23 KiB
Postscript : Débogage de modèles en apprentissage automatique avec les composants du tableau de bord AI responsable
Quiz avant la leçon
Introduction
L'apprentissage automatique influence notre vie quotidienne. L'IA s'intègre dans certains des systèmes les plus importants qui nous touchent en tant qu'individus et en tant que société, que ce soit dans les domaines de la santé, des finances, de l'éducation ou de l'emploi. Par exemple, des systèmes et modèles sont impliqués dans des tâches de prise de décision quotidienne, comme les diagnostics médicaux ou la détection de fraudes. En conséquence, les avancées de l'IA, combinées à son adoption accélérée, sont confrontées à des attentes sociétales en évolution et à une réglementation croissante. Nous observons constamment des domaines où les systèmes d'IA ne répondent pas aux attentes, exposent de nouveaux défis, et où les gouvernements commencent à réglementer les solutions d'IA. Il est donc essentiel d'analyser ces modèles pour garantir des résultats équitables, fiables, inclusifs, transparents et responsables pour tous.
Dans ce programme, nous examinerons des outils pratiques permettant d'évaluer si un modèle présente des problèmes liés à l'IA responsable. Les techniques traditionnelles de débogage en apprentissage automatique reposent souvent sur des calculs quantitatifs tels que la précision agrégée ou la perte moyenne d'erreur. Imaginez ce qui peut se produire lorsque les données utilisées pour construire ces modèles manquent de certaines caractéristiques démographiques, comme la race, le genre, les opinions politiques, la religion, ou représentent ces caractéristiques de manière disproportionnée. Que se passe-t-il lorsque les résultats du modèle favorisent certains groupes démographiques ? Cela peut entraîner une surreprésentation ou une sous-représentation de ces groupes sensibles, ce qui pose des problèmes d'équité, d'inclusivité ou de fiabilité. Un autre facteur est que les modèles d'apprentissage automatique sont souvent considérés comme des boîtes noires, ce qui rend difficile la compréhension et l'explication des raisons derrière leurs prédictions. Tous ces défis sont rencontrés par les data scientists et les développeurs d'IA lorsqu'ils ne disposent pas d'outils adéquats pour déboguer et évaluer l'équité ou la fiabilité d'un modèle.
Dans cette leçon, vous apprendrez à déboguer vos modèles en utilisant :
- Analyse des erreurs : identifier les zones de votre distribution de données où le modèle présente des taux d'erreur élevés.
- Vue d'ensemble du modèle : effectuer une analyse comparative entre différents groupes de données pour découvrir des disparités dans les métriques de performance de votre modèle.
- Analyse des données : examiner les zones où il pourrait y avoir une surreprésentation ou une sous-représentation des données, ce qui pourrait biaiser votre modèle en faveur d'un groupe démographique par rapport à un autre.
- Importance des caractéristiques : comprendre quelles caractéristiques influencent les prédictions de votre modèle à un niveau global ou local.
Prérequis
En guise de prérequis, veuillez consulter les outils d'IA responsable pour les développeurs

Analyse des erreurs
Les métriques traditionnelles de performance des modèles utilisées pour mesurer la précision reposent principalement sur des calculs basés sur les prédictions correctes ou incorrectes. Par exemple, déterminer qu'un modèle est précis à 89 % avec une perte d'erreur de 0,001 peut être considéré comme une bonne performance. Cependant, les erreurs ne sont souvent pas réparties uniformément dans votre ensemble de données sous-jacent. Vous pourriez obtenir un score de précision de 89 %, mais découvrir que dans certaines régions de vos données, le modèle échoue 42 % du temps. Les conséquences de ces schémas d'échec pour certains groupes de données peuvent entraîner des problèmes d'équité ou de fiabilité. Il est essentiel de comprendre les zones où le modèle fonctionne bien ou non. Les régions de données où le modèle présente un grand nombre d'inexactitudes peuvent s'avérer être des groupes démographiques importants.

