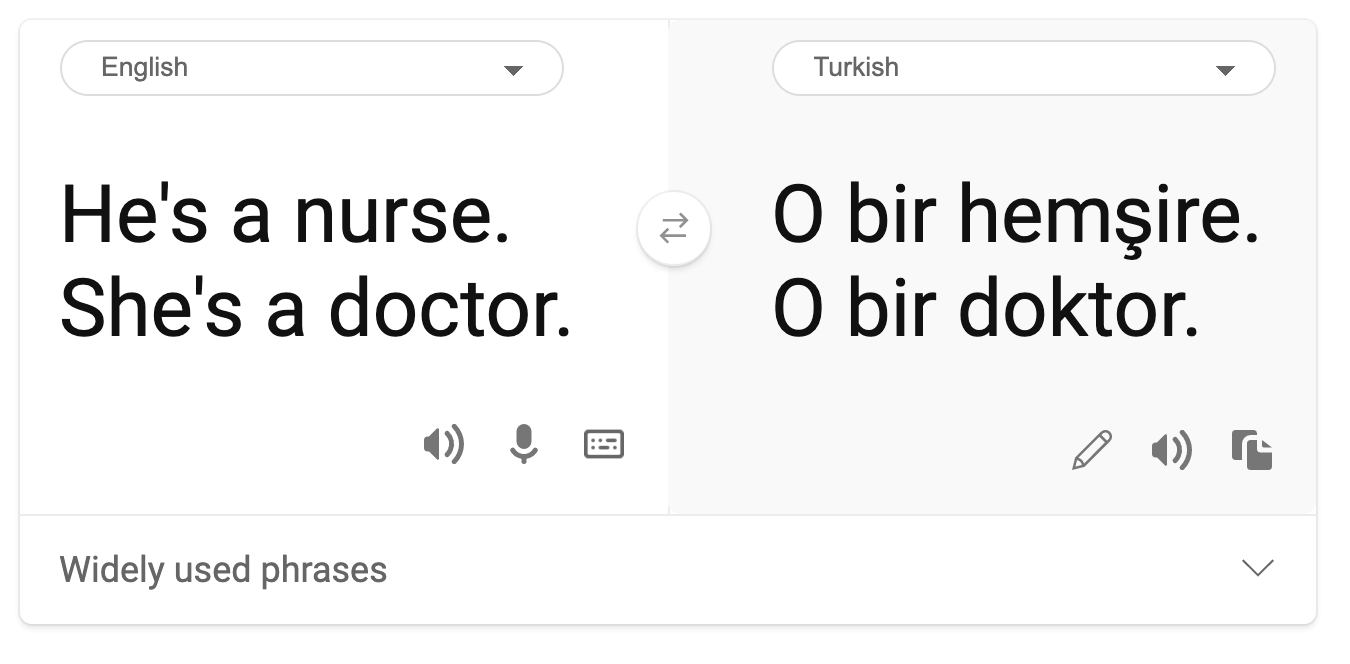
तुर्की में अनुवाद

फिर से अंग्रेजी में अनुवाद
AI सिस्टम को डिज़ाइन और परीक्षण करते समय, हमें यह सुनिश्चित करना चाहिए कि AI निष्पक्ष हो और इसे पूर्वाग्रही या भेदभावपूर्ण निर्णय लेने के लिए प्रोग्राम न किया गया हो, जो मनुष्यों के लिए भी निषिद्ध हैं। AI और मशीन लर्निंग में निष्पक्षता सुनिश्चित करना एक जटिल सामाजिक-तकनीकी चुनौती बनी हुई है।
विश्वसनीयता और सुरक्षा
विश्वास बनाने के लिए, AI सिस्टम को सामान्य और अप्रत्याशित परिस्थितियों में विश्वसनीय, सुरक्षित और सुसंगत होना चाहिए। यह जानना महत्वपूर्ण है कि AI सिस्टम विभिन्न परिस्थितियों में कैसा व्यवहार करेगा, विशेष रूप से जब वे असामान्य हों। AI समाधान बनाते समय, उन सभी संभावित परिस्थितियों को संभालने पर ध्यान केंद्रित करना आवश्यक है जिनका सामना AI समाधान कर सकता है। उदाहरण के लिए, एक स्वचालित कार को लोगों की सुरक्षा को सर्वोच्च प्राथमिकता देनी चाहिए। इसलिए, कार को चलाने वाले AI को सभी संभावित परिदृश्यों पर विचार करना चाहिए, जैसे रात, तूफान, बर्फ़ीला तूफ़ान, सड़क पर दौड़ते बच्चे, पालतू जानवर, सड़क निर्माण आदि। AI सिस्टम कितनी अच्छी तरह से विभिन्न परिस्थितियों को विश्वसनीय और सुरक्षित रूप से संभाल सकता है, यह डेटा वैज्ञानिक या AI डेवलपर द्वारा डिज़ाइन या परीक्षण के दौरान विचार किए गए पूर्वानुमान के स्तर को दर्शाता है।
समावेशिता
AI सिस्टम को सभी को शामिल करने और सशक्त बनाने के लिए डिज़ाइन किया जाना चाहिए। AI सिस्टम को डिज़ाइन और लागू करते समय, डेटा वैज्ञानिक और AI डेवलपर सिस्टम में संभावित बाधाओं की पहचान करते हैं और उन्हें संबोधित करते हैं जो अनजाने में लोगों को बाहर कर सकती हैं। उदाहरण के लिए, दुनिया भर में 1 बिलियन लोग विकलांग हैं। AI की प्रगति के साथ, वे अपने दैनिक जीवन में अधिक आसानी से जानकारी और अवसरों तक पहुंच सकते हैं। बाधाओं को दूर करके, यह नवाचार के अवसर पैदा करता है और बेहतर अनुभवों के साथ AI उत्पादों को विकसित करता है जो सभी को लाभान्वित करते हैं।
सुरक्षा और गोपनीयता
AI सिस्टम को सुरक्षित होना चाहिए और लोगों की गोपनीयता का सम्मान करना चाहिए। लोग उन सिस्टमों पर कम विश्वास करते हैं जो उनकी गोपनीयता, जानकारी, या जीवन को जोखिम में डालते हैं। मशीन लर्निंग मॉडल को प्रशिक्षित करते समय, हम सर्वोत्तम परिणाम प्राप्त करने के लिए डेटा पर निर्भर करते हैं। ऐसा करते समय, डेटा की उत्पत्ति और अखंडता पर विचार करना आवश्यक है। उदाहरण के लिए, क्या डेटा उपयोगकर्ता द्वारा प्रस्तुत किया गया था या सार्वजनिक रूप से उपलब्ध था? इसके बाद, डेटा के साथ काम करते समय, यह महत्वपूर्ण है कि AI सिस्टम गोपनीय जानकारी की रक्षा कर सके और हमलों का विरोध कर सके। जैसे-जैसे AI अधिक प्रचलित होता जा रहा है, गोपनीयता की रक्षा करना और महत्वपूर्ण व्यक्तिगत और व्यावसायिक जानकारी को सुरक्षित रखना अधिक महत्वपूर्ण और जटिल होता जा रहा है। गोपनीयता और डेटा सुरक्षा के मुद्दों को AI के लिए विशेष रूप से ध्यान देने की आवश्यकता है क्योंकि डेटा तक पहुंच AI सिस्टम को लोगों के बारे में सटीक और सूचित भविष्यवाणियां और निर्णय लेने के लिए आवश्यक है।
- उद्योग के रूप में हमने गोपनीयता और सुरक्षा में महत्वपूर्ण प्रगति की है, जो मुख्य रूप से GDPR (जनरल डेटा प्रोटेक्शन रेगुलेशन) जैसे नियमों द्वारा संचालित है।
- फिर भी AI सिस्टम के साथ हमें यह स्वीकार करना होगा कि सिस्टम को अधिक व्यक्तिगत और प्रभावी बनाने के लिए अधिक व्यक्तिगत डेटा की आवश्यकता और गोपनीयता के बीच तनाव है।
- जैसे इंटरनेट के साथ जुड़े कंप्यूटरों के जन्म के साथ, हम AI से संबंधित सुरक्षा मुद्दों की संख्या में भारी वृद्धि देख रहे हैं।
- साथ ही, हमने सुरक्षा में सुधार के लिए AI का उपयोग होते देखा है। उदाहरण के लिए, अधिकांश आधुनिक एंटी-वायरस स्कैनर आज AI ह्यूरिस्टिक्स द्वारा संचालित हैं।
- हमें यह सुनिश्चित करने की आवश्यकता है कि हमारे डेटा विज्ञान प्रक्रियाएं नवीनतम गोपनीयता और सुरक्षा प्रथाओं के साथ सामंजस्यपूर्ण रूप से मिश्रित हों।
पारदर्शिता
AI सिस्टम को समझने योग्य होना चाहिए। पारदर्शिता का एक महत्वपूर्ण हिस्सा AI सिस्टम और उनके घटकों के व्यवहार को समझाना है। AI सिस्टम की समझ में सुधार के लिए यह आवश्यक है कि हितधारक यह समझें कि वे कैसे और क्यों कार्य करते हैं ताकि वे संभावित प्रदर्शन मुद्दों, सुरक्षा और गोपनीयता चिंताओं, पूर्वाग्रहों, बहिष्करण प्रथाओं, या अनपेक्षित परिणामों की पहचान कर सकें। हम यह भी मानते हैं कि जो लोग AI सिस्टम का उपयोग करते हैं, उन्हें यह स्पष्ट और ईमानदारी से बताना चाहिए कि वे कब, क्यों, और कैसे उनका उपयोग करते हैं। साथ ही, उनके उपयोग की सीमाओं के बारे में भी जानकारी होनी चाहिए। उदाहरण के लिए, यदि कोई बैंक अपने उपभोक्ता ऋण निर्णयों का समर्थन करने के लिए AI सिस्टम का उपयोग करता है, तो यह महत्वपूर्ण है कि परिणामों की जांच की जाए और यह समझा जाए कि कौन सा डेटा सिस्टम की सिफारिशों को प्रभावित करता है। सरकारें उद्योगों में AI को विनियमित करना शुरू कर रही हैं, इसलिए डेटा वैज्ञानिकों और संगठनों को यह समझाना होगा कि AI सिस्टम नियामक आवश्यकताओं को पूरा करता है या नहीं, विशेष रूप से जब कोई अवांछनीय परिणाम होता है।
- क्योंकि AI सिस्टम इतने जटिल हैं, यह समझना कठिन है कि वे कैसे काम करते हैं और उनके परिणामों की व्याख्या कैसे करें।
- इस समझ की कमी इन सिस्टमों के प्रबंधन, संचालन, और प्रलेखन को प्रभावित करती है।
- यह समझ की कमी, विशेष रूप से, उन निर्णयों को प्रभावित करती है जो इन सिस्टमों द्वारा उत्पन्न परिणामों का उपयोग करके किए जाते हैं।
जवाबदेही
जो लोग AI सिस्टम डिज़ाइन और तैनात करते हैं, उन्हें यह सुनिश्चित करना चाहिए कि उनके सिस्टम कैसे काम करते हैं, इसके लिए वे जवाबदेह हों। जवाबदेही की आवश्यकता विशेष रूप से संवेदनशील उपयोग प्रौद्योगिकियों जैसे चेहरे की पहचान के साथ महत्वपूर्ण है। हाल ही में, चेहरे की पहचान तकनीक की मांग बढ़ रही है, विशेष रूप से कानून प्रवर्तन संगठनों से जो इस तकनीक की क्षमता को लापता बच्चों को खोजने जैसे उपयोगों में देखते हैं। हालांकि, इन तकनीकों का उपयोग सरकार द्वारा नागरिकों की मौलिक स्वतंत्रताओं को खतरे में डालने के लिए किया जा सकता है, जैसे कि विशिष्ट व्यक्तियों की निरंतर निगरानी को सक्षम करना। इसलिए, डेटा वैज्ञानिकों और संगठनों को यह सुनिश्चित करना चाहिए कि उनके AI सिस्टम का प्रभाव व्यक्तियों या समाज पर जिम्मेदार हो।
🎥 ऊपर दी गई छवि पर क्लिक करें: चेहरे की पहचान के माध्यम से बड़े पैमाने पर निगरानी की चेतावनी
आखिरकार, हमारे युग के लिए सबसे बड़े सवालों में से एक यह है कि, AI को समाज में लाने वाली पहली पीढ़ी के रूप में, हम यह कैसे सुनिश्चित करेंगे कि कंप्यूटर लोगों के प्रति जवाबदेह बने रहें और यह सुनिश्चित करें कि कंप्यूटर डिज़ाइन करने वाले लोग बाकी सभी के प्रति जवाबदेह बने रहें।
प्रभाव मूल्यांकन
मशीन लर्निंग मॉडल को प्रशिक्षित करने से पहले, AI सिस्टम के उद्देश्य को समझने के लिए प्रभाव मूल्यांकन करना महत्वपूर्ण है; इसका इरादा उपयोग क्या है; इसे कहाँ तैनात किया जाएगा; और कौन सिस्टम के साथ इंटरैक्ट करेगा। ये समीक्षक या परीक्षक के लिए सहायक होते हैं ताकि वे संभावित जोखिमों और अपेक्षित परिणामों की पहचान करते समय किन कारकों पर विचार करें, यह जान सकें।
प्रभाव मूल्यांकन करते समय ध्यान केंद्रित करने के क्षेत्र निम्नलिखित हैं:
- व्यक्तियों पर प्रतिकूल प्रभाव: किसी भी प्रतिबंध या आवश्यकताओं, असमर्थित उपयोग, या किसी भी ज्ञात सीमाओं के बारे में जागरूक होना जो सिस्टम के प्रदर्शन को बाधित कर सकती हैं, यह सुनिश्चित करने के लिए महत्वपूर्ण है कि सिस्टम का उपयोग इस तरह से न हो जो व्यक्तियों को नुकसान पहुंचा सके।
- डेटा आवश्यकताएं: यह समझना कि सिस्टम डेटा का उपयोग कैसे और कहाँ करेगा, समीक्षकों को उन डेटा आवश्यकताओं का पता लगाने में सक्षम बनाता है जिनका आपको ध्यान रखना चाहिए (जैसे, GDPR या HIPPA डेटा नियम)। इसके अलावा, यह जांचें कि क्या डेटा का स्रोत या मात्रा प्रशिक्षण के लिए पर्याप्त है।
- प्रभाव का सारांश: संभावित हानियों की एक सूची एकत्र करें जो सिस्टम का उपयोग करने से उत्पन्न हो सकती हैं। ML जीवनचक्र के दौरान, यह समीक्षा करें कि पहचानी गई समस्याओं को कम किया गया है या संबोधित किया गया है।
- प्रत्येक छह मुख्य सिद्धांतों के लिए लागू लक्ष्य: मूल्यांकन करें कि क्या प्रत्येक सिद्धांत के लक्ष्यों को पूरा किया गया है और क्या कोई अंतराल है।
जिम्मेदार AI के साथ डिबगिंग
जैसे सॉफ़्टवेयर एप्लिकेशन को डिबग करना आवश्यक है, वैसे ही AI सिस्टम को डिबग करना भी आवश्यक है ताकि सिस्टम में समस्याओं की पहचान की जा सके और उन्हें हल किया जा सके। कई कारक हैं जो एक मॉडल को अपेक्षित या जिम्मेदार तरीके से प्रदर्शन करने से रोक सकते हैं। अधिकांश पारंपरिक मॉडल प्रदर्शन मेट्रिक्स मॉडल के प्रदर्शन के मात्रात्मक समुच्चय होते हैं, जो यह विश्लेषण करने के लिए पर्याप्त नहीं हैं कि मॉडल जिम्मेदार AI सिद्धांतों का उल्लंघन कैसे करता है। इसके अलावा, मशीन लर्निंग मॉडल एक ब्लैक बॉक्स है जो यह समझना कठिन बनाता है कि इसके परिणामों को क्या प्रेरित करता है या जब यह गलती करता है तो स्पष्टीकरण प्रदान करता है। इस पाठ्यक्रम में बाद में, हम जिम्मेदार AI डैशबोर्ड का उपयोग करना सीखेंगे ताकि AI सिस्टम को डिबग करने में मदद मिल सके। डैशबोर्ड डेटा वैज्ञानिकों और AI डेवलपर्स के लिए एक समग्र उपकरण प्रदान करता है ताकि वे निम्नलिखित कार्य कर सकें:
- त्रुटि विश्लेषण: मॉडल की त्रुटि वितरण की पहचान करने के लिए जो सिस्टम की निष्पक्षता या विश्वसनीयता को प्रभावित कर सकता है।
- मॉडल अवलोकन: यह पता लगाने के लिए कि डेटा समूहों में मॉडल के प्रदर्शन में असमानताएं कहाँ हैं।
- डेटा विश्लेषण: डेटा वितरण को समझने और डेटा में किसी भी संभावित पूर्वाग्रह की पहचान करने के लिए जो निष्पक्षता, समावेशिता, और विश्वसनीयता के मुद्दों को जन्म दे सकता है।
- मॉडल व्याख्या: यह समझने के लिए कि मॉडल की भविष्यवाणियों को क्या प्रभावित करता है। यह मॉडल के व्यवहार को समझाने में मदद करता है, जो पारदर्शिता और जवाबदेही के लिए महत्वपूर्ण है।
🚀 चुनौती
हानियों को पहली जगह में पेश होने से रोकने के लिए, हमें:
- सिस्टम पर काम करने वाले लोगों में पृष्ठभूमि और दृष्टिकोण की विविधता होनी चाहिए।
- ऐसे डेटासेट में निवेश करना चाहिए जो हमारे समाज की विविधता को दर्शाते हों।
- मशीन लर्निंग जीवनचक्र के दौरान जिम्मेदार AI का पता लगाने और सुधारने के लिए बेहतर तरीकों का विकास करना चाहिए।
उन वास्तविक जीवन परिदृश्यों के बारे में सोचें जहां मॉडल की अविश्वसनीयता मॉडल-निर्माण और उपयोग में स्पष्ट है। हमें और क्या विचार करना चाहिए?
पाठ के बाद का क्विज़
समीक्षा और स्व-अध्ययन
इस पाठ में, आपने मशीन लर्निंग में निष्पक्षता और असमानता की अवधारणाओं की कुछ मूल बातें सीखी हैं। इस कार्यशाला को देखें ताकि विषयों को गहराई से समझा जा सके:
- जिम्मेदार AI की खोज में: सिद्धांतों को व्यवहार में लाने पर Besmira Nushi, Mehrnoosh Sameki और Amit Sharma द्वारा प्रस्तुति

🎥 ऊपर दी गई छवि पर क्लिक करें वीडियो के लिए: RAI Toolbox: जिम्मेदार AI बनाने के लिए एक ओपन-सोर्स फ्रेमवर्क, Besmira Nushi, Mehrnoosh Sameki और Amit Sharma द्वारा
साथ ही पढ़ें:
-
Microsoft का RAI संसाधन केंद्र: Responsible AI Resources – Microsoft AI
-
Microsoft का FATE अनुसंधान समूह: FATE: Fairness, Accountability, Transparency, and Ethics in AI - Microsoft Research
RAI Toolbox:
Azure Machine Learning के उपकरणों के बारे में पढ़ें जो निष्पक्षता सुनिश्चित करते हैं:
असाइनमेंट
अस्वीकरण:
यह दस्तावेज़ AI अनुवाद सेवा Co-op Translator का उपयोग करके अनुवादित किया गया है। जबकि हम सटीकता के लिए प्रयासरत हैं, कृपया ध्यान दें कि स्वचालित अनुवाद में त्रुटियां या अशुद्धियां हो सकती हैं। मूल भाषा में उपलब्ध मूल दस्तावेज़ को आधिकारिक स्रोत माना जाना चाहिए। महत्वपूर्ण जानकारी के लिए, पेशेवर मानव अनुवाद की सिफारिश की जाती है। इस अनुवाद के उपयोग से उत्पन्न किसी भी गलतफहमी या गलत व्याख्या के लिए हम उत्तरदायी नहीं हैं।