14 KiB
Histoire de l'apprentissage automatique
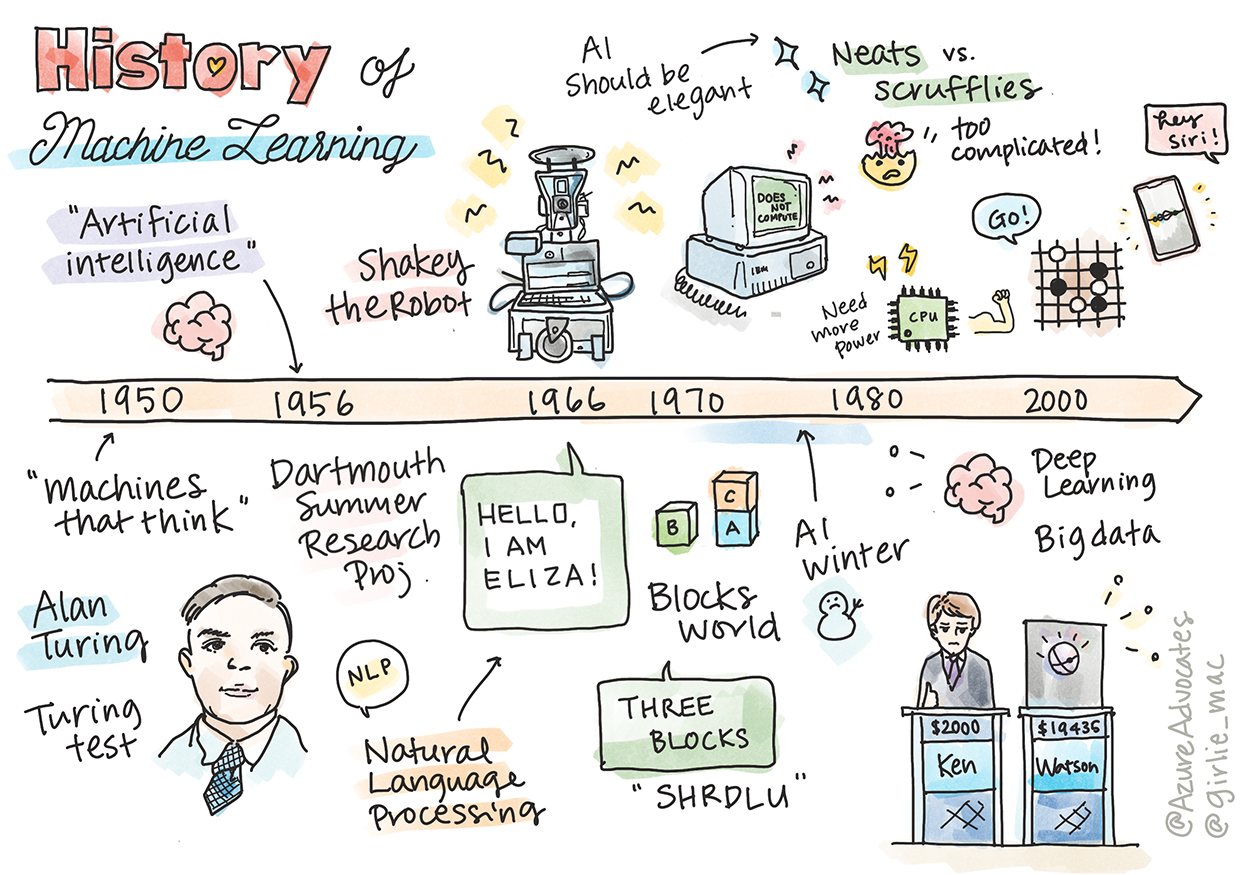
Sketchnote par Tomomi Imura
Quiz avant le cours

🎥 Cliquez sur l'image ci-dessus pour une courte vidéo sur cette leçon.
Dans cette leçon, nous allons parcourir les étapes majeures de l'histoire de l'apprentissage automatique et de l'intelligence artificielle.
L'histoire de l'intelligence artificielle (IA) en tant que domaine est étroitement liée à celle de l'apprentissage automatique, car les algorithmes et les avancées computationnelles qui sous-tendent l'apprentissage automatique ont alimenté le développement de l'IA. Il est utile de se rappeler que, bien que ces domaines en tant qu'aires d'étude distinctes aient commencé à se cristalliser dans les années 1950, des découvertes importantes algorithmiques, statistiques, mathématiques, computationnelles et techniques ont précédé et chevauché cette époque. En fait, les gens réfléchissent à ces questions depuis des centaines d'années : cet article discute des fondements intellectuels historiques de l'idée d'une "machine pensante".
Découvertes notables
- 1763, 1812 Théorème de Bayes et ses prédécesseurs. Ce théorème et ses applications sous-tendent l'inférence, décrivant la probabilité qu'un événement se produise en fonction de connaissances préalables.
- 1805 Théorie des moindres carrés par le mathématicien français Adrien-Marie Legendre. Cette théorie, que vous apprendrez dans notre unité sur la régression, aide à ajuster les données.
- 1913 Chaînes de Markov, nommées d'après le mathématicien russe Andrey Markov, sont utilisées pour décrire une séquence d'événements possibles basée sur un état précédent.
- 1957 Perceptron, un type de classificateur linéaire inventé par le psychologue américain Frank Rosenblatt, qui sous-tend les avancées en apprentissage profond.
- 1967 Plus proche voisin, un algorithme initialement conçu pour cartographier des itinéraires. Dans un contexte d'apprentissage automatique, il est utilisé pour détecter des motifs.
- 1970 Rétropropagation, utilisée pour entraîner les réseaux neuronaux feedforward.
- 1982 Réseaux neuronaux récurrents, des réseaux neuronaux artificiels dérivés des réseaux neuronaux feedforward qui créent des graphes temporels.
✅ Faites quelques recherches. Quelles autres dates se démarquent comme étant cruciales dans l'histoire de l'apprentissage automatique et de l'IA ?
1950 : Des machines qui pensent
Alan Turing, une personne véritablement remarquable qui a été élu par le public en 2019 comme le plus grand scientifique du 20e siècle, est crédité d'avoir contribué à poser les bases du concept d'une "machine capable de penser". Il a affronté les sceptiques et son propre besoin de preuves empiriques de ce concept en partie en créant le Test de Turing, que vous explorerez dans nos leçons sur le traitement du langage naturel.
1956 : Projet de recherche d'été à Dartmouth
"Le projet de recherche d'été à Dartmouth sur l'intelligence artificielle a été un événement fondateur pour l'intelligence artificielle en tant que domaine", et c'est ici que le terme "intelligence artificielle" a été inventé (source).
Chaque aspect de l'apprentissage ou toute autre caractéristique de l'intelligence peut en principe être décrit si précisément qu'une machine peut être conçue pour le simuler.
Le chercheur principal, le professeur de mathématiques John McCarthy, espérait "progresser sur la base de l'hypothèse que chaque aspect de l'apprentissage ou toute autre caractéristique de l'intelligence peut en principe être décrit si précisément qu'une machine peut être conçue pour le simuler." Les participants comprenaient un autre grand nom du domaine, Marvin Minsky.
L'atelier est crédité d'avoir initié et encouragé plusieurs discussions, notamment "l'essor des méthodes symboliques, des systèmes axés sur des domaines limités (premiers systèmes experts) et des systèmes déductifs par rapport aux systèmes inductifs." (source).
1956 - 1974 : "Les années dorées"
Des années 1950 au milieu des années 1970, l'optimisme était élevé quant à la capacité de l'IA à résoudre de nombreux problèmes. En 1967, Marvin Minsky déclarait avec confiance : "Dans une génération... le problème de la création de 'l'intelligence artificielle' sera substantiellement résolu." (Minsky, Marvin (1967), Computation: Finite and Infinite Machines, Englewood Cliffs, N.J.: Prentice-Hall)
La recherche en traitement du langage naturel a prospéré, la recherche a été affinée et rendue plus puissante, et le concept de "micro-mondes" a été créé, où des tâches simples étaient accomplies en utilisant des instructions en langage clair.
La recherche était bien financée par des agences gouvernementales, des avancées ont été réalisées en computation et en algorithmes, et des prototypes de machines intelligentes ont été construits. Certaines de ces machines incluent :
-
Shakey le robot, qui pouvait se déplacer et décider comment effectuer des tâches "intelligemment".

Shakey en 1972
-
Eliza, un premier "chatterbot", pouvait converser avec les gens et agir comme un "thérapeute" primitif. Vous en apprendrez davantage sur Eliza dans les leçons sur le traitement du langage naturel.
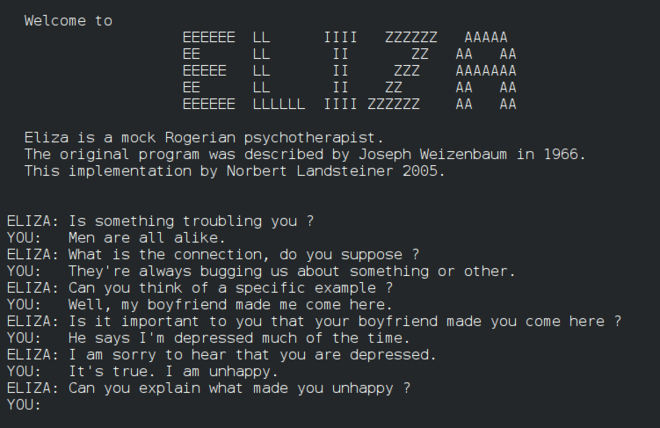
Une version d'Eliza, un chatbot
-
"Blocks world" était un exemple de micro-monde où des blocs pouvaient être empilés et triés, et des expériences pour enseigner aux machines à prendre des décisions pouvaient être testées. Les avancées construites avec des bibliothèques telles que SHRDLU ont aidé à propulser le traitement du langage.

🎥 Cliquez sur l'image ci-dessus pour une vidéo : Blocks world avec SHRDLU
1974 - 1980 : "Hiver de l'IA"
Au milieu des années 1970, il était devenu évident que la complexité de la création de "machines intelligentes" avait été sous-estimée et que ses promesses, compte tenu de la puissance de calcul disponible, avaient été exagérées. Le financement s'est tari et la confiance dans le domaine a ralenti. Certains problèmes qui ont affecté la confiance incluent :
- Limitations. La puissance de calcul était trop limitée.
- Explosion combinatoire. Le nombre de paramètres nécessaires à l'entraînement augmentait de manière exponentielle à mesure que l'on demandait plus aux ordinateurs, sans une évolution parallèle de la puissance et des capacités de calcul.
- Manque de données. Il y avait un manque de données qui entravait le processus de test, de développement et de raffinement des algorithmes.
- Posons-nous les bonnes questions ?. Les questions mêmes qui étaient posées ont commencé à être remises en question. Les chercheurs ont commencé à recevoir des critiques sur leurs approches :
- Les tests de Turing ont été remis en question, entre autres idées, par la théorie de la "chambre chinoise" qui postulait que "programmer un ordinateur numérique peut lui donner l'apparence de comprendre le langage mais ne pourrait pas produire une véritable compréhension." (source)
- L'éthique de l'introduction d'intelligences artificielles telles que le "thérapeute" ELIZA dans la société a été contestée.
En même temps, diverses écoles de pensée en IA ont commencé à se former. Une dichotomie s'est établie entre les pratiques "scruffy" vs. "neat AI". Les laboratoires scruffy ajustaient les programmes pendant des heures jusqu'à obtenir les résultats souhaités. Les laboratoires neat "se concentraient sur la logique et la résolution formelle de problèmes". ELIZA et SHRDLU étaient des systèmes scruffy bien connus. Dans les années 1980, à mesure que la demande pour rendre les systèmes d'apprentissage automatique reproductibles augmentait, l'approche neat a progressivement pris le devant de la scène car ses résultats sont plus explicables.
Années 1980 : Systèmes experts
À mesure que le domaine grandissait, ses avantages pour les entreprises devenaient plus clairs, et dans les années 1980, la prolifération des "systèmes experts" s'est également accrue. "Les systèmes experts étaient parmi les premières formes véritablement réussies de logiciels d'intelligence artificielle (IA)." (source).
Ce type de système est en réalité hybride, consistant en partie en un moteur de règles définissant les exigences métier, et un moteur d'inférence qui exploitait le système de règles pour déduire de nouveaux faits.
Cette époque a également vu une attention croissante portée aux réseaux neuronaux.
1987 - 1993 : "Refroidissement de l'IA"
La prolifération du matériel spécialisé pour les systèmes experts a eu l'effet malheureux de devenir trop spécialisée. L'essor des ordinateurs personnels a également concurrencé ces grands systèmes spécialisés et centralisés. La démocratisation de l'informatique avait commencé, et elle a finalement ouvert la voie à l'explosion moderne des big data.
1993 - 2011
Cette époque a vu une nouvelle ère pour l'apprentissage automatique et l'IA, permettant de résoudre certains des problèmes causés auparavant par le manque de données et de puissance de calcul. La quantité de données a commencé à augmenter rapidement et à devenir plus largement disponible, pour le meilleur et pour le pire, notamment avec l'avènement du smartphone vers 2007. La puissance de calcul a augmenté de manière exponentielle, et les algorithmes ont évolué en parallèle. Le domaine a commencé à gagner en maturité à mesure que les jours libres du passé se cristallisaient en une véritable discipline.
Aujourd'hui
Aujourd'hui, l'apprentissage automatique et l'IA touchent presque toutes les parties de nos vies. Cette époque appelle à une compréhension attentive des risques et des effets potentiels de ces algorithmes sur les vies humaines. Comme l'a déclaré Brad Smith de Microsoft : "La technologie de l'information soulève des questions qui touchent au cœur des protections fondamentales des droits humains comme la vie privée et la liberté d'expression. Ces questions augmentent la responsabilité des entreprises technologiques qui créent ces produits. À notre avis, elles appellent également à une réglementation gouvernementale réfléchie et au développement de normes autour des utilisations acceptables" (source).
Il reste à voir ce que l'avenir nous réserve, mais il est important de comprendre ces systèmes informatiques ainsi que les logiciels et algorithmes qu'ils exécutent. Nous espérons que ce programme vous aidera à mieux comprendre afin que vous puissiez décider par vous-même.

🎥 Cliquez sur l'image ci-dessus pour une vidéo : Yann LeCun discute de l'histoire de l'apprentissage profond dans cette conférence
🚀Défi
Plongez dans l'un de ces moments historiques et apprenez-en davantage sur les personnes derrière eux. Il y a des personnages fascinants, et aucune découverte scientifique n'a jamais été créée dans un vide culturel. Que découvrez-vous ?
Quiz après le cours
Révision et étude personnelle
Voici des éléments à regarder et écouter :
Ce podcast où Amy Boyd discute de l'évolution de l'IA

Devoir
Avertissement :
Ce document a été traduit à l'aide du service de traduction automatique Co-op Translator. Bien que nous nous efforcions d'assurer l'exactitude, veuillez noter que les traductions automatisées peuvent contenir des erreurs ou des inexactitudes. Le document original dans sa langue d'origine doit être considéré comme la source faisant autorité. Pour des informations critiques, il est recommandé de recourir à une traduction professionnelle réalisée par un humain. Nous déclinons toute responsabilité en cas de malentendus ou d'interprétations erronées résultant de l'utilisation de cette traduction.