Le composant d'analyse des erreurs du tableau de bord RAI illustre comment les échecs du modèle sont répartis entre différents groupes avec une visualisation en arbre. Cela permet d'identifier les caractéristiques ou les zones où le taux d'erreur est élevé dans votre ensemble de données. En voyant d'où proviennent la plupart des inexactitudes du modèle, vous pouvez commencer à enquêter sur la cause profonde. Vous pouvez également créer des groupes de données pour effectuer des analyses. Ces groupes de données aident dans le processus de débogage à déterminer pourquoi la performance du modèle est bonne dans un groupe, mais erronée dans un autre.

Les indicateurs visuels sur la carte en arbre permettent de localiser plus rapidement les zones problématiques. Par exemple, plus la couleur rouge d'un nœud d'arbre est foncée, plus le taux d'erreur est élevé.
La carte thermique est une autre fonctionnalité de visualisation que les utilisateurs peuvent utiliser pour enquêter sur le taux d'erreur en utilisant une ou deux caractéristiques afin de trouver un contributeur aux erreurs du modèle dans l'ensemble des données ou les groupes.

Utilisez l'analyse des erreurs lorsque vous devez :
- Comprendre en profondeur comment les échecs du modèle sont répartis dans un ensemble de données et entre plusieurs dimensions d'entrée et de caractéristiques.
- Décomposer les métriques de performance agrégées pour découvrir automatiquement des groupes erronés afin d'informer vos étapes de mitigation ciblées.
Vue d'ensemble du modèle
Évaluer la performance d'un modèle d'apprentissage automatique nécessite une compréhension globale de son comportement. Cela peut être réalisé en examinant plusieurs métriques telles que le taux d'erreur, la précision, le rappel, la précision ou l'erreur absolue moyenne (MAE) pour identifier des disparités entre les métriques de performance. Une métrique de performance peut sembler excellente, mais des inexactitudes peuvent être révélées dans une autre métrique. De plus, comparer les métriques pour identifier des disparités dans l'ensemble des données ou les groupes permet de mettre en lumière les zones où le modèle fonctionne bien ou non. Cela est particulièrement important pour observer la performance du modèle entre des caractéristiques sensibles et non sensibles (par exemple, la race, le genre ou l'âge des patients) afin de découvrir des injustices potentielles dans le modèle. Par exemple, découvrir que le modèle est plus erroné dans un groupe contenant des caractéristiques sensibles peut révéler des injustices potentielles.
Le composant Vue d'ensemble du modèle du tableau de bord RAI aide non seulement à analyser les métriques de performance de la représentation des données dans un groupe, mais il donne également aux utilisateurs la possibilité de comparer le comportement du modèle entre différents groupes.

La fonctionnalité d'analyse basée sur les caractéristiques du composant permet aux utilisateurs de se concentrer sur des sous-groupes de données au sein d'une caractéristique particulière pour identifier des anomalies à un niveau granulaire. Par exemple, le tableau de bord dispose d'une intelligence intégrée pour générer automatiquement des groupes pour une caractéristique sélectionnée par l'utilisateur (par exemple, "time_in_hospital < 3" ou "time_in_hospital >= 7"). Cela permet à un utilisateur d'isoler une caractéristique particulière d'un groupe de données plus large pour voir si elle est un facteur clé des résultats erronés du modèle.

Le composant Vue d'ensemble du modèle prend en charge deux classes de métriques de disparité :
Disparité dans la performance du modèle : Ces ensembles de métriques calculent la disparité (différence) dans les valeurs de la métrique de performance sélectionnée entre les sous-groupes de données. Voici quelques exemples :
- Disparité dans le taux de précision
- Disparité dans le taux d'erreur
- Disparité dans la précision
- Disparité dans le rappel
- Disparité dans l'erreur absolue moyenne (MAE)
Disparité dans le taux de sélection : Cette métrique contient la différence dans le taux de sélection (prédiction favorable) entre les sous-groupes. Un exemple de cela est la disparité dans les taux d'approbation de prêt. Le taux de sélection signifie la fraction de points de données dans chaque classe classée comme 1 (dans une classification binaire) ou la distribution des valeurs de prédiction (dans une régression).
Analyse des données
"Si vous torturez les données suffisamment longtemps, elles avoueront n'importe quoi" - Ronald Coase
Cette affirmation peut sembler extrême, mais il est vrai que les données peuvent être manipulées pour soutenir n'importe quelle conclusion. Une telle manipulation peut parfois se produire involontairement. En tant qu'humains, nous avons tous des biais, et il est souvent difficile de savoir consciemment quand nous introduisons des biais dans les données. Garantir l'équité dans l'IA et l'apprentissage automatique reste un défi complexe.
Les données constituent un angle mort important pour les métriques traditionnelles de performance des modèles. Vous pouvez avoir des scores de précision élevés, mais cela ne reflète pas toujours les biais sous-jacents qui pourraient exister dans votre ensemble de données. Par exemple, si un ensemble de données sur les employés montre que 27 % des femmes occupent des postes de direction dans une entreprise contre 73 % d'hommes au même niveau, un modèle d'IA de publicité d'emploi formé sur ces données pourrait cibler principalement un public masculin pour des postes de direction. Ce déséquilibre dans les données a biaisé la prédiction du modèle en faveur d'un genre. Cela révèle un problème d'équité où il existe un biais de genre dans le modèle d'IA.
Le composant Analyse des données du tableau de bord RAI aide à identifier les zones où il y a une surreprésentation ou une sous-représentation dans l'ensemble de données. Il aide les utilisateurs à diagnostiquer la cause profonde des erreurs et des problèmes d'équité introduits par des déséquilibres ou un manque de représentation d'un groupe de données particulier. Cela donne aux utilisateurs la possibilité de visualiser les ensembles de données en fonction des résultats prédits et réels, des groupes d'erreurs et des caractéristiques spécifiques. Parfois, découvrir un groupe de données sous-représenté peut également révéler que le modèle n'apprend pas bien, d'où les nombreuses inexactitudes. Avoir un modèle avec des biais dans les données n'est pas seulement un problème d'équité, mais montre également que le modèle n'est pas inclusif ou fiable.

Utilisez l'analyse des données lorsque vous devez :
- Explorer les statistiques de votre ensemble de données en sélectionnant différents filtres pour diviser vos données en différentes dimensions (également appelées groupes).
- Comprendre la distribution de votre ensemble de données entre différents groupes et caractéristiques.
- Déterminer si vos conclusions liées à l'équité, à l'analyse des erreurs et à la causalité (dérivées d'autres composants du tableau de bord) sont le résultat de la distribution de votre ensemble de données.
- Décider dans quels domaines collecter davantage de données pour atténuer les erreurs provenant de problèmes de représentation, de bruit dans les étiquettes, de bruit dans les caractéristiques, de biais dans les étiquettes, et de facteurs similaires.
Interprétabilité du modèle
Les modèles d'apprentissage automatique ont tendance à être des boîtes noires. Comprendre quelles caractéristiques clés des données influencent les prédictions d'un modèle peut être difficile. Il est important de fournir de la transparence sur les raisons pour lesquelles un modèle fait une certaine prédiction. Par exemple, si un système d'IA prédit qu'un patient diabétique risque d'être réadmis à l'hôpital dans moins de 30 jours, il devrait être en mesure de fournir des données justificatives qui ont conduit à sa prédiction. Avoir des indicateurs de données justificatifs apporte de la transparence pour aider les cliniciens ou les hôpitaux à prendre des décisions éclairées. De plus, être capable d'expliquer pourquoi un modèle a fait une prédiction pour un patient individuel permet de respecter les réglementations en matière de responsabilité. Lorsque vous utilisez des modèles d'apprentissage automatique de manière à affecter la vie des gens, il est crucial de comprendre et d'expliquer ce qui influence le comportement d'un modèle. L'explicabilité et l'interprétabilité des modèles aident à répondre à des questions dans des scénarios tels que :
- Débogage du modèle : Pourquoi mon modèle a-t-il fait cette erreur ? Comment puis-je améliorer mon modèle ?
- Collaboration humain-IA : Comment puis-je comprendre et faire confiance aux décisions du modèle ?
- Conformité réglementaire : Mon modèle satisfait-il aux exigences légales ?
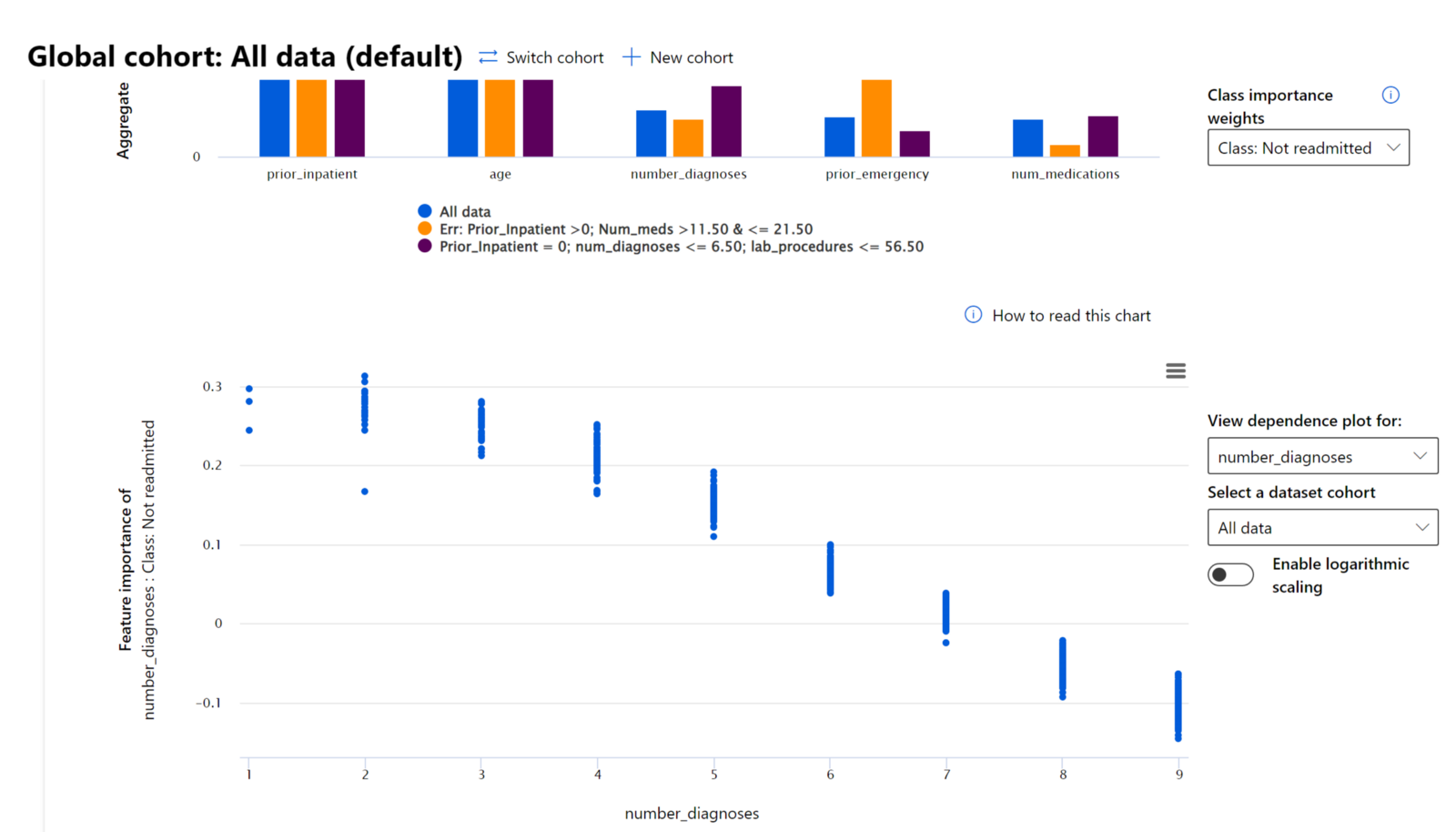
Le composant Importance des caractéristiques du tableau de bord RAI vous aide à déboguer et à obtenir une compréhension complète de la manière dont un modèle fait des prédictions. C'est également un outil utile pour les professionnels de l'apprentissage automatique et les décideurs afin d'expliquer et de montrer des preuves des caractéristiques influençant le comportement d'un modèle pour la conformité réglementaire. Ensuite, les utilisateurs peuvent explorer des explications globales et locales pour valider quelles caractéristiques influencent les prédictions d'un modèle. Les explications globales listent les principales caractéristiques qui ont affecté les prédictions globales d'un modèle. Les explications locales affichent les caractéristiques qui ont conduit à la prédiction d'un modèle pour un cas individuel. La capacité d'évaluer les explications locales est également utile pour déboguer ou auditer un cas spécifique afin de mieux comprendre et interpréter pourquoi un modèle a fait une prédiction correcte ou incorrecte.
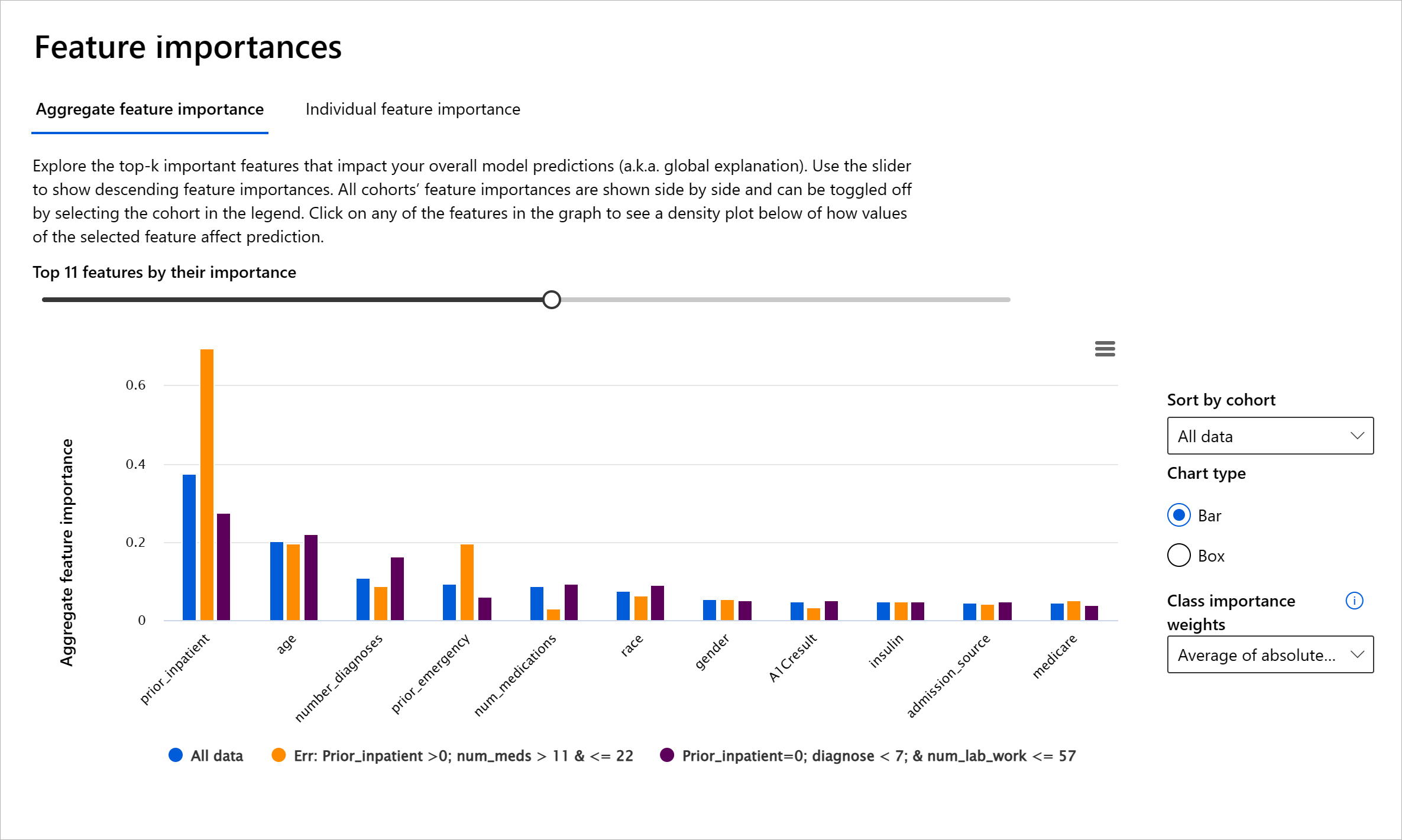
- Explications globales : Par exemple, quelles caractéristiques affectent le comportement global d'un modèle de réadmission à l'hôpital pour diabétiques ?
- Explications locales : Par exemple, pourquoi un patient diabétique de plus de 60 ans avec des hospitalisations antérieures a-t-il été prédit comme étant réadmis ou non réadmis dans les 30 jours à l'hôpital ?
Dans le processus de débogage pour examiner la performance d'un modèle entre différents groupes, Importance des caractéristiques montre quel niveau d'impact une caractéristique a entre les groupes. Cela aide à révéler des anomalies en comparant le niveau d'influence qu'une caractéristique a dans les prédictions erronées d'un modèle. Le composant Importance des caractéristiques peut montrer quelles valeurs dans une caractéristique ont influencé positivement ou négativement le résultat du modèle. Par exemple, si un modèle a fait une prédiction incorrecte, le composant vous donne la possibilité d'examiner en détail quelles caractéristiques ou valeurs de caractéristiques ont conduit à la prédiction. Ce niveau de détail aide non seulement au débogage, mais fournit également de la transparence et de la responsabilité dans des situations d'audit. Enfin, le composant peut vous aider à identifier des problèmes d'équité. Par exemple, si une caractéristique sensible comme l'origine ethnique ou le genre est très influente dans les prédictions d'un modèle, cela pourrait être un signe de biais racial ou de genre dans le modèle.
Utilisez l'interprétabilité lorsque vous devez :
- Déterminer dans quelle mesure les prédictions de votre système d'IA sont fiables en comprenant quelles caractéristiques sont les plus importantes pour les prédictions.
- Approcher le débogage de votre modèle en le comprenant d'abord et en identifiant si le modèle utilise des caractéristiques pertinentes ou simplement des corrélations erronées.
- Découvrir des sources potentielles d'injustice en comprenant si le modèle base ses prédictions sur des caractéristiques sensibles ou sur des caractéristiques fortement corrélées avec elles.
- Renforcer la confiance des utilisateurs dans les décisions de votre modèle en générant des explications locales pour illustrer leurs résultats.
- Réaliser un audit réglementaire d'un système d'IA pour valider les modèles et surveiller l'impact des décisions du modèle sur les humains.
Conclusion
Tous les composants du tableau de bord RAI sont des outils pratiques pour vous aider à construire des modèles d'apprentissage automatique moins nuisibles et plus fiables pour la société. Ils améliorent la prévention des menaces aux droits humains, la discrimination ou l'exclusion de certains groupes des opportunités de vie, et le risque de préjudice physique ou psychologique. Ils aident également à renforcer la confiance dans les décisions de votre modèle en générant des explications locales pour illustrer leurs résultats. Certains des préjudices potentiels peuvent être classés comme :
- Allocation, si un genre ou une origine ethnique, par exemple, est favorisé par rapport à un autre.
- Qualité du service. Si vous entraînez les données pour un scénario spécifique mais que la réalité est beaucoup plus complexe, cela conduit à un service de mauvaise qualité.
- Stéréotypage. Associer un groupe donné à des attributs préassignés.
- Dénigrement. Critiquer ou étiqueter injustement quelque chose ou quelqu'un.
- Sur- ou sous-représentation. L'idée est qu'un certain groupe n'est pas visible dans une certaine profession, et tout service ou fonction qui continue de promouvoir cela contribue à causer des préjudices.
Tableau de bord Azure RAI
Tableau de bord Azure RAI est basé sur des outils open-source développés par des institutions académiques et organisations de premier plan, y compris Microsoft. Ces outils sont essentiels pour les data scientists et les développeurs d'IA afin de mieux comprendre le comportement des modèles, identifier et atténuer les problèmes indésirables des modèles d'IA.
-
Apprenez à utiliser les différents composants en consultant la documentation du tableau de bord RAI.
-
Consultez quelques notebooks d'exemples du tableau de bord RAI pour déboguer des scénarios d'IA plus responsables dans Azure Machine Learning.
🚀 Défi
Pour éviter que des biais statistiques ou de données ne soient introduits dès le départ, nous devrions :
- avoir une diversité de parcours et de perspectives parmi les personnes travaillant sur les systèmes
- investir dans des ensembles de données qui reflètent la diversité de notre société
- développer de meilleures méthodes pour détecter et corriger les biais lorsqu'ils surviennent
Réfléchissez à des scénarios réels où l'injustice est évidente dans la construction et l'utilisation des modèles. Que devrions-nous considérer d'autre ?
Quiz après le cours
Révision et auto-apprentissage
Dans cette leçon, vous avez appris certains des outils pratiques pour intégrer l'IA responsable dans l'apprentissage automatique.
Regardez cet atelier pour approfondir les sujets :
- Tableau de bord Responsible AI : Une solution complète pour opérationnaliser l'IA responsable en pratique par Besmira Nushi et Mehrnoosh Sameki

🎥 Cliquez sur l'image ci-dessus pour une vidéo : Tableau de bord Responsible AI : Une solution complète pour opérationnaliser l'IA responsable en pratique par Besmira Nushi et Mehrnoosh Sameki
Consultez les matériaux suivants pour en savoir plus sur l'IA responsable et comment construire des modèles plus fiables :
-
Outils du tableau de bord RAI de Microsoft pour déboguer les modèles ML : Ressources sur les outils d'IA responsable
-
Explorez la boîte à outils Responsible AI : Github
-
Centre de ressources RAI de Microsoft : Ressources sur l'IA responsable – Microsoft AI
-
Groupe de recherche FATE de Microsoft : FATE : Équité, Responsabilité, Transparence et Éthique dans l'IA - Microsoft Research
Devoir
Explorez le tableau de bord RAI
Avertissement :
Ce document a été traduit à l'aide du service de traduction automatique Co-op Translator. Bien que nous nous efforcions d'assurer l'exactitude, veuillez noter que les traductions automatisées peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue d'origine doit être considéré comme la source faisant autorité. Pour des informations critiques, il est recommandé de recourir à une traduction professionnelle réalisée par un humain. Nous déclinons toute responsabilité en cas de malentendus ou d'interprétations erronées résultant de l'utilisation de cette traduction